AUTOSAR_SWS_LogAndTrace文档中文翻译
**
1 Introduction and functional overview
**
本规范规定了AUTOSAR自适应平台日志和跟踪的功能。
日志和跟踪为AA提供接口,以便将日志信息转发到通信总线、控制台或文件系统。
提供的每个日志记录信息都有自己的严重性级别。对于每个严重级别,都提供了一个单独的方法供应用程序或自适应平台服务使用,例如ara::com。此外,提供了将十进制值转换为十六进制数字系统或二进制数字系统的实用方法。
为了将提供的日志记录信息打包成标准化的交付和表示格式,需要一个协议。为此,可以使用在AUTOSAR联盟内标准化的LT协议。
LT协议可以将附加信息添加到所提供的日志记录信息中。日志客户端可以使用这些信息来关联、排序或过滤接收到的日志帧。
关于用例和LT协议本身的详细信息由PRS日志和跟踪协议规范提供。有关LT协议的更多信息,请参阅[1]
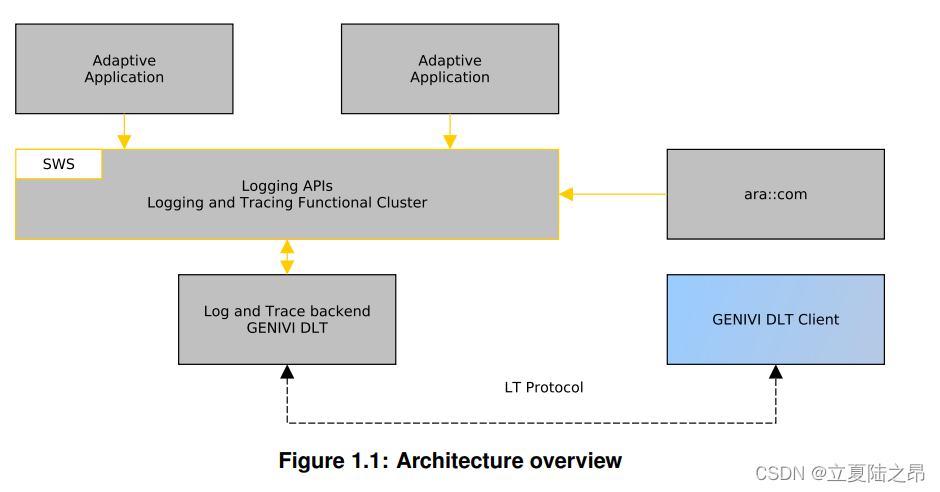
此外,本文件还介绍了AUTOSAR自适应平台日志和跟踪。此外,本文档还介绍了对AUTOSAR自适应台日志和跟踪的附加规范扩展
**
2 Acronyms and Abbreviations
**

3 Input documents & related standards and norms 输入文件及相关标准规范
[1] Log and Trace Protocol Specification
AUTOSAR_PRS_LogAndTraceProtocol
[2] Glossary
AUTOSAR_TR_Glossary
[3] Specification of Manifest
AUTOSAR_TPS_ManifestSpecification
[4] Specification of the Adaptive Core
AUTOSAR_SWS_AdaptiveCore
[5] Requirements on Log and Trace
AUTOSAR_RS_LogAndTrace
[6] Specification of Time Synchronization for Adaptive Platform
AUTOSAR_SWS_TimeSync
3.2他适用规范
AUTOSAR提供了一个核心规范[4,SWS AdaptiveCore],该规范也适用于日志和跟踪。本规范的“所有FC的一般要求”一章应被视为实施日志和跟踪的附加和必要规范。
4限制和假设
4.1已知限制
所提供的日志记录框架API设计为独立于底层日志记录后端实现,因此不施加限制。
4.2适用于汽车领域
无适用性限制
5对其他FC的依赖性
对其他FC没有依赖性。
5.1平台依赖性
本规范是AUTOSAR AUTOSAR自适应平台的一部分,因此依赖于它
6需求跟踪
下表引用了RS日志和跟踪[5]中指定的需求,并链接到这些需求的实现。请注意,如果特定要求的“满足者”栏为空,则表示本文件未满足此要求。
7功能规范本规范
定义了为日志和跟踪定义的C++日志API的使用。AA可以使用这些功能将日志消息转发到各种接收器,例如网络、串行总线、控制台或文件系统。
提供了以下功能:
1)初始化日志框架的方法(见7.3)
2)将十进制值转换为十六进制或二进制值的实用方法(见7.4)3)日志消息的自动时间戳(见7.5)
4)日志和跟踪网络带宽限制(见第7.6章)
