Python小白(python数据分析与可视化)从入门到精通
引言
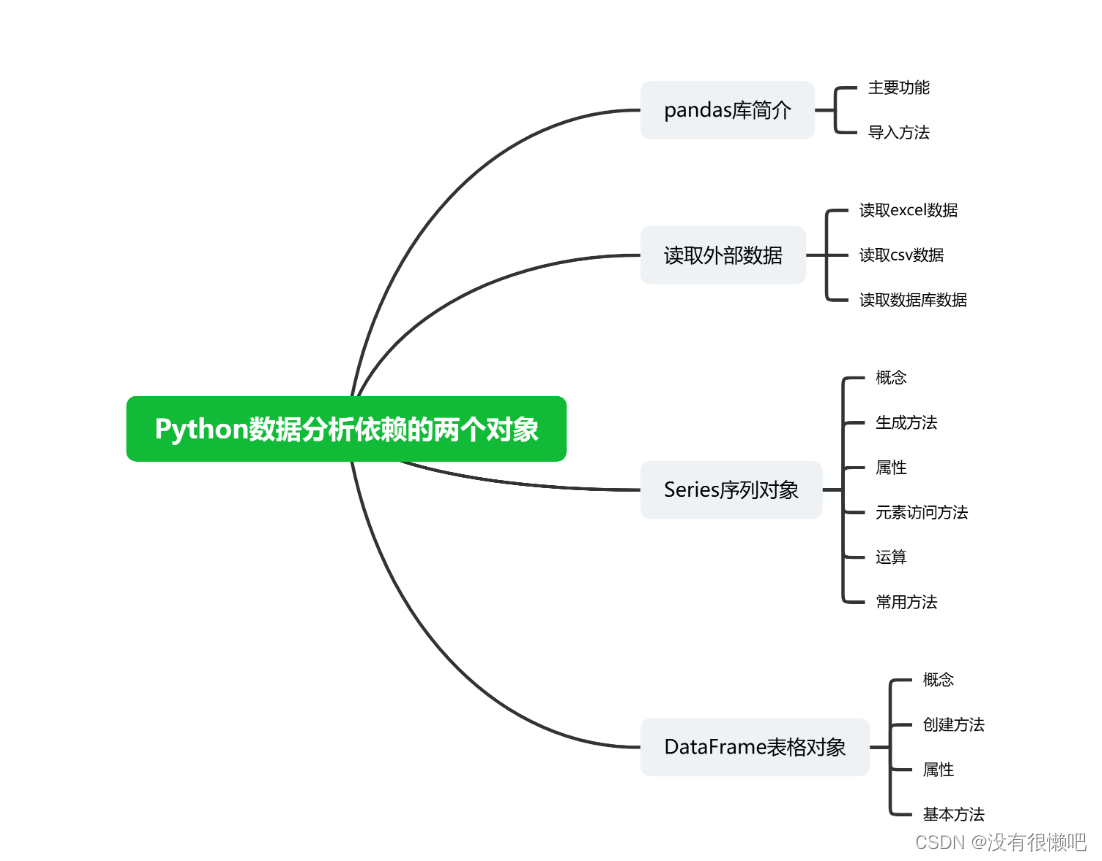
一、Python数据分析环境配置
二、python数据收集和准备
三、Python数据分析基础
四、Python可视化基础
五、进阶可视化技巧
六、数据可视化实战
总结
引言:
Python作为一门强大的编程语言,拥有丰富的数据处理和可视化库,使得数据分析与可视化变得更加简单和高效。本文将介绍基于Python的数据分析与可视化方法,帮助读者更好地处理和探索数据。
一、Python数据分析环境配置
? ? ? ? (一)、Anaconda正式版:是款针对程序员们使用的编程开发工具。Anaconda,一个开源的Python发行版本,可用于管理Python及?其相关包,包含了conda、Python等?180多个科
学包及其依赖项。
????????Anaconda网址:https://www.anaconda.com/
? ? ? ? (二)、Jupyter Notebook:Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍

简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示的程序。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
????????
二、python数据收集和准备
在开始数据分析之前,我们首先需要收集并准备好待分析的数据。可以通过各种渠道获取数据,如API接口、数据库查询、文件导入等。同时,数据也需要进行清洗和处理,包括去除重复值、处理缺失值、异常值处理等。
(一)pandas是什么?
