Oracle开发经验总结
文章目录
- 1. 加注释
- 2. 增加索引
- 3. nvl(BOARDCODE,100)>00
- 4. 去掉distinct可以避免hash比较,提高性能
- 5. like模糊查询优化(转化为instr()函数)
- 6. SQL计算除数为0时,增加nullif判断
- 7. 分页
- 8. 查看执行计划
- 9. <if test="productCode != null and productCode !='' ">相关问题
- 10. in (null) 不能成功
- 11. oracle中不存在反引号`,存在会报错
- 12. 扩容sql命令
- 13. 联合索引
- 14. oracle索引名全库唯一,不像mysql全表唯一就可以
- 15. impala与oracle的不同
- 16. sql动态语句
- 17. oracle dml才加commit,impala和mysql不需要commit
- 18. 备份数据
- 19. 查看索引信息
- 20. 清缓存
- 21. 给数据库加空间
- 22. 重启oracle
- 23. impala dm dataMarket 数据集市层
- 24. 时间比较
- 25. 登录
- 26. clob blob
- 27. 查询数据库连接数 设值为600个连接没问题
- 28. oracle 查询sql的执行频率/次数
- 29. 查找最近一段时间,最消耗CPU的SQL语句及会话信息
- 30. 查询正在运行的sql、解锁sql
- 31. 查看oracle数据库的连接数和会话
- 32. sqlplus 查看sql语句的执行情况
- 33. oracle实例的内存(SGA和PGA)调整
- 34. dump备份、删除用户、创建用户
- 35. 除了在java配置文件中设置连接数,oracle数据库还有一个连接数上限值,默认是600,可以调整到1000多
- 36. with temp as 优化
- 37. in中结果集大小问题
- 38. 查看内存空间
- 39. 查询表空间使用率信息
- 40. 排序分页
- 41. 查询用户下的索引建造语句
- 42. 最后的/要加,是在sqlplus上执行,不加它的后面的语句不会执行,在dbeaver上不能这样使用,会执行报错,另外在sqlplus中执行多个语句,如果一个语句报错,后面的语句仍然可以正常的执行
- 43. 执行sql脚本
- 44. oracle需要先设置环境变量,如果sql文件有中文,文件编码要设置为GB2312,不然中文会乱码
- 45. 多行数据合并为一行
- 46. impala、oracle,列值是区分大小写的,mysql默认不区分大小写,三个的列名都不区分大小写
- 47. oracle没有自增主键,是依靠序列来完成的,且序列可以设置步长
- 48. hive impala
- 49. 查询树形结构的表数据
- 50. varchar是标准的sql类型,varchar2是oracle中的类型,在oracle12版本之前上限是4000字节,12版本及之后是32767字节,11版本gbk中文占两个字节,utf-8占三个字节
- 51. hint 好处是优化器不用选择了,直接使用具体的索引,当然能不能使用到要看数据量
- 52. 开启mybatis sql日志
- 53. orache number类型 mybatis if判断不能有!=''
- 54. mybatis #{param} 字符类型或者数据类型都不需要额外加或不加引号,mybatis会根据类型自己判断加不加引号,直接写成param = #{param}即可
- 55. mybatis oracle 批量插入
1. 加注释
COMMENT ON COLUMN 表名.字段名 IS '注释';
COMMENT ON TABLE 表名 IS '注释';
2. 增加索引
impala没有索引,oracle索引名全库唯一,mysql索引名不要求库唯一,表唯一即可
索引命名
IND_表名_01
IND_表名_02
加主键
ALTER TABLE 表名 ADD CONSTRAINT SYS_001 PRIMARY KEY(ID);
包含函数式索引的联合索引
CREATE INDEX 索引名 ON 表名(字段1,INSTR函数);
联合唯一索引
create unique index 索引名 on 表名(字段1, 字段2);
删除索引
drop index 索引名
3. nvl(BOARDCODE,100)>00
加nvl(字段,‘00’)>00,防止联合索引失效
4. 去掉distinct可以避免hash比较,提高性能
5. like模糊查询优化(转化为instr()函数)
!!! 注意数据为null时,字段 not like ‘%关键字%’ 或者 instr(字段, ‘关键字’) = 0,都不会查询到 需要变成where 条件1 and (instr(字段, ‘关键字’) = 0 or 字段 is null)
instr函数,查找一个字符串在另一个字符串首次出现的位置,不包含返回0
select instr(‘hl’,e’) FROM dual;
不包含返回0
包含返回1
like模糊查询优化:
LIEE haha% 对应 instr(字段,‘haha’) = 1
LIEE %haha% 对应 instr(字段,‘haha’) > 0
LIKE %haha 对应 instr(REVERSE(字段),REVERSE(‘haha’)) = 1
LIKE 'haha_%cd% 对应 instr(字段,‘haha_’) = 1 AND instr(字段,‘cd’) >= 2
字段 NOT LIKE ‘%haha%’ 对应 instr(字段, ‘haha’) = 0
相同:
SELECT I PROM dual WHERE instr(‘abcd’,b)>0;
SELECT 1 PROM dual WHERE ‘abcd’ LIKE ‘%b%’
相同:
SELECT 1 FROM dual WHERE instr(‘abede’) = 0;
SELECT 1 FROM dual WHER 'abcd’ NOT LIKE '%e%;
SELECT 1 FROM dual WHERE NOT instr(‘abcd’,‘e’) > 0;
instr(字段, ‘haha’) 若字段为null,结果为null,字段为’‘,结果为0
impala字段值可以为’‘空,oracle字段值’'也会被当成null处理
6. SQL计算除数为0时,增加nullif判断
and 字段*365/nullif((字段1*字段2),0)
7. 分页
select * from (select 字段, rownum r from 表 where 条件 and rownum <= 5) b where b.r >= 3
8. 查看执行计划
explain plan for select …;
select * from table(dhms_xplan.DISPLAY);
9. 相关问题
<if test="productCode != null and productCode !='' "> 中productCode != null 可以生效,
productCode != '' 不会生效,如果productCode是"",则在这个test中是满足条件的,
在数据库中,product_code = '' 和product_code is nu11不是一样的
