多线程安全,无锁化编程(超级详细)
多线程安全,无锁化编程
内核的多线程安全
IRQL(Interrupt ReQuest Level )
什么是中断?

中断硬件(电脑自身的硬件或者与电脑连接的外部设备)产生的一个电信号
过程:比如外部设备有事情需要系统去处理的话,外部设备发出一个电信号,经过中断控制器得到中断向量传给cpu,cpu根据中断向量(这里的中断id)在中断向量表找到对应的中断函数,来处理这个函数,处理分为上半部分和下半部分。
-
上半部分,关中断,要求处理特别快,处理慢就会造成其他硬件等待时间变长,响应速度下降,性能下降,所以只把重要的部分(快速需要完成的任务)放在上半部分执行。
-
下半部分,把不重要不紧急的放在下半部分去处理,

-
通过对中断控制器8259A的配置,可将IRQ0~IRQ7对应到中断向量20h~27h。同样地IRQ8~1RQ15可对应到中断向量28h~2Fh
中断的分类
异常:CPU内部出现的中断
-
特征是:IF(中断标志,rflag或者eflag中断标志寄存器中的一个位,用来做中断的开启或者屏蔽)维持不变(当cpu产生异常的时候,中断不会被屏蔽的,还可以响应其他中断请求)
-
故障(FALT) 如除0,缺页,越界,堆栈段错误(客观的)
-
陷阱(TRAP)如调试指令int 3了,溢出等,故意为之(人为的有目的的)
中断(外部中断): IF标志清零(关中断,在处理完当前中断之前,不响应其他中断,直到IF标志置1)
中断向量
中断向量:0-255(1Byte)
-
0(0x0)~31(0x1f):异常
-
32 (0x20)~47 (0x2f):IO引起的屏蔽中断(由中断控制器连接的硬件)
-
48 (0x30)~255 (0xff):软中断,比如linux是通过0x80系统调用system_call()进入内核
中断优先级
无中断:
-
PASSIVE_LEVEL(0) DriverEntry()、DriverUnload(),分发函数处于这个级别
软中断:
-
APC_LEVEL (1)
-
DISPATCH_LEVEL(2) 完成函数(在irp完成的时候调用的函数)、NDIS(防火墙)回调函数处于这个级别 (做内核开发不涉及硬件的话,最高的中断级别就不会超过在这个级别的)
硬中断:
-
DIRQL 设备中断请求级处理程床执行
-
PROFILE_LEVEL 配置文件定时器
-
CLOCK2_LEVEL时钟
-
SYNCH LEVEL同步级
-
IPI LEVE 处理器之间中断级
-
POWER LEVEL电源故障级
如何遵循中断级别要求?
要清楚驱动中各个函数的中断级别

添加图片注释,不超过 140 字(可选)
要清楚要调用的API的运行级别(主要看函数内部有没有访问分页内存)
-
降IRQL比如:需要在高IRQL中处理低IRQL的一些事情。键盘木马,键盘过滤驱动记录按键消息,把数据拿到再存到文件中,上传到服务器上。但按键消息只能在完成函数(DISPATCH_LEVEL,不能进行文件的读写)拿到,这时候需要开启一个工作者线程,把IRQL降低,在工作者线程把数据存为文件即可。
-
PASSIVE_LEVEL级别可以使用任何函数和内存
-
DISPATCH_LEVEL级别只能访问能运行在DISPATCH_LEVEL级别的API和非分页内存
-
NONPAGEPOOL内存可在任何级别使用
-
PAGEDPOOL只能在PASSIVE_LEVEL和APC_LEVEL
-
如果不能保证代码遵循了IRQL级别,比如知道当前的代码是PASSIVE_LEVE,但不能保证代码里面是否有IRQL不匹配,就可使用在PASSIVE_LEVEL和APC_LEVEL级别代码中加:PAGED_CODE()宏。
/// 这个宏就是用来判断,如果当前代码的IRQL > APC_IRQL,就会ASSERT(FALSE);抛出异常,系统蓝屏
/// 只在调试版本有效
#define PAGED_CODE()\
{if (KeGetCurrentIrql() > APC_LEVEL){\
KdPrint(("EX: Pageable code called at IRQL %d\n",KeGetCurrentlrql()));\
ASSERT(FALSE);}\
}\相关视频推荐
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

中断上下文与进程上下文
上下文context:
-
上下文简单说来就是个环境,相对于进程而言,就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件内存信息等。
-
上下文:关联到某个对象的空间,相当于人身上的一个口袋
如果cpu在执行中断函数的时候,就称系统处在中断上下文里面,这时候系统代替硬件去做一些事情,处在硬件的环境中,由于硬件环境没有进程调度的机制,所以系统如果处于中断上下文的话是不可睡眠的,因为一但睡眠,就无法把你切换回来了,也再调度其他进程执行,系统就死掉了。
-
中断上下文:其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被中断的进程环境)
如果系统在代替进程做一些事情,就称系统处在进程上下文,处于进程上下文是可以睡眠的,因为睡眠之后,还可以通过调度机制重新把你切换回来。
一个进程的上下文可以分为三个部分:
-
用户级上下文:正文数据、用户堆栈以及共享存储区:
-
寄存器上下文:通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)栈指针(EFLAGS)
-
系统级上下文:进程控制块task struct、内存管理信息mm struct、vm_area_struct、pgd、pte)、内核栈
Linux内核工作在进程上下文或者中断下文。
-
1、睡眠或者放弃CPU(硬件与人睡眠例子) 因为内核在进入中断之前会关闭进程调度,一旦睡眠或者放弃CPU,这时内核无法调度别的进程来执行,系统就会死掉。引起睡眠的情况:wake(),异步读循环等待,内存分配函数。
-
2、尝试获得信号量如果获不到信号量,代码就会睡眠,效果同1
-
3、执行耗时的任务中断处理应该尽可能快,因为内核要响应大量服务和请求中断上下文占用CPU时间太长会严重影响系统功能
-
4、访问用户空间的虚拟地址
-
提供系统调用服务的内核代码,代表发起系统调用的应用程序运行在进程上下文,代表进程运行。
-
另一方面,中断处理程序,异步运行在中断上下文,代表硬件运行,中断上下文和特定进程无关。运行在中断上下文的代码就要受一些限制,不能做下面的事情:
线程的相关概念
什么是线程?
-
1.易于调度。线程是系统调度的基本单位,线程的切换比进程要快。
-
2.提高并发性。通过线程可方便有效地实现并发性。进程可创建多个线程来执行同一程序的不同部分。(左右手画画,唱歌)
-
3.开销少,创建线比创建进程要快,所需开销很少,仅占有量的资源,比如栈和寄存器。
-
4.利于充分发挥多处理器的功能。通过创建多线程进程(即进程可具有两个或更多个线程)每个线程在各个处理器上运行,从而实现应用程序的并发性使每个处理器都得到充分运行。
-
查着任务管理器(现在绝大多程序都是多线程的)
-
目的:提高系统并发的度(某一个时间段多程序执行,但具体到某一个时刻只有一个程序)
-
所谓线程,即进程中执行运算的最小单位,亦即执行处理机调度的基本单位。如果把进程理解为在逻辑上操作系统所完成的任务,那么线程表示完成该任务的许多可能的子任务之一。
-
线程可以在处理器上独立调度执行。这样,在多处理器环境下就允许几个线程各自在单独处理器上进行。操作系统提供线程就是为了方便而有效地实现这种并发性,线程带来的好处包括:
超线程
-
虽然单线程芯片每秒钟能够处理成千上万条指令,但是在任一时刻只能够对一条指令进行操作。而超线程技术可以使芯片同时进行多线程处理,使芯片性能得到提升。
-
采用超线程技术能同时执行两个线程,但它并不像两个真正的CPU那样,每个CPU都具有独立的资源(寄存器)。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗CPU的性能(连体人例子)
-
Die:CPU核心,又称为内核,就是CPU上面中间的小方块,里面是CPU的核心,是CPU最重要的组成部分。CPU中心那块隆起的芯片就是核心,是由单晶硅以一定的生产工艺制造出来的,CPU所有的计算、接受/存储命令、处理数据都由核心执行。各种CPU核心都具有固定的逻辑结构,一级缓存、二级缓存、执行单元、指令级单元和总线接口等逻辑单元都会有科学的布局。为了便于CPU设计生产、销售的管理CPU制造商会对各种CPU核心给出相应的代号,这也就是所谓的CPU核心类型。核心面积(这是决定CPU成本的关键因素,成本与核心面积基本上成正比)
-
超线程技术是在一颗CPU同时执行多个程序而共同分享一颗CPU内的资源,理论上要像两颗CPU一样在同一时间执行两个线程,P4处理器需要多加入一个Logical CPU Pointer(逻辑处理单元)。因此新一代的P4 HT的die的面积比以往的P4增大了5%。而其余部分如ALU(算数逻辑运算单元)、FPU(浮点运算单元)L2Cache (二级缓存)则保持不变,这些部分是被分享的。
-
cpu有:单核、单核超线程(假多核)、多核(真多核),超线程是多核cpu出现之前的过渡。
-
是Intel所研发的一种技术,于2002年发布。超线程的英文是HT技术,全名为Hyper-Threading,中文又名超线程。
-
采用超线程即是可在同一时间里,应用程序可以使用芯片的不同部分。
与进程关系:
-
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
-
线程在运行过程中,需要同步与互斥。不同进程的线程间要用进程通信的办法实现同步。
-
在系统中,一个程序至少有一个进程,一个进程至少有一个线程。
与进程区别:
-
进程是资源分配单位。线程除了拥有部分寄存器和栈外(切换线程的时候,就需要对线程上下文(栈和寄存器)进行备份),不拥有系统资源,但可以访问属于进程的资源。
-
线程:调度单位,即线程拥有CPU,即在CPU运行的是线程。运行一定时间片就会被切换。
-
系统开销:在创建或撤消进程时由于系统都要为之分配和收资源,导致系统的开销明显大于创建或撤消线程时的开销。
同步:线程与线程之间合作
互斥:线程之间竞争
带来什么问题?(R3的例子说明)
-
局部变量(得加锁,保证一次只能被一个人访问,卫生间为例子)
-
全局变量以及其他资源
-
程序一致性(线程安全性,存钱的例子)
-
代码多线程安全(可重入:一份代码可以让多个线程执行,一个资源可以被多个线程访问)
分发函数为什么处在多线程环境下?
