Graph Transformer2023最新研究成果汇总,附15篇必看论文
图Transformer是一种结合了Transformer模型和图神经网络(GNN)的框架,用于在图形结构数据上执行预测任务。在图Transformer中,Transformer的自注意力机制被用来学习节点之间的关系,而GNN则被用来生成节点的嵌入表示。通过这种方式,图Transformer能够捕捉到图中节点的远程依赖关系,从而有效地对大规模图数据进行建模和预测。这种设计避免了引入中间层的任何结构化偏置,从而显著增强了图数据的表达能力。
今天我就帮同学们整理了Graph Transformer今年以及以往的一些值得一看的研究成果,目前共有15篇,想在这个方向发论文找创新点的同学们建议收藏。
论文和代码需要的看文末
1.Are More Layers Beneficial to Graph Transformers
更多的层对图Transformer有益吗?
「简述:」论文研究了图Transformer的深度问题,发现现有的图Transformer相对较浅。作者发现增加层数并不能提高性能,因为深图Transformer受到全局注意力的限制。为了解决这个问题,作者提出了一种名为DeepGraph的新模型,它使用子结构令牌和局部注意力来增强表示的表达能力。实验表明,作者的方法解除了图Transformer的深度限制,并在各种基准测试中取得了最先进的性能。

2.Graph Inductive Biases in Transformers without Message Passing
不使用消息传递的Transformer中的图归纳偏置
