精通推荐算法4:经典DNN框架特征交叉模型 Deep Crossing(面试必备)
微软2016年提出的Deep Crossing模型奠定了深度学习精排模型的基本架构,具有十分重要的意义。它采用“Embedding + MLP”的结构,成为目前推荐算法的基本范式。通过深度神经网络,实现大规模特征自动组合,大大减少了对人工构造交叉组合特征的依赖和开销。同时将残差网络第一次落地到推荐算法中,优化深度学习反向传播梯度弥散和过拟合等问题。并且完整解决了特征工程、Embedding稀疏向量稠密化等各种关键问题。虽然发表距今已有很多年,但仍然是一个非常重要的模型。
Deep Crossing论文地址,微软,2016年,KDD![]() https://dl.acm.org/doi/abs/10.1145/2939672.2939704
https://dl.acm.org/doi/abs/10.1145/2939672.2939704
1?Deep Crossing业务背景和特征体系
Deep Crossing是微软于2016年在 “Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features”[1]一文中提出,应用于其Bing搜索引擎的广告推荐中。用户输入搜索词后,搜索引擎在展示常规搜索结果时,会同时插入与搜索词相关的广告。广告主为广告的曝光、点击和转化付费,平台从而获得收益。在搜索引擎中,用户通过搜索词给出了自己的主动意图,所以与搜索词相关的广告通常都可以有不错的转化。谷歌、百度等搜索引擎行业的头部公司,其搜索广告业务均占有其公司总收入的很大比重。因此提升搜索广告的点击和转化,显然是一件非常重要且有意义的事情。
在传统机器学习算法中,我们一般需要搜集尽可能多的输入特征,从而对新的实例进行预测和分类。只使用原始特征,一般较难取的好的效果。在工业界和学术界,我们通常都需要花费很大一部分精力,对原始特征进行处理。一种重要的处理方法是,对多个原始特征进行交叉组合,然后将产出的新特征输入到机器学习模型中。特征交叉可以很好的提升模型表达能力,但如何做交叉一直是一个难题。Deep Crossing出现以前,大多数情况下还是通过手工构造交叉特征。在特征量大的场景下(比如搜索、推荐、广告),手工构造交叉特征,搜索空间十分大,成本会急剧上升。Deep Crossing创造性的提出用深度神经网络进行自动特征交叉,并在工业化场景下端到端完成了原始特征输入、Embedding降维、深度神经网络进行特征交叉、自动拟合目标等整个过程。
搜索广告场景主要包括用户侧特征、广告侧特征和上下文特征。目标是在指定的搜索词下,将最符合用户意图的广告展示给用户,从而提升用户体验和平台各项指标。使用的特征主要有:
-
搜索词(Query):用户在搜索框中输入的一段文本
-
?广告关键词(Keyword):广告主标记的广告关键词,用于匹配用户的搜索词
-
广告标题(Title):广告的标题,也是一段文本
-
广告落地页(Landing page):用户点击广告后的跳转页面,一般也是广告主来提供
-
匹配类型(Match Type):广告关键词和用户搜索词的匹配类型,主要有完全匹配、短语匹配、宽泛匹配和上下文匹配。
-
广告计划(Campaign):广告的配置信息,比如广告预算、目标位置等
-
广告曝光(Impression):广告展示给用户的一次曝光实例,一般在运行时,和其他信息一起被日志系统记录下来。?