<choose>
<when test="productCode != null">
and a.productCode = #{productCode ,jdbcType=VARCHAR
</when>
<otherwise>
and a.productCode is nul1
</otherwise>
</choose>
10. in (null) 不能成功
11. oracle中不存在反引号`,存在会报错
12. 扩容sql命令
AER tablespace 模式 ADD datafile '/oracle/app/oracle/oradata/0RCL/datafile/haha.dbf' SIZE 20G
13. 联合索引
oracle在联合索引的最左匹配原则时,若第一个索引字段没有命中,oracle会进行索引跳跃式扫描,跳跃前导列,命中后面的索引,
但是有的场景比如a,b,c三个字段的联合索引,where b and c 可以做到skip scan,但是where c 或 where b不能做到,还是全表扫描
14. oracle索引名全库唯一,不像mysql全表唯一就可以
oracle的索引名称重复是全库比较,在a表中建立一个索引名,b表中不能建立相同名称的素引名
15. impala与oracle的不同
1.1 时间比较
impala:
and (datediff(from_unixtime(unix_timestamp(字段,'yyyyMMdd'), 'yyyy-MM-dd'), from_unixtime(unix_timestamp('20231221', 'yyyyMMdd'), 'yyyy-MM-dd')) +1) - nvl(字段1, 字段2)
oracle:
and (to number(query_date(ctbdl.MATURITYDATE)-query_date('20231221')) - nvl(字段1, 字段2)
oracle自定义函数定义:
Function QUERY_DATE(SOURCE_DATE VARCHAR2) RETURN DATE DETERMINISTIC
IS
DEST_DATE DATE;
BEGIN
if length(SOURCE_DATE) = 8
then
DEST_DATE := to_date(SOURCE_DATE,'yyyymmdd');
return DEST_DATE;
end if;
if length(SOURCE_DATE) = 10
then
DEST_DATE := to_date(SOURCE_DATE,'yyyy-mm-dd');
return DEST_DATE;
end if;
if length(SOURCE_DATE) > 10
then
DEST_DATE := to_date(substr(SOURCE_DATE,0,10), 'yyyy-mm-dd');
return DEST_DATE;
end if;
return '';
EXCEPTION
WHEN OTHERS THEN
RETURN '';
END QUERY_DATE;
1.2 参数拼接
concat在impala可以有多个参数
concat在oracle只能有两个参数,用||可以拼接多个参数
1.3 case when then语句
case when then else end,then、else后oracle不能跟表达式,impala可以
1.4 locate函数
locate函数在impala中有,在oracle中没有,要换成instr,且参数顺序要颠倒过来
1.5 select *, other_column from table
select *, other_column from table,此语法在mpala可以使用,在oracle不可以,加上别名即可
1.6 group_concat函数
impala的group_concat函数在oracle改为listagg函数
1.7 count() 结果类型转换
impala直count()结果是可以直接强转为long,而oracle无法强转成long
// impala:
Map<String,Object> map =jdbctemplateImpala.queryForMap(sql);
Lcng count = (Long) map.get("count");
// oracle:
Map<String,Object> map = jdbcTemplateImpala.queryForMap(sql);
Long count = object2Long(map.get("count"));
public Long object2Long(object obi) {
if (objects.isNull(obj)){
throw newIllegalArgumentException("param error");
}
return new BigDecimal(String.valueOf(obj)).longValue();
}
1.8 插入’'(空)、null
在oracle中,不管字段默认是’‘,还是null,不论在dbeaver客户端插入’‘,还是在mybatis中插入’‘,
查出来都是NULL,即使在dbeaver中字段先赋值,再改为’‘,重新刷新不管是mybatis还是oracle查出来都是null。
可以认为在oracle不存在’‘,即使默认值是最后不论是mybatis还是oracle查出来都是null。
要用字段is null才可以查出数据,字段=’'查不出数据
instr(字段,搜索关键字),字段值是null,结果就是null。
即使insert into ‘’,由于字段还是被当成null(mybatis查出来也是null),所以instr(字段,搜索关键字)结果还是null。
在impala中,‘‘和null完全是不同的,插入什么查出来就是什么,
instr(字段,"搜索关键字),字段是null,结果就是null,
字段值是’‘结果就是0。查询时字段值是’’,要用字段=才能查出数据,
字段是null,要用字段is null才能查出数据
在oracle中插入’', oracle会当成null处理,字段 = '‘是查不出结果的,需要 字段 is null,才能查出结果;
在hive中插入’'和插入null,会认为是不同的
''需要字段 = ‘’ 查出结果
null需要字段 is null 查出结果
如果插入的不是空,是空格’ ',那跟其他的字符处理起来没有区别
1.9 复制数据
-- impala
insert into table dwd.table_name (select * from dwd.table_name where date = '20231226');
-- oracle/mysql
insert into table_name select * from table_name;
16. sql动态语句
这种语句需要在sqlplus上执行,否则会报错,另外sqlplus执行多条语句时,一条语句报错不会阻断执行,剩下的语句仍然可以执行成功。
BEGIN
execute immediate 'str_sql'; --动态执行DDL语句
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
/
17. oracle dml才加commit,impala和mysql不需要commit