-
创建设备对象的时候没有设置排他性,即该设备对象可以被多个进程打开,每个Irp请求都会发给分发函数处理,分发函数处在多进程环境。
-
多进程肯定是多线程。即使在同一个进程,也可以开启多线程,在每个线程都向设备对象发送Irp请求,对应的分发函数可以处理多个线程的Irp请求,自然也是多线程环境
多线程创建
-
多线程编程都包含三个组成部分:
-
一是线程执行函数;(线程代码)
-
二是线程创建函数;(如何创建线程)
-
三是线程数据同步机制(如何保证多线程数据安全)
-
线程执行函数就是在新的线程中要执行的代码,需要通过编程去实现,把要在新的线程中完成的任务放在该执行函数中去完成;
-
创建线程函数负责新的线程的创建,它需要线程执行函数作为参数,然后线程执行函数自己的参数也做为参数之一(如果线程执行函数自己存在参数的话)
-
线程数据同步机制则负责多线程执行环境条件下数据的完整性和一致性。
创建线程的函数(应用层)
-
CreateThread:是Windows的API函数(SDK函数的标准形式,直截了当的创建方式,任何场合都可以使用),提供操作系统级别的创建线程的操作,且仅限于工作者线程。不调用MFC和CRT的函数时,可以用Create Thread,其它情况不要使用。因为:
-
C Runtime中需要对多线程进行纪录和初始化,以保证C函数库工作正常。
-
MFC也需要知道新线程的创建,也需要做一些初始化工作(分配内存)。
-
有些CRT的函数malloc(),fopen(),_open(),strtok(),ctime(),或localtime()等函数需要专门的线程局部存储的数据块,这个数据块通常需要在创建线程的时候就建立,如果使用CreateThread,这个数据块就没有建立,但函数会自己建立一个,然后将其与线程联系在一起,这意味着如果你用CreateThread来创建线程,然后使用这样的函数,会有块内存在不知不觉中创建,而且这些函数并不将其删除,而CreateThread和ExitThread也无法知道这件事,于是就会有Memory Leak,在线程频繁启动的软件中,迟早会让系统的内存资源耗尽。
-
_beginthreadex:MS对C Runtime库的扩展SDK函数,首先针对C Runtime库做了一些初始化的工作,以保证C Runtime库工作正常。然后,调用CreateThread真正创建线程
-
AfxBeginThread:MFC中线程创建的MFC函数,首先创建了相应的CWinThread对象,然后调CWinThread::CreateThread,在CWinThread::CreateThread中完成了对线程对象的初始化工作,然后调用_beginthreadex(AfxBeginThread相比较更为安全)创建线程。它让线程能够响应消息,可用于界面线程,也可以用于工作者线程。
-
pthread_create: LINUX平台
函数应用条件
-
AfxBeginThread:在MFC中用,工作者线程/界面线程
-
_beginthreadex:调用C运行库的,应该用这个,但不能用在MFC中。
-
CreateThread:工作者线程,MFC中不能用C runtime 中不能用。所以r任何时候最好都不要用。
-
AfxBeginThread>_beginthreadex>CreateThread
函数传参数(内核层和应用层一样)
创建线程的函数(内核层)
/// 线程执行函数
void DoFind(IN PVOID pContext)
{
/// 为了让子线程常驻内存,写死循环,某些情况(比如用全局变量作为标志)才break退出,
while(1)
{
if(something) break;
}
}
/// 主线程,需要等待子线程的结束,否则,如果主线程比子线程提前结束,子线程就成了`孤魂野鬼`
void StartThread()
{
HANDLE hThread = NULL;
PVOID objtowait = 0;
/**
* @brief PsCreateSystemThread 线程创建函数,创建线程,创建成功之后,会执行DoFind函数,直到DoFind函数返回,PsCreateSystemThread才返回;
* @param[out] hThread 创建线程的句柄
* @param[in] DoFind 函数地址,指向线程执行的代码;
* @param[in] NULL(倒数第一个)结构体,传给线程执行函数的某些参数封装到结构体中;比如传ip地址和端口
* @author cisco(微信公众号:坚毅猿)
* @date 2022-02-27 22:09
*/
NTSTATUS dwStatus =
PsCreateSystemThread(
&hThread,0,NULL,(HANDLE)0,
NULL,DoFind,NULL
);
///
if (!NT_SUCCESS(dwStatus)
{
return;
}
/**
* @brief ObReferenceObjectByHandle 获取新创建子线程的句柄;
* @param[in] hThread PsCreateSystemThread()所创建线程的句柄;
* @param[out] &objtowait 由线程句柄得到线程的内核对象
* @param[in] NULL(第一个)不应该传NULL,要指定线程的类型;
* @author cisco(微信公众号:坚毅猿)
* @date 2022-02-27 22:09
*/
ObReferenceObjectByHandle(
hThread,
THREAD_ALL_ACCESs,
NULL,
KernelMode,
&objtowait,
NULL
)
/// 等待子线程的内核对象退出,只要该线程没有退出,这个函数会一直在这里等待,如果该线程退出来了,objtowait的状态就会发生改变,函数就会返回,继续往下执行。
/// 如果主线程提前结束,主线程传给子线程的参数是在主线程定义局部变量,已经销毁了,就成了野指针,子线程再访问这些变量的时候,就可能出问题了。
KeWaitForSingleobject(objtowait,Executive,KernelMode,FALSE,NOE);
ObDereferenee(&objtowait);
return;
}线程的同步与互斥
同步(A告诉B发生了什么事)
-
常用机制
-
KEVENT事件
-
KSEMAPHORE信号量
-
KMUTEX互斥体
-
KQUEUE
-
KTHREAD线程内核对象
-
KTIMER(本质:上述的都带dispatcher header结构体)
-
fileobject/driverobject等不行(不带dispatcher header结构体)
同步机制-KEVENT
-
用于线程同步
-
eg:生产者-消费者、R0-R3、司机-售票员
-
Event两个状态:
-
Signaled
-
Non-signaled
-
Event两个类别:
-
Notification事件:不自动恢复,需要手动设置,比如卧室的灯打开了,如果不手动关灯,就会一直亮着
-
synchronization事件:自动恢复,比如声控灯
-
KeWaitForSingleObject(一次等一个对象)/KeWaitForMultipleObject(一次等多个对象)等待事件的发生
LARGE_INTEGER TimeOut = {0};
/// 等待时间必须是负数,等待10s
TimeOut.QuadPart = -10* 10000000i64;
KeWaitForSingleObject(
&kSemaphore, //如果等待进程的事件发生了,就会把信号量+1,KeWaitForSingleObject()检测到kSemaphore变化了,函数返回,就会退出等待。
Executive,
KernelMode,
RFALSE,
&TimeOut //TimeQut==0.不等待;NULL,无限等待
);-
创建:loCreateNotificationEvent
/// 线程A:
/// 定义开灯事件
KEVENT waitEvent;
/// 初始化事件,NotificationEven表示设置为不自动恢复事件,FALSE表示最初为无信号状态
/// 这里没有给事件起名字,可以给事件起名字
KeInitializeEvent(&waitEvent,
NotificationEvent,
FALSE);
/// 开灯 会将线程B从睡眠中唤醒
KeSetEvent(&waitEvent,
IO_NO_INCREMENT,
FALSE);
/// 线程B:
/// 等灯 在等待线程A的开灯事件的过程中会睡眠,让出CPU,直到线程A开灯,线程B才会被唤醒,KeWaitForSingleObject函数返回,继续往下执行
KeWaitForSingleObject(
&waitEvent,
Executive,
KernelMode,
FALSE,
NULL); ///< TimeQut=0,不等待;NULL,无限等待
/// 关灯 把事件状态设置成无信号状态
KeClearEvent(&waitEvent);
KeResetEvent(&waitEvent);进程创建监视:R0到R3通信 方式1:轮询
/// 方式1:轮询
/// 缺点:效率问题
while(1)
{
///发送DeviceloControl下去拿数据
Sleep(1000);
}进程创建监视:R0到R3通信 方式2:通过事件
内核层
-
Event创建:
/// BaseNamedObjects固定的,ProcEvent可以自己定义
L"\\BaseNamedObjects\\ProcEvent"
IoCreateNotificationEvent-
数据存放:
/// 在创建设备对象的时候,可以分配一段空间作为设备扩展,设备扩展可以存放我们任何想存放的数据
/// 利用设备扩展存放创建的监视的进程信息,一旦通知的应用层,应用层就会下来从设备扩展里面把数据拿到
typedef struct _DEVICE_EXTENSION
{
HANDLE hProcessHandle; ///< 事件对象句柄
PKEVENT ProcessEvent; ///< 用户和内核通信的事件对象指针
HANDLE hParentId; ///< 创建进程的父id
HANDLE hProcessId; ///< 创建进程的id
BOOLEAN bCreate; ///< 表示进程是创建还是销毁
}DEVICE_EXTENSION, *PDEVICE_EXTENSION;
/// 指定设备扩展的大小,这样创建出来的设备对象就有一个设备扩展
IoCreateDevice( DriverObject, sizeof(DEXICE_EXTENSION); &ustrDeviceName ...)