-
广告点击(Click):用户对广告的一次点击实例,一般也是在运行时,和其他信息一起被日志系统记录下来。
-
点击率(Click through rate):广告的总点击数,除以广告的总曝光数。也就是广告被点击的后验概率。它能很大程度上反应广告未来被点击的概率,是搜索推荐广告系统中十分重要的后验统计数据。
-
点击预估(Click Prediction):另一个模型对广告CTR的预估值

上述特征主要分为两大类:类别型特征和数值型特征。
-
类别型特征:又叫ID型特征,它们一般是可枚举的。比如上述特征中的搜索词、广告关键词、广告标题、广告落地页、匹配类型、广告计划等,都属于类别型特征。类别型特征可以通过独热(one-hot)或者多热(multi-hot)进行编码。但如果特征枚举值比较多,比如上述中的广告计划,其枚举值是百万量级,会极大的增加模型体积。Deep Crossing怎么解决这一问题的呢?它将广告计划ID,按照历史点击数从高到底排序,取前10000个,编号从0到9999。剩下的共享同一个ID,编号为10000。通过这种长尾共享同一个ID的方式,可以优化枚举值过多,带来的模型体积剧增问题。这应该算是最早的Group Embedding方案吧。类别型特征枚举值过多,是我们经常会碰到的难题。它会导致模型体积过大、特征Embedding不收敛等问题。
-
数值型特征:文中又叫计数型特征(counting feature),它们一般是连续数值,不可枚举。比如上述特征中的点击率、点击预估等,都属于数值型特征。数值型特征一般分为两种处理方法。一种是直接将其特征值,拼接到堆叠层(Stacking Layer)的特征向量中。Deep Crossing等早期的模型一般采用这种方法。实现比较简单,但泛化能力不足,容易受异常值干扰。另一种是将数值型特征进行离散化,构建为可枚举的ID,然后再进行Embedding,最后和其他特征一起拼接到堆叠层中。这种方法实现复杂一些,但泛化能力强,抗噪能力也不错,还能为模型添加一定的非线性能力。目前大多数精排模型都采用这种方法。
2?Deep Crossing网络结构
今天回过头来看,Deep Crossing是一个相当普通的模型,它没有涉及到行为序列建模、记忆和泛化的处理、多任务建模等技术。但在当年却极为重要,它将深度学习应用到了搜索推荐场景,并展示了很多工业界完整落地的细节。当时主要难点有:
-
如何自动构建交叉特征。在Deep Crossing的年代,人们已经充分验证了交叉特征的重要性。但大多数情况下,特征交叉需要手工完成,会带来极大的成本。特别是搜索广告这种特征数量特别多的网络应用场景下,手工构建交叉特征几乎不可行。Deep Crossing使用深度神经网络,实现了自动构建交叉特征。
-
如何实现稀疏特征编码。通常情况下可以通过独热或者多热进行稀疏特征编码,然后再输入到模型中。但如果特征过于稀疏,枚举值过多,则会导致模型体积过大,无法有效训练和上线。Deep Crossing一方面采用Embedding降维的方式,实现了稀疏特征稠密化,并降低模型体积。另一方面对长尾ID进行聚合,同样大大降低了模型体积。
-
如何实现模型整个链路的端到端监督学习。Deep Crossing之前,虽然已经有论文在推荐场景中应用了深度学习,但工业界还没有模型可以整个链路端到端监督学习。Deep Crossing构建模型输出层和真实标签之间的损失,来充分拟合目标,从而实现端到端监督学习。
下面详细分析Deep Crossing的模型结构,从而理解这三个问题是如何得到解决的。Deep Crossing主要包括四层,从下到上,依次为Embedding层、Stacking层、Multiple Residual Units层和Scoring层。如下图所示。

2.1 Embedding层
Embedding层将高维稀疏的输入特征,转变为低维稠密的特征。推荐算法的Embedding层一般占了模型很大一部分体积。因此对于枚举值较多的特征,比如上述的广告计划(Campaign),Deep Crossing会让长尾者共享相同的ID,从而大幅降低特征枚举值,减小模型体积,保证可以顺利上线。对于搜索词和广告关键词等高维特征,Deep Crossing将他们的维度设置为256。维度低于256的特征,比如数值型特征,如图4-2中的特征2,则不需要进行Embedding,直接合并到Stacking层中。
Embedding层作为当前绝大多数推荐模型的第一层,包含了大部分的模型参数,其作用至关重要,相比于独热编码,优势主要有三点:
-
将高维稀疏的输入特征,转变为低维稠密的输出特征,实现降维和信息压缩。从而保证模型体积可控,最终可以顺利训练和上线。通常情况下,Embedding后的向量长度,要远小于独热编码向量长度。