oracle不是自动提交,dml语句需要加commit,不过在mybatis中会帮我们自动提交,不需要加;
ddl语句是不需要加commit的;
truncate是ddl语句,delete是dml语句。
18. 备份数据
ALTER TABLE TABLE_A RENAME TO TABLE_A_bak20231224;
CREATE TABLE TABLE_A AS SELECT * FROM TABLE_A_bak20231224 WHERE to_timestamp(BIZ DATE,'yyyyMMdd') >= to_timestamp('20230701,'yyyyMMdd');
这里复制表结构不会复制到索引、默认值和注释
19. 查看索引信息
-
一个表下的所有索引
select * from all_indexes where table_name=‘表名’ -
用户下的所有索引
select * from all_indexes where table_owner = ‘户名名’; -
一个表下的所有索引字段
select * from all_ind_columns where table_name = ‘表名’; -
查看版本
select * from “V$VERSION”; -
查询所有的表名
select * from user_tables; -
查看存储过程
select TO_CHAR(dbms_metadata.getddl(‘PROCEDURE’,U.OBJECT_NAME)) || CHR(10) || ‘/’ FROM USER_OBJECTS U WHERE OBJECT_TYPE = ‘PROCEDURE’;
20. 清缓存
ALTER system flush shared_pool;
ALTER system flush buffer_cache;
ALTER system flush GLOBAL_context;
21. 给数据库加空间
ALTER TABLESPACE tablespace_name ADD DATAFILE ‘path_to_datafile’ SIZE size_in_MB;
22. 重启oracle
su - oracle;
sqlplus / as sqldba;
startup;
23. impala dm dataMarket 数据集市层
24. 时间比较
select count(1) from (select END_TIME - BEGIN_TIME AS CHANGE_TIME FROM 表名) aa where aa.CHANGE_TIME <= ‘0 0:0:01’;
25. 登录
su - oracle
sqlplus /nolog
conn 用户名/密码@ip:1521/orcl
26. clob blob
clob 字符串形式大对象
blob 二进制形式大对象
最大长度都是4GB
String -> blob
// utl_raw.cast_to_raw
@Insert("insert into 表名(id, 字段1) values(#{id}, utl_raw.cast_to_raw(#{字段1}))")
blob -> String
可以实现TypeHandler接口或者继承BaseTypeHandler父类
由于varchar2最大是4000字节,所以有时需要用到clob
string 和 clob 可以直接互相转换
如果是很长的字符直接存在clob中,如果是图片等直接存在nas盘中,不建议存在数据库
27. 查询数据库连接数 设值为600个连接没问题
sqlplus / as sysdba
select count(*) from V$PROCESS
28. oracle 查询sql的执行频率/次数
-- sql执行情况
SELECT b.sid AS oracleID, b.username AS 用户名, b.serial#, paddr, sql_text AS 正在执行的SQL, b.machine AS 计算机名称
FROM v$process a, v$session b, v$sqlarea c
WHERE a.addr = b.paddr AND b.sql_hash_value = c.hash_value;
28.1 查询执行最慢的sql
select *
from (select sa.SQL_TEXT,
sa.SQL_FULLTEXT,
sa.EXECUTIONS "执行次数",
round(sa.ELAPSED_TIME / 1000000, 2) "总执行时间",
round(sa.ELAPSED_TIME / 1000000 / sa.EXECUTIONS, 2) "平均执行时间",
sa.COMMAND_TYPE,
sa.PARSING_USER_ID "用户ID",
u.username "用户名",
sa.HASH_VALUE
from v$sqlarea sa
left join all_users u
on sa.PARSING_USER_ID = u.user_id
where sa.EXECUTIONS > 0
order by (sa.ELAPSED_TIME / sa.EXECUTIONS) desc)
where rownum <= 50;
28.2 查询次数最多的 sql
select *
from (select s.SQL_TEXT,
s.EXECUTIONS "执行次数",
s.PARSING_USER_ID "用户名",
rank() over(order by EXECUTIONS desc) EXEC_RANK
from v$sql s
left join all_users u
on u.USER_ID = s.PARSING_USER_ID) t
where exec_rank <= 100;
28.3 查看总消耗时间最多的前10条SQL语句
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
last_load_time,
v.PARSING_USER_ID,
ROUND(v.ELAPSED_TIME / 1000000 / (CASE
WHEN (EXECUTIONS = 0 OR NVL(EXECUTIONS, 1 ) = 1) THEN
1
ELSE
EXECUTIONS
END),
2) "执行时间'S'",
v.SQL_FULLTEXT,
v.cpu_time,
v.disk_reads,
rank() over(order by v.elapsed_time desc) elapsed_rank
from v$sql v ) a
where elapsed_rank <= 100 and last_load_time > to_char(sysdate - 1/24, 'YYYY-MM-DD/HH:MI:SS') order by "执行时间'S'" desc
28.4 查询最近一小时内最慢的SQL
select executions, cpu_time/1e6 as cpu_sec, elapsed_time/1e6 as elapsed_sec, round(elapsed_time/sqrt(executions)) as important, v.*
from v$sql v
where executions > 10 and last_load_time > to_char(sysdate - 1/24, 'YYYY-MM-DD/HH:MI:SS')