/// 访问:
//获得DEVICE_EXTENSION结构
PDEVICE_EXTENSION deviceExtension = (PDEVICE_EXTENSION)g_pDeviceObject->DeviceExtension;
/// 保存信息
deviceExtension->hParentId = hParentId;
deviceExtension->hProcessId = PId;
deviceExtension->bcreate =bCreate;-
事件触发
/// 触发事件,通知应用程序
/// 设置事件为有信号
KeSetEvent(deviceExtension->ProcessEvent, 0,FALSE);
/// 用完之后,把事件恢复到无信号
KeClearEvent(deviceExtension->ProcessEvent);应用层
/// Global在XP是不用加的,在win7以上系统事件前面一定要加Global
/// XP下服务程序和应用程序创建的内核对象的命名空间默认是全局的,而Win7后不是,服务创建的内核对象默认在session0下,
/// 用户创建的内核对象默认在各自的session下(一次登陆就是一个session),解决此问题的方法为在创建命名时间对象时指定名字是全局的,即带上Global
#define EVENT_NAME L"Global\\ProcEvent"
/// 打开内核事件对象
HANDLE hProcessEvent = ::OpenEventW(SYNCHRONIZE, FALSE,
EVENT_NAME);
/// 等待事件,INFINTE等待的时间是无限的,有事件触发的时候函数返回,然后进入while循环
while (::WaitForSingleObject(hProcessEvent, INFINTE))
{
/// bugs to fix here
/// 发送DeviceloControl下去拿数据
}优化
-
存在的问题:
-
如果源码事件名字正确,编译出来的监控程序,当有其他程序打开的时候,监控程序就退出
-
如果源码事件名字错误,编译出来的监控程序,能监控进程的创建和销毁,但CPU占用会达到100%,好像变成了轮询
-
改进的空间
-
现存的问题:创建进程的信息保存在同一个设备扩展中,如果系统创建的进程比较多,应用层来不及拿数据,新数据会把老数据覆盖掉
-
改进:应该使用一个链表,以保证能把数据长期保存
互斥(A和B只能一个访问)
-
KSPIN_LOCK自旋锁
-
ERESOURCE读写锁共享锁
-
FAST_MUTEX快速互斥锁
KSPIN_LOCK自旋锁
-
用于线程互斥
-
用到情况不多,主要要的还是另外两种
-
忙等(不会睡眠文不会阻塞)。对忙等线程的调度则该线程会占着CPU不放,一直轮循,因此Spinlock适用于等待时间不会太长(例如不要超过25微秒)的情况。而Mutex不是,它会系统阻塞请求线程。如果你需要长时间串行化访问一个对象,应该首先考虑使用互斥量而不是自旋锁。
-
Spinlock请求成功之后,CPU的执行级别会提升到DISPATCH_LEVEL,Mutex不会。
-
DISPATCH_LEVEL及以下级别都可以请求Spinlock。Mutex通常在PASSIVE_LEVEL请求,在DISPATCH_LEVEL上TIMEOUT需设为0。
-
Spinlock是“非递归锁”,即不能递归获得该锁,而Mutex是“递归锁”。
-
Spinlock主要用于多CPU多核的情况,但效率不高,使用ERESOURCE较好
使用注意事项:
-
多CPU共享安全
-
提升IRQL到DISPATCH_LEVEL
-
禁止访问分页内存
-
不能调用只能在PASSIVE_LEVEL调用的函数
-
获得时间越短越好,因为自旋锁是轮询的机制,当锁被拿到之后,别人是在忙等,一直在问你“锁可以用了吗可以用了吗可以用了吗?”
使用方法:
/// 定义
KIRQL OldIrql; ///< 获取自选锁的时候,IRQL会上升,需要提前保存原来的IRQL用来恢复原始状态
KSPINLOCK mySpinLockProc; ///< 存放要拿的自旋锁
/// 获得自旋锁并保存原来的状态,拿的过程是轮询是忙等,拿不到会在这一直拿,不会让出CPU,不会阻塞睡眠
KeAcquireSpinLock(
&mySpinLockProc,
&OldIrql);
/// 对数据进行操作和访问
g_i++; ///< 全局资源,尽量快完成操作
...
/// 释放自旋锁并恢复原来的状态
KeReleaseSpinlLock(
&mySpinLockProc,Oldlrqll.ERESOURCE读写锁共享锁
-
允许多人读,一个人写
使用方法:
/// 把ERESOURCE封装在结构体里面,封装一下好看一点,看名字就知道是锁
/// 把拿锁释放锁删除锁操作封装成单独的函数,用起来方便些
typedef struct _MY_LOCK
{
ERESOURCE m_Lock;//用于互斥
}MY_LOCK;
/// 初始化
/// __stdcall表示 1.参数从右向左压入堆栈 2.函数被调用者修改堆栈
VOID __stdcall InitLock(MY_LOCK* IpLock)
{
ExInitalizeResourceLite(&lpLock->m_Lock);
}
/// 拿写锁
VOID __stdcall LockWrite(MY_LOCK* IpLock)
{
/// 进入临界区
KeEnterCriticalRegion();
/// Exclusive
ExAcquireResourceExclusiveLite(&lpLock->m_Lock,TRUE)
}
/// 释放锁
VoID stdcall UnLockWrite(MY_LOCK* lpLock)
{
ExReleaseResourceLite(&lpLock->m_Lock);
/// 退出临界区
KeLeaveCriticalRegion();
}
/// 拿读锁与拿写锁类似前面
VoID_stdcall LockRead(MY_LOCK* lpLock)
{
/// 进入临界区
KeEnterCriticalRegion0;
/// Shared
ExAcquireResourceSharedLite(&lplLock->m_Lock,TRUE);
}
/// 释放锁
VoID stdcall UnLockWrite(MY_LOCK* lpLock)
{
ExReleaseResourceLite(&lpLock->m_Lock);
/// 退出临界区
KeLeaveCriticalRegion();
}
/// 以让等待读优先的方式去拿读锁
VOID __stdcall LockReadStarveWriter(MY_LOCK* lpLock)
{
KeEnterCriticalRegion();
/// 让等待中的读优先,StarveExclusive使饥饿,使写进程饥饿
/// 有多个线程等待同一资源,当有锁释放的时候,先满足读的线程还是先满足写的线程
ExAcquireSharedStarveExclusive(&lpLock->m_Lock, TRUE);
/// 让等待中的写优先
/// ExAcquireSharedWaitForExclusive(&lpLock->m_Lock, TRUE);
}
/// 用完之后在DriverUnderUnload把锁删掉
VOID __stdcall DeleteLock(MY_LOCK* IpLock)
{
/// 不在卸载的时候删除锁,会蓝屏
ExDeleteResourceLite(&lpLock->m_Lock);
}使用eg:
/// 全局资源,链表
LIST_ENTRY g_WaitList;
/// 代码在多线程环境下,所以需要定义一个锁来保护这个链表
MY_LOCK g_WaitListLock;
/// DriverEntry里通过这个函数初始化锁
InitLock(&g_WaitListLock);
/// 多线程环境里
/// 拿写锁
LockWrite(&g_WaitListLock);
/// 从链表中找到节点
IpWaitEntry = LookupWaitEntryByID(&g_WaitList, IpReply->m_ulWaitID);
/// 修改找到的节点的内容
if (IpWaitEntry != NULL)
{
IpWaitEntry->m_bBlocked = IpReply->m_ulBlocked;
KeSetEvent(&lpWaitEntry->m_ulWaitEvent, O, FALSE);
///return; ///< 这里不能return,因为返回在锁释放之前,之前申请的锁没有释放,会导致死锁(其他进程等到锁)
}
/// 释放锁
UnLockWrite(&g_WaitListLock);
/// 在DriverUnload中调用这个函数删除锁
DeleteLock(&g_WaitListLock);FAST_MUTEX快速互斥锁
-
为什么叫FAST_MUTEX
-
MUTEX与 KSPIN_LOCK自旋锁和ERESOURCE读写锁共享锁相比性能是最差的,所以才出现了FAST_MUTEX,而且在windows内核中基本上都不用MUTEX了
-
用于互斥
-
不会超过APC_LEVEL
-
和KSPIN_LOCK自旋锁一样,是“非递归锁”,即不能递归获得该锁,而Mutex是“递归锁”。
使用方法:
/// 定义一个FAST_MUTEX锁
FAST_MUTEX gSfilterAttachLock;
/// 初始化
ExInitializeFastMutex( &gSfilterAttachLock);
/// 拿锁
ExAcquireFastMutex( &gSfilterAttachLock );
/// ExAcquireFastMutex( &gSfilterAttachLock ); ///< 这里不能两次获取锁,因为和FAST_MUTEX和`KSPIN_LOCK`自旋锁一样,是“`非递归锁`”
//Do something here
...