「简述:」图数据的Transformer越来越受欢迎,并在许多学习任务中取得了成功。先前的工作通过消息传递模块和/或位置编码来引入图的归纳偏差。但是,使用消息传递的图Transformer存在已知的问题,并且与其他领域的Transformer有显著差异,这使得研究进展的转移更加困难。另一方面,没有消息传递的图Transformer在较小的数据集上通常表现不佳,而在这样的数据集中,归纳偏差更为重要。为了填补这一空白,作者提出了一种新的图Transformer——图归纳偏差Transformer(GRIT),它不需要使用消息传递就可以引入图的归纳偏差。GRIT具有表达能力,可以表达最短路径距离和各种图传播矩阵。它在各种图形数据集上实现了最先进的实证性能,从而展示了不使用消息传递的图变换器所能提供的强大功能。
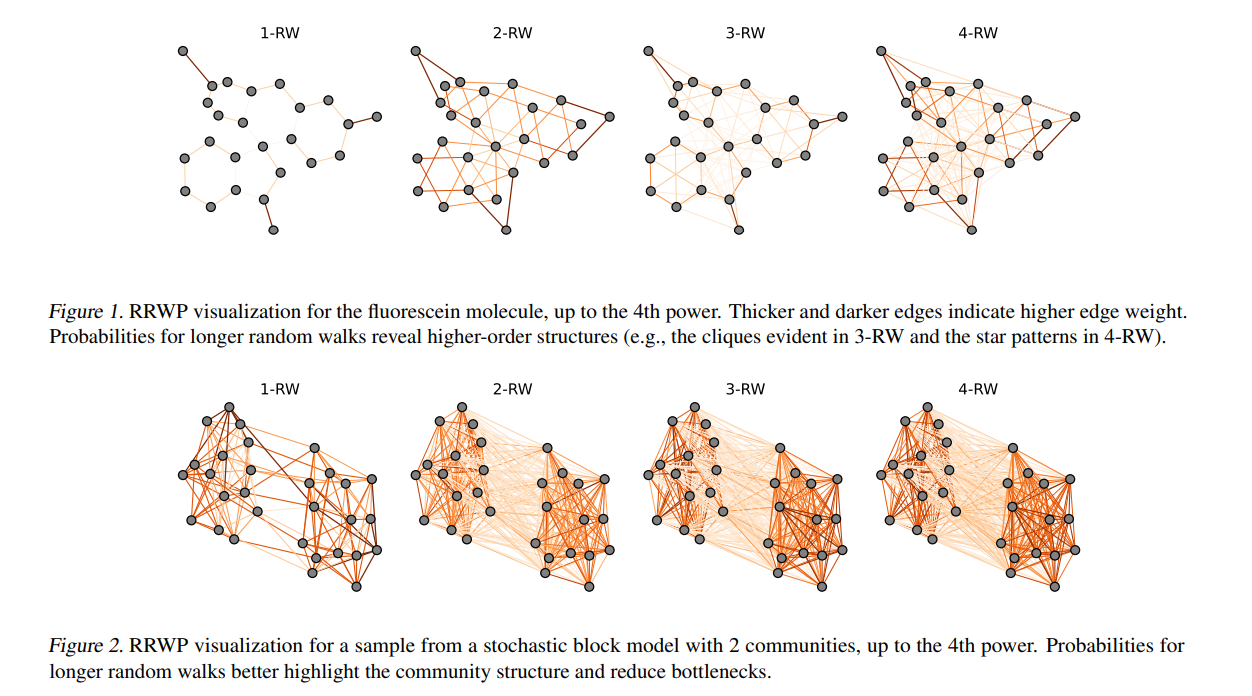
3.Exphormer: Sparse Transformers for Graphs
用于图形的稀疏Transformer
「简述:」图Transformer是一种有前途的架构,用于各种图形学习和表示任务。本文介绍了一个名为EXPHORMER的框架,用于构建强大和可扩展的图Transformer。它基于虚拟全局节点和扩展器图的稀疏注意力机制,具有线性复杂度和理想的理论性质。将EXPHORMER集成到GraphGPS框架中,可以在广泛的图形数据集上获得有竞争力的结果,包括在三个数据集上取得最先进的结果。此外,EXPHORMER还可以扩展到更大的图形数据集上。
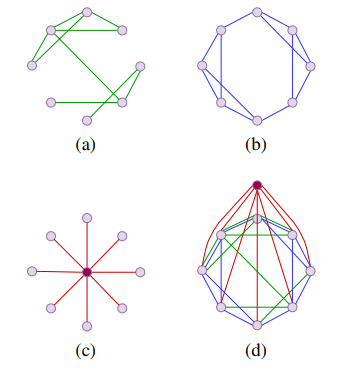