order by important desc
28.5 查看CPU消耗时间最多的前10条SQL语句
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
rank() over(order by v.cpu_time desc) elapsed_rank
from v$sql v) a
where elapsed_rank <= 10;
28.6 查看消耗磁盘读取最多的前10条SQL语句
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
rank() over(order by v.disk_reads desc) elapsed_rank
from v$sql v) a
where elapsed_rank <= 10;
29. 查找最近一段时间,最消耗CPU的SQL语句及会话信息
可以根据 V$ACTIVE_SESSION_HISTORY 视图来获取
29.1 查找最近一分钟内,最消耗CPU的SQL语句
SELECT ASH.INST_ID,
ASH.SQL_ID,
(SELECT VS.SQL_TEXT
FROM GV$SQLAREA VS
WHERE VS.SQL_ID = ASH.SQL_ID
AND ASH.INST_ID = VS.INST_ID) SQL_TEXT,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
ASH.SESSION_INFO,
COUNTS,
PCTLOAD * 100 || '%' PCTLOAD
FROM (SELECT ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE) SESSION_INFO,
COUNT(*) COUNTS,
ROUND(COUNT(*) / SUM(COUNT(*)) OVER(), 2) PCTLOAD,
DENSE_RANK() OVER(ORDER BY COUNT(*) DESC) RANK_ORDER
FROM GV$ACTIVE_SESSION_HISTORY ASH
WHERE ASH.SESSION_TYPE <> 'BACKGROUND'
AND ASH.SESSION_STATE = 'ON CPU'
AND SAMPLE_TIME > SYSDATE - 1 / (24 * 60)
GROUP BY ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE)) ASH
WHERE RANK_ORDER <= 10
ORDER BY COUNTS DESC;
29.2 查找最近一分钟内,最消耗CPU的会话
SELECT SESSION_ID,
COUNT(*)
FROM V$ACTIVE_SESSION_HISTORY V
WHERE V.SESSION_STATE = 'ON CPU'
AND V.SAMPLE_TIME > SYSDATE - 10/ (24 * 60)
GROUP BY SESSION_ID
ORDER BY COUNT(*) DESC;
29.3 查找最近一分钟内,最消耗I/O的SQL语句
SELECT ASH.INST_ID,
ASH.SQL_ID,
(SELECT VS.SQL_TEXT
FROM GV$SQLAREA VS
WHERE VS.SQL_ID = ASH.SQL_ID
AND ASH.INST_ID = VS.INST_ID) SQL_TEXT,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
ASH.SESSION_INFO,
COUNTS,
PCTLOAD * 100 || '%' PCTLOAD
FROM (SELECT ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE) SESSION_INFO,
COUNT(*) COUNTS,
ROUND(COUNT(*) / SUM(COUNT(*)) OVER(), 2) PCTLOAD,
DENSE_RANK() OVER(ORDER BY COUNT(*) DESC) RANK_ORDER
FROM GV$ACTIVE_SESSION_HISTORY ASH
WHERE ASH.SESSION_TYPE <> 'BACKGROUND'
AND ASH.SESSION_STATE = 'WAITING'
AND ASH.SAMPLE_TIME > SYSDATE - 1 / (24 * 60)
AND ASH.WAIT_CLASS = 'USER I/O'
GROUP BY ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE)) ASH
WHERE RANK_ORDER <= 10
ORDER BY COUNTS DESC;
29.4 查找最近一分钟内,最消耗资源的SQL语句
SELECT ASH.INST_ID,
ASH.SQL_ID,
(SELECT VS.SQL_TEXT
FROM GV$SQLAREA VS
WHERE VS.SQL_ID = ASH.SQL_ID
AND ASH.INST_ID = VS.INST_ID) SQL_TEXT,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
ASH.SESSION_INFO,
COUNTS,
PCTLOAD * 100 || '%' PCTLOAD
FROM (SELECT ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE) SESSION_INFO,
COUNT(*) COUNTS,
ROUND(COUNT(*) / SUM(COUNT(*)) OVER(), 2) PCTLOAD,
DENSE_RANK() OVER(ORDER BY COUNT(*) DESC) RANK_ORDER
FROM GV$ACTIVE_SESSION_HISTORY ASH
WHERE ASH.SESSION_TYPE <> 'BACKGROUND'
AND ASH.SESSION_STATE = 'WAITING'
AND ASH.SAMPLE_TIME > SYSDATE - 1 / (24 * 60)
AND ASH.WAIT_CLASS = 'USER I/O'
GROUP BY ASH.INST_ID,
ASH.SQL_ID,
ASH.SQL_CHILD_NUMBER,
ASH.SQL_OPNAME,
(ASH.MODULE || '--' || ASH.ACTION || '--' || ASH.PROGRAM || '--' ||
ASH.MACHINE || '--' || ASH.CLIENT_ID || '--' ||
ASH.SESSION_TYPE)) ASH
WHERE RANK_ORDER <= 10
ORDER BY COUNTS DESC;
29.5 查找最近一分钟内,最消耗资源的会话
SELECT ASH.SESSION_ID,
ASH.SESSION_SERIAL#,
ASH.USER_ID,
ASH.PROGRAM,