/// ExReleaseFastMutex( &gSfilterAttachLock ); ///< 这里不能两次释放锁,因为和FAST_MUTEX和`KSPIN_LOCK`自旋锁一样,是“`非递归锁`”
ExReleaseFastMutex( &gSfilterAttachLock);KSEMAPHORE信号量
-
用于同步与多个资源共享访问
-
信号量不是信号
-
信号是发给程序的软中断,比如kill -9杀掉进程
-
信号量可以用来做同步类似KEVENT,但多数情况下的用法是表示一个资源能被多个线程共享,比如你的女盆友只能允许你一个人访问,而老师就可以被多个同学访问
/// 定义一个信号量
KSEMAPHORE kSemaphore;
/// 初始化信号量
KeInitializeSemaphore(
&kSemaphore,
1, ///< 信号量的初始值,资源数
2 ///< 信号量的最大值,可以在初始化的时候把设置为1,1,这样就把信号量退化成了互斥体了,在早期的linux就是通过信号量去模拟互斥体的
);
LARGE_INTEGER waitTime = {0};
waitTime.QuadPart = -1*10000000i64;
/// 消耗资源,对信号量进行减一
KeWaitForSingleObject(&kSemaphore,
Executive,
KernelMode,
FALSE,
&waitTime ///< O,立即返回;
///< NULL,无限等待(如果信号量为0(即没有资源了),函数就会一直等,等有资源了才会返回。);
///< 负数 等待|负数|秒
);
/// 释放资源,对信号量进行加一
KeReleaseSemaphore(&kSemaphore,
1,
IO_NO_INCREMENT,
1,
FALSE);R0同步互斥总结
-
DISRATCH_LEVEL:
-
只能使用SpinLock
-
APC/PASSIVE:
-
互斥: ERESOURCE/FAST_MUTEX
-
同步: KEVENT/KSEMAPHORE
-
R3/R0同步通信:
-
KEVENT
-
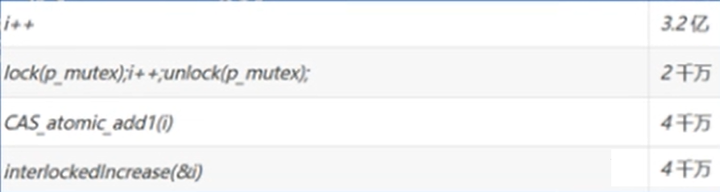
整数增减赋值:
-
InterlockedExchange()(相当于a<-->b交换以Interlocked开头是原子操作,原子操作是不会被打断的)
-
InterlockedIncrement()(相当于i++)
-
在多核多线程下,毫无疑问i++一定要加锁
-
但在单核多线程,也一定要加锁,是因为g_count++,在C语言中是一条指令,但一条指令不代表是原子操作,在编译的时候,实际的被翻译成了多条汇编指令,如果线程在执行这些汇编指令的时候,还没全部执行完就被切换出去了,这样就会出现问题。
/// 对全局资源增减指令,假设g_count为0
g_count++;
/// 对应的汇编指令
/// 把全局资源放在eax寄存器中,准备下一步用eax累加,如果线程A执行到这里的时候时间片用完了,切换之前备份进程上下文(把eax寄存器备份起来,全局资源g_count这时还没发生变化,还是0)
/// A线程切换出去之后,B线程进来了,也把全局资源放在eax寄存器中,执行完整的3条汇编指令之后,全局资源g_count这时发生了变化,变成1,然后B线程被切换出去了
/// A线程被切换回来,恢复A线程的上下文,eax恢复为0,继续执行add eax,1,mov dword ptr[i],eax之后全局资源g_count还是1(正确值应该是2,因为之前B线程已经+1了)
mov eax dword ptr[i]
add eax,1
mov dword ptr[i],eax
R3多线程同步互斥总结
-
Critical Section/Mutex/Semaphore/Event
-
Critical Section与Mutex作用非常相似,但Mutex是可以命名的,也就是说它可以跨越进程使用。所以创建互斥量需要的资源更多,如果只为了在进程内部使用的话(同一进程不同线程中互斥),使用临界区会带来速度上的优势并能够减少资源占用量(不断进行锁的升级)。
-
互斥量(Mutex),信号量(Semaphore), 事件(Event)都可以跨越进程来进行同步数据操作(一个进程创建之后,另外的进程可以通过名字打开它,从而用于进程间的数据同步)
-
通过Mutex可以指定资源被独占的方式使用,但如果一个资源允许N(N>1)个进程或者线程访问,这时候如果利用Mutex就没有办法完成这个要求,Semaphore可以,当作一种资源计数器。
-
因为互斥量是跨进程的,互斥量一旦被创建,就可以通过名字打开它。(FAST_MUTEX不能命名)
Critical_Section(只能同一进程不同线程中互斥)
-
Critical_Section使用
-
InitializeCriticalSection(&m_sec);
-
EnterCriticalSection(&m_sec);
-
LeaveCriticalSection(&m_sec);
-
DeleteCriticalSection(&m_sec);
-
Critical_Section的实现
/// 不能跨进程,只能用于同一进程不同线程中互斥
struct RTL_CRITICAL_SECTION
{
/// Debuglnfo 此字段包含一个指针,指向系统分配的伴随结构,该结构的类型为RTL_CRITICAL_SECTION_DEBUG
PRTL_CRITICAL_SECTION_DEBUG Debuglnfo;
/// LockCount这是临界区中最重要的一个字段。它被初始化为数值-1;此数值等于或大于0时,表示此临界区被占用。当其不等于-1时,OwningThread字段包含了拥有此临界区的线程ID。此字段与(RecursionCount-1)数值之间的差值表示有多少个其他线程在等待获得该临界区。
LONG LockCount;
/// RecursionCount此字段包含所有者线程已经获得该临界区的次数。如果该数值为零,下一个尝试获取该临界区的线程将会成功。
LONG RecursionCount;
/// OwningThread此字段包含当前占用此临界区的线程的线程标识符。此线程ID与GetCurrentThreadld之类的API所返回的ID相同。
HANDLE OwningThread;
/// LockSemaphore它实际上是一个自复位事件(event),而不是个信号。它是一个内核对象句柄,用于通知操作系统:该临界区现在空闲。操作系统在一个线程第一次尝试获得该临界区,但被另一个已经拥有该临界区的线程所阻止时,自动创建这样一个句柄。应当调用DeleteCriticalSection (它将发出一个调用该事件的 CloseHandle调用,并在必要时释放该调试结构),否则将会发生资源泄漏。
HANDLE LockSemaphore;
/// SpinCount仅用于多处理器系统。在多处理器系统中,如果该临界区不可用,调用线程将在对与该临界区相关的信号执行等待操作之前,旋转dwSpinCount次(轮询)。如果该临界区在旋转操作期间变为可用,该调用线程就避免了等待操作(等待的过程是会进入内核的,会睡眠,操作系统会把线程放入等待队列里面去,直到锁释放之后,再通过Semaphore将其唤醒,是很耗时间的)。旋转计数可以在多处理器计算机上提供更佳性能,其原因在于在一个循环中旋转通常要快于进入内核模式等待状态。此字段默认值为零,但可以用InitializeCriticalSectionAndSpinCount API将其设置为一个不同值。
ULONG_PTR SpinCount;
};用Critical_Section实现CAutoLocker(自动锁,类似智能指针)
利用C++的面向对象机制
-
构造函数(对象生成的时候被调用)
-
把拿锁的操作放在构造函数里面,随着对象的构造,拿锁
-
析构函数(对象销毁的时候被调用)
-
把释放锁的操作放在析构函数里面,随着对象的销毁,释放锁
/// 用C++的类封装Critical_Section
/// 还不是自动的,还需要手动调用Lock()和UnLock()
class CLock
{
public:
/// 加锁
void Lock()
{EnterCriticalSection(&m_sec);}
/// 释放锁
void Unlock()
{LeaveCriticalSection(&m_sec);}
/// 在构造函数里面初始化锁
CLock()
{InitializeCriticalSection(&m_sec);}
/// 再析构函数里面删除锁
~CLock()
{DeleteCriticalSection(&m_sec);}
private:
CRITICAL_SECTION m_sec;
};
/// 在封装的CLock基础上继续封装一层
class CAutoLock{
public:
/// 在构造函数里面加锁
CAutoLock(CLock * pLock):m_pLock(pLock) ///< 等价于m_pLock=pLock
{
m_pLock->Lock);
}
/// 再析构函数里面释放锁
~CAutoLock)
{m_pLock->Unlock();}
private:
CLock* m_pLock;
};
///
/// 定义一个全局锁
CLock g_lock;
///使用例子:在函数内部使用CAuroLock
{
/// 生成一个匿名对象,构造对象的时候,初始化锁,加锁
CAutoLock a(&g_lock);
...
