大创项目推荐 深度学习实现行人重识别 - python opencv yolo Reid
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的行人重识别算法研究与实现 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate

1 课题背景
行人重识别是计算机视觉领域的研究热点之一,旨在研究不重叠的多个摄像区域间对于特定行人的匹配准确率,是图像检索的子问题,多应用于安防和刑侦。我国实现的视频监控“天网”,就是通过在人流量大的公共区域密集安装监控设备来实现“平安城市”建设。尽管部分摄像头可转动,但仍存在监控盲区和死角等局限性问题,Re-
ID技术弥补了摄像设备的视觉局限性。然而,在实际应用中异时异地相同行人的图像数据,在姿势、前景背景、光线视角以及成像分辨率等方面差异大,使得Re-
ID研究具有挑战性。
行人重识别展示
2 效果展示
手动标记
检测结果
3 行人检测
本项目实现了基于 yolo框架的行人目标检测算法,并将该目标检测算法应用在图像和视频的识别检测之中。
简介
下图所示为 YOLOv5 的网络结构图,分为输入端,Backbone,Neck 和 Prediction 四个部分。其中,
输入端包括 Mosaic 数据增强、自适应图片缩放、自适应锚框计算,Backbone 包括 Focus 结构、CSP
结 构,Neck 包 括 FPN+PAN 结 构,Prediction 包 括GIOU_Loss 结构。
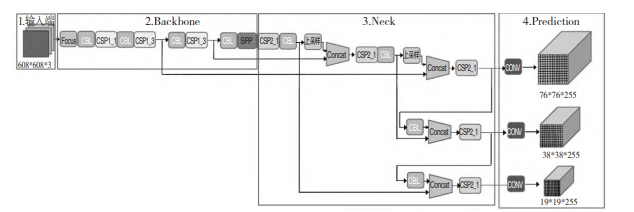
Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
?
①==>40×40×255
②==>20×20×255
③==>10×10×255
?

相关代码
?
class Yolo(object):
def __init__(self, weights_file, verbose=True):
self.verbose = verbose
# detection params
self.S = 7 # cell size
self.B = 2 # boxes_per_cell
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train","tvmonitor"]
self.C = len(self.classes) # number of classes
# offset for box center (top left point of each cell)
self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)]*self.S*self.B),
[self.B, self.S, self.S]), [1, 2, 0])
self.y_offset = np.transpose(self.x_offset, [1, 0, 2])
self.threshold = 0.2 # confidence scores threhold
self.iou_threshold = 0.4
# the maximum number of boxes to be selected by non max suppression
self.max_output_size = 10
self.sess = tf.Session()
self._build_net()
self._build_detector()
self._load_weights(weights_file)
4 行人重识别
简介
行人重识别(Person re-identification)也称行人再识别, 被广泛认为是一个图像检索的子问题,
是利用计算机视觉技术判断图像或者视频中是否存在特定行人的技术,
即给定一个监控行人图像检索跨设备下的该行人图像。行人重识别技术可以弥补目前固定摄像头的视觉局限, 并可与行人检测、行人跟踪技术相结合,
应用于视频监控、智能安防等领域。
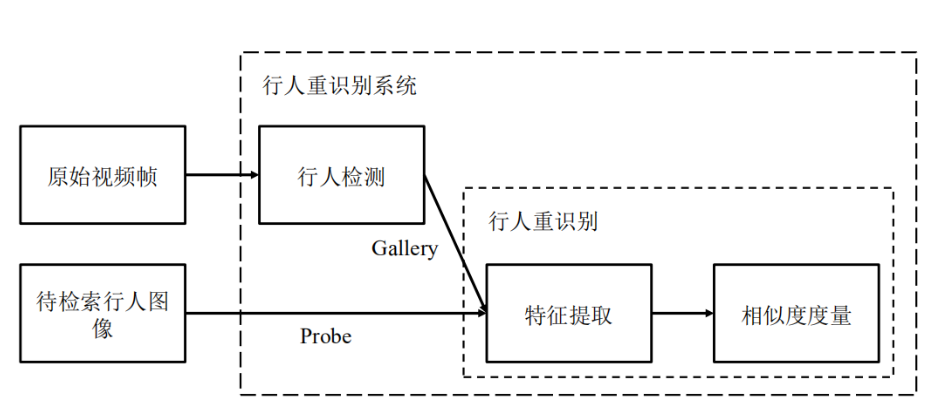 行人重识别系统
行人重识别系统
行人检测
主要用于检测视频中出现的人像,作为一个行人重识别首先要做到的就是能够将图片中的行人识别出来,称为Gallery输入。当然,在学术研究领域,行人重识别主要还是关注的下面这个部分,而对于行人检测这部分多选择采用目前已经设计好的框架。
行人重识别
这一部分就是对上面的Probe以及Gallery进行特征提取,当然提取的方式可以是手工提取,也可以使用卷积神经网络进行提取。然后呢,就是对图片的相似度进行度量,根据相似图进行排序。
针对行人重识别系统从细节来说,包括下面几个部分:
- 特征提取(feature Extraction):学习能够应对在不同摄像头下行人变化的特征。
- 度量学习(Metric Learning) :将学习到的特征映射到新的空间使相同的人更近不同的人更远。
- 图像检索(Matching):根据图片特征之间的距离进行排序,返回检索结果
Reid提取特征
行人重识别和人脸识别是类似的,刚开始接触的可以认为就是人脸换成行人的识别。
-
截取需要识别的行人底库

-
保存行人特征,方便进行特征比对
相关代码
?
# features:reid模型输出512dim特征
person_cossim = cosine_similarity(features, self.query_feat)
max_idx = np.argmax(person_cossim, axis=1)
maximum = np.max(person_cossim, axis=1)
max_idx[maximum < 0.6] = -1
score = maximum
reid_results = max_idx
draw_person(ori_img, xy, reid_results, self.names) # draw_person name
5 其他工具
OpenCV
是一个跨平台的计算机视觉处理开源软件库,是由Intel公司俄罗斯团队发起并参与和维护,支持与计算机视觉和机器学习相关的众多算法。

本项目中利用opencv进行相关标记工作,相关代码:
?
import cv2
import numpy as np
def cv_imread(filePath):
cv_img = cv2.imdecode(np.fromfile(filePath,dtype=np.uint8), -1)
return cv_img
# 需要可视化的图片地址
img_path = ‘’
# 对应图片的检测结果
detection_result = []
# 如果路径中包含中文,则需要用函数cv_imread的方式来读取,否则会报错
img = cv_imread(img_path)
# 可视化
for bb in detection_result:
# bb的格式为:[xmin, ymin, xmax, ymax]
cv2.rectangle(img, (int(bb[0]), int(bb[1])),
(int(bb[2]), int(bb[3])),
(255, 0, 0), 2)
cv2.imshow('1', img)
cv2.waitKey(0)
?
6 最后
🧿 更多资料, 项目分享:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!