SUM(DECODE(ASH.SESSION_STATE, 'ON CPU', 1, 0)) "CPU",
SUM(DECODE(ASH.SESSION_STATE, 'WAITING', 1, 0)) -
SUM(DECODE(ASH.SESSION_STATE,
'WAITING',
DECODE(ASH.WAIT_CLASS, 'USER I/O', 1, 0),
0)) "WAITING",
SUM(DECODE(ASH.SESSION_STATE,
'WAITING',
DECODE(ASH.WAIT_CLASS, 'USER I/O', 1, 0),
0)) "IO",
SUM(DECODE(ASH.SESSION_STATE, 'ON CPU', 1, 1)) "TOTAL"
FROM V$ACTIVE_SESSION_HISTORY ASH
WHERE ASH.SAMPLE_TIME > SYSDATE - 1 / (24 * 60)
GROUP BY ASH.SESSION_ID, ASH.USER_ID, ASH.SESSION_SERIAL#, ASH.PROGRAM
ORDER BY SUM(DECODE(ASH.SESSION_STATE, 'ON CPU', 1, 1));
30. 查询正在运行的sql、解锁sql
30.1 查看 Oracle 正在执行的 sql 语句
SELECT b.sid oracleID,
b.username 用户名,
b.serial#,
paddr,
sql_text 正在执行的SQL,
b.machine 计算机名称
FROM v$process a, v$session b, v$sqlarea c
WHERE a.addr = b.paddr
AND b.sql_hash_value = c.hash_value
30.2 kill 进程
ALTER system KILL SESSION '{ORACLEID},{SERIAL#}';
30.3 若利用步骤2命令kill一个进程后,进程状态被置为"killed",但是锁定的资源很长时间没有被释放,那么可以在os级别再kill相应的进程(线程)。
-- 首先通过执行下面SQL获得PID
SELECT spid, osuser, s.program
FROM v$session s, v$process p
WHERE s.paddr=p.addr AND s.sid={ORACLEID};
在OS上kill这个进程
-- pid: 获取到的spid
$ kill -9 {pid}
30.4 查询当前用户正在执行的SQL
select a.sid,
a.serial#,
a.paddr,
a.machine,
nvl(a.sql_id, a.prev_sql_id) sql_id,
b.sql_text,
b.sql_fulltext,
b.executions,
b.first_load_time,
b.last_load_time,
b.last_active_time,
b.disk_reads,
b.direct_writes,
b.buffer_gets
from v$session a, v$sql b
where a.username = sys_context('USERENV', 'CURRENT_USER')
and a.status = 'ACTIVE'
and nvl(a.sql_id, a.prev_sql_id) = b.sql_id;
30.5 查询当前被锁的表
SELECT l.session_id sid,
s.serial#,
l.locked_mode 锁模式,
l.oracle_username 登录用户,
l.os_user_name 机器用户名,
s.machine 机器名,
s.terminal 终端用户名,
o.object_name 被锁对象名,
s.logon_time 登录数据库时间
FROM v$locked_object l, all_objects o, v$session s
WHERE l.object_id = o.object_id
AND l.session_id = s.sid
ORDER BY sid, s.serial#;
30.6 解除锁命令
alter system kill session 'sid,serial#'
31. 查看oracle数据库的连接数和会话
su - oracle
sqlplus “/as sysdba”
-- 查询当前数据库进程的连接数
select count(*) from v$process;
-- 查询数据库当前会话的连接数
select count(*) from v$session;
-- 查询oracle的并发连接数
select count(*) from v$session where status='ACTIVE';
-- 查询不同用户的连接数
select username,count(username) from v$session where username is not null group by username;
-- 查看哪些用户有sysdba或sysoper系统权限(查询时需要相应权限)
select * from V$PWFILE_USERS;
-- 当前的连接数
select count(*) from v$process
-- 数据库允许的最大连接数,查看数据库设置的最大连接数和最大session数量,语句查看,最大进程连接数为150.
select value from v$parameter where name = 'processes'
-- ,show parameter processes命令查看的是汇总的信息,也可以直接
-- 查看数据库设置的最大连接数和最大session数量,show parameter processes命令查看的是汇总的信息,也可以直接select value from v$parameter where name ='processes'; 语句查看,最大进程连接数为150.
select value from v$parameter where name ='processes';
SQL> show parameter processes;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
aq_tm_processes integer 0
db_writer_processes integer 2
gcs_server_processes integer 0
global_txn_processes integer 1
job_queue_processes integer 1000
log_archive_max_processes integer 4
processes integer 150
SQL> select value from v$parameter where name ='processes';
VALUE
--------------------------------------------------------------------------------
150
-- 修改最大连接数
SQL> alter system set processes = 200 scope = spfile;
System altered.
