多线程高级知识点
多线程高级知识点
1.ThreadLocal
1.1 什么是 ThreadLocal?
??ThreadLocal?叫做本地线程变量,意思是说,ThreadLocal?中填充的的是当前线程的变量,该变量对其他线程而言是封闭且隔离的,ThreadLocal?为变量在每个线程中创建了一个副本,这样每个线程都可以访问自己内部的副本变量。
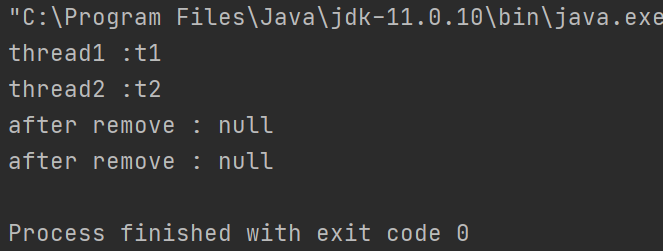
public class ThreadLocalTest {
static ThreadLocal<String> t = new ThreadLocal<>();
static void print(String str) {
//打印当前线程中本地内存中本地变量的值
System.out.println(str + " :" + t.get());
//清除本地内存中的本地变量
t.remove();
}
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
//设置线程 1 中本地变量的值
t.set("t1");
//调用打印方法
print("thread1");
//打印本地变量
System.out.println("after remove : " + t.get());
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
//设置线程 1 中本地变量的值
t.set("t2");
//调用打印方法
print("thread2");
//打印本地变量
System.out.println("after remove : " + t.get());
}
});
t1.start();
t2.start();
}
}

1.2ThreadLocal 原理
? ThreadLocal 类提供的几个方法:
public T get() { }//取值
public void set(T value) { }//设值
public void remove() { }//删除值
protected T initialValue() { }//初始化值默认返回 null,如果想在 get 之前不需要调用 set 就能正常访问的话,必须重写 initialValue() 方法。

? ThreadLocal 类中的 set 方法和 getMap 方法:
/**
* Sets the current thread's copy of this thread-local variable
* to the specified value. Most subclasses will have no need to
* override this method, relying solely on the {@link #initialValue}
* method to set the values of thread-locals.
*
* @param value the value to be stored in the current thread's copy of
* this thread-local.
*/
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}

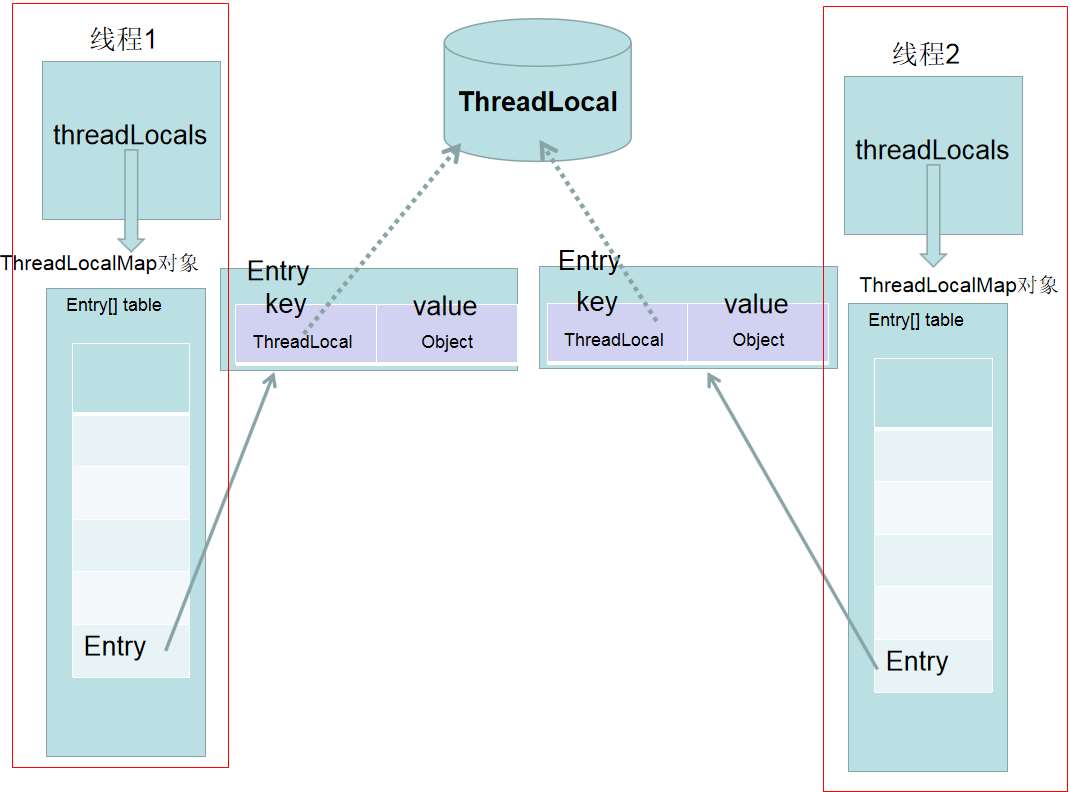
? 我们可以发现调用 ThreadLocal 的 set 方法时,传入的参数 value 会存入到一个 ThreadLocalMap 对象中。接着,我们找找 ThreadLocalMap 是从哪里来的,通过 getMap 方法,我们也不难发现 ThreadLocalMap 对象,就是当前线程的一个成员变量 threadLocals。
? 也就是说,每次我们每次往 ThreadLocal 中 set 值就是存入了当前线程对象的 threadLocals 属性里,而 threadLocals 的类型是 ThreadLocalMap。ThreadLocalMap 可以理解为 ThreadLocal 类实现的定制化的 HashMap。
? ThreadLocal 的 get 方法源码:
/**
* Returns the value in the current thread's copy of this
* thread-local variable. If the variable has no value for the
* current thread, it is first initialized to the value returned
* by an invocation of the {@link #initialValue} method.