-
特征语义化,提升模型泛化能力。同一特征组内,Embedding相似度较高的,其语义也是相近的,从而保证模型的泛化能力和鲁棒性。比如搜索词为“手机保护壳”和“手机套”时,广告结果应该大体相近。独热编码则没有这个能力。
-
可以与模型其他层参数一起,端到端训练更新。从而使得参数更加合理和准确。而独热编码的参数一般是不变的。
Embedding表征学习,作用大,难度高,是推荐算法精排模块中的重要研究方向。Embedding训练如何加快收敛,如何提升实时性?高维稀疏ID特征,向量维度大,枚举值多,如何降低参数量和模型体积?长尾ID特征样本不足,训练不充分,如何提升参数准确度?近年来,Graph Embedding、迁移学习等越来越多的方法不断涌现出来。
2.2?Stacking层
这一层比较简单,把Embedding层输出的特征向量,和没有经过Embedding处理的特征向量合并成一个长向量,然后输出给下一层。
2.3?Multiple Residual Units层
由多层残差单元(Residual Unit)堆叠而成。计算机视觉领域,由残差单元作为基本结构的ResNet[2]模型,一举夺得2015年ImageNet比赛冠军。它创造性的提出了残差单元,使得模型深度达到了惊人的152层,将深度学习推向了新的高度。Deep Crossing借鉴了ResNet的思想,在它的基础上做了一定修改,去掉了卷积网络。这是第一次将残差网络,应用到了计算机视觉之外的领域。
残差单元的结构如下图所示。原始输入特征经过两层全连接和ReLU激活变换后,得到输出特征。然后再将输出特征和原始输入特征相加,得到最终输出。
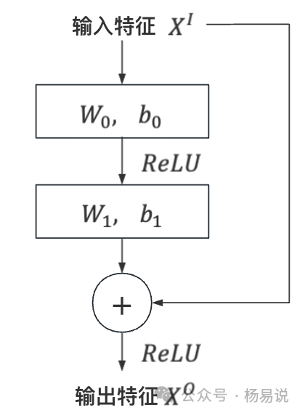
Multiple Residual Units层,由多层残差单元堆叠而成。这一层通过深度神经网络,实现了特征自动交叉,从而大大降低了人工构造交叉特征带来的成本,并提升了模型表达能力,和预估准确率。作者在实验中发现,Deep Crossing相比其他网络,泛化能力更好。它可以应用到各种不同的任务中。这跟残差网络起到了一定的正则作用,从而保证模型稳定性和鲁棒性,有一定的关系。
文中还对特征交叉时间点先后的问题进行了研究。Deep Crossing在堆叠层特征合并之后,就进行了特征交叉。而DSSM双塔模型,则只在最后一层,通过余弦相似度计算,实现特征交叉,比Deep Crossing要晚很多。实验结果证明,特征交叉早的Deep Crossing模型,效果要优于DSSM。一方面是因为Deep Crossing特征交叉更为充分,其每一层全连接都在进行特征交叉。另一方面特征交叉晚,导致底层低阶特征没有实现交叉,只是在上层高阶特征上完成了交叉。所以特征交叉一定要尽可能的早,尽可能的充分。目前粗排模型受困于性能问题,很多场景仍然在使用DSSM,导致缺少了特征交叉。如何在粗排中实现充分的特征交叉,是目前一个重要的研究方向。
2.4?Multiple Residual Units层Scoring层
模型的输出层。点击率预估是个经典的二分类问题,输出层一般有两种实现:
-
Sigmoid变换,此时上一层的输出是一个标量。将其归一化为0到1之间数值,代表点击的概率。Deep Crossing采用了这一方法。
-
Softmax变换,此时上一层的输出是一个向量,向量长度为预估类别的数量。比如二分类问题,向量长度则为2。将输出向量归一化为0到1之间数值,向量中每个值代表每个类别的预估概率。
目标函数:Deep Crossing采用了LogLoss,但也可以采用Softmax等其他函数。
3?Deep Crossing总结
Deep Crossing是深度学习应用到推荐算法中的一个革命性模型。它通过深度神经网络,实现了特征自动交叉,并第一次将残差网络应用到了计算机视觉之外的领域,大大提升了模型表达能力。它通过Embedding向量编码,解决了高维稀疏特征的建模问题,一举奠定了“Embedding + MLP”的深度学习推荐系统范式。它是工业界第一次实现深度学习推荐模型端到端训练,并披露了很多其中的细节,为后来工业界大规模应用深度学习打下了坚实的基础。
4 伪代码


5 实验效果
6 参考文献
[1]?Ying Shan, T Ryan Hoens, et al. 2016. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 255–262.
[2]?K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!