mmseg上手自己的数据集
2023-12-14 19:59:03
- 制作自己的数据集,VOC格式为例。
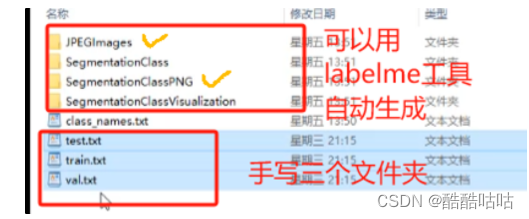
这三个文件包括数据集的名称。可以使用labelme脚本自动生成。
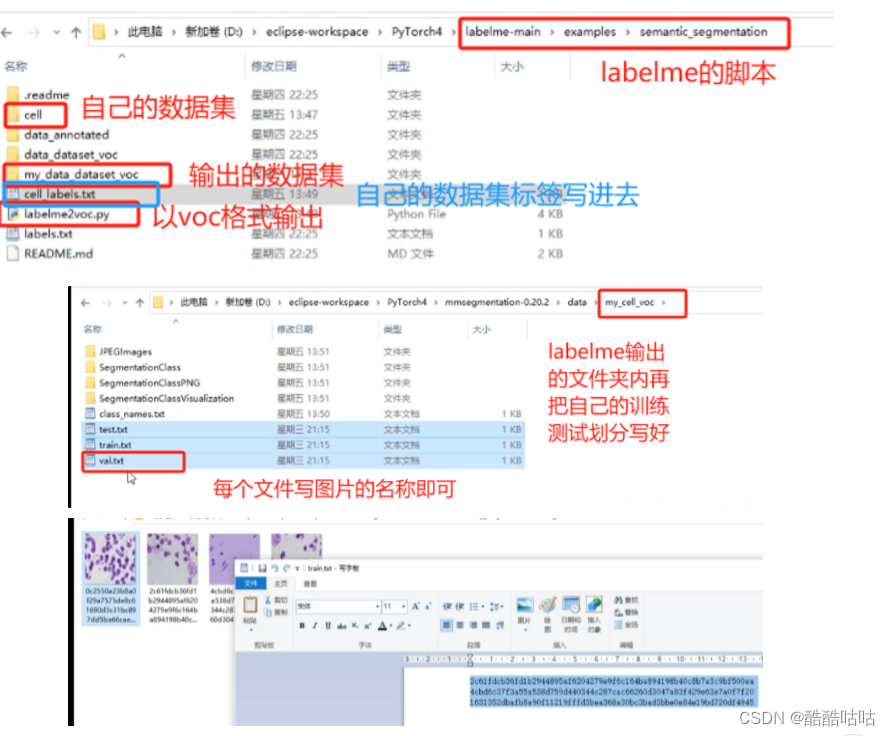
- 跟据预测类别修改配置文件
D:\projects\mmsegmentation-main\mmseg\datasets\voc.py
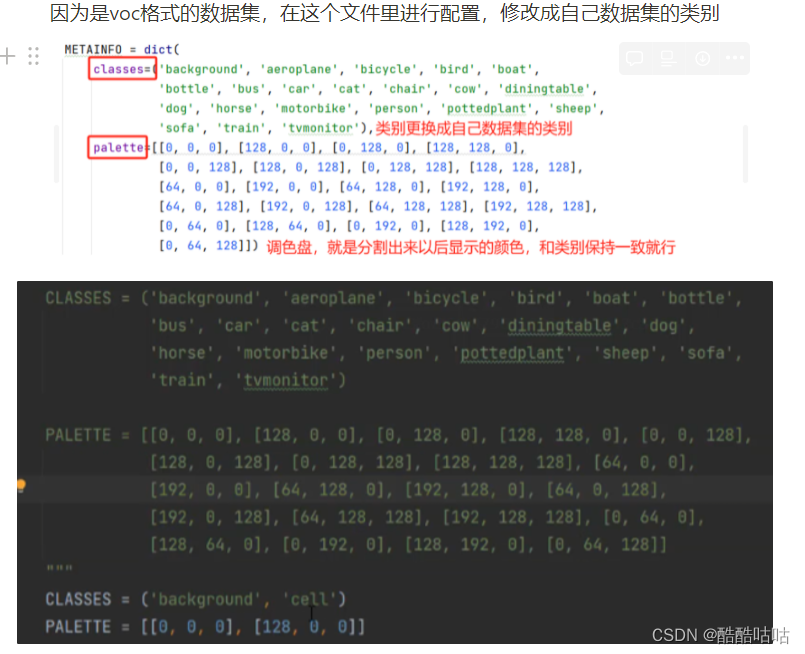
因为是voc格式的数据集,在这个文件里进行配置,修改成自己数据集的类别
- 加载预训练模型开始训练
D:\projects\mmsegmentation-main\configs\upernet\upernet_r18_4xb4-20k_voc12aug-512x512.py
选择一个适合自己数据集的模型
D:\projects\mmsegmentation-main\tools\train.py
在train.py文件中进行训练,执行结束后在tools/work_dir文件中找到刚才训练的结果,找到刚刚生成的py文件 复制到config中
在该文件中进行修改:
num_classes(不要忘记还有个背景类别)
data = dict{ }中修改data_root
修改 train val test
如果使用公开数据集,就按照官方文档的格式整理
预训练的模型在官网下载一下:对实验结果影响挺大
https://mmsegmentation.readthedocs.io/zh-cn/latest/model_zoo.html
文章来源:https://blog.csdn.net/weixin_43614026/article/details/134931815
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!