AA和FC可以启动(见7.1.1)和关闭(见7.1.2)通过调用ARA::core::Initialize()或ARA::core::Deinitialize(),具有直接ARA接口的所有FC(例如,日志框架)
7.1功能集群生命周期
7.1.1启动
为了初始化日志框架,需要向日志框架提供强制性信息。这些信息是从应用程序执行清单和AUTOSAR元模型中提取的。执行清单参数Executable.loggingBehavior定义是否应初始化日志记录功能。在使用任何ara::log API之前,必须初始化日志记录框架(通过ara::core::Initialize)。否则将导致未定义的行为。
[SWS_LOG_00001]在日志框架能够处理之前记录的Log消息(例如,未建立守护进程通信)应排队。
队列大小由LogAndTraceInstantiation.queueSize定义。如果超过此大小,则应丢弃最旧的条目。
7.1.2关闭
当调用ara::core::Deinitialize()时,日志框架应确保不能建立新的客户端连接。
当调用ara::core::Deinitialize()时,如果连接了客户端,则日志记录框架应注意可以收集缓冲区中的所有剩余消息
7.2必要参数和初始化
识别用户应用程序的概念:能够区分系统内不同应用程序实例的日志(例如ECU甚至整个车辆),该系统中的每个应用程序进程都必须获得特定的ID和描述。
日志上下文的概念:为了能够区分应用程序进程中不同逻辑组的日志,必须为应用程序进程内的每个上下文分配特定的ID和描述。每个应用程序进程都可以有任意数量的上下文,但至少有一个上下文是默认上下文。
日志跟踪实例化中收集了日志和跟踪功能集群的特定于计算机的配置设置。使用日志框架的应用程序进程需要通过应用程序执行清单提供以下配置:
?应用程序ID
?应用程序描述
?默认日志级别,如果未通过清单设置,则设置默认预定义值
?日志模式
?日志文件路径,在特定的日志模式指示日志记录到文件的情况下,使用日志记录框架的应用程序进程为每个上下文创建一个日志记录实例。
上下文是在创建日志记录实例时定义的,应提供以下信息:
? 上下文 ID
? 上下文描述
? 默认日志级别,如果未通过清单设置,则设置默认预定义值
7.2.1 应用程序 ID
应用程序 ID 是一个标识符,允许将生成的日志记录信息与其用户应用程序相关联。应用程序 ID 作为字符串值传递。根据 Logging 框架的实际实现,即 Logging 后端,应用程序ID的长度可能会受到限制。为了能够明确地将接收到的日志信息与来源相关联,建议在一个ECU内分配唯一的应用程序ID。ECU之间不需要应用程序ID的唯一性,因为ECU ID将是区别因素。系统集成商全权负责确保每个应用程序流程实例都有一个唯一的应用程序ID。通过在清单中定义该值,集成商能够执行一致性检查。DltLogChannel中的applicationId标识应用程序实例,并作为applicationId放入日志和跟踪消息中。
注:应用程序ID是每个应用程序进程的唯一ID,这意味着如果同一应用程序进程多次启动,则每个实例都应有自己的ID。
7.2.1应用程序描述
由于应用程序ID的长度可能很短,因此可以提供额外的描述性文本。此描述以字符串形式传递,最大长度取决于实现。DltLogChannel中的applicationDescription是一个可选设置,允许将applicationId描述为描述性文本
7.2.2默认日志级别
日志严重性级别表示日志消息的严重性。第7.3章对严重程度进行了定义。DltLogChannel中的logTraceDefaultLogLevel定义应用程序实例的初始日志报告级别。
