【非关系型数据库】Redis概述及安装、命令使用
目录
HSET/HGET/HDEL/HEXISTS/HLEN/HSETNX
?HGETALL/HKEYS/HVALS/HMGET/HMSET
ZADD/ZCARD/ZCOUNT/ZREM/ZINCRBY/ZSCORE/ZRANGE/ZRANK
?ZRANGEBYSCORE/ZREMRANGEBYRANK/ZREMRANGEBYSCORE
ZREVRANGE/ZREVRANGEBYSCORE/ZREVRANK?
前瞻
关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostgreSQL 等。
以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败。
非关系型数据库
NoSQL(NoSQL = Not Only SQL ),意思是“不仅仅是 SQL”,是非关系型数据库的总称。
除了主流的关系型数据库外的数据库,都认为是非关系型。
不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
主流的 NoSQL 数据库有 Redis、MongBD、Hbase、Memcached、ElasticSearch、TSDB 等。
关系型数据库和非关系型数据库区别
数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
非关系型数据库产生背景
可用于应对 Web2.0 纯动态网站类型的三高问题(高并发、高性能、高可用)。
- High performance——对数据库高并发读写需求
- Huge Storage——对海量数据高效存储与访问需求
- High Scalability && High Availability——对数据库高可扩展性与高可用性需求
总结?
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。让关系型数据库关注在关系上和对数据的一致性保障,非关系型数据库关注在存储和高效率上。例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
关系型数据库:
实例-->数据库-->表(table)-->记录行(row)、数据字段(column)
非关系型数据库:
实例-->数据库-->集合(collection)-->键值对(key-value)
非关系型数据库不需要手动建数据库和集合(表)。
Redis简介
什么是Redis
Redis(远程字典服务器) 是一个开源的、使用 C 语言编写的 NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
Redis具有的优点
- 具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
- 支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Sorted Sets 等数据类型操作。
- 支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 原子性:Redis 所有操作都是原子性的。
- 支持数据备份:即 master-salve 模式的数据备份。
?Redis使用场景
Redis作为基于内存运行的数据库,是一个高性能的缓存,一般应用在Session缓存、队列、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等。
Redis 适用于数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需要保证弱一致性、逻辑简单的场景。
我们通常会将部分数据放入缓存中,来提高访问速度,然后数据库承担存储的工作。
哪些数据适合放入缓存中?
- 即时性。例如查询最新的物流状态信息。
- 数据一致性要求不高。例如门店信息,修改后,数据库中已经改了,五分钟后缓存中才是最新的,但不影响功能使用。
- 访问量大且更新频率不高,例如网站首页的广告信息,访问量大,但是不会经常变化。
?Redis为什么这么快?
- Redis是一款纯内存结构,避免了磁盘I/O等耗时操作。
- Redis命令处理的核心模块为单线程,不存在多线程切换而消耗CPU,不用考虑各种锁的问题,不存在加锁、释放锁的操作,没有因为可能出现死锁而导致性能消耗。
- 采用了 I/O 多路复用机制,大大提升了并发效率。
注:在 Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的。
Redis安装部署
环境准备
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config?修改内核参数
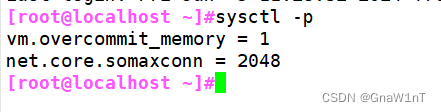
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 2048
 ?
?
?安装redis
yum install -y gcc gcc-c++ make
tar zxvf /opt/redis-7.0.9.tar.gz -C /opt/
cd /opt/redis-7.0.9
make
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。?创建redis工作目录
mkdir /usr/local/redis/{conf,log,data}
cp /opt/redis-7.0.9/redis.conf /usr/local/redis/conf/
useradd -M -s /sbin/nologin redis
chown -R redis.redis /usr/local/redis/?环境变量
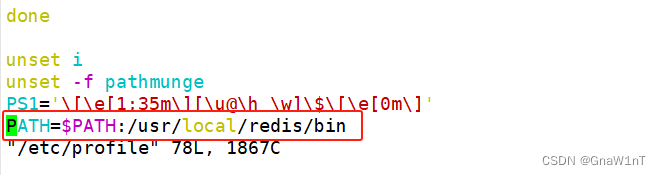
vim /etc/profile
PATH=$PATH:/usr/local/redis/bin #增加一行
source /etc/profile
 ?
?
?修改配置文件
vim /usr/local/redis/conf/redis.conf
bind 127.0.0.1 192.168.80.10 #87行,添加 监听的主机地址
protected-mode no #111行,将本机访问保护模式设置no。如果开启了,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应
port 6379 #138行,Redis默认的监听6379端口
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目录
requirepass abc123 #1037行,增加一行,设置redis密码
?