-- 重启数据库:修改processes和sessions值必须重启oracle服务器才能生效
shutdown immediate; -- 关闭实例
startup; -- 启动
-- 可以用如下命令查看数据库连接的消耗情况:
SQL> select b.MACHINE, b.PROGRAM, b.USERNAME, count(*) from v$process a, v$session b where a.ADDR = b.PADDR and b.USERNAME is not null group by b.MACHINE, b.PROGRAM, b.USERNAME order by count(*) desc;
MACHINE
----------------------------------------------------------------
PROGRAM USERNAME
------------------------------------------------ ------------------------------
COUNT(*)
----------
DESKTOP-S9K68TG
DBeaver 6.3.0 - Metadata WLY
1
LAPTOP-VKRM9M36
DBeaver 6.3.0 - Metadata HMF
1
MACHINE
----------------------------------------------------------------
PROGRAM USERNAME
------------------------------------------------ ------------------------------
COUNT(*)
----------
LAPTOP-VKRM9M36
DBeaver 6.3.0 - Main WLY
1
oracledb
sqlplus@oracledb (TNS V1-V3) SYS
MACHINE
----------------------------------------------------------------
PROGRAM USERNAME
------------------------------------------------ ------------------------------
COUNT(*)
----------
1
LAPTOP-VKRM9M36
DBeaver 6.3.0 - Main HMF
1
DESKTOP-S9K68TG
MACHINE
----------------------------------------------------------------
PROGRAM USERNAME
------------------------------------------------ ------------------------------
COUNT(*)
----------
DBeaver 6.3.0 - Main WLY
1
6 rows selected.
32. sqlplus 查看sql语句的执行情况
su - oracle
sqlplus / as sysdba
@?/rdbms/admin/awrrpt.sql
33. oracle实例的内存(SGA和PGA)调整
一、名词解释
(1)SGA:SystemGlobal Area是OracleInstance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。
(2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Librarycache(共享SQL区)和Datadictionarycache(数据字典缓冲区)。 共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。
(3)缓冲区高速缓存:DatabaseBufferCache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。
(4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。
(5)Java池:Java Pool为Java命令的语法分析提供服务。
(6)PGA:ProcessGlobal Area是为每个连接到Oracledatabase的用户进程保留的内存。
二、分析与调整
(1)系统全局域:
SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。
a.共享池Shared Pool:
查看共享池大小Sql代码
SQL>show parameter shared_pool_size
查看共享SQL区的使用率:
Sql代码
select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache;
--动态性能表
LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。
查看数据字典缓冲区的使用率:
Sql代码
select(sum(gets-getmisses-usage-fixed))/sum(gets)"Data dictionary cache"from v$rowcache;
--动态性能表
这个使用率也应该在90%以上,否则需要增加共享池的大小。
修改共享池的大小:
Sql代码
ALTERSYSTEMSET SHARED_POOL_SIZE =64M;
b.缓冲区高速缓存DatabaseBufferCache:
查看共享池大小Sql代码
SQL>show parameter db_cache_size
查看数据库数据缓冲区的使用情况:
Sql代码
SELECTname,valueFROM v$sysstat orderbynameWHEREnameIN(''DBBLOCK GETS'',''CONSISTENT GETS'',''PHYSICALREADS'');
SELECT * FROM V$SYSSTAT WHERENAMEIN('parse_time_cpu','parse_time_elapsed','parse_count_ hard');
计算出来数据缓冲区的使用命中率=1-(physicalreads/(dbblock gets+consistent gets)),这个命中率应该在90%以上,否则需要增加数据缓冲区的大小。
c.日志缓冲区
查看日志缓冲区的使用情况:
Sql代码
SELECTname,valueFROM v$sysstat WHEREnameIN('redo entries','redo log space requests')
查询出的结果可以计算出日志缓冲区的申请失败率:
申请失败率=requests/entries,申请失败率应该接近于0,否则说明日志缓冲区开设太小,需要增加ORACLE数据库的日志缓冲区。
d.大型池:
可以减轻共享池的负担,可以为备份、恢复等操作来使用,不使用LRU算法来管理。其大小由数据库的'共享模式/db模式'如果是共享模式的话,要分配的大一些。
