ffmpeg 硬件解码零拷贝unity 播放
ffmpeg硬件解码问题
ffmpeg 在硬件解码,一般来说,我们解码使用cuda方式,当然,最好的方式是不要确定一定是cuda,客户的显卡不一定有cuda,windows 下,和linux 下要做一些适配工作,最麻烦的不是这个,二是ffmpeg解码后,颜色空间的转换,如果使用cuda,那么可以使用cuda去在gpu中直接转码,如果没有cuda,那么我们希望的是不要转颜色空间。
ffmpeg 硬件解码相信下面这一段代码是大家比较熟悉的
if (frame->format == hw_pix_fmt) {
/* retrieve data from GPU to CPU */
sw_frame->format = sourcepf; // AV_PIX_FMT_NV12;
//if ((ret = av_hwframe_transfer_data(sw_frame, frame, 0)) < 0) {
if ((ret = av_hwframe_map(sw_frame, frame, 0)) < 0) {
fprintf(stderr, "Error transferring the data to system memory\n");
av_frame_free(&frame);
av_frame_free(&sw_frame);
return -1;
}
tmp_frame = sw_frame;
}
else
{
tmp_frame = frame;
}
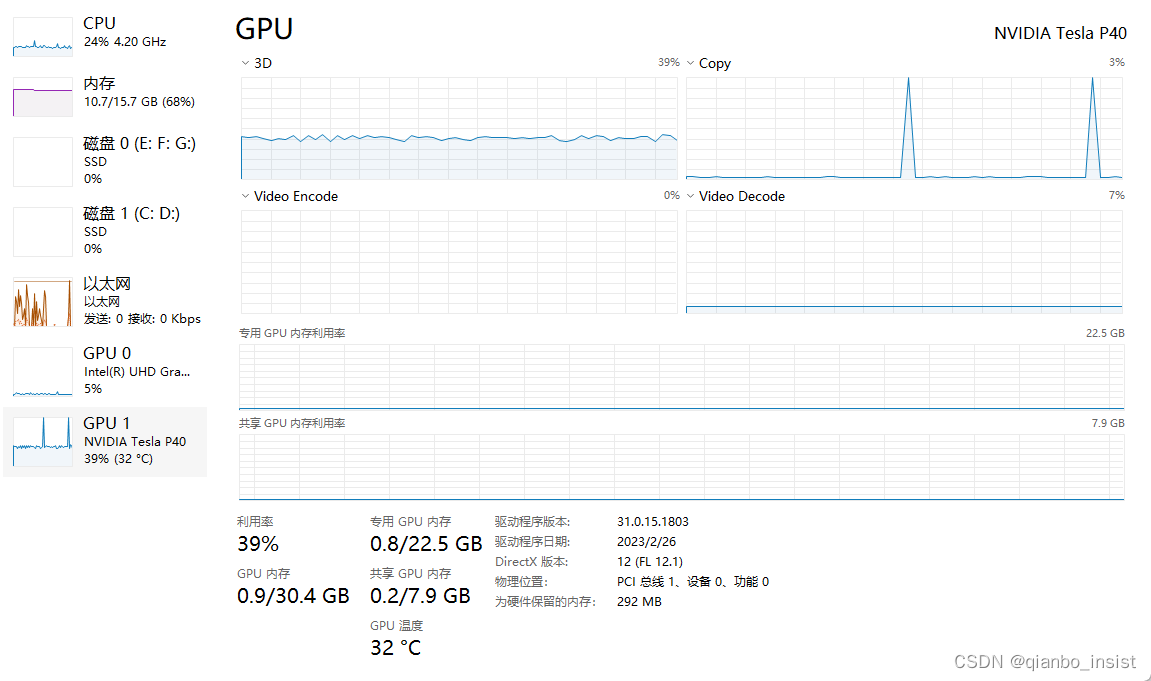
如下我们在解码的时候,gpu 一个tesla p40 都占用了42%,实际上是unity渲染占用
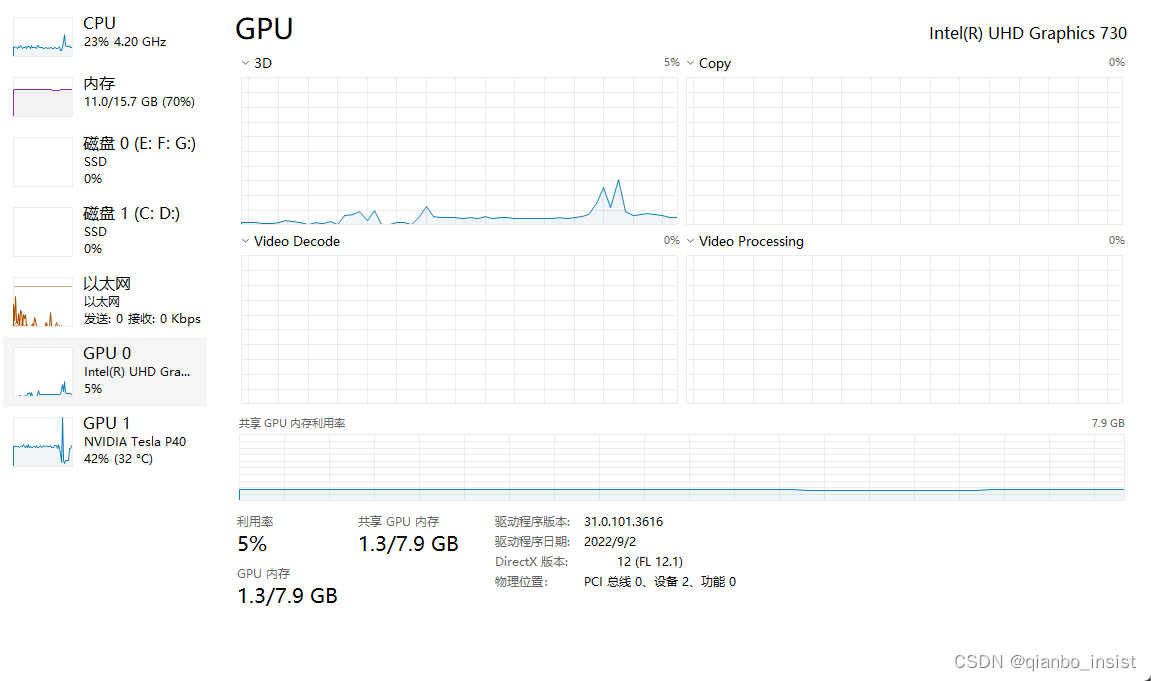
打开tesla p40 的decode,实际上并不多,间歇会有一个峰值,后来稳定在7% 左右,p40的显存不小,但是解码其实不如3080这种gpu。
回过头来说ffmpeg 函数,av_hwframe_map 函数直接把gpu显存中的数据映射到内存,并且颜色转换从cuda到nv12,实际上cuda中的颜色就是nv12,只是把数据下载到了内存,这个过程是避免不了的,如果我们希望三维软件或者opencv 直接识别这个内存数据,显然是最好是rgb24,或者bgr24 这种颜色空间,那么问题就是
我们熟悉的swscale 函数颜色转换还是比较消耗cpu,那么我们应该怎么做才是最合适的方法
2 最合适的方法
应该是 ffmpeg transfer到内存后,不转换,直接使用三维软件使用shader来转变颜色空间,当然这肯定又是一次内存到显存的上载,但这个也是避免不了的。
2.1 拷贝
使用用户空间自己的内存直接给ffmpeg 的av_hwframe_map 函数 ,让ffmpeg下载时到用户空间指定的内存地址。
2.2 显示
使用shader 显示nv12
Shader"draw/s1"
