【halcon深度学习】create_dl_model_detection
基本介绍
create_dl_model_detection 不是一个封装的库函数,是一个算子。用于创建用于目标检测或实例分割任务的深度学习模型。
输入参数:
-
Backbone (input_control): 指定用作背骨网络的深度学习分类器,充当模型的基础。用户可以选择不同的预训练分类器,如 AlexNet、Compact 等。
-
NumClasses (input_control): 指定模型要区分的类别数目。
-
DLModelDetectionParam (input_control): 一个字典,包含用于配置对象检测模型的各种参数。这些参数将影响模型的结构、训练方式等。
输出参数:
- DLModelHandle (output_control): 返回创建的深度学习模型的句柄。
描述:
-
该操作符的主要目的是创建一个深度学习模型,该模型可用于目标检测或实例分割任务。
-
用户需要通过参数
Backbone指定用作背骨网络的深度学习分类器,以及通过NumClasses指定模型要区分的类别数。 -
参数
DLModelDetectionParam是一个字典,用户可以在其中设置各种用于配置对象检测模型的参数。这些参数包括锚点角度、锚点纵横比、Backbone网络层级、图像维度、最大检测数等。 -
用户还可以设置参数
instance_segmentation,以指定模型是否用于实例分割任务。 -
对于参数
Backbone,用户可以选择不同的预训练分类器,每个分类器具有不同的特点和适用场景。例如,AlexNet 适用于简单分类任务,MobileNet V2 适用于移动和嵌入式应用。
示例用法:
* 创建一个用于目标检测的深度学习模型
create_dl_model_detection('pretrained_dl_classifier_compact.hdl', 3, DLModelDetectionParam, DLModelHandle)
上述代码创建一个目标检测模型,使用 ‘pretrained_dl_classifier_compact.hdl’ 作为背骨网络,模型要区分的类别数为 3,其他参数通过字典 DLModelDetectionParam 进行配置,并将模型的句柄存储在 DLModelHandle 中。
详细分析
Backbone
第一个参数 Backbone ,Backbone 主要就是用来提取特征的,Backbone 有很多成熟的模型。halcon用的也不是自己原创的,而是早就有的成熟模型。(根据我的粗浅认知,Backbone 就是一个神经卷积网络,什么是神经卷积网络?可以参考我之前写的一篇文章《卷积神经网络CNN中的卷积操作详解》)
create_dl_model_detection这个函数的Backbone ,有哪些参数可选呢?一共有6个!
(pretrained 表示预训练,表示这些都是预训练的好的网络。)
-
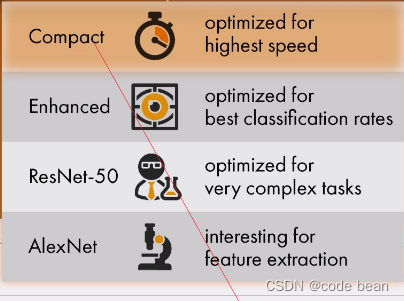
'pretrained_dl_classifier_alexnet.hdl':- 适用于简单的分类任务。
- 部分卷积层中的卷积核较大,与其他性能相当的网络(例如
'pretrained_dl_classifier_compact.hdl')相比,这可能有助于特征提取。 - 默认特征金字塔建立在此背骨网络上,最高级别为 4。
-
'pretrained_dl_classifier_compact.hdl':- 旨在在内存和运行时上具有高效性。
- 默认特征金字塔建立在此背骨网络上,最高级别为 4。
-
'pretrained_dl_classifier_enhanced.hdl':- 拥有比
'pretrained_dl_classifier_compact.hdl'更多的隐藏层,因此被认为更适用于更复杂的任务,但以时间和内存为代价。 - 默认特征金字塔建立在此背骨网络上,最高级别为 5。
- 拥有比
-
'pretrained_dl_classifier_mobilenet_v2.hdl':- 是一个小型且低功耗的模型,更适合移动和嵌入式视觉应用。
- 默认特征金字塔建立在此背骨网络上,最高级别为 4。
-
'pretrained_dl_classifier_resnet18.hdl':- 适用于更复杂的任务,与
'pretrained_dl_classifier_enhanced.hdl'类似,但结构不同,使训练更加稳定且内部更健壮。 - 默认特征金字塔建立在此背骨网络上,最高级别为 5。
- 适用于更复杂的任务,与
-
'pretrained_dl_classifier_resnet50.hdl':- 适用于更复杂的任务,与
'pretrained_dl_classifier_enhanced.hdl'类似,但结构不同,使训练更加稳定且内部更健壮。 - 默认特征金字塔建立在此背骨网络上,最高级别为 5。
- 适用于更复杂的任务,与
在使用 create_dl_model_detection 操作符时,你可以选择其中一个作为 Backbone 参数,具体选择取决于任务的需求和资源约束。
DLModelDetectionParam
DLModelDetectionParam 参数是一个字典,用于指定创建目标检测或实例分割模型时的各种参数。以下是一些可能在 DLModelDetectionParam 中设置的参数,你可以根据任务需求进行调整:
-
'anchor_angles': 锚定框的角度。 -
'anchor_aspect_ratios'(旧版本'aspect_ratios'): 锚定框的宽高比。 -
