[玩转AIGC]LLaMA2之如何微调模型
2023-12-28 19:45:39
1、下载训练脚本
首先我们从github上下载Llama 2的微调代码:GitHub - facebookresearch/llama-recipes: Examples and recipes for Llama 2 model
执行命令:
git clone https://github.com/facebookresearch/llama-recipes
cd llama-recipes
下载完成之后,安装对应环境,执行命令:
pip install -r requirements.txt
2、 下载模型
在这里我补充一下模型下载权限的申请
2.1、申请下载权限
需先在Meta上申请权限(国家选中国不行,要选其他国家)
https://ai.meta.com/resources/models-and-libraries/llama-downloads/
申请的邮箱必须是跟huggingface注册邮箱一致
申请完权限之后你会收到邮件:
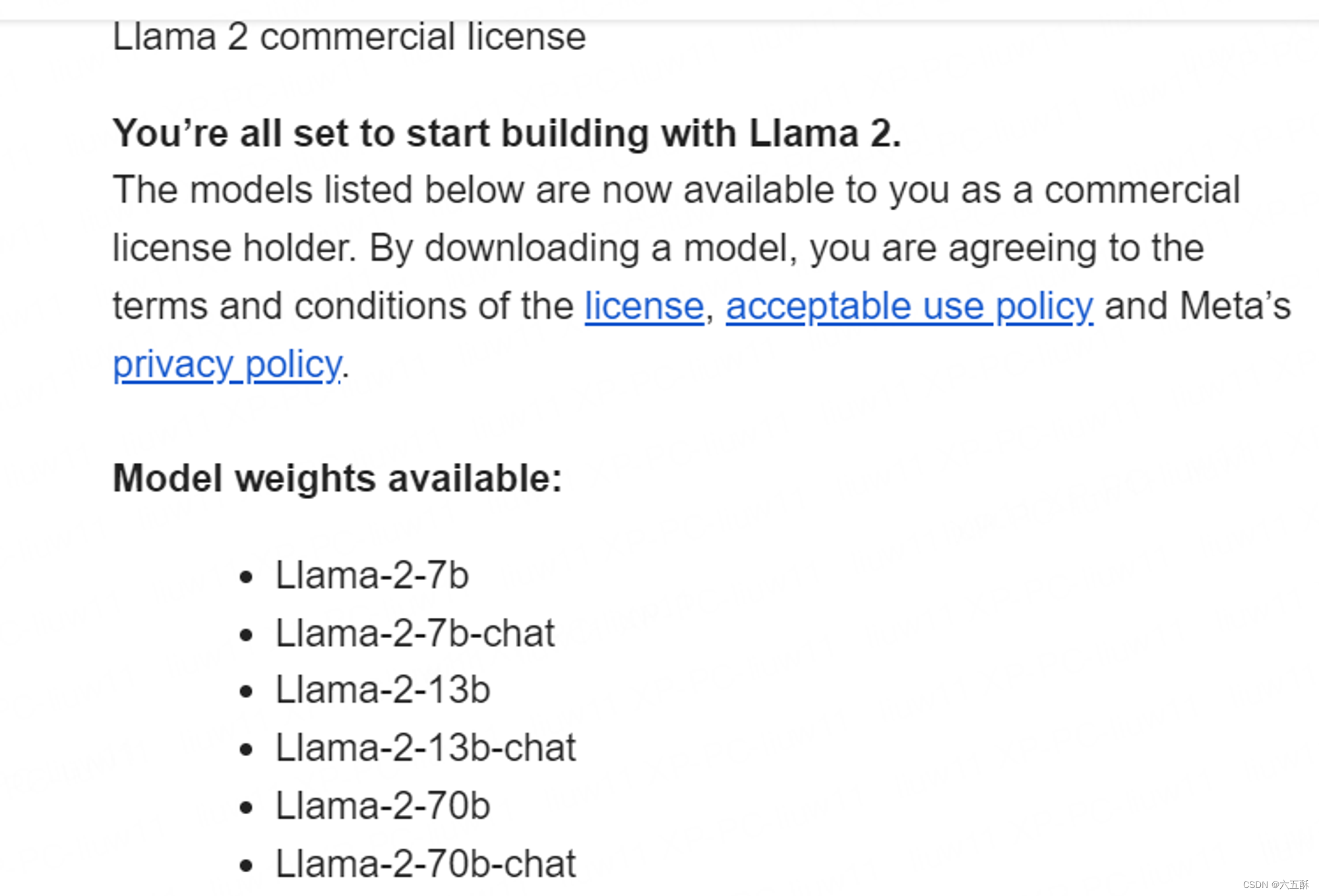
然后再去HuggingFace上submit权限申请,连接在下面
https://huggingface.co/meta-llama/Llama-2-7b-hf
打开后点击提交:
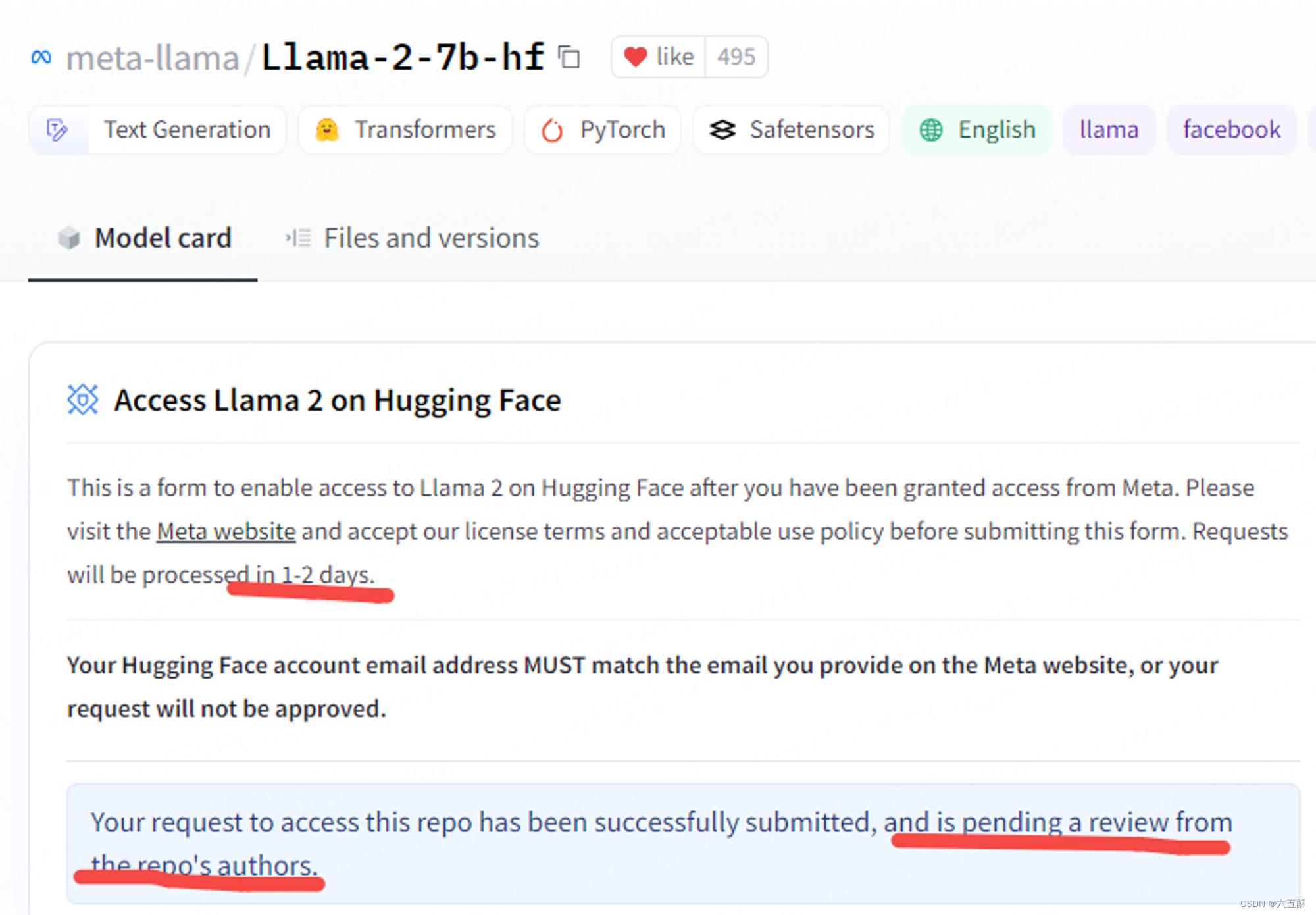
提交后还要等待仓库作者的确认,请求将在 1-2 天内得到处理
实测大概一个小时,会有邮件通知已授权,邮件如下:
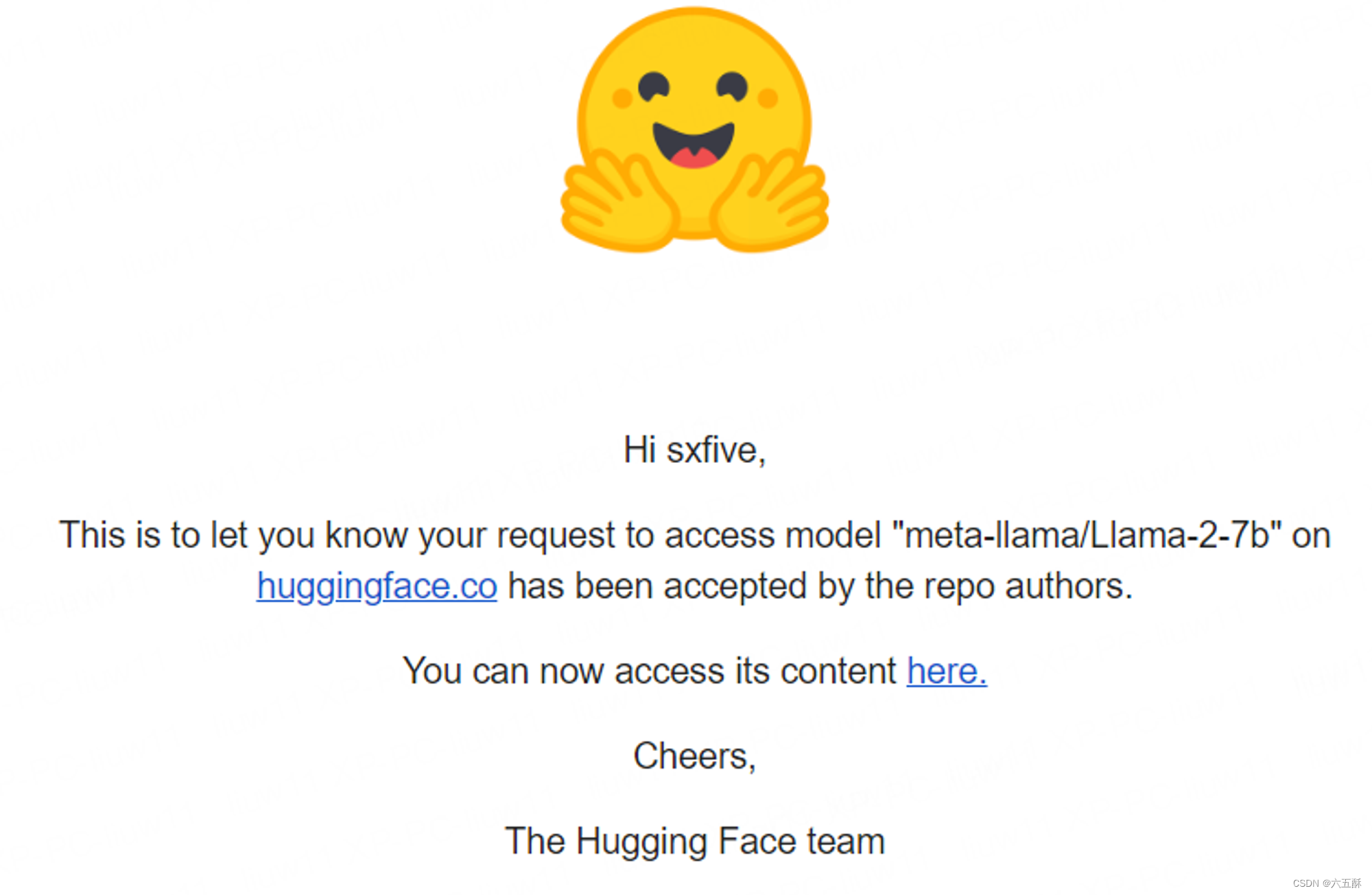
然后回到HuggingFace
点击头像->setting->Access Tokens 里面获取tokens
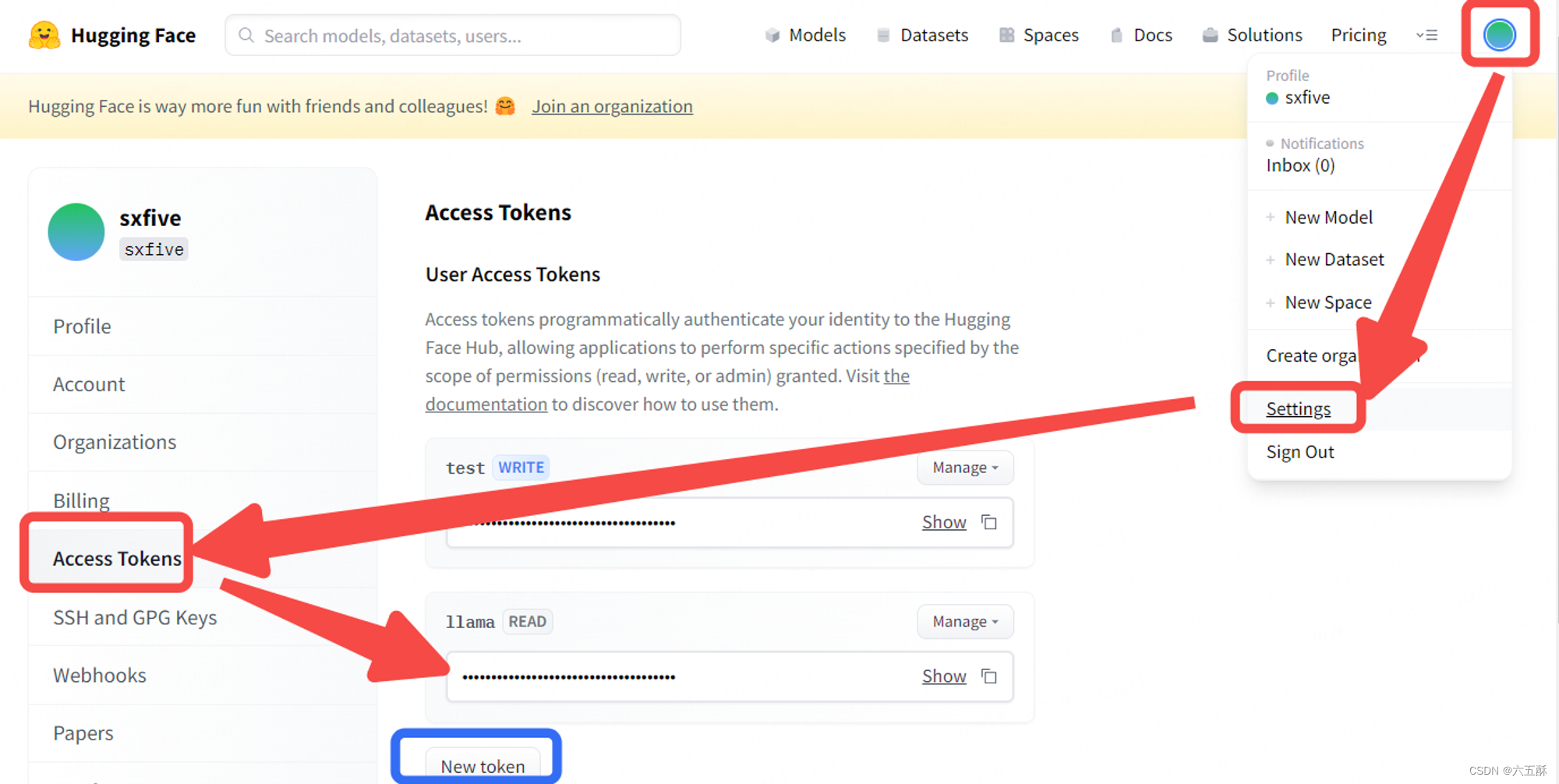
没有的话就自己创建一个token,也就是点击new token,再把创建的token复制下来
2.2、模型下载
有了权限就可以从HuggingFace上下载模型:https://huggingface.co/meta-llama