每个启动的日志消息都具有这样的严重性级别。默认的日志严重性级别是通过每个应用程序进程的应用程序配置设置的。日志严重性级别充当报告筛选器。只有具有更高或相同严重性的日志消息才会被日志框架处理,而其他消息则被忽略。
默认的日志严重性级别是为某个应用程序进程最初配置的日志报告级别,但可以根据上下文进行覆盖。
应用程序进程范围内的日志报告级别应在运行时可调整。实现是底层后端的实现细节。例如。
通过日志客户端(例如DLT Viewer)远程访问。这同样适用于上下文报告级别。
在应用程序范围内提供初始默认日志严重性级别而不是按上下文提供默认日志严重程度级别的设计原理如下:
1.它简化了 API 的使用。否则,用户必须在使用 API 之前为每个组定义上下文默认日志严重性级别
2.可以在运行时对日志消息进行上下文分离。
7.2.3 日志模式
根据日志记录框架的实现,可以通过不同的方式处理传递的日志记录信息。目标(日志消息接收器)可以是控制台输出、文件系统上的文件或通信总线。系统集成商负责在计算机清单中填充此信息。提供了一个直接的 API,用于动态更改此值以用于开发目的。在AUTOSAR元模型中,logTraceLogMode等同于此处描述的日志模式,有关更多信息,请参见[3]。LogAndTraceInstantiation 的 DltLogChannel 中的 logTraceLogMode 定义日志消息将转发到的目标
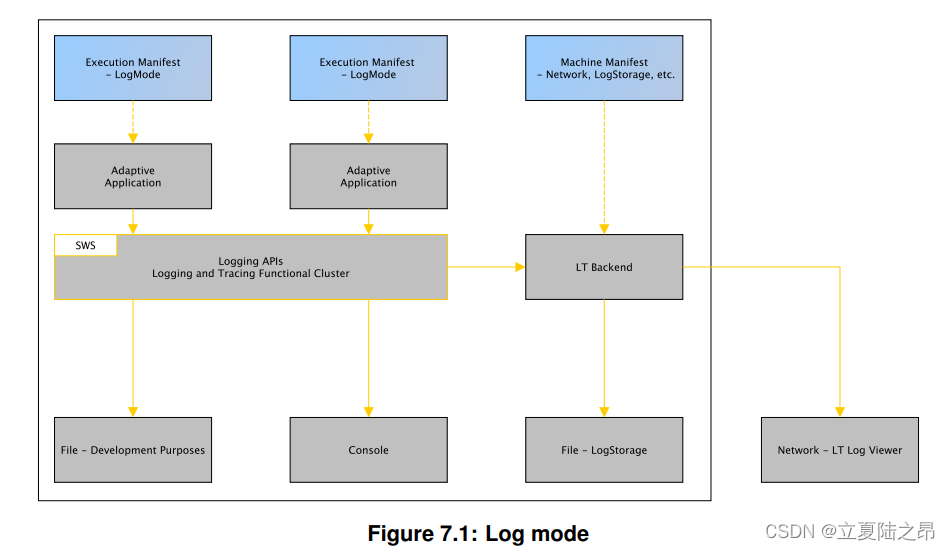
如图所示,一旦将日志模式设置为使用日志记录后端,该后端的配置就集中在机器清单配置中。例如,日志记录后端可以配置为在本地存储日志记录信息,该配置将保留在特定于计算机的清单中。此外,使用由LogAndTraceInstantiation通过DltLogChannel聚合的PlatformModuleEthernetEndpointConfiguration来配置用于日志消息的以太网上的输出通道。
7.2.3.1日志文件路径
如果将日志模式设置为记录到文件,则需要提供目标目录路径。DltLogChannel中的logTraceFilePath定义将日志记录信息传递到的目标文件。此选项用于开发、集成和原型制作,不适合生产。
7.2.4上下文ID
上下文ID是用于对应用程序进程范围内的日志记录信息进行逻辑分组的标识符。上下文ID作为字符串值传递。
根据日志记录后端的实际实现,上下文ID的长度可能会受到限制。上下文ID在应用程序进程的作用域中是唯一的,因此开发人员负责分配它,并且此信息不会在清单中建模。不需要在多个不同的应用程序进程中保持上下文ID的唯一性,因为应用程序ID将是区分不同应用程序的关键。
注意:应特别注意库组件。这些库旨在由应用程序进程使用,因此在应用程序进程的范围内运行。从这些库执行的日志记录将在父应用程序进程的范围内结束。为了将内部库日志与应用程序进程日志或同一进程中的其他库日志区分开来,每个库可能需要在系统范围内保留其自己的上下文ID-至少当它将由多个应用程序进程使用时是这样。
7.2.5上下文描述
由于上下文ID的长度可能很短,因此必须提供附加的描述性文本。此上下文描述作为字符串传递。上下文描述的最大长度取决于实现。
7.2.6日志框架的初始化
应用程序ID和描述用于识别所提供的日志信息,并将其与确切的流程相关联。日志模式和接收器信息定义将日志记录信息路由到何处。可能的目的地是控制台、文件系统或通信总线。