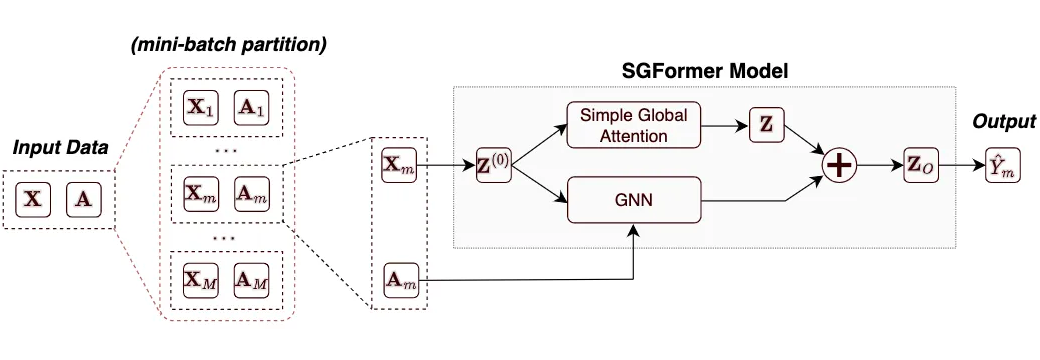
4.Simplifying and Empowering Transformers for Large-Graph Representations
简化和增强大型图表示的Transformer
「简述:」学习大型图的表示是一个长期存在的挑战,因为涉及大量数据点的相互依存性质。本文介绍了一种名为SGFormer的简化图形Transformer,它使用一个简单的注意力模型来高效地在不同节点之间传播信息,成本仅为一层传播层和与节点数量线性复杂度相比极小的计算量。SGFormer不需要位置编码、特征/图预处理或额外的损失。在实证上,SGFormer成功地扩展到了网页规模的ogbn-papers100M图,并在中等规模图上比SOTA Transformers实现了高达141倍的推理加速。
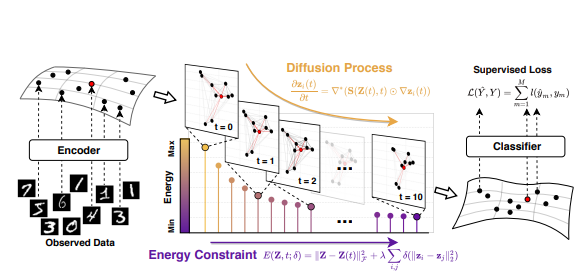
5.DIFFormer: Scalable (Graph) Transformers Induced by Energy Constrained Diffusion
能量约束扩散引起的可扩展(图)Transformer
「简述:」现实世界的数据生成通常涉及实例之间的复杂相互依赖关系,违反了标准学习范式的IID数据假设。为了解决这个问题,作者提出了一种能量受限扩散模型,将数据集中的一批实例编码为逐渐包含其他实例信息进化状态。扩散过程受到关于实例表示在潜在结构上的全局一致性的原理能量函数的约束。作者提出了一种新的神经网络编码器类别,称为DIFFORMER(基于扩散的Transformer),包括两个实例:一个具有线性复杂度的简单版本,适用于数量庞大的实例;另一个用于学习复杂结构的版本。实验表明,该模型作为通用编码器骨干具有广泛的应用性,并在各种任务中表现出优越的性能。