}
/// 函数退出后,自动销毁匿名对象,析构函数释放锁,删除锁
/// 与手动加锁相比
/// 优点:自动化
/// 缺点:粒度不好把握,如果{...}内部代码很长,包含循环的情况,锁就迟迟得不到释放,其他线程会等很久,性能下降。
/// 改进方法:在函数内部继续加‘{}’来精准限定锁的范围实现基于双重校验多线程安全的单实例模
-
问题:在多核上,多个线程可能同时创建多个实例,只保存一个实例,造成内存泄漏
-
解决方法:单实例双重校验保证多线程安全
-
第一次创建实例的时候,第一个拿到锁的人才能创建实例
-
加一个自动锁
实现多线程安全的栈操作
-
同时访问栈顶指针会导致程序一致性问题
-
解决方法:访问栈顶指针之前加锁
/// 基于链表的栈
typedef struct _node
{
int value;
struct _node *next;
}node,*pnode;
/// 全局变量栈顶指针没有加锁
node *top = NULL;
/// 改进:定义一个锁来保护全局变量
ICRITICAL_SECTION g_cs;
/// 在创建栈之前,初始化锁
InitializeCriticalSection(&g_cs);
CreateStack();
/// 在销毁栈之后,删除锁
DeleteCriticalSection(&g_cs);
/// 创建两个线程,把出栈和入栈(访问全局变量的操作)用线程去实现
unsigned tid = 0;
HANDLE hArray [2] = {0};
hArray[0] = (HANDLE)_beginthreadex(NULL,
0,
PushProc,
NULL,
0,
&tid);
hArray[1] = (HANDLE)_beginthreadex (NULL,
0,
Pop,
NULL,
0,
&tid);
UINT WINAPI PushProc (LPVOID arg)
{
/// 如果当前有其他线程在堆栈进行操作时,则等待该线程操作完栈(栈顶指针释放),当前进程才可以对栈进行操作
EnterCriticalSection(&g_cs);
for (int i=0;i<100;i++)
{
Push(i);
}
LeaveCriticalSection(&g_cs);
return 1;
}
UINT WINAPI PopProc(LPVOID arg)
{
int v = 0 ;
/// 同上
EnterCriticalSection(&g_cs);
while(!IsStackEmpty())
{
Pop (&v);
printf ("%d ", v);
}
LeaveCriticalSection(&g_cs);
printf("\n") ;
return 1 ;
}
/// 最终的测试效果是,pop的时候打印输出结果是99-0,证明push也是完整的从0-99,所以加了锁之后的push和pop对全局资源栈顶指针的访问时是串行的Mutex(同一进程或者跨进程互斥)
-
Mutex使用
/// 创建一个Mutex,Mutex是一个HANFDLE类型
HANDLE hMutex = NULL;
hMutex = CreateMutex(NULL, FALSE, NULL);
/// 加锁
WaitForSingleObjeat(hMutex,INFINITE);
//WaitForMultipleObjects(2, hArray,TRUE,INFINITE);
/// 放锁
ReleaseMutex(hMutex);
///关闭
CloseHandle(hMutex);Mutex实现多线程安全
-
线程忘记放锁,但是线程结束之启,会自动放锁
/// 这里用到了WIN32的函数,需要把这些头文件包含进来
#include <windows.h>
#include <process.h>
#include <conio.h>
/// 要保护的全局变量
int g_iTotal = 0;
/// 创建一个Mutex,Mutex是一个HANFDLE类型
HANDE g_hMutex = NULL;
/// 创建一个Mutex来保护g_iTotal
g_hMutex = CreateMutex(NULL,FALSE,NULL);
/// 创建两个线程,func1,func2
unsigned tid = 0;
HANDLE hArray [2] = {0};
hArray[0] = (HANDLE)_beginthreadex(NULL,
0,
func1,
NULL,
0,
&tid);
hArray[1] = (HANDLE)_beginthreadex (NULL,
0,
func2,
NULL,
0,
&tid);
UINT WINAPI func1(LPVOID arg)
{
/// 如果当前有其他线程在堆栈进行操作时,则等待该线程操作完栈
for (int i=0;i<5;i++)
{
WaitForSingleObjeat(hMutex,INFINITE);
g_iTotal++;
printf("t1:%d\n",g_iTotal);
/// 等待1s
Sleep(1000);
//ReleaseMutex(hMutex);
/// 测试时发现即使在func1中没有放锁,func2也是可以对g_iTotal进行操作,这不是想要的结果,期待的情况应该是func2也是无法对g_iTotal进行操作,才是互斥。但微软提供的文档示例是可以用Mutex实现互斥的:https://msdn.microsoft.com/en-us/library/windows/desktop/ms686927(v=vs.85).aspx
/// Mutex的互斥效果没有问题!是因为func1退出了,锁才被释放,func2等待func1退出之后,就获得了锁,从而才能对g_iTotal进行操作。
/// 验证:等待输入字符,func1一直没有退出,可以发现func2的确一直在等待(此时是死锁),直到按下任意键后,func1退出,func2才能对g_iTotal进行操作。所以Mutex的互斥效果是没有问题的
//_getch()
}
return 1;
}
UINT WINAPI func2(LPVOID arg)
{
/// 同上
for (int i=0;i<5;i++)
{
WaitForSingleObjeat(hMutex,INFINITE);
g_iTotal++;
printf("t2:%d\n",g_iTotal);
ReleaseMutex(hMutex);
}
return 1 ;
}
CloseHandle(hArray[0]);
CloseHandle(hArray[1]);
/// 关闭Mutex
CloseHandle(hMutex);EVENT(用于线程之间的同步)
/// 售票员和司机的例子
/// 这里用到了WIN32的函数,需要把这些头文件包含进来
#include <windows.h>
#include <process.h>
#include <conio.h>
/// 创建一个Event,Event是一个HANFDLE类型
HANDE g_hEvent = NULL;
/// 创建一个、Event来进行同步
g_hEvent = CreateEvent(NULL,FALSE,NULL);
/// 创建两个线程,Driver,Seller
unsigned tid = 0;
HANDLE hArray [2] = {0};
hArray[0] = (HANDLE)_beginthreadex(NULL,
0,
Driver,
NULL,
0,
&tid);
hArray[1] = (HANDLE)_beginthreadex (NULL,
0,
Seller,
NULL,
0,
&tid);
UINT WINAPI Driver(LPVOID arg)
{
/// 如果当前有其他线程在堆栈进行操作时,则等待该线程操作完栈
for (int i=0;i<5;i++)
{
printf("driver:waiting to driver...\n");
/// 等待seller卖完票
WaitForSingleObjeat(hEvent,INFINITE);
printf("driver:begin to driver\n");
printf("driver:bus goes\n");
}
return 1;
}
UINT WINAPI Seller(LPVOID arg)
{
for (int i=0;i<100;i++)
{
printf("seller:%d ticket sold\n",i);
/// 等待1s
Sleep(1000);
}
printf("seller:ticket finished,close the door\n");
/// seller卖完票了,通知Driver关门开车
SetEvent(g_hEvent);
return 1 ;
}
CloseHandle(hArray[0]);
CloseHandle(hArray[1]);
/// 关闭Mutex
CloseHandle(hEvent);进程通信
详情请看:超详细的linux进程间通信及其优缺点
无锁化编程
什么是无锁化编程
-
无锁化编程(Lock-Free):不使用锁的情况下实现多线程之间对变量进行同步和访问的一种程序设计实现方法,Lock-Free的程序不包括锁机制,但不包括锁机制的程序不一定是lock-free的。
-
如何判断代码是不是无锁化编程

-异步编程:线程在调用函数的时候,不管这个函数有没有拿到数据,会立即返回,后面通过回调函数或者是事件机制来拿到函数执行的结果。异步比同步效率要高。
-
同步编程:线程在调用函数的时候,只要这个函数没有拿到数据,就一直在哪里等待,不会立即返回,直到拿到数据才会返回。
-
eg:A在微信上向女盆友B发消息之后,A去做其他事情了,B给A回消息,会有消息声音提醒A,A打开微信拿到B回复的消息
-
eg1:完成端口模型
-
同步阻塞编程(Block)
-
基于锁的(lock-based)
-
阻塞的意思是,会睡眠让出CPU,有结果的时候就会被唤醒,一般用于读之前不确定有没有结果数据,使用阻塞比较好。
-
eg:A在微信上向女盆友B发消息之后,A抱着手机睡着了,直到B给A回消息,会有消息声音吵醒A,A醒来打开微信拿到B回复的消息
-
同步非阻塞编程(Non-blocking Synchronization) :根据粒度不同分为以下几类
-
eg:女盆友B在微信上向A发消息之前确定A是在线的,B发完消息后,A秒回B,B直接看到到A回复的消息
-
eg1:网络中的select模型、epoll模型,多路复用,多个IO复用同一个Event,只有Event会阻塞,读写不会阻塞
-
非阻塞的意思是,不会睡眠,一直在等,直到拿到结果,一般用于读之前明确知道的是有结果数据的,而且很快能拿到结果。
-
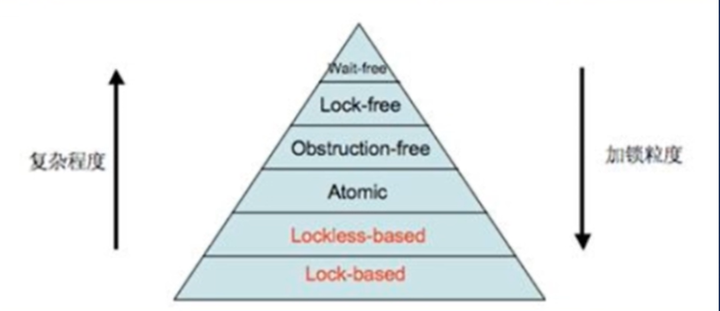
无等待Wait-free:所有线程可以在有限步之内结束
-
无锁Lock-free:任何时刻至少有一个线程可以在有限步内完成操作。
-
无阻碍Obstruction-free:一个线程,在其它线程都暂停(无竞争)的情况下,可以在有限步之内结束。
-
所有wait free都是lock-free,所有的lock-free都是obstruction-free
-
无锁编程涉及到的技术要点
