【ZooKeeper高手实战】ZooKeeper 中的核心参数讲解
🌈🌈🌈🌈🌈🌈🌈🌈 ?
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送
发送 资料 可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁

ZooKeeper 中的核心参数讲解
zk 一般必须要配置的核心参数说明(在 zoo.cfg 中配置):
-
tickTime:zk 里的最小时间单位,默认 2000 ms,其他的一些参数就会以这个 tickTime 为基准来设置,如 tickTime * 2 -
dataDir:存放 zk 里数据快照的目录,包括了事务日志以及快照文件,用于在 zk 重启时恢复之前内存中的数据 -
dataLogDir:主要放一事务日志数据,写数据是通过 2PC 来写的,每台机器都会写入一个本地磁盘的事务日志(Proposal)有些情况下,可能想要将事务日志文件单独放在一个目录,可以指定该参数
(默认情况下,zk 的事务日志与快照文件都会存储在
dataDir目录下)
dataLogDir 的机器最好挂载 SSD 固态硬盘,读写速度非常快,而 zk 集群写操作必须要保证一半以上机器都写成功事务日志,因此事务日志的 磁盘写速度 对 zk 的写性能影响很大的
影响 Leader 和 Follower 组成集群运行的两个核心参数说明:
initLimit:表示 Leader 在启动之后会等待 Follower 跟自己建立连接以及同步数据的最长时间,默认值 10,表示10 * tickTime即最长等待 20 ssyncLimit:表示 Leader 和 Follower 之间心跳的最长等待时间,默认值 5,表示5 * tickTime = 10s,如果超过 10s 没有心跳,Leader 就把这个 Follower 踢出去
zk 中的数据快照
zk里的数据分成两份:一份是在磁盘上的事务日志,一份是在内存里的数据结构,理论上两份数据应该是一致的,但是 Follower 宕机可能会导致数据的丢失:
- Follower 宕机,导致内存里的数据丢失了,但是磁盘上的事务日志还存在,可以根据磁盘的日志来恢复内存中的数据
- Follower 没收到事务日志就宕机了,也可以在启动之后找 Leader 去同步数据
那么为了保证在 Follower 重启之后,可以恢复宕机前内存中的数据,就引入了 zk 的 数据快照机制:
每当执行一定的事务之后,就会把内存里的数据快照存储到 dataDir 目录去,作为 zk 当前的一个数据快照
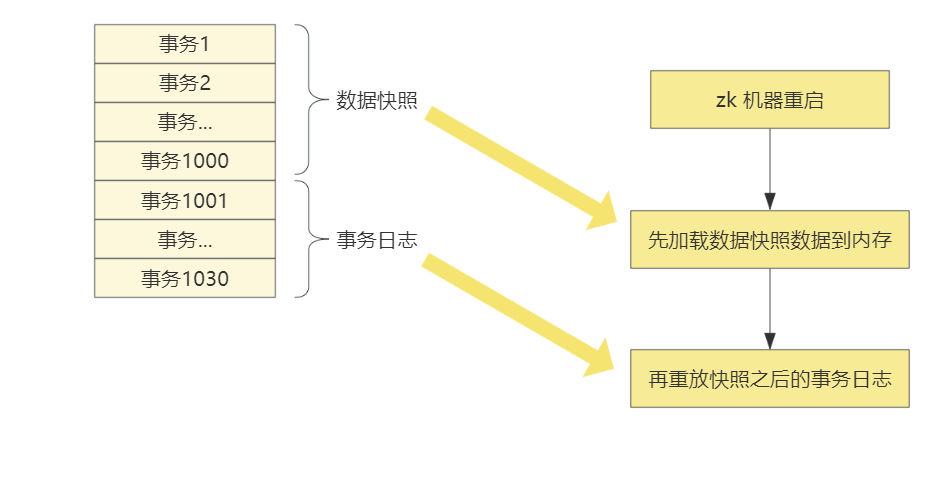
zk 机器在重启时如何根据数据快照进行内存数据的重建呢?
就比如说已经执行了 1030 个事务,在执行到 1000 个事务的时候,zk 存储了一份快照到 dataDir 目录中去,后边又执行了 30 个事务,后边执行的 30 个事务在磁盘的事务日志中有一份存档,但是并没有在刚刚存储的快照中,那么 zk 在重新启动的时候,会先加载快照,将快照中的数据恢复到内存中去,也就是先恢复 1000 个事务的数据,之后执行的 30 个事务可以在内存中 重放 一遍,就可以将重启之前内存中的数据全部恢复了,简化一下整理流程也就是:
- 读取快照文件:加载最近的内存快照数据
- 重放事务日志:将快照文件之后的事务日志进行
重放(重放也就是对事务日志重新执行一边),将数据恢复到内存中去 - 对外提供服务
当然,还是画一份图,方便更快理解:
数据快照相关参数设置:
zk 存储快照的频率是由 snapCount 来控制的,默认是执行 10 万个事务,存储一次快照,如果没到 10 万个事务,就重启了,此时并没有存储快照,因为 10 万个事务以内,直接读取磁盘中的事务日志事件还是可以接受的,不需要快照,将这部分没有快照的事务日志回放到内存就可以重建内存数据了
一台机器上最多能启动多少个 zk 客户端?
zk 客户端指的是,比如我们在一台机器上运行 Kafka、Canal、HDFS,就拿 Canal 来举例,将 Canal 部署在一台机器上之后,它会去使用 zk,那么这个 Canal 就作为 zk 的客户端去跟 zk 服务端进行通信了
那么在一台机器上,可以创建多少个 zk 客户端和 zk 的服务端去进行连接可通信呢?
默认一台机器上最多创建 60 个 zk 客户端,3.4.0 之前是 10 个
为什么要注意这个呢?
就比如我们自己去开发一个系统使用 zk 的话,在一台机器上,我们要注意不要去无限制的创建 zk 客户端,可能有些时候创建 zk 客户端的时候 没有注意使用单例,如果并发多个请求时,对每个请求都建立一个 zk 的客户端,会被 zk 的服务端给拒绝连接!
一个 znode 最多可以存储多少数据呢?
通过参数 jute.maxbuffer 来控制,一个 znode 最多可以存储 1MB 的数据
运行时 Leader 和 Follower 通过哪两个端口通信?
- 机器的
3888端口,用于集群恢复模式时,进行 Leader 选举投票的 - 机器的
2888端口,用于 Leader 和 Follower 之间进行数据同步和运行时通信的
zk 中的数据快照如何定时清理?
autopurge.purgeInterval:定义自动清理任务的间隔时间,以小时为单位,每次清理 zk 会检查并删除超过 autopurge.snapRetainCount 指定数量的快照文件,默认是 1,即每隔 1 小时清理一次autopurge.snapRetainCount:指定 zk 中保留的快照文件数量,当快照文件数量超过这个值时,最旧的快照文件将被自动删除,默认是 3
上边这两个参数,在默认情况下是没有打开的,通过这两个参数可以定时清理 zk 中的数据快照,避免磁盘空间被占满
# 如果需要打开,配置如下
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
Leader 相关的参数:
leaderServers:表示 Leader 是否接收客户端的连接,如果设置为 no,那么写请求将会由 Follower 转发给 Leader,默认 yescnxTimeout:在 Leader 选举的时候,各个机器会基于 3888 端口建立 TCP 连接,该参数表示建立 TCP 连接的超时时间,默认 5000ms
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!