6.GraphGPS: General Powerful Scalable Graph Transformers
通用的强大可扩展图Transformer
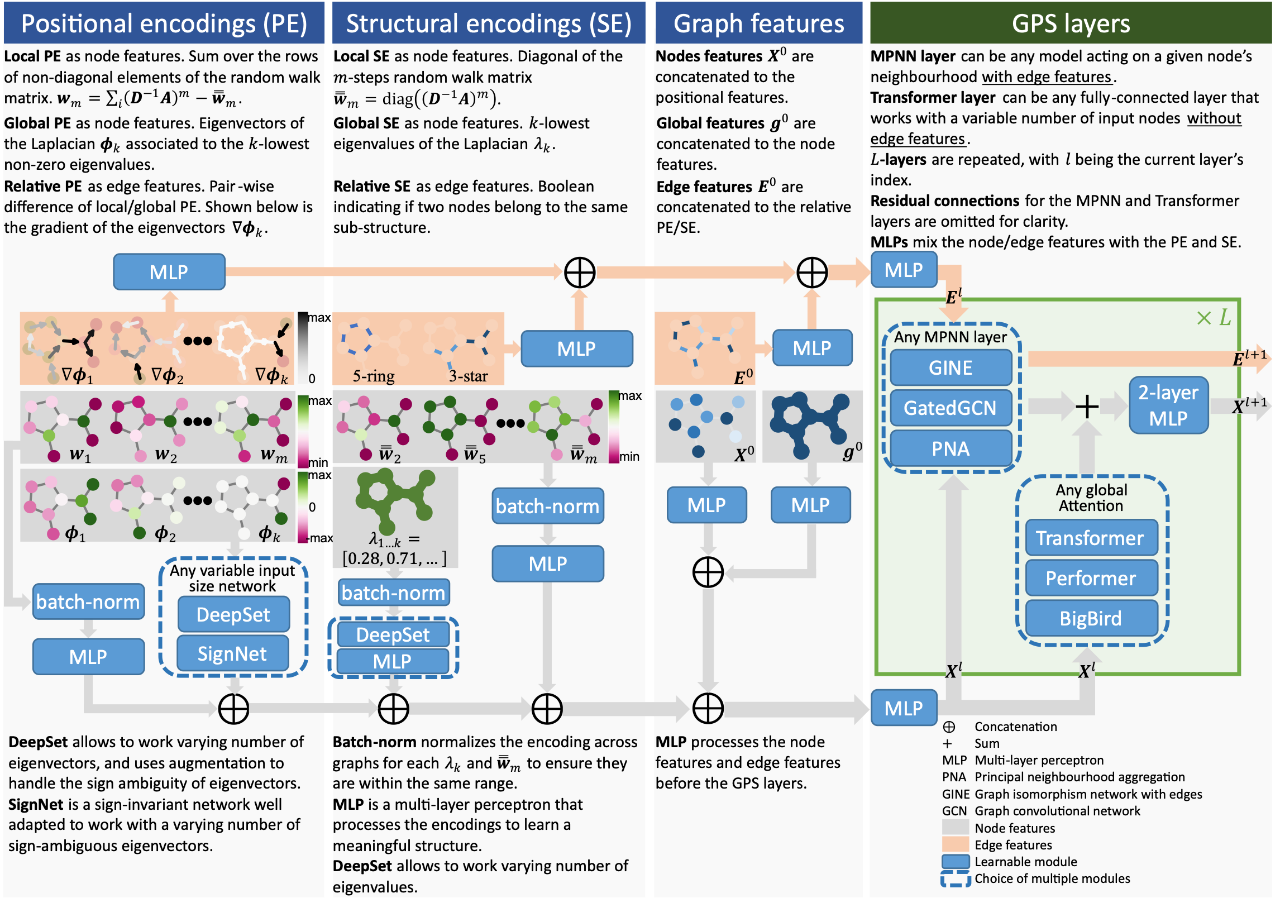
「简述:」论文提出了一种新的图形Transformer架构,名为GPS,它具有线性复杂性和在各种基准测试中的最先进结果。以前的图形Transformer受限于小型图形,而作者提出的架构对大型图形也有效。该架构由三个主要部分组成:位置/结构编码、局部消息传递机制和全局注意力机制。作者提供了一个模块化框架,支持多种类型的编码,并在小型和大型图形中都高效且可扩展。
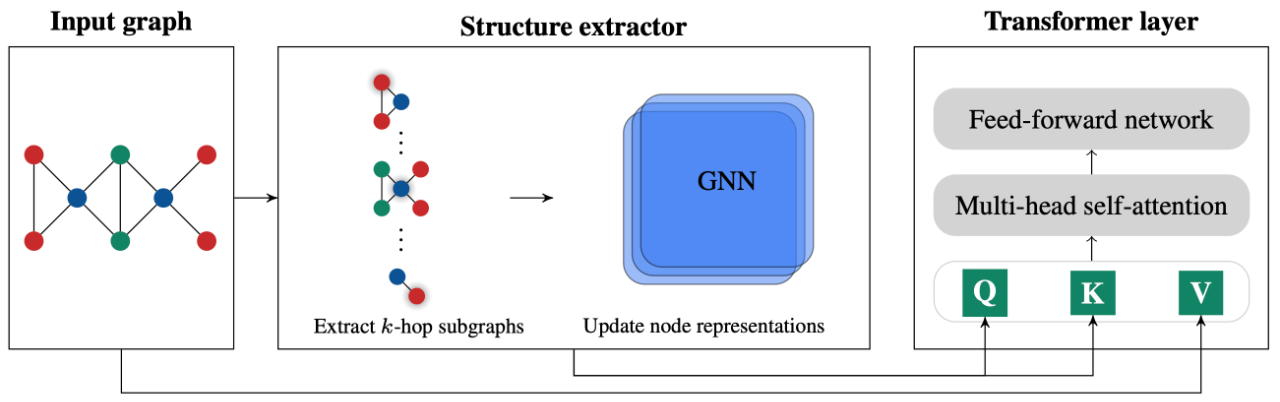
7.Structure-Aware Transformer for Graph Representation Learning
用于图表示学习的结构感知Transformer
「简述:」论文提出了Structure-Aware Transformer,用于图表示学习。该方法通过从每个节点提取子图表示并将其纳入自注意力机制中来捕捉结构信息。作者提出了几种自动生成子图表示的方法,并证明所得表示具有表现力。在实验上,该方法在五个图预测基准测试中实现了最先进的性能。作者的结构感知框架可以与现有的GNN结合使用,从而系统地提高性能。
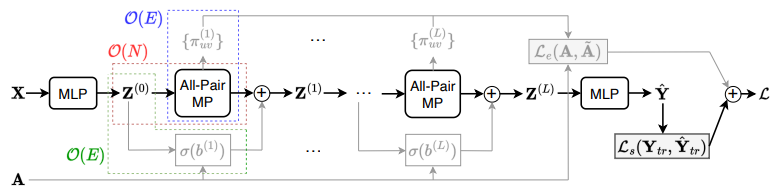