从应用程序进程的角度来看,当应用程序进程决定注册日志记录上下文时,日志记录框架被初始化,并创建一个记录器实例。这些上下文用于对日志记录信息进行逻辑集群。
7.3日志消息
日志消息通常可以输出到不同的目标。日志和跟踪功能集群支持以下日志记录目标:-控制台-本地文件系统上的文件-网络本节中的大部分讨论都假定消息正在输出到网络,因为此用例需要考虑将网络负载降至最低。
日志和跟踪功能集群提供两个主要的日志消息“类”:模型化消息和非模型化消息。这两种方法都支持向日志消息中添加一个或多个“参数”。没有任何参数的日志消息毫无用处,将被丢弃。
非模型化消息是组成日志消息的传统方式:消息的所有参数都被添加到内部消息缓冲区,然后最终序列化以输出到控制台/文件或通过网络。报文的所有部分都将通过网络发送。在DLT协议中,这些消息称为“详细”消息。
模型化消息被设计为通过省略来自网络的消息的某些静态(即不变)部分来减少网络上的流量。顾名思义,这些部分被添加到应用程序ARXML模型中。在DLT协议中,这些消息称为“非详细”消息。日志消息查看器应用程序能够通过组合来自模型的静态部分和来自接收消息的动态部分来显示完整的消息。
非模型化消息主要在开发期间使用,因为模型化消息所需的信息在那时可能不可用。但是,非模型化消息可能会给网络带来很高的负载,这使得模型化消息通常是生产系统中的首选。
Ara::Log功能集群支持在单个应用程序中同时定义和使用建模消息和非建模消息。
7.3.2.3用法
C++API假定存在一个工具,该工具扫描建模的日志消息调用站点的源代码,并按需生成具有唯一ID的预期符号。
框架需要扫描所有源代码以调用Ara::Log::Logger::Log成员函数,并生成与该成员函数调用的第一个参数匹配的符号。
那么该框架将定义一个称为SpeedMsg的全局constexpr变量,该变量属于实现定义类型。此变量包含有关消息建模方面的知识,如参数类型和日志级别,允许ara::log实现验证给定给ara::log::Logger::log的参数类型数是否与特定消息的模型匹配。
消息变量定义将通过ara/log/logger.h提供。
将LogStream对象存储在变量中:也可以通过在某些命名变量中本地存储ara::log::LogStream对象,以其他方式使用Logging API。与临时对象的不同之处在于,它在语句末尾不会超出范围,但只要变量存在,它就会保持有效且可重复使用。因此,可以向它提供分布在多行代码上的数据。为了让Logging框架处理消息缓冲区,需要调用ara::log::LogStream::Flush方法,否则当对象死亡时,即当变量超出范围时,缓冲区将被处理,位于函数块的末尾。
性能备注:由于不再为每条消息创建ara::log::LogStream,而是可以重新用于多条消息,因此创建此对象的成本仅按日志级别支付一次。这对实际性能的实际影响程度取决于Logging框架的实现。然而,这种API日志记录替代使用的主要目标是获得多行生成器功能。
注意:强烈建议不要在多线程应用程序中保留全局ara::log::LogStream对象,因为这样并发访问保护将不再由Logging API覆盖。
用法示例:
<DLT-MESSAGE-COLLECTION-SET>
<SHORT-NAME>DltMessages</SHORT-NAME>
<DLT-MESSAGES>
<DLT-MESSAGE>
<SHORT-NAME>SpeedMsg</SHORT-NAME>
...