*
* @return the current thread's value of this thread-local
*/
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}

? 同 set 方法一样,也是先根据当前线程获取 ThreadLocalMap 对象,然后在 map 中取值。
1.3 有哪些应用场景?
- 在进行对象跨层传递的时候,使用 ThreadLocal 可以避免多次传递,打破层次间的约束。
- 线程间数据隔离
- 进行事务操作,用于存储线程事务信息。
- 数据库连接,Session 会话管理。
1.4 ThreadLocal 是否会内存泄漏?
? Java 中的内存泄露,广义并通俗的说,就是:不再会被使用的对象的内存不能被回收,就是内存泄露。
? 当仅仅只有 ThreadLocalMap 中的 Entry 的 key 指向 ThreadLocal 的时候,ThreadLocal 会进行回收的!!!
? ThreadLocal 被垃圾回收后,在 ThreadLocalMap 里对应的 Entry 的键值会变成 null,但是 Entry 是强引用,那么 Entry 里面存储的 Object,并没有办法进行回收,所以有内存泄漏的风险。
弱引用也是用来描述非必需对象的,当 JVM 进行垃圾回收时,无论内存是否充足,该对象仅仅被弱引用关联,那么就会被回收。
2. 线程池
2.1 什么是线程池?
? 线程池,本质上是一种对象池,用于管理线程资源。 在任务执行前,需要从线程池中拿出线程来执行。 在任务执行完成之后,需要把线程放回线程池。 通过线程的这种反复利用机制,可以有效地避免直接创建线程所带来的坏处。
2.2 为什么使用线程池?
- 降低资源消耗,通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度,当任务到达时,任务可以不需要等到线程创建就立即执行。
- 提高线程的可管理性,线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以统一分配。
2.3 线程池实现原理
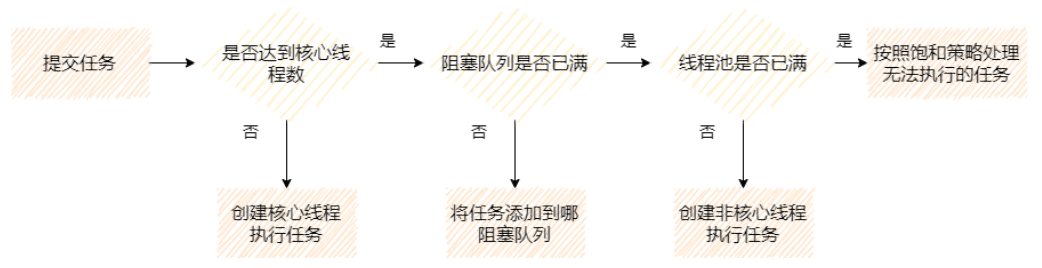
? 通过上图,我们看到了线程池的主要处理流程。我们的关注点在于,任务提交之后是怎么执行的。大致如下:
- 判断核心线程池是否已满,如果不是,则创建线程执行任务
- 如果核心线程池满了,判断队列是否满了,如果队列没满,将任务放在队列中
- 如果队列满了,则判断线程池是否已满,如果没满,创建线程执行任务
- 如果线程池也满了,则按照拒绝策略对任务进行处理。
2.4 拒绝策略
? jdk 自带 4 种拒绝策略:
CallerRunsPolicy?:当任务添加到线程池中被拒绝时,会在线程池当前正在运行的 Thread 线程池中处理被拒绝的任务。AbortPolicy?: 当任务添加到线程池中被拒绝时,它将抛出 RejectedExecutionException 异常。DiscardPolicy?:当任务添加到线程池中被拒绝时,线程池将丢弃被拒绝的任务。JDK 默认策略。DiscardOldestPolicy?:当任务添加到线程池中被拒绝时,线程池会放弃等待队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
? 这四种策略各有优劣,比较常用的是DiscardPolicy,但是这种策略有一个弊端就是任务执行的轨迹不会被记录下来。所以,我们往往需要实现自定义的拒绝策略, 通过实现RejectedExecutionHandler接口的方式。
2.5 execute() 和 submit() 区别?