8.NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification
用于节点分类的可扩展图结构学习Transformer
「简述:」论文介绍了一种新的图神经网络,名为NODEFORMER,用于大型图上的节点分类。它采用了一种新的全对消息传递方案,可以在任意节点之间高效地传播节点信号。这种方案通过使用kernerlized Gumbel-Softmax运算符,将算法复杂性降低到线性,使得在大型图上学习潜在的图结构成为可能。实验结果表明,该方法在各种任务中表现出了良好的效果,包括在图上的节点分类和图形增强应用程序。
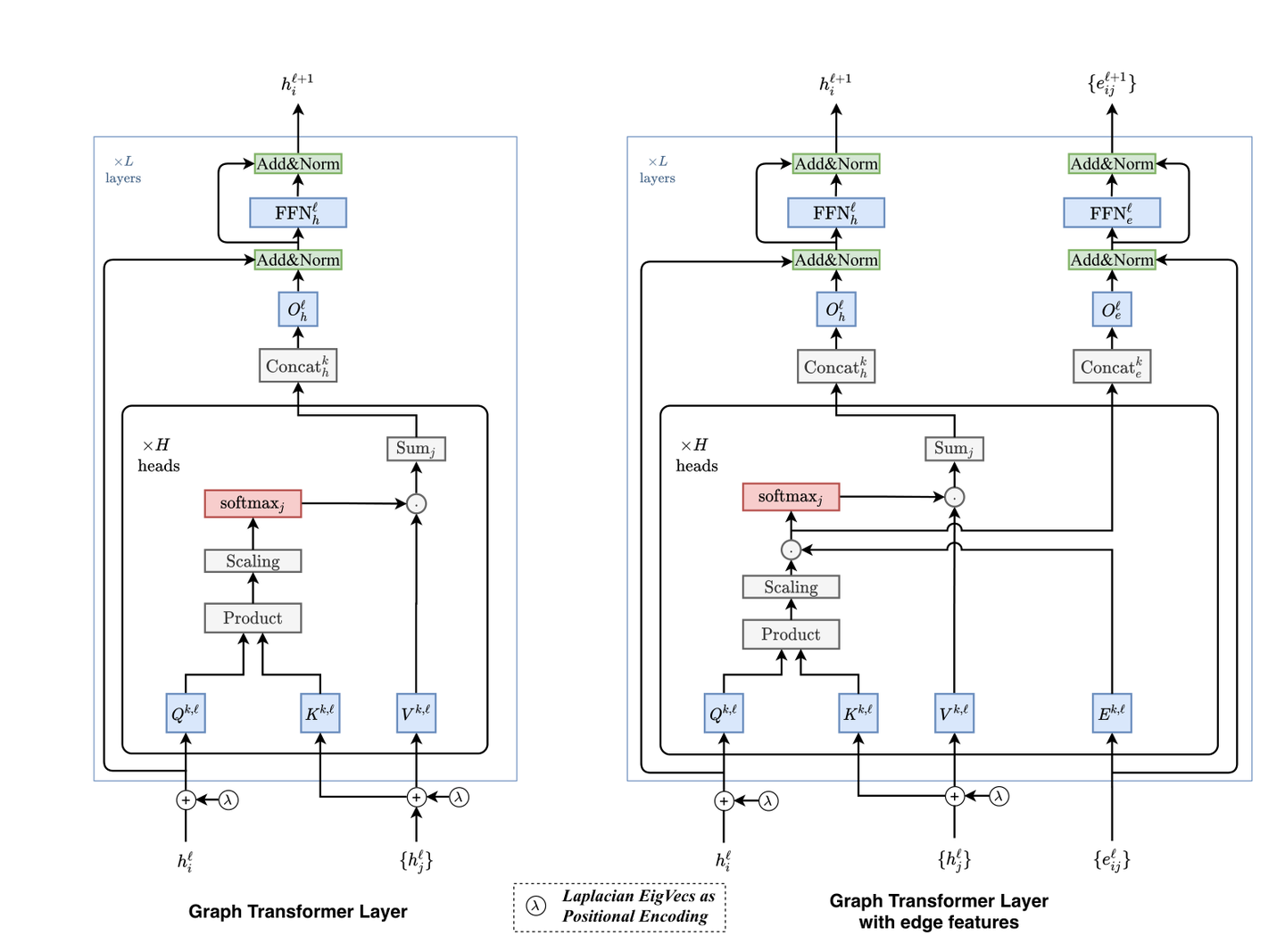
9.A Generalization of Transformer Networks to Graphs
Transformer网络向图的泛化
「简述:」论文提出了一种适用于任意图的Transformer神经网络架构的泛化方法。原始的Transformer是为自然语言处理(NLP)而设计的,它在表示序列中单词之间所有连接的全连通图中操作。作者引入了一种图Transformer,与标准模型相比具有四个新特性。首先,对于图中每个节点,注意力机制是其邻域连接的函数。其次,位置编码由拉普拉斯特征向量表示,这自然地推广了NLP中常用的正弦位置编码。第三,层归一化被批量归一化层替换,它可以提供更快的训练和更好的泛化性能。最后,该架构扩展到边缘特征表示,这对于化学任务(键类型)或链接预测(知识图谱中的实体关系)等任务可能至关重要。
