深度学习:混合精度训练
前言
浮点数据类型主要分为双精度Double(FP64)、单精度Float(FP32)和半精度Half(FP16)。FP64浮点数据采用8个字节共64位,来进行的编码存储的一种数据类型;FP32浮点数据采用4个字节共32位来表示;FP16浮点数据则采用2个字节共16位来表示。
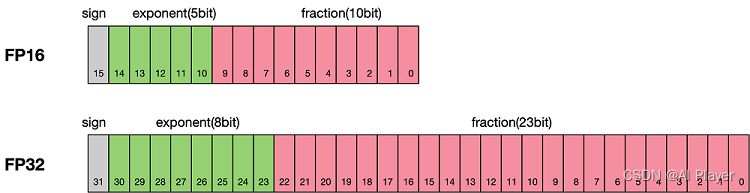
默认情况下,大多数深度学习框架(比如Pytorch)都采用32位浮点算法进行训练,混合精度训练可以在神经网络训练过程中,针对不同的层,采用不同的数据精度(比如半精度16位)进行计算,从而实现降低显存和加快速度的目的。
混合精度训练
在此主要介绍了混合精度训练的核心技术、优缺点和代码示例。
核心技术
混合精度训练过程中,主要使用了权重备份和损失缩放两大方法,此外还可以引入梯度裁剪和动态调整学习率等相关技术,提高训练稳定性,从而发挥混合精度训练的优势,并尽可能避免混合精度训练的弊端。
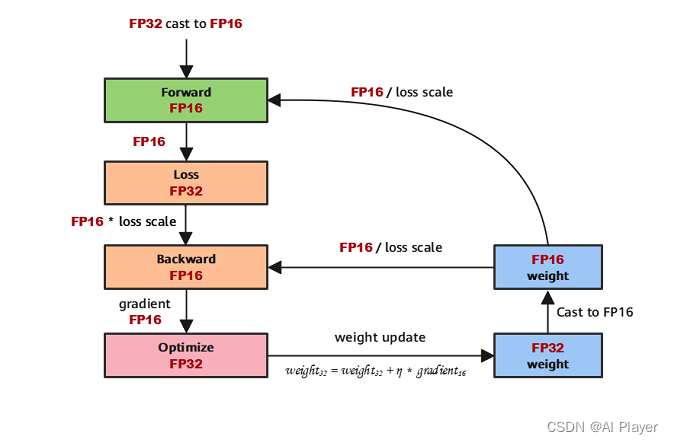
权重备份
如果直接全部采用FP16的精度进行模型训练,由于梯度幅值本身非常小,参数更新的时候乘上学习率就更小了,容易导致 NAN 或者参数更新失败(无法更新)的问题,故模型参数更新需要采用 FP32 格式上操作,因此需要维护一份 FP32 的模型参数副本,并利用FP16的梯度更新FP32模型的参数。值得注意的是,这里备份的模型副本增加的主要是静态内存。只要动态内存的值基本都是使用FP16来进行存储,则最终模型与整网络使用FP32进行训练相比起来, 内存占用也基本能够减半。
损失缩放
使用损失缩放的原因是 FP16 的梯度表示范围比较窄,如果不做处理,大量非零梯度会遇到溢出问题,那么即使后续是采用 FP32 参数更新也是没用的。故需要设置一个缩放系数(loss scale),将前向传播得到的Loss进行放大,放大到 16 精度可表示范围,但是需要注意在反向传播后需要除以缩放系数,将权重缩小后更新模型的参数。
动态损失缩放:上面提到的损失缩放都是使用一个默认值对损失值进行缩放,为了充分利用FP16的动态范围,可以更好地缓解舍入误差,尽量使用比较大的放大倍数。总结动态损失缩放算法,就是每当梯度溢出时候减少损失缩放规模,并且间歇性地尝试增加损失规模,从而实现在不引起溢出的情况下使用最高损失缩放因子,更好地恢复精度。
梯度裁剪
由于半精度浮点数表示的梯度较小,容易出现数值溢出或数值过小的问题。为了解决这个问题,采用梯度裁剪的方法,限制梯度的范围,防止梯度消失或爆炸。
动态调整学习率
随着训练的进行,动态地调整学习率以适应使用半精度浮点数时可能出现的数值不稳定性。这有助于提高训练的稳定性和收敛速度。
优势与弊端
混合精度训练的核心思想是将神经网络中的参数和梯度使用更低位数的浮点数表示,通常是16位半精度浮点数。混合精度的优势在于主要在于减小显存占用和加快训练速度方面。
- 减少显存占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,从而可以使用更大的模型或更多的数据进行训练。
- 加快通讯效率:对于分布式训练,特别是在大模型训练的过程中,通讯的开销往往会增大训练时间,使用低精度的数据,由于较小的位宽可以提高通讯效率,从而加快模型训练。
- 计算效率更高:使用低精度的数据,执行运算性能也更高,从而加快模型训练,特别是在支持混合精度的硬件上(如NVIDIA的Volta架构及以后的GPU)。
弊端在于:
- 数据溢出:FP16数据类型的有效数据范围比FP32数据类型的有效数据范围小,使用FP16替换FP32就会出现上溢(Overflow)或下溢(Underflow),从而容易出现数值不稳定性的问题,需要采用一些技术手段来处理。
- 精度损失:FP16和FP32的最小间隔(精确度)不同,从FP32转换到FP16就会出现强制舍入,从而带来一定的精度损失。
- 训练不稳定:使用混合精度训练容易出现NAN和参数无法更新的问题,需要精心设计超参数,以提高训练的稳定性。
- 硬件依赖: 混合精度训练的效果受到硬件支持的限制,只有支持半精度浮点数运算的硬件才能发挥其优势。
代码示例
为了演示混合精度训练的流程,下面是Pytorch官方代码示例,供参考:
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!