MsSQL中的索引到底长啥样,查找过程怎么进行
2023-12-22 16:40:33
建表
mysql> create table user(
-> id int(10) auto_increment,
-> name varchar(30),
-> age tinyint(4),
-> primary key (id),
-> index idx_age (age)
-> )engine=innodb charset=utf8mb4;
insert into user(name,age) values('张三',30);
insert into user(name,age) values('李四',20);
insert into user(name,age) values('王五',40);
insert into user(name,age) values('刘八',10);
mysql> select * from user;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 30 |
| 2 | 李四 | 20 |
| 3 | 王五 | 40 |
| 4 | 刘八 | 10 |
+----+--------+------+
聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引(Primary Key)就属于聚簇索引。
非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(Secondary Index)就属于非聚簇索引。
聚簇索引(Clustered Index)和 非聚簇索引(Non-Clustered Index) 是从 索引结构和数据存放方面 来对索引来划分类型。
数据表的主键列使用的就是主键索引(Primary Key)。
二级索引(Secondary Index)又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
唯一索引,普通索引,前缀索引等索引属于二级索引。
id 字段是主键索引,age 字段是二级索引(辅助索引)。
所以 id 字段是聚簇索引,age 字段是非聚簇索引。
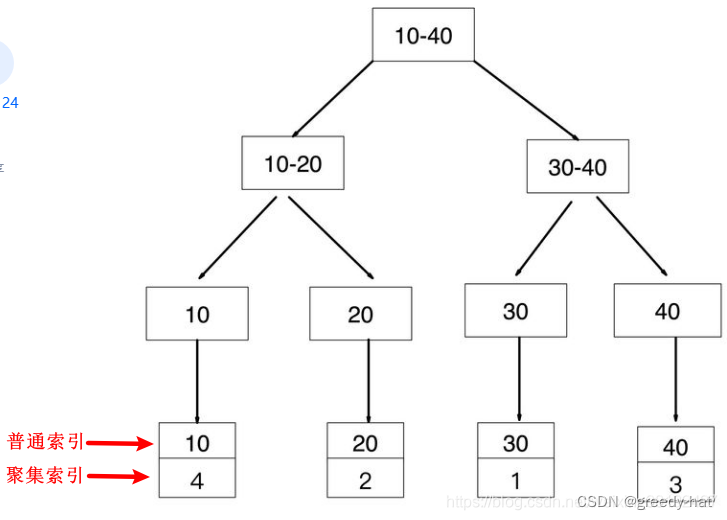
索引结构
id 是主键,所以是聚簇索引,其叶子节点存储的是 id 主键对应的行记录的数据。
id 索引结构

age 索引结构
查找过程
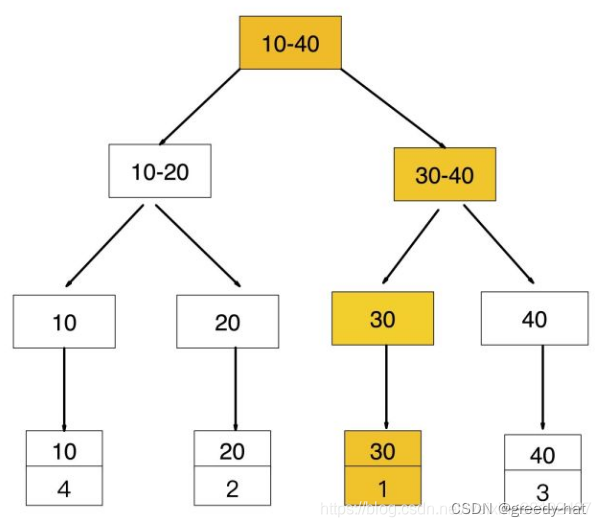
查找id
如果查询条件为主键(聚簇索引),则只需扫描一次 B+ Tree 即可通过聚簇索引定位到要查找的行记录数据
select * from user where id = 1

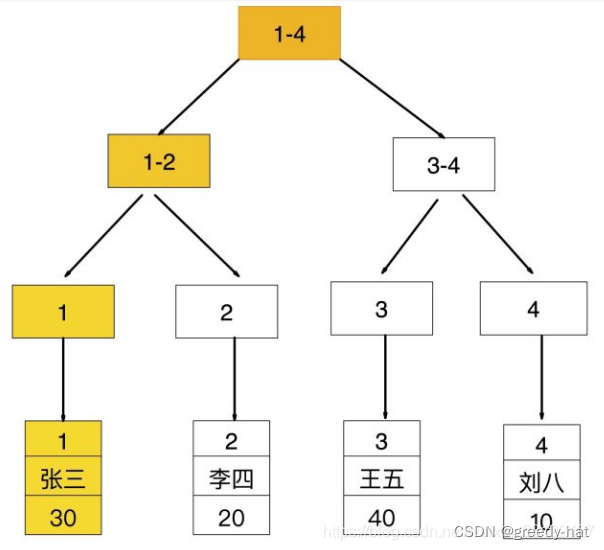
查找age
查询条件为普通索引(非聚簇索引),需要扫描两次 B+ Tree,
第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据(第二次查询也称为回表查询)。
select * from user where age = 30;
tips
覆盖索引
- 覆盖索引是指一个索引包含了查询语句中所需的所有字段,因此可以直接返回查询结果而不需要进行回表查询。
- 优点在于它能够减少磁盘 I/O 和提高查询性能,因为数据库引擎可以直接从索引中获取所需的数据,而不必去实际的数据表中获取。
联合索引
联合索引是指针对多个字段创建的单个索引,它可以涵盖多个字段的查询条件,并且在某些情况下可以提高查询效率。
文章来源:https://blog.csdn.net/qq_41638851/article/details/135154667
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!