10.Do Transformers Really Perform Bad for Graph Representation?
Transformers在图表示中表现真的很差吗?
「简述:」论文提出了一种名为Graphormer的图表示学习方法,它建立在标准的Transformer架构之上,并在广泛的图表示学习任务上取得了出色的结果。作者通过提出几种简单而有效的结构编码方法来帮助Graphormer更好地对图结构化数据进行建模,从而解决了Transformer在图表示学习中表现不佳的问题。此外,作者还展示了通过他们的图结构信息编码方式,许多流行的GNN变体都可以作为Graphormer的特例。
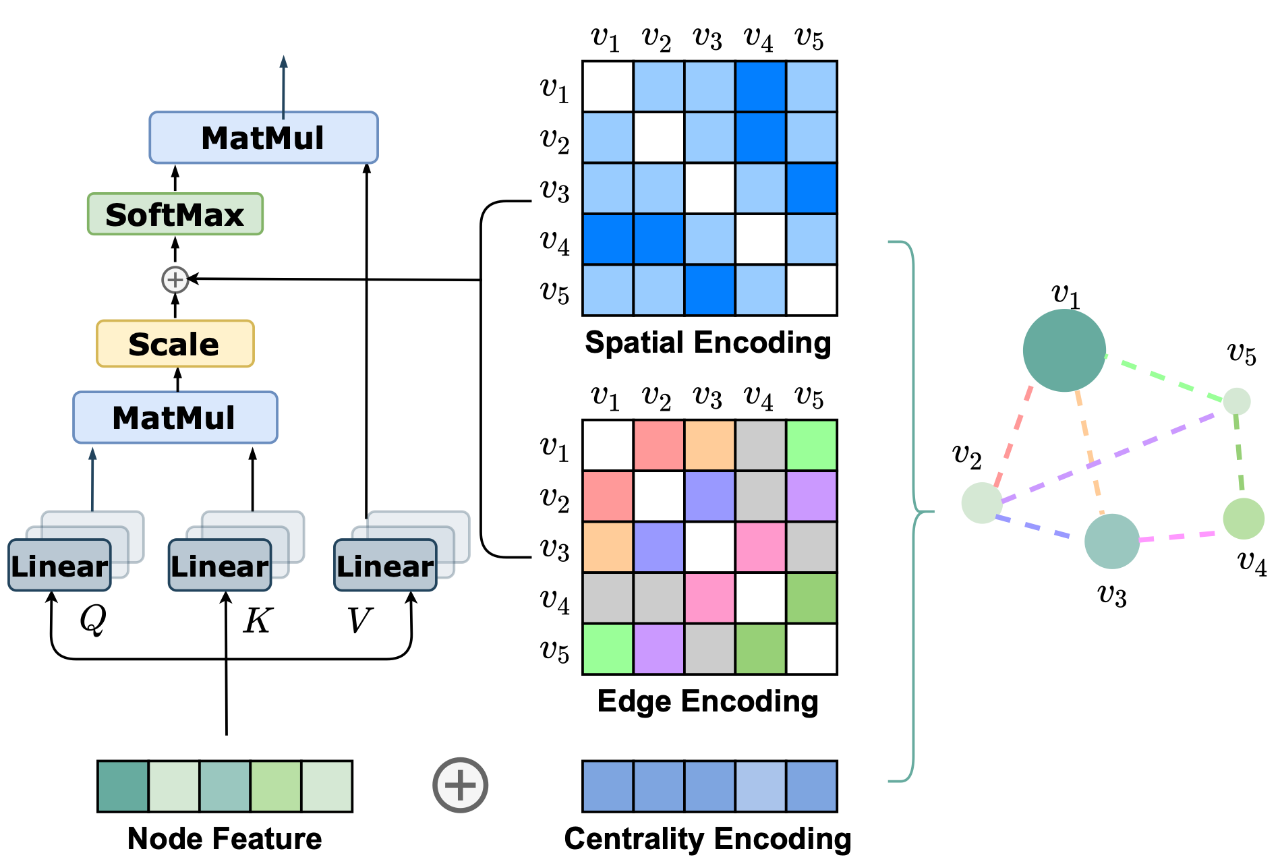
11.Rethinking Graph Transformers with Spectral Attention
使用光谱注意力重新思考图Transformer
「简述:」Transformer在处理序列数据方面很成功,但在处理图数据时遇到了困难,因为定义图中的位置很困难。作者提出了一种新的方法,称为谱注意力网络(SAN),它使用了一种学习位置编码(LPE),可以从拉普拉斯算子的全谱中学习节点的位置。然后,作者将LPE添加到图的节点特征中,并将其传递给全连接的Transformer。这种方法在理论上可以很好地区分不同的图,并且可以更好地检测相似的子结构。此外,由于Transformer与图完全连接,因此不会受到信息瓶颈的影响,可以更好地模拟物理现象。
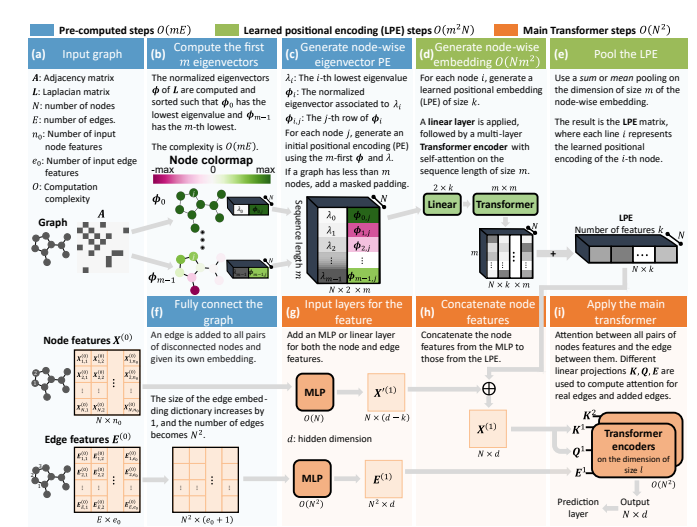
12.GRAPH-BERT: Only Attention is Needed for Learning Graph Representations