? execute()和 submit() 的区别主要两点:
- execute()方法只能执行 Runnable 类型的任务。submit () 方法可以执行 Runnable 和 ca11ab1e 类型的任务。
- submit()方法可以返回持有计算结果的 Future 对象,同时还可以抛出异常,而 execute() 方法不可以。
换句话说就是,execute()方法用于提交不需要返回值的任务, submit ()方法用于需要提交返回值的 任务。
2.6 shutdown() 和 shutdownNow() 区别?
shutdown()会将线程池状态置为SHUTDOWN,不再接受新的任务,同时会等待线程池中已有的任务执行完成再结束。shutdownNow()会将线程池状态置为SHUTDOWN,对所有线程执行interrupt()操作,清空队列,并将队列中的任务返回回来。
3. volatile
3.1 volatile 的作用
? 一般作于变量,在多处理器开发的过程中保证了内存的可见性,适用于一写多读的场景。相比于 synchronized 关键字,volatile 关键字的执行成本更低,效率更高。
3.2 volatile 的特性
? 并发编程的三大特性为可见性、有序性和原子性。通常来讲 volatile 可以保证可见性和有序性。
- 可见性:volatile 可以保证不同线程对共享变量进行操作时的可见性。即当一个线程修改了共享变量时,另一个线程可以读取到共享变量被修改后的值。
- 有序性:volatile 会通过禁止指令重排序进而保证有序性。
- 原子性:对于单个的 volatile 修饰的变量的读写是可以保证原子性的,但对于 i++ 这种复合操作并不能保证原子性。这句话的意思基本上就是说 volatile 不具备原子性了。
3.3 volatile 和 synchronized 区别?
- volatile 是在告诉 jvm 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取,synchronized 则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile 仅能使用在变量级别;synchronized 则可以使用在变量、方法和类级别的
- volatile 仅能实现变量的修改可见性,不能保证原子性;而 synchronized 则可以保证变量的修改可见性和原子性
- volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
- volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化
4. 常见锁
4.1 乐观锁 VS 悲观锁
? 乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。
? 悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。
? 乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
4.2 自旋锁 VS 适应性自旋锁
? 阻塞或唤醒一个 Java 线程需要操作系统切换 CPU 状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
? 在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃 CPU 的执行时间,看看持有锁的线程是否很快就会释放锁。
? 而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
? 自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是 10 次,可以使用-XX:PreBlockSpin 来更改)没有成功获得锁,就应当挂起线程。
??自适应的自旋锁(适应性自旋锁)自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
4.3 可重入锁 VS 非可重入锁
??可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者 class),不会因为之前已经获取过还没释放而阻塞。
??非可重入锁,则与上面相反,会线程出现死锁,整个等待队列中的所有线程都无法被唤醒。
4.4 独享锁 VS 共享锁
??独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程 T 对数据 A 加上排它锁后,则其他线程不能再对 A 加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。
??共享锁是指该锁可被多个线程所持有。如果线程 T 对数据 A 加上共享锁后,则其他线程只能对 A 再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
4.5 公平锁 VS 非公平锁
??公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大。
??非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
5. 线程间通信
5.1 线程间通信
? Java 线程通信是将多个独立的线程个体进行关联处理,使得线程与线程之间能进行相互通信。比如线程 A 修改了对象的值,然后通知给线程 B,使线程 B 能够知道线程 A 修改的值,这就是线程通信。
5.2 wait/notify 机制
? 一个线程调用 Object 的 wait() 方法,使其线程被阻塞;另一线程调用 Object 的 notify()/notifyAll() 方法,wait() 阻塞的线程继续执行。
- wait():让当前线程释放对象锁并进入等待(阻塞)状态。
- notify():唤醒一个正在等待相应对象锁的线程,使其进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到 CPU 的执行。
- notifyAll():唤醒所有正在等待相应对象锁的线程,使它们进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到 CPU 的执行。
wait()、notify() 和 notifyAll() 三个方法来实现,这三个方法均非 Thread 类中所声明的方法,而是 Object 类中声明的方法。原因是每个对象都拥有 monitor(锁),所以让当前线程等待某个对象的锁,当然应该通过这个对象来操作,而不是用当前线程来操作,因为当前线程可能会等待多个线程的锁,如果通过线程来操作,就非常复杂了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!