-
原子操作(atomic operations)
-
内存屏障(memory barriers)
-
内存顺序(memory order)
-
指令序列一致性(sequential consistency)
-
ABA现象处理
-
加锁虽然数据安全了,但在加锁的区域内,没有并发了,只能串行访问(只要一个线程访问,其他线程必须阻塞),程序性能大打折扣。
-
在多线程环境下,也可以不加锁(无锁化编程),其通过乐观锁,自旋锁达到数据安全的访问
-
加锁和无锁是相互补充,无法完全将另一种取代,在批处理的情况下,无锁化优化空间比加锁要小
加锁带来的问题
-
死锁
-
夺资源而造成的一种互相等待的规象,若无外力作用,它们都将无法推进下去。
-
死锁不能自行解开
-
活锁
-
进程(或线程)在执行过程中没有被阻塞,由于某些条件没有满足导致一真重复尝试,失败,尝试,失败。比如某些重试机制导致一个交易(请求)被不断地重试,而每次重试都是失败的(线程在做无用功)
-
eg:小狗追着自电的尾巴咬,虽然一直在咬却一直没有咬到;两个人在馆路相遇,同时向一个方向避让,然后又商另一个方向避让,如此反复。
-
活锁有可能自行解开
-
饥饿:一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态。
-
如果事务T1封锁了数据R.事务2又请求封锁R,T2等待T3也请求封锁R,当T1释放R上的封锁后、系统首先批准了T3的请求,12仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求......T2可能永远等待。(解决办法:先来先服务)
-
优先级翻转:T2如果优先级高,就会造成优先级翻转,造成高优先级任务被许多具有较低优先级任务阻塞,实时性难以得到保证。解决方法:优先级天花板;优先级继承等。
-
性能下降
-
拿锁放锁耗时
-
拿锁期间无法并发,阻塞了其他线程
死锁例子
-
A、B两把锁拿锁的顺序
-
应该按照统一顺序去拿锁,否则容易造成循环,造成死锁
-
每一辆车类似一个线程,每一条道路类似一个全局资源,每辆车都占据别人等待的资源(加锁),形成循环拿锁会导致拥堵(死锁)

-
进程在执行过程中,由于竞争资源而造成的、种阻塞的现象。若无外力作用,它们都将无法推进下去
死锁的发生必须具备以下四个必要条件。
-
互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求著只能等待,直至占有资源的进程用毕释放。
-
请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源己被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。(A,B两把锁拿和放的顺序:所有进程都应该按照:拿A,拿B,放B,放A的顺序)
-
不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
-
环路等待条件:指在发生死锁时,必然存在—个进程程-资源的环形链,即进程集合P0,P1,P2,…, Pn}中的P0正在等待一个P1占用的资源:P1正在等待P2占用的资源,…, Pn正在等待已被P0占用的资源。
-
Dijkstra哲学家用餐问题(5个哲学家,5只筷子)
-
服务生解法:哲学家必须经过他的允许才能拿起餐叉
-
资源分级解法:按照某种规则编号为1至5,每一个哲学家总是先拿起左右两边编号较低的餐叉,再拿编号较高的餐叉。用完餐叉后,他总是先放下编号较高的餐叉,再放下编号较低的餐叉。在这种情祝卡,当四位哲学家同时拿起他们手边编号较低的餐叉时,只有编号最高编号的餐叉留着桌上,从而第五位哲学家就不能再使用任何一只餐叉了(第五位哲学家拿0号餐叉,但0号餐叉已经被第一位哲学家拿走了),而且只要一个哲学家能使用最高编号的餐叉(第四位哲学家),所以他能使用两只餐叉用餐,当他吃完后,他会放下编号最高的餐叉,再放下编号较低的餐叉,从而让另一位哲学家拿起后边的这只开始吃东西
如何解决死锁问题
-
verifier勾选死锁检测,加载驱动如果有死锁会蓝屏,在windbg加载dump文件,执行!deadlock分析哪个地方发生死锁
-
在windbg中attch进程,然后在执行!locks 列举进程中锁的使用情况,应用层和内核层都可以用
-
看LockCount不为0的锁的占用者
-
~查看是进程中的哪一个线程占用
-
~n kb看占用锁线程的栈,画出进程程-资源请求图看是否形成环
工作者消费者例子
@todo
悲观锁和乐观锁
-
悲观锁:总做最坏的打算(悲观),每次访问数据时都认为别人会修改,所以每次在拿数据的时候都会上锁,这样其他人想访问这个数据就会阻塞直到获得该锁为止关系型数据库里的行锁,表锁等,读锁,写锁等,都是悲观锁,即在做操作之前先上锁Java里面的同步原语synchronized和ReentrantLock的实现也是悲观锁
select" from mytable `for update`
public syhchronized void func(){...}-
乐观锁:每次访问数据的时候都认为别人不会修改(乐观),所以不上锁.乐观锁的缺点是不能解决脏读的问题,所以在更新时需要判断此期问有没有别人更新这个数据需要其他机制辅助,比如使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高效率。
-
CAS: java.util.concurrent.atomic包下面的原子变量类
-
update mytable set Name='tom',version=version+1 where ID=#{id} and version=#{version}
-
如果并发量不大且不允许脏读,可以使用悲观锁解决并发问题。但如果系统的并发非常大的话,悲观锁定会带来非常大的性能问题,这个时候我们就要选择乐观锁。
无锁化编程的常见方法
-
Atomic原子操作,针对计数器,可以使用原子加,比如Atomiclnteger_sync_fetch_and_add
-
CAS(Compare and Swap)
-
用一个循环看观察变量,如果变量在我访问变量这段时间内没有被别人修改,我就放心去修改变量
-
比如:cpu指令级别,CMPXCHG指令,比较看内存的值有没有被修改,如果发现值在这段时间没有被修改,就可以放心去修改这个值
-
会有一个问题,别的线程该了这个值之后又改回来了,这时候,通过这个方式就发现不了,这时候需要加入版本控制
-
Ring Buffer环形队列
-
使用数组实现队列构成一个环,环形队列
-
适合一个线程负责读一个线程负责写的情况,不需要加锁 -RCU(Read-Copy-Update) ,新旧副本切换机制,对于旧副本可以采用延迟释放的做法。
原子操作
无锁化编程之CAS操作
-
非原子操作 /// i++对应三条汇编指令,所以i++执行中间是可以被打断的 /// 读、改、写(回) /// AT&T汇编,赋值方向是从左往右 movl i,%eax addl $1,%eax movl %eax,i
-
i=0;
-
i++;
-
原子操作:在执行完毕之前不会被任何其它任务或事件中断的一系列操作它是非阻塞编程的基础,没有原子操作,会因为中断异常等各种原因引起数据状态的不一致从而影响到程序的正确。
硬件层面原子操作:
-
基本的内存操作的原子性: -CPU保证处理器从内存当中读取或者写入一个字节的行为肯定是原子的。
-
其他CPU处理器不能访问这个字节的内存地址
-
复杂的内存操作CPU不能保证其原子性
-
比如跨总线宽度或者跨多个缓存行(Cache Line) ,跨页表的访问
-
CPU指令集中的原子操作指令保证:
-
如X86平台下中的是CMPXCHG,就是一种CAS原子操作,属于Read-Modify-Write (RMW)l类型
操作系统层面原子操作(基于硬件层面的原予操作):
-
LINUX: atomic_set/and/inc
-
Windows: InterlockedExchange/lnterlockedlncrement
-
各种开发语言中(C,C++,java)基于操作系统提供的接口(跨平台)
原子操作的顺序性问题
-
原子操作不仅要保证操作的原子性,还要考虑在不同的语言和内存模型下如何保证操作的顺序性,编译时和运行时的指令重排,内存顺序冲突(Memory order violation) 等问题。
-
原子性确保指令执行期间不被打断,要么全部执行,要么根本不执行
-
顺序性确保即使两条或多条指令出现在独立的执行线程中或者独立的处理器上时,保持它们本该执行的顺序
伪代码:
x=y=0;
线程1:
x=1;
r1=y;
线程2:
y=2;
r2=x;-
假设在编译器、CPU不对指令进行重排,且两个线程交织执行(假设以上四条语句都是原子操作)时共有4!/(2!*2!)=6种情况

-
再考虑乱序执行的情况下: Core1的指令预处理单元看到线程1的两条语句没有依赖性(不管哪条语句先执行,在两条指令语句完成后都会得到一样的结果),会先执行r1=y再执行x=1,或者两条指令同时执行。Core2也一样。这样一来就有可能出来个r1=r2=0的结果。
原子操作顺序性问题解决方法
-
加锁,串行执行,但效率不高,优先级反转等问题
-
原子操作,C++11内存模型
-
synchronized-with机制 假设X是一个原子变量。如果线程A写了X,线程B读了x,那么线程A、B间存在synchronized-with关系,它能保证对X的读和写是互斥的。
-
happens-before机制
i = 0;
i = 1; ///< 线程A执行
j = i; ///< 线程B执行
j是否一定等于1呢?假定线程A的操作(i=1)happens-before线程B的操作(j=i) ,那么可以确定线程B执行后即使在乱序等情况下j=1一定成立
-
C++11std:atomic对不同的内存order对原子性和synchronized-with和happens-before机制有不同的定义
/// 再宽松内存模型下只保证原子性,不保证顺序性
auto r1 = y.load(std::memory_order_relaxed);
x.store(r1, std::memory_order_relaxed);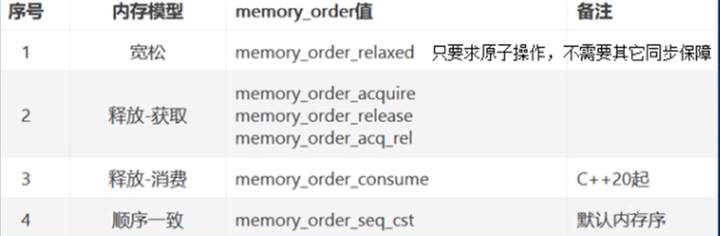
CAS操作
无锁化编程之CAS操作
-
CAS(Compare and Swap,即比较并替换),wikipedia中对于CAS的定义为:
-
1、是一种多线程中的原子操作
-
2、类似于乐观锁,只有当读取的值和预期值相等(j就认为没有其他线程修改过当前的共享资源,但如果有线程修改了共享资源再改回来,乐观锁就还是认为没被修改了)时才进行赋新值
-
3、返回结果必须表明是否成功
-
CAS操作包含三个操作数s内存地址(V)、预期原值(A)、新值(B)。如果内存地址的值与预期原值相同,那么处理器会自动将内存的值更新为新值。否则,处理器不做任何操作。无论哪种情况,处理器会在CAS指令之前返回该地址的值。CAS有效地说明了"我认为地址V应该包含值A;如果包含该值,则将B放到这个地址;否则,不要更新该地址,只告诉我这个地址现在的值即可"
-
代码:
/// CAS封装成一个函数,整个过程是原子操作,不可以被打断
/// CAS封装程一个函数,但函数里面有这个多条指令,如何能保证整个函数是原子操作呢?