学习图表示只需要注意力机制
「简述:」论文提出了一种新的图神经网络,即基于注意力机制的GRAPH-BERT(Graph based BERT),它不需要任何图卷积或聚合算子。作者建议在局部上下文中训练GRAPH-BERT以采样无链接的子图,而不是用完整的大型输入图来训练。预训练的GRAPH-BERT可以有效地转移到其他应用程序任务,或者在有监督标签信息或某些面向应用的目标时进行必要的微调。实验结果表明,GRAPH-BERT在学习和效率方面都可以超越现有的GNNs。
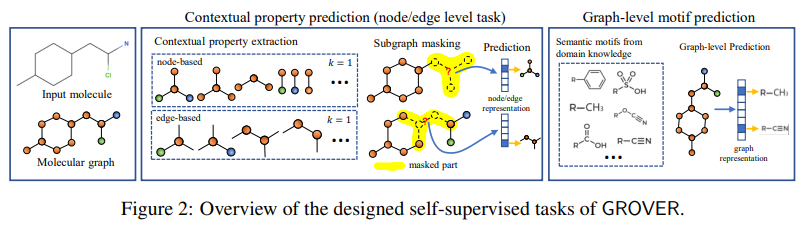
13.Self-Supervised Graph Transformer on Large-Scale Molecular Data
大规模分子数据上的自监督图Transformer
「简述:」为了解决分子表示学习中的问题,作者提出了一种名为GROVER的新框架。它可以从大量无标签的分子数据中学习分子结构,并使用Transformer风格的架构来编码这些信息。与传统的监督学习方法相比,GROVER不需要任何标签,因此可以更高效地处理大规模数据集。作者使用1000万个无标签分子来预训练GROVER,并在11个具有挑战性的基准上进行微调,取得了显著的改进。这种框架对于提高分子设计和发现的效率非常有前途。
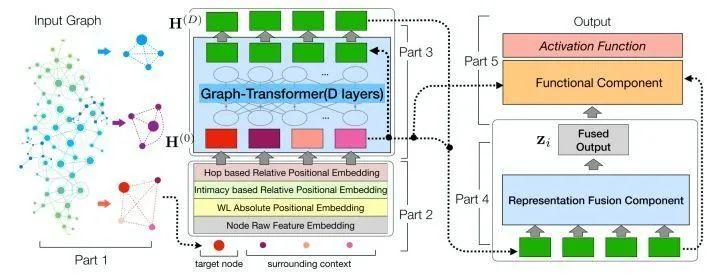
14.GraphiT: Encoding Graph Structure in Transformers
在Transformer中编码图结构