</DLT-MESSAGE>
</DLT-MESSAGES>
</DLT-MESSAGE-COLLECTION-SET>
源代码包含以下代码序列:
1 Logger& logger = …
2 logger.Log(SpeedMsg, 4.2);;
然后,框架将定义一个全局constexpr变量,称为实现定义类型的SpeedMsg。此变量包含有关消息建模方面的知识,如参数类型和日志级别,允许ara::log实现验证给定给ara::log::Logger::log的参数类型数是否与特定消息的模型匹配。
消息变量定义将通过ara/log/logger.h提供。
将LogStream对象存储在变量中:也可以通过在某些命名变量中本地存储ara::log::LogStream对象,以其他方式使用Logging API。与临时对象的不同之处在于,它在语句末尾不会超出范围,但只要变量存在,它就会保持有效且可重复使用。因此,可以向它提供分布在多行代码上的数据。为了让Logging框架处理消息缓冲区,需要调用ara::log::LogStream::Flush方法,否则当对象死亡时,即当变量超出范围时,缓冲区将被处理,位于函数块的末尾。
性能备注:由于不再为每条消息创建ara::log::LogStream,而是可以重新用于多条消息,因此创建此对象的成本仅按日志级别支付一次。这对实际性能的实际影响程度取决于Logging框架的实现。然而,这种API日志记录替代使用的主要目标是获得多行生成器功能。
注意:强烈建议不要在多线程应用程序中保留全局ara::log::LogStream对象,因为这样一来,日志AP将不再覆盖并发访问保护
使用示例:
1 Logger& ctx0 = CreateLogger("CTX0", "Context Description CTX0");
2 ctx0.LogInfo() << "Some log information" << 123;
1 // Locally stored LogStream object will process the arguments
2 // until either Flush() is called or it goes out of scope from
3 // the block is was created
4 Logger& ctx1 = CreateLogger("CTX1", "Context Description CTX1");
5 LogStream localLogInfo = ctx1.LogInfo();
6 localLogInfo << "Some log information" << 123;
7 localLogInfo << "Some other information";
8 localLogInfo.Flush();
9 localLogInfo << "a new message..." << 456;
7.5日志和跟踪时间戳
日志和跟踪信息通过与总线无关的LT协议传输。
该协议提供了在每个发送的消息中包括时间戳的可能性,只要这些消息是用扩展的报头发送的(有关更多信息,请参阅[5])。
同步时基由时间同步功能集群提供。自适应应用程序使用now()方法从TS中检索当前时间(有关更多信息,请参阅[6])。
根据要求[TPS_MANI_03162],参考时基源自机器清单时基资源。
[SWS_LOG_00082]dLog和Trace应具有对同步时基的访问权限。LogAndTraceInstantation中的属性timeBaseResource应用于识别时基
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!