{
Properties
{
_MainTex ("Y", 2D) = "white" {}
_MainTexUV ("UV", 2D) = "white" {}
}
SubShader
{
Lighting Off
Pass{
CGPROGRAM
sampler2D _MainTex;
sampler2D _MainTexUV;
#pragma vertex vert
#pragma fragment frag
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
//float4 vert(float4 v : POSITION) : SV_Position
//{
// return UnityObjectToClipPos(v);
//}
v2f vert(appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = v.uv;
return o;
}
// fixed4 frag(v2f i):SV_Target
// {
1 - i.uv.y 左右镜像
// fixed2 uv = fixed2(i.uv.x, 1 - i.uv.y);
// fixed4 ycol = tex2D(_MainTex, uv);
// fixed4 uvcol = tex2D(_MainTexUV, uv);
// float y = ycol.r;
// float v = uvcol.r - 0.5;
// float u = uvcol.g - 0.5;
// float r = y + 1.370705 * v;
// float g = y - 0.337633 * u - 0.698001 * v;
// float b = y + 1.732446 * u;
// return fixed4(r,g,b, 1.0);
// }
fixed4 frag(v2f i) : SV_Target
{
fixed4 col;
float y = tex2D(_MainTex, i.uv).a;
fixed4 uvs = tex2D(_MainTexUV, i.uv);
float u = uvs.r - 0.5;
float v = uvs.g - 0.5;
float r = y + 1.403 * v;
float g = y - 0.344 * u - 0.714 * v;
float b = y + 1.770 * u;
col.rgba = float4(r, g, b, 1.0f);
return col;
}
ENDCG
}
}
FallBack "VertexLit"
}
这已经是目前最快的方法了
其他问题
其他就是怎么直接把显存给pytorch 了,这个也是比较重要的,下次再说吧
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!