「简述:」论文提出了一种新的图神经网络模型GraphiT,它将图结构视为节点特征的集合,并将结构和位置信息整合到Transformer架构中。通过利用基于图上的正定核的相关位置编码策略和枚举并编码局部子结构(如短路径),GraphiT能够超越传统图神经网络(GNN)学习到的表示。作者在多个分类和回归任务上全面评估了这两个想法的有效性,并展示了它们之间的组合效果。除了在标准基准测试上表现良好外,GraphiT还具有自然可视化机制,可以解释预测结果中的图模式,使其成为科学应用中重要解释性的强大候选者。
15.Representing Long-Range Context for Graph Neural Networks with Global Attention
用全局注意力表示图神经网络的远程上下文
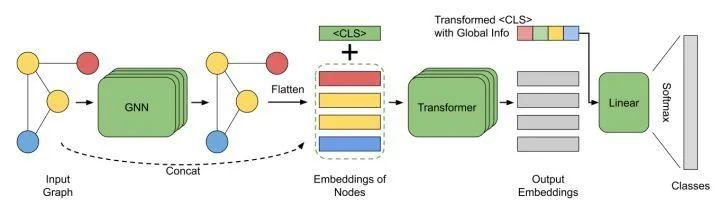
「简述:」论文提出了一种使用Transformer-based self-attention来学习长范围成对关系的图神经网络模型,称为GraphTrans。该模型在标准GNN模块之后应用了一个位置不变的Transformer模块,并采用一种新的“读出”机制来获得全局图嵌入。该方法在几个图分类任务上取得了最先进的结果,超过了显式编码图结构的方法。作者认为,纯粹基于学习的方法可能适合学习图的高级别、长范围关系。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“Graph”获取论文+代码合集
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!