打开可看到模型有多个:
这里我们选择:Llama-2-7b-hf
通过代码下载:
下面的your token就是要填从你自己的HuggingFace复制下来的token,根据上面的步骤走过来,你已经申请过权限了,所以token可用
import huggingface_hub
huggingface_hub.snapshot_download(
"meta-llama/Llama-2-7b-hf",
local_dir="./Llama-2-7b-hf",
token="your token"
)
import huggingface_hub
huggingface_hub.snapshot_download(
"meta-llama/Llama-2-7b-hf",
local_dir="./Llama-2-7b-hf",
token="**********************"
)
3、模型微调
3.1、使用单卡微调
#创建模型输出文件
mkdir output
# 使用单卡
export CUDA_VISIBLE_DEVICES=0
#开始训练
python llama_finetuning.py --use_peft --peft_method lora --quantization --model_name Llama-2-7b-hf --output_dir output
3.2、使用多卡训练:
比如多GPU单节点
torchrun --nnodes 1 --nproc_per_node 4 examples/finetuning.py --enable_fsdp --use_peft --peft_method lora --model_name /path_of_model_folder/7B --fsdp_config.pure_bf16 --output_dir path/to/save/PEFT/model
文章来源:https://blog.csdn.net/qq_27149279/article/details/135275723
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!