/// CAS是系统原语,CAS操作是一条CPU的原子指令,所以不会有线程安全问题
/// 在JDK1.5之后,Java程序中才可以使用CAS操作,该操作由sun.misc.Unsafe类里面的compareAndSwapInt()和compareAndSwapLong()等几个方法包装提供,虚拟机在内部对这些方法做了特殊处理,即时编译出来的结果就是一条平台相关的处理器CAS指令,没有方法调用的过程,或者可以认为是无条件内联进去了。
bool compare_and_swap(int *reg,int oldval,int newval)
{
int reg_val = *reg; ///< 把内存地址的值读出
/// 轮询直到成功才返回
while(1){
if(reg_val == oldval) ///< 把读出的值和期望的值做比较
{
*reg = newval; ///< 假设读出的值和期望的值一致,认为没有人对当前的地址对应的内存进行修改,把新值写入当前内存
return true;
}
}
return false;
}几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是CMPXCHG汇编指令
-
适用场景: CAS适合简单对象的操作,比如布尔值、整型值等; CAS适合冲突较少的情况,如果太多线程在同时自旋,那么长时间循环会导致CPU开销很大;
CAS在各个平台的支持
-
Linux的CASGCC4.1+版本中支持CAS的原争操作
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval,...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newal,...)
```
- 2) `Windows的CAS`
```c
InterlockedCompareExchange(
__inout LONG volatitle *Target,
__in LONG Exchange,
__in LONG Comperand);-
C++11中的CAS
/// C++11中的STL中的atomic类的函数可以跨平台,但底层还是根据不同系统,调用系统的CAS
template class <T>
bool atomic_compare_exchange_weak(std:atomic<T> *obj,T* expected,T desired);
template class<T>
bool atomic_compare_exchange_weak(volatile std::atomic <T> *obj,T* expected,T desired);Java基于CAS的应用1:Atomic
-
Java并发包中许多Atomic的类的底层原理都是CAS。在java.util.concurrent包中大量实现都是建立在基于CAS实现Lock-Free算法上,没有CAS就不会有此包。java.util.concurfent.atomic提供了基于CAS实现的若干原语
/// 原子类型整型类,初始值是5
Atomiclnteger atomiclnteger = new Atomiclnteger(5);
/// CAS操作,把值改为10
atomiclnteger.compareAndSet(5,10);-
getAndAddInt,incrementAndGet在底层Unsafe类中的代码,运用到了CAS
/// getAndAddInt的实现
public final int getAndAddInt(Object obj, long obj_addr,int val) {
int old;
do{
old = this.getIntVolatile(obj,obj_addr);
}while(!this.compareAndSwapInt(obi,obj_addr,old, old + val)); ///< CAS
return old;
}
/// incrementAndGet的实现
public final int incrementAndGet(){
for (;;){
int current = get();
int next = current + 1;
/// CAS
if(compareAndSet(current,next))
{
return next;
}
}
版权所有,```
##### Java基于CAS的应用2:自旋锁
- 自旋锁也用到了CAS
```java
/// 自选锁的实现
public class SpinLock
{
/// 拥有自旋锁的线程的句柄或者id或者对象
private AtomicReference<Thread> owner = new AtomicReference<>();
/// 次数,表示自旋锁可以被同一线程可以递归地获取多少次
private int count =0;
/// 加锁
public void lock()
{
/// 获取当前想要获取这把自旋锁的的线程
Thread current = ThreadcurrentThread();
/// 如果该线程已经拥有这把自旋锁,统计,然后直接返回
if(current == owher.get())
{
count++;
return;
}
/// 如果该线程没有拥有这边自旋锁,调用CAS,如果为NULL(当前没有线程占用这把自选锁),则设置为current的线程,否则就在while轮询等待,直到拿到锁
while(!owner.compareAndSet(null,current)){}
}
/// 同上
public void unlock()
{
Thread current = Thread.currentThread();
if(current == owner.get()
{
if(count!=O)
{
count--;
}
else
{
owner.compareAndSet(current,null);
}
}
}
}Java多线程中synchronized锁升级
synchronized锁升级原理在锁对像的对象头里面有一个threadid字段,在第一次访问的时候threadid为空,jvm让其持有偏向锁(实际上没有加锁,只是标记了一下),并将threadid设置为其线程id,再次进入的时候会先判断threadid是否与其线程id一致,如果一致则可以直接使用此对象;如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁,执行一定次数之后,如果还没有获取到要使用的对象,此时就会把锁从轻量级升级重量级锁(进入系统内核,放入等待队列,由操作系统安排),此过程就构成了synchromized锁的升级。
-
锁的升级的目的:锁升级是为了减低了锁带来的性能消耗。在Java 6之后优化 synchronized的实现方式,使用了偏向锁升级为轻量级锁再升级到重量级锁的方式,从而减低了锁带来的性能消耗。
-
在JavaSE1.6之后进行了生要包括为了减少获得锁和释放锁带来的性能消耗,而引入的偏向锁和轻量级锁以及其它各种优化之后,变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
CAS面临的问题
-
1.ABA问题:如果内存地址V初次读取的值是A,在CAS等待期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过(手提箱例子,把手提箱的数据读取,然后再把手提箱放回去)。ABA问题以及解决:使用带版本号的原子引用AtomicStampedRefence<V>
/// 不带版本号
AtomicReference<String> atomicReference = new AtomicReference<>("A");
/// 带版本号
AtomicStampedReference <String> stampReference = new AtomicStampedReference<>("A",1);
/// 线程1:
/// 有版本号的初始版本是1
int stamp = stampReference.getStamp( );
/// 无版本号的原子操作,先把A设置变成B
atomicReference compareAndSet("A","B");
/// 无版本号的原子操作,先把B设置变成A
atomicReference compareAndSet("B","A");
/// 无版本号的原子操作,先把A设置变成B,stamp+1
stampReference.compareAndSet("A","B",stamp,stamp + 1);
/// 无版本号的原子操作,先把A设置变成B,stamp再+1
stampReference.compareAndSet("B","A" ,stamp+ 1,stamp+ 2);
/// 有版本号的最终版本是3
stampReference.getStamp();
线程2:
/// 拿到版本号是1
int stamp = stampReference.getStamp( );
/// 无版本号的原子操作,先把A设置变成C,因为它不知道中间A变成了B又恢复成A,所以操作可以执行
atomicReference.compareAndSet("A","C");
/// 拿到的值是C,说明该操作成功了
atomicReference.get( );
/// 线程2 的版本号是1,而线程1已经把版本号改成3了,1!=3,操作无法执行
stampReference compareAndSet("A","C",stamp,stamp + 1);
/// 拿到的值还是原来A,说明该操作失败了
stampReference getReference( );//A-
2.高并发下,反复更新某个变量,却不成功,一直自旋(不会阻塞不会睡眠),导致CPU负载过高
-
3.只保证对一个变量进行原子操作,多个变量无能为力,只能加锁了。
CAS实现无锁队列
-
判断队列是否为空
-
常规队列:队头指针和队尾都为NULL
-
无锁队列:队头指针和队尾都指向一个节点,这个结点的next==NULL
/// 出队
/// 如果队列为空,直接返回出队失败
/// 否则,修改front指向待出队结点的下一结点,返回出队结点的值,删除出队的结点
int cas_deque(LinkQue *q, int *e)
{
QNode *tmp=NULL;
do
{
if (is_que_empty(q))
{
return(O);
}
/// 拿到front的下一个结点
tmp = q->front->next;
}
while(!CASH(long *)(&(q->front->next)),(long)tmp,(long)temp->next)); ///< 用CAS把结点摘掉,即修改front指向待出队结点的下一结点
*e = tmp->data;
free(temp);
returnt 1;
}
/// 入队
/// 创建一个结点
/// 把结点插入到rear的后面
/// 把rear指向新的结点
void cas_enque(LinkQue *q, int e)
{
/// 创建一个结点
QNode newNode = (QLode *)malloc(sizeof(QNode));
newNode->data = e;
newNode->next = NULL;
QNode *tmp;
do
{
tmp = q->rear;
}
while(!CAS((long *)(&(tmp->next)),NULL, (long)newNode)); ///< 把结点插入到rear的后面
/// 把rear指向新的结点
Pq->rear = newNode;
}-
同理无锁也可以实现无锁的栈
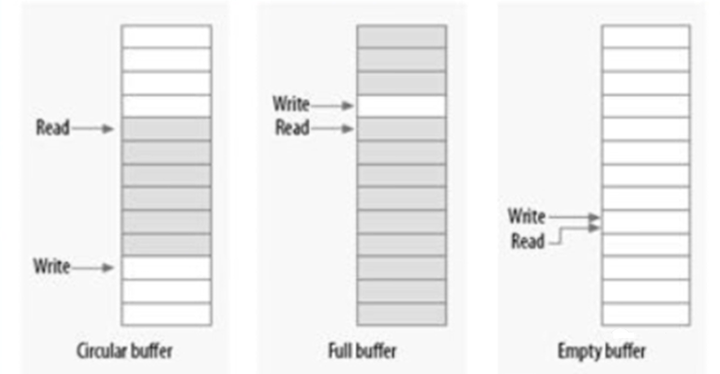
环形缓冲区(ring buffer)
无锁编程之环形缓冲区(ring buffer)
-
如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(Ring Buffer)生产者将数据放入数组的尾端,而消费者从数组的另一端(头部)移走数据,当达到数组的尾部时,生产者绕回到数组的头部。
-
写入索引(或指针,rear)只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据。
-
同理,读取索引(front)也只允许消费者访问并修改。
-
环形缓冲区,如果生产者和消费者的速度不一致,速度差*足够长的时间 > 环形缓冲区长度,不会出问题吗?