?定义systemd服务管理脚本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target
[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
 ?
?
?启动服务
systemctl start redis-server
systemctl enable redis-server
netstat -lntp | grep 6379
?
Redis命令工具
redis-server:Redis 服务器启动命令
redis-benchmark:性能测试工具,用于检测 Redis 在本机的运行效率
redis-check-aof:修复有问题的 AOF 持久化文件
redis-check-rdb:修复有问题的 RDB 持久化文件
redis-cli:Redis 客户端命令行工具
redis-sentinel:Redis 哨兵集群使用
redis-cli 命令行工具
语法:redis-cli -h host -p port [-a password]
-h :指定远程主机
-p :指定 Redis 服务的端口号
-a :指定密码,未设置数据库密码可以省略-a 选项
若不添加任何选项表示,则使用 127.0.0.1:6379 连接本机上的 Redis 数据库

redis-benchmark 测试工具
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
基本的测试语法:redis-benchmark [选项] [选项值]。
-h :指定服务器主机名。
-p :指定服务器端口。
-s :指定服务器 socket
-c :指定并发连接数。 ?
-n :指定请求数。
-d :以字节的形式指定 SET/GET 值的数据大小。
-k :1=keep alive 0=reconnect 。
-r :SET/GET/INCR 使用随机 key, SADD 使用随机值。
-P :通过管道传输<numreq>请求。
-q :强制退出 redis。仅显示 query/sec 值。
--csv :以 CSV 格式输出。
-l :生成循环,永久执行测试。
-t :仅运行以逗号分隔的测试命令列表。
-I :Idle 模式。仅打开 N 个 idle 连接并等待。
例:
向 IP 地址为 192.168.75.10、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
![]()

?测试存取大小为 100 字节的数据包的性能

?测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能

Redis数据库常用命令
set:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?存放数据
get:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?获取数据type 键 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?查看键的数据类型
keys 键 * ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?查询键名,支持通配符 * ?
exists 键 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?判断键是否存在
expire 键 过期时间 ? ? ? ? ? ? ? ? ? ? ? ? ? 为已存在的键设置过期时间
setex 键 过期时间 值 ? ? ? ? ? ? ? ? ? ? ? ? 创建string类型的键并设置过期时间
ttl 键 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 查看键的生命周期时间,-1 永不过期,-2 已过期
rename 旧键 新键 ? ? ? ? ? ? ? ? ? ? ? ? ? ? 重命名键名,会覆盖已存在的键
renamenx 旧键 新键 ? ? ? ? ? ? ? ? ? ? ? ? ? 重命名键名,不会覆盖已存在的键
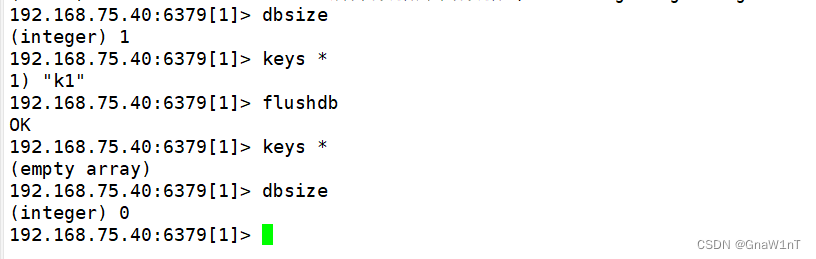
dbsize ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 统计当前库中键的总数
config set requirepass '密码' ? ? ? ? ? ? ? ?设置/修改redis密码
config get requirepass ? ? ? ? ? ? ? ? ? ? ? 查看密码
auth '密码' ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?在redis里验证密码
select 库ID ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?切换库,默认库ID为 0~15
move 键 库ID ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 移动键到指定的库
flushdb ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?清空当前库(慎用)
flushall ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 清空所有库(慎用)
set:存放数据,命令格式为 set key value
get:获取数据,命令格式为 get key

keys 命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用。

 ?exists 命令可以判断键值是否存在。
?exists 命令可以判断键值是否存在。

?del 命令可以删除当前数据库的指定 key。

?type 命令可以获取 key 对应的 value 值类型。
?
?expire 命令可以为给定的 key 设置过期时间

?rename 命令是对已有 key 进行重命名。(覆盖)
命令格式:rename 源key 目标key
使用rename命令进行重命名时,无论目标key是否存在都进行重命名,且源key的值会覆盖目标key的值。在实际使用过程中,建议先用 exists 命令查看目标 key 是否存在,然后再决定是否执行 rename 命令,以避免覆盖重要数据。