指定Large Pool的大小:
Sql代码
ALTERSYSTEMSET LARGE_POOL_SIZE=64M
e.Java池:
在安装和使用Java的情况下使用。
(2)PGA调整
a.PGA_AGGREGATE_TARGET初始化设置
PGA_AGGREGATE_TARGET的值应该基于Oracle实例可利用内存的总量来设置,这个参数可以被动态的修改。假设Oracle实例可分配4GB的物理内存,剩下的内存分配给操作系统和其它应用程序。你也许会分配80%的可用内存给Oracle实例,即3.2G。现在必须在内存中划分SGA和PGA区域。
在OLTP(联机事务处理)系统中,典型PGA内存设置应该是总内存的较小部分(例如20%),剩下80%分配给SGA。
OLTP:PGA_AGGREGATE_TARGET=(total_mem * 80%) * 20%=2.5G
在DSS(数据集)系统中,由于会运行一些很大的查询,典型的PGA内存最多分配70%的内存。
DSS:PGA_AGGREGATE_TARGET=(total_mem * 80%) * 50%
在这个例子中,总内存4GB,DSS系统,你可以设置PGA_AGGREGATE_TARGET为1600MB,OLTP则为655MB。
b.配置PGA自动管理
不用重启DB,直接在线修改。
34. dump备份、删除用户、创建用户
下面语句都是在目标数据库上执行
dump备份
-- 登录
su - oracle
sqlplus /nolog
conn 用户名/密码@ip:1521/orcl
-- 进入系统管理员,查看是否有exe权限
show user
select * from dba_role_privs where granted_role = 'EXP_FULL_DATABASE';
-- 导出的目标目录
cd /oracle/
exp userid=用户名/密码@ip:1521/orcl file=dumpfile.dmp full=y -- 导出所有用户的数据
exp userid=用户名/密码@ip:1521/orcl file=dumpfile.dmp owner=用户名 -- 导出特定用户的数据
exp userid=用户名/密码@ip:1521/orcl file=dumpfile.dmp tables=表名 -- 导出特定用户的指定表数据,多个表以逗号隔开,且要删除目的地数据库的此表
删除用户、创建用户
drop user 用户名 cascade;
create user 用户名 identified by 密码 default tablespace 用户名;
grant all privileges to 用户名;
grant connect to 用户名;
导入到另一个数据库
imp userid=用户名/密码@ip:1521/orcl file=dumpfile.dmp full=y
35. 除了在java配置文件中设置连接数,oracle数据库还有一个连接数上限值,默认是600,可以调整到1000多
36. with temp as 优化
select A.*, B.*, C.* (SELECT * FROM table_a) A
INNER JOIN (SELECT * FROM table_b) B ON A.id = B.relation_id
INNER JOIN (SELECT * FROM table_c) C ON A.id = C.relation_id
可以改造成如下(场景:c是INNER JOIN 有效,left join无效;temp中的结果集要小于几千条,尽量小)
WITH TEMP AS (
SELECT A.*, B.*
(SELECT * FROM table_a) A
INNER JOIN (SELECT * FROM table_b) B ON A.id = B.relation_id
) SELECT TEMP.*, c.* FROM TEMP
-- in (子查询的size基本不受限制,五六千没问题,不像固定的值size最大1000)
INNER JOIN (SELECT * FROM table_c AND relation_id IN (SELECT ID FROM TEMP)) C ON TEMP.id = C.relation_id
37. in中结果集大小问题
oracle:
in() 如果in中的数据是固定的值,我们赋的值,比如java中传的值,形如where id in (1, 2, 3),数据量不能超过1000,否则会报错,
但是in中的结果是子查询,形如where id in (select id from table_name),基本上五六千没问题,如果超过阈值就会截取阈值内的数据量,不会报错,会造成数据丢失,这个阈值是大于五千的,不只具体是 多少。
解决办法除了大集合拆分为多个小集合进行查询,还可以:
<if test="idList != null and idList.size > 0">
and (字段 in
<foreach collection="idList" item="item” index="index" open="(" close=")" separator=",">
<if test="(index % 999) == 998"> NULL) or 字段 in (</if>#{item}
</foreach> )
</if>
mysql:
in()中数据量超过1000不会报错,但是有大小限制,几mb好像,如果大量,不建议大家一次性查询,可以几百的size查一次,多次查。
impala:
in()中数据量应该是没限制的(记忆中是这样,大数据的东西不是很了解,不过如果数据量过大还是建议大家分批次查)
38. 查看内存空间
select tablespace_name, sum(bytes)/(1024*1024) from dba_free_space group by tablespace_name;
39. 查询表空间使用率信息
SELECT tablespace_name,
ROUND((total_space - free_space) / total_space * 100, 2) "Used%",
ROUND(total_space / 1024 / 1024, 2) "Total(MB)",
ROUND(free_space / 1024 / 1024, 2) "Free(MB)",
ROUND((total_space - free_space) / 1024 / 1024, 2) "Used(MB)"
FROM (SELECT tablespace_name,
SUM(bytes) / 1024 / 1024 total_space,
SUM(DECODE(autoextensible, 'YES', maxbytes, bytes)) / 1024 / 1024 free_space
FROM dba_data_files
GROUP BY tablespace_name);
--或者使用下面语句
--使用外连接(等价于隐式内连接),以及 SELECT 子句中的运算符和函数(例如 ROUND、/)
select a.tablespace_name,
a.total/1024 total,