'anchor_num_subscales'(旧版本'num_subscales'): 锚定框的子刻度数量。 -
'backbone_docking_layers': Backbone 的对接层。 -
'bbox_heads_weight','class_heads_weight': 目标框和类别框的权重。 -
'capacity': 模型的容量。 -
'class_ids': 类别的标识。 -
'class_ids_no_orientation': 无方向的类别标识。 -
'class_names': 类别名称。 -
'class_weights': 类别权重。 -
'freeze_backbone_level': Backbone 网络的级别。 -
'ignore_direction': 是否忽略方向。 -
'image_dimensions': 图像的维度。 -
'image_height','image_width': 图像的高度和宽度。 -
'image_num_channels': 图像的通道数。 -
'instance_segmentation': 是否进行实例分割。 -
'instance_type': 实例的类型。 -
'mask_head_weight': 掩膜框的权重(仅适用于实例分割)。 -
'max_level','min_level': 特征金字塔的最大和最小级别。 -
'max_num_detections': 最大检测数量。 -
'max_overlap': 最大重叠。 -
'max_overlap_class_agnostic': 类别无关的最大重叠。 -
'min_confidence': 最小置信度。 -
'optimize_for_inference': 是否优化用于推断。
这些参数提供了对创建模型的各个方面进行精细控制的能力,以满足不同场景和任务的需求。你可以根据实际情况选择性地设置这些参数。
一些参数的说明
'max_overlap': 最大重叠。 和 'max_overlap_class_agnostic': 类别无关的最大重叠。
指的的选择框(锚定框)的重叠,这个和非极大抑制有关(交并比)。
可以去看看这篇:《非极大抑制》
instance_segmentation,以指定模型是否用于实例分割任务。
当然这里面很多参数,其实可以来自之前讲到的一个函数:
determine_dl_model_detection_param
直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议使用这一过程来优化训练和推断性能。
没错关联起来了。
代码上下文
*
determine_dl_model_detection_param (DLDataset, ImageWidth, ImageHeight, GenParam, DLDetectionModelParam)
*
* Get the generated model parameters.
MinLevel := DLDetectionModelParam.min_level
MaxLevel := DLDetectionModelParam.max_level
AnchorNumSubscales := DLDetectionModelParam.anchor_num_subscales
AnchorAspectRatios := DLDetectionModelParam.anchor_aspect_ratios
*
* *******************************************
* ** Create the object detection model ***
* *******************************************
*
* Create dictionary for generic parameters and create the object detection model.
DLModelDetectionParam := dict{}
DLModelDetectionParam.image_width := ImageWidth
DLModelDetectionParam.image_height := ImageHeight
DLModelDetectionParam.image_num_channels := ImageNumChannels
DLModelDetectionParam.min_level := MinLevel
DLModelDetectionParam.max_level := MaxLevel
DLModelDetectionParam.anchor_num_subscales := AnchorNumSubscales
DLModelDetectionParam.anchor_aspect_ratios := AnchorAspectRatios
DLModelDetectionParam.capacity := Capacity
*
* Get class IDs from dataset for the model.
ClassIDs := DLDataset.class_ids
DLModelDetectionParam.class_ids := ClassIDs
* Get class names from dataset for the model.
ClassNames := DLDataset.class_names
DLModelDetectionParam.class_names := ClassNames
*
* Create the model.
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!