?renamenx 命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
命令格式:renamenx 源key 目标key

?dbsize 命令的作用是查看当前数据库中 key 的数目。

?使用config set requirepass yourpassword命令设置密码

?使用config get requirepass命令查看密码(一旦设置密码,必须先验证通过密码,否则所有操作不可用)

Redis多数据库常用命令
Redis 支持多数据库,Redis 默认情况下包含 16 个数据库,数据库名称是用数字 0-15 来依次命名的。
多数据库相互独立,互不干扰。
多数据库间切换
命令格式:select 序号
使用 redis-cli 连接 Redis 数据库后,默认使用的是序号为 0 的数据库。

?多数据库间移动数据
格式:move 键值 序号

清除数据库内数据
FLUSHDB :清空当前数据库数据
FLUSHALL :清空所有数据库的数据,慎用!
?Redis五大数据类型的增查删
String数据类型
概述:String是redis最基本的类型,最大能存储512MB的数据,String类型是二进制安全的,即可以存储任何数据、比如数字、图片、序列化对象等
SET/GET/APPEND/STRLEN

 ?
?



INCR/DECR/INCRBY/DECRBY?





?
![]()



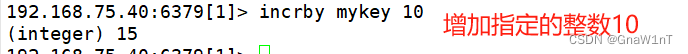
GETSET?



SETEX?


![]()


?SETNX




?MSET/MGET/MSETNX






List数据类型
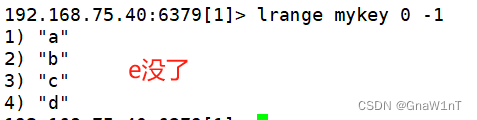
概述:列表的元素类型为string,按照插入顺序排序,在列表的头部或尾部添加元素
?LPUSH/LPUSHX/LRANGE








LPOP/LLEN?



LREM/LSET/LINDEX/LTRIM?
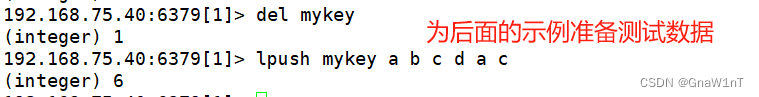










?LINSERT?







RPUSH/RPUSHX/RPOP/RPOPLPUSH?













Hash数据类型(散列类型)
概述:hash用于存储对象。可以采用这样的命名方式:对象类别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值。 如:存储 ID 为 2 的汽车对象。
如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对。
HSET/HGET/HDEL/HEXISTS/HLEN/HSETNX











HINCRBY?





?HGETALL/HKEYS/HVALS/HMGET/HMSET





Set数据类型(无序集合)?
概述:无序集合,元素类型为String类型,元素具有唯一性,不允许存在重复的成员。多个集合类型之间可以进行并集、交集和差集运算。
应用范围:
1.可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性。
2.充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如所有购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们想获取有哪些客户同时购买了这两种商品时,Set的intersections命令就可以充分发挥它的方便和效率的优势了。
SADD/SMEMBERS/SCARD/SISMEMBER






SPOP/SREM/SRANDMEMBER/SMOVE?













?Sorted Set数据类型(zset、有序集合)
概述:a、有序集合,元素类型为Sting,元素具有唯一性,不能重复。
b、每个元素都会关联一个double类型的分数score(表示权重),可以通过权重的大小排序,元素的score可以相同。
应用范围:
1)可以用于一个大型在线游戏的积分排行榜。每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOP10的用户信息。当然我们也可以利用ZRANK命令通过username来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。
2)Sorted-Set类型还可用于构建索引数据。
ZADD/ZCARD/ZCOUNT/ZREM/ZINCRBY/ZSCORE/ZRANGE/ZRANK














?ZRANGEBYSCORE/ZREMRANGEBYRANK/ZREMRANGEBYSCORE








ZREVRANGE/ZREVRANGEBYSCORE/ZREVRANK?







本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!