round(100-b.free/a.total*100,2) "%Used"
from
(select tablespace_name,sum(bytes) total
from dba_data_files
group by tablespace_name
) a,
(select tablespace_name,sum(bytes) free
from dba_free_space
group by tablespace_name
) b
where a.tablespace_name=b.tablespace_name;
40. 排序分页
select * from (select b.*, rownum r from (select a.*,rownum from 表名 a order by create_time desc) b) where r = 1
41. 查询用户下的索引建造语句
select dbms_lob.substr(dbms_metadata.get_ddl('INDEX', INDEX_NAME)) || ';' FROM DBA_INDEXES WHERE OWNER = '用户名';
select dbms_metadata.get_ddl('INDEX', U.INDEX_NAME) FROM USER_INDEXES U;
42. 最后的/要加,是在sqlplus上执行,不加它的后面的语句不会执行,在dbeaver上不能这样使用,会执行报错,另外在sqlplus中执行多个语句,如果一个语句报错,后面的语句仍然可以正常的执行
BEGIN
execute immediate 'DROP INDEX INDEX_001'; --引号里不能加分号,会报错,引号里语句不会执行成功
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
/
create index index_name on table_name(column_name);
43. 执行sql脚本
在命令窗口或oracle服务器上,一个语句报错,不会中断,下面的语句仍然会继续执行;
在dbeaver普通sql编辑器中执行,一个语句报错会中断
su - oracle;
sqlplus /nolog;
conn 用户名/密码@ip:1521/orcl
@/home/oracle/test.sql;
44. oracle需要先设置环境变量,如果sql文件有中文,文件编码要设置为GB2312,不然中文会乱码
NLS_LANG/SIMPLIFIED CHINESE_CHINA.ZHS16GBK
查询语言字符集:select userenv(‘language’) form dual
45. 多行数据合并为一行
select LISTAGG(TABLE_NAME, '", "') from 表名
46. impala、oracle,列值是区分大小写的,mysql默认不区分大小写,三个的列名都不区分大小写
mysql默认不区分大小写,可以通过设置比较字符集来将表变成大小写敏感,不光指字段、表名等,数据也是不区分大小写。
mysql如下:
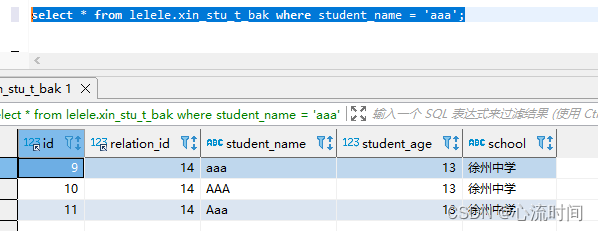
47. oracle没有自增主键,是依靠序列来完成的,且序列可以设置步长
48. hive impala
hive -f 执行sql文件
hive可以插入数据和查询数据,没有删除语句,不过hive可以通过update来覆盖数据
impala只可以查询数据,hive查询速度比impala慢很多
49. 查询树形结构的表数据
select * from (select * from 表名) A start with typeName in ('haha') CONNECT BY PRIOR typeName = parentName;
50. varchar是标准的sql类型,varchar2是oracle中的类型,在oracle12版本之前上限是4000字节,12版本及之后是32767字节,11版本gbk中文占两个字节,utf-8占三个字节
实际 oracle 现在大多使用19版本
51. hint 好处是优化器不用选择了,直接使用具体的索引,当然能不能使用到要看数据量
select /*+ index(表名, 索引名) */ 字段1 from 表名
(select /*+ index(表名, 索引名) */ 字段1 from 表名1) a
这条语句要放在最前面,且表名有别名要用别名,上面的第二句还是用表名,因为a不算表1的别名,不然不会起作用;
hint跟字段之间不需要有逗号;
hint语句写错,hint不起作用,但sql语句不会报错;
52. 开启mybatis sql日志
application.yml文件中添加如下配置
logging:
1evel:
com.xinliushijian.demo: DEBUG # 这里是debug级别mybatis sql日志才能打印出来
mybatis:
configuration:
log-impl:org.apache.ibatis.logging.stdout.stdOutImpl
53. orache number类型 mybatis if判断不能有!=‘’
orache number类型
“delete_flag” NUMBER(15, 0) DEFAULT 0 NOT NULL ENABLE;
<if test="deleteFlag != null and deleteFlag !='' ">
//这里进不来
AND delete_flag=#{deleteFlag}
</if>
<if test="deleteFlag != null ">
//这里可以进来
AND delete_flag=#{deleteFlag}
</if>
54. mybatis #{param} 字符类型或者数据类型都不需要额外加或不加引号,mybatis会根据类型自己判断加不加引号,直接写成param = #{param}即可
55. mybatis oracle 批量插入
<insert id="batchInsert" parameterType="java.util.List">
insert into 表名(id, delete_flag)
<foreach collection="list" item="item" index="index" separator="union all">
select #{item.id, jdbcType=VARCHAR}, 0 from dual
</foreach>
</insert>
或者
<insert id="batchInsert" parameterType="java.util.List">
insert all
<foreach collection="list" item="item" index="index" separator=" ">
into 表名(id, delete_flag) values(#{item.id, jdbcType=VARCHAR}, 0)
</foreach>
select * from dual
</insert>
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!