-
满了肯定不能再生产了
-
同理,空了肯定不能再读了
-
基于数组的循环队列
int EnQueue(int value); ///< rear = (rear+1) % MAXSIZE;
int DeQueue(int *value); ///< front = ( front+1) % MAXSIZE
int IsQueueFull(); ///< (rear+1) % MAXSIZE == front
int IsQueueEmpty(); ///< rear==front-
一般情况
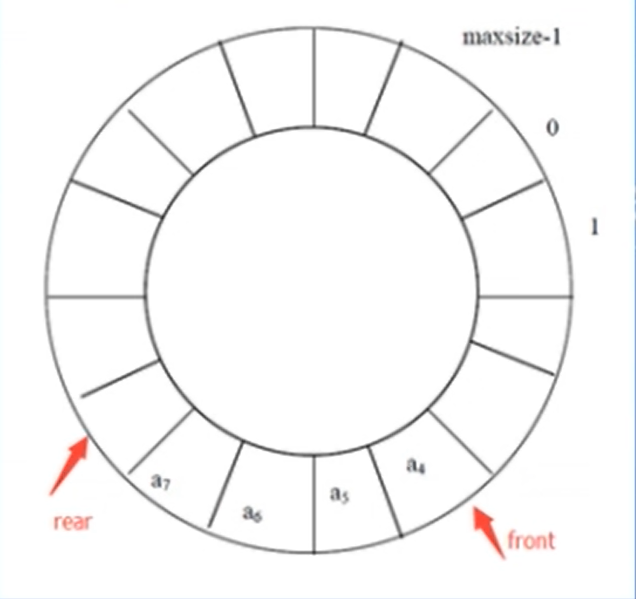
-
队空

-
队满

Linux kfifo
-
在Linux内核文件kfifo.h和kfifo.c中,定义了一个先进先出环形缓冲区实现kfifo。
-
kfifo缓冲区长度为2的幂。读、写指针分别是无符号整型变量。
-
把读写指针变换为缓冲区内的索引值:指针值 & (缓冲区长度 - 1)。比求余操作高效。
-
读指针和写指针地址关系:读指针 + 缓冲区存储的数据长度 = 写指针
-
kfifo的写操作时计算缓冲区剩余可写空间长度:len = min{待写入数据长度,缓冲区长度 - (写指针-读指针)} 防止溢出
-
然后分两段写入数据:
-
第一段是从写指针开始向缓冲区末尾方向;
-
第二段是从缓冲起始处写入除下的可写入数据,这部分前能数据长度为即并无实际数据写。
RCU(Read-Copy Update)
无锁编程之RCU
-
RCU (Read-Copy-Update) 主要针对链表(堆上分配的内存),读取数据时不对链表进行加锁,允许多个线程同时读取,而只能一个线程对链表进行修改(加锁),在Linux内核中有广泛应用
-
适用于读多写少,比如浏览电脑的目录
-
RCU的实现需要考虑:
-
宽限期:在读取一个节点过程中,另外一个线程删除了这个节点。删除线程可以把这个节点从链表中移除(remove),但不能立即销毁它(free),必须等到所有的读取线程完成后。这个过程称为宽限期(Grace period)。
-
节点完整性:如果读线程读到了另一线程插入的一个新节点,需要保证读线程读到的这个节点的完整性。
-
链表完整性:写线程新增或者删除一个节点,不会导致遍历一个链表从中间断开。但并不保证一定能读到新增的节点或者不读到要被删除的节点。
宽限期
-
如果读线程执行到此处,时间片到了被切换出去,写线程把这个节点修改或者删除释放掉了,读线程再切换回来,继续往下执行会出问题,数据被修改了或者访问一个无效内存奔溃
/// 伪代码
node *g_data;
DEFINE_SPINLOCK(mutex};
/// 读线程
void work_read(void)
{
node *fp = g_data;
/// 如果读线程执行到此处,时间片到了被切换出去,写线程把这个节点修改或者删除释放掉了,读线程再切换回来,继续往下执行会出问题,数据被修改了或者访问一个无效内存奔溃
if( fp != NULL )
{
dosth(fp->a,fp->b,fp->c);
}
}
/// 写线程
void work_update(node* new_fp)
{
/// 拿到锁
spin_lock(&mutex);
node *old_fd = g_data;
g_data = new_fp;
/// 释放锁
spin_unlock(&mutex);
}-
改进:引入宽限期
/// 伪代码
void work_read(void)
{
rcu_read_lock(); ///< 帮助检查宽限期是否结束
nodeNfp = g_ data;
if( p!= NULL) ///< 此处切换
{
dosth(fp->a, fp->b, fp->c);
}
rcu_readunlock();
}
void work_ update(node * new_ fp)
{
spin_lock(&mutex);
node *old_fp = g_data;
g_data = new_fp;
spin_unlock(&mutex);
synchronize_rcu(); ///< 宽限期开始,等待所有线程rcu_read_unlock();
kfree(old_fp);
}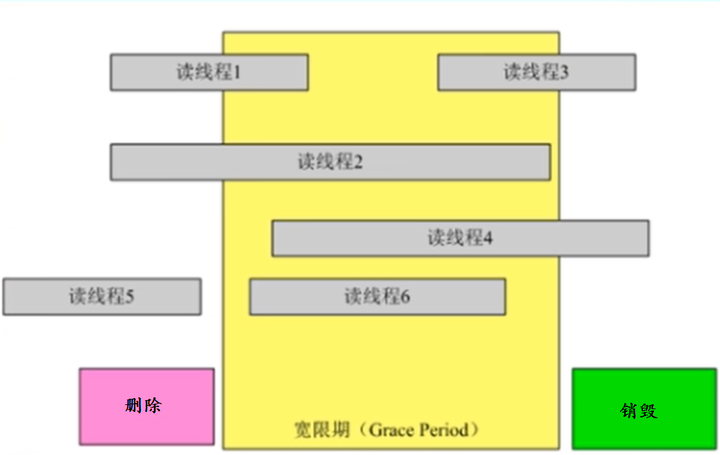
-
宽限期只由线程1和线程2决定
节点完整性问题
/// 读线程
void work_read(void)
{
rcu_read_lock(); ///< 帮助检查宽限期是否结束
node *fp = g_data;
///< 由于程序的乱序执行,有可能这部分指令先于rcu_read_lock()执行,情况1:fp有可能是之前指向的老节点的数据
/// 情况2:有可能有一部分指向老节点,而有一部分指向新节点的数据,因为work_update会修改g_data = new_fp
if( fp != NULL )
{
dosth(fp->a, fp->b, fp>c);
}
rcu_read_unlock();
}
/// 写线程
void work_update(node * new_fp)
{
spin_Lock(&mutex);
node *old_fp = g_data;
new_fp->a =...
new_fp->b =...
new_fp->c =...
g_data = new_fp; ///< 乱序执行,可能会先于前面new_fp->b等赋值指令,与读线程结合,有可能读线程访问的时候,a初始化了,c也初始化了,但b没有初始化,这也是节点的不完整性,情况3
spin_unlock(&mutex);
synchronize_rcu(); ///< 宽限期开始,等待所有线程
kfree(old_ fp);
}
/// 问题1: work_read(void)乱序执行,导致部分数据old和new
node *fp = rcu_dereference(g_data); ///<替换node *fp= g_data,即订阅系统
/// 问题2:work_update乱序执行,导致部分数据初始化和部分数据未初始化
rcu_assign pointer(g_data,new_fp); ///< 替换g_data = new_fp; ,保证执行顺序,即发布系统链表完整
-
插入节点: 先new->next=A;再Head->next=new;
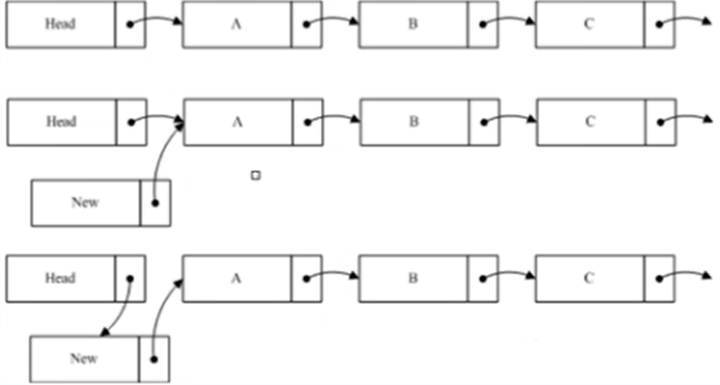
-
删除节点: 先A->next=C;保持B->next=C;宽限期保证读B的线程可以继续访问后续节点。

无锁编程与有锁编程性能对比
-
在性能上基于CAS实现的硬件级的互后,其单次操作性能比相同条件下的应用层的较为高效,但当多个线程并发时,硬件级的互斤引入的消耗一样很高(类似spin_ lock)。无锁算法及相关数据结构并不意味在所有的环境下都能带来整体性能的极大提升。循环CAS操作对时会大量占用cpu,对系统时间的开销也是很大。这也是基于循环CAS实现的各种自旋锁不适合做操作和等待时间太长的并发操作的原因。而通过对有锁程序进行合理的设计和优化,在很多的场景下更容易使程序实现高度的并发性。
-
只有少数数据结构可以支持实现无锁编程,比如队列、栈、链表、词典等
-
通过对锁之间的数据进行批处理,可以极大的提高系统的性能,而使用原子操作,则无法实现批处理上的改进
/// 加锁与批处理
lock();
/// 当循环越大,与原子操作相比,加锁程序的系统性能越强
for(k=0;k<100;k++)
i++;
unlock();
/// CAS原子操作,没办法优化批处理
for(k=0;k<100;k++)
InterlockedIncrement(i);-
当多个线程并发时,硬件级的互斥引入的代价与应用层的锁争用同样令人碗惜。因此如果纯粹希望通过使用CAS无锁算法及相关数据结构而带来程序性能的大量提升是不可能的,硬件级原子操作使应用层操作变慢,而且无法再度优化。相反通过对有锁多线程程序的良好设让人可以使程序性能没有任何下降,可以实现高度的并发性。
-
但是我们也要看到应用层无锁的好处,比如不需要程序员再去考虑死锁、优先级反转等问题,因此在对应用程序不太复杂,而对性能要求稍高时,可以采用有锁多线程。而程序较为复杂,性能要求满足使用的情况下,可以使用应用级无锁算法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!