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能
????????pandas官网地址:https://www.pypandas.cn/
# 导入pandas库
import pandas as pd # 命名为pd(二)读取外部数据:
* 导入excel文件方法:调用pandas库的read_excel函数
dataset = pd.read_excel(r'excel文件名') # 表示在当前文件
* 导入csv文件方法:调用pandas库的read_csv函数
data1 = pd.read_csv(r'../../数据集/新用户表.csv', # 表示在上一文件夹的数据集文件夹中
sep=',',
encoding='gbk'# 编码
)* 读取数据库数据
?Pandas库中提供连接Mysq|等数据库的方法,?可以在python读取数据库中的结构化数据。
?Pandas库中读取MySQL等数据库的方法中可以传入sq|语句字符串作为参数,?实现sq|语句的运行。
from sqlalchemy import create_engine
user = 'root' #用户名
password = '123456' #密码
ip = 'localhost' # ip地址
port = '3306' # 端口
database = 'data_analysis' # 数据库名
# 创建mysql引擎对象,将上述信息写入函数的参数中
engine = create_engine(f'mysql+pymysql://{user}:{password}@{ip}:{port}/{database}')
engine
# 将表data1写入engine中的数据库中的user表中
data1.to_sql('user',engine,index=False)? (三)序列对象数据清洗和处理
? ? ? 1.获取序列对象的方法:Series序列对象、数据类型是series
?????????从表格对象中提取序列对象:表格对象["列名称"]
?????????手动生成一个序列对象:pd.Series(列表对象)类生成
data = pd.read_csv(r'../../数据集/新用户表.csv')
df["时间"] #从表格对象中提取序列对象
data1 = pd.Series(["a","b","c",]) #手动生成一个序列对象Series序列对象的属性:
series = pd.Series(['a','b','c'])
print(series.values) # 值
print(series.index) # 索引
print(series.name) # 名称
print(series.dtypes) # 数据类型
print(series.size) # 数据个数(四)Series序列对象常用方法:
astype() :转换序列对象中元素的数据类型
df["订单编号"].astype(int)# 转换为整形数据value?counts():用于统计序列中每个元素值出现了多少次
注意:返回值也是一个序列对象
sort?values():对序列中的数据进行排序
注意:返回的新序列对象对象中索引|排序被打乱了
rank():返回序列中数据大小的排名
注意:返回的是-一个序列对象,索引和原序列相同
round():控制数字型序列的小数点位
序列对象.str.方法名():一系列用于批量处理字符串序列对象中元素的方法
注意:返回序列对象
str.split():根据特定字符分割序列中各字符串
?str.contains():判断序列中各元素是否包含某个字符
?str.replace():批量替换序列中所有元素中的某字符串?
str.count():统计序列中各元素中某字符的出现次数
agg():对序列对象的元素进行加工的方法
注意:返回序列对象
语法:
1.序列对象.agg(lambda?x:关于x的返回值)
2.序列对象.agg(定义好的加工函数)

? (五)DataFrame对象数据清洗和处理
?导入数据库表格或者excel数据时形成的数据对象就是表格对象
?表格对象的类型:?DataFrame
表格对象的组成部分
表格对象的主要组成部分有3个:1.数据(values)、2.?索引(index)、3.列名称(columns)
创建表格对象的方法
?可以通过pandas库中的DataFrame()类来创建一个?表格对象
?通过DataFrame()类的参数columns来设置表格对象的列名称
# 用二维列表来生成一个表格对象
df = pd.DataFrame(
[['张三','男'],['李四','女']],
columns=['姓名','性别']
)
# 用字典来生成表格对象
dict1 = {'姓名':['张三','李四'],'性别':['男','女']}
df2 = pd.DataFrame(dict1)表格对象的基本方法
?head():?返回前5行数据,用于概览
?info():?查看表格对象行列数、各列的数据类型和非空值数量
?describe():?对表格对象中的数字型序列进行各类统计量的计算
?rename():?修改表格对象的列名称
?to?excel():?将表格对象导出成excel
三、Python数据分析基础
在Python中,Pandas是一个非常强大的数据处理库,它提供了DataFrame这一数据结构,使得我们可以方便地处理表格数据。DataFrame不仅支持数据的读写操作,还提供了丰富的数据处理函数,如筛选、排序、聚合等。此外,NumPy库则提供了高效的数组运算功能,为数据分析提供了强大的支持。
(一)表格对象的增删查改
?1.通过序列对象查询数据:
- 访问单列:表格对象 ['列名称'] [行索引]
- 访问多列:表格对象 [['列名称1','列名称2',...]] [行索引]
df = pd.read_excel('../数据集/超市销售数据.xlsx')
df['顾客类型'][:5]
df[['顾客类型','性别']][:5]loc方法:
- 访问单列:表格对象.loc[行索引,'列名称']
- 访问多列:表格对象.loc[行索引,['列名称1','列名称2',...]]
df = pd.read_excel('../数据集/超市销售数据.xlsx')
df.loc[:5,'顾客类型']
df.loc[:5,['顾客类型','性别','商品类别']]
df.loc[:5,'顾客类型':'商品类别']?iloc方法
- 表格对象.iloc[行索引,列索引]
- 和loc方法的区别主要在列索引,iloc中的列索引表示列的序号,接收的是数字
df.iloc[:,[3,4,5]]
df.iloc[:,3:6]? ?2.表格对象条件查询
query方法:
- 语法:表格对象.query(查询条件字符串)
- 查询条件字符串:例如:'a>1','性别=="男"','a>1 and b==2'
df.query('城市=="城市C" and 性别=="男" and 支付方式=="现金"')
loc方法:
- 语法:表格对象.loc[ 布尔值序列 , 列索引 ]
- 布尔值序列由一个序列对象做条件判断运算得到,如:df['年龄']==18
- 布尔值序列中True所在的行即满足条件的行
- 当列索引为":"时(查询所有的列),条件查询语句也可以简写为:表格对象[布尔值序列]
# loc方法
df.loc[df['城市']=='城市C',:]
# loc方法实现多条件查询
c1 = df['城市']=='城市C'
c2 = df['性别']=='男'
c3 = df['支付方式']=='现金'
df.loc[c1&c2&c3]3.表格对象索引重置
df2.reset_index()
# 以某列数据作为索引
df2.set_index('发票编号')4.表格对象新增列数据
语法:表格对象['新的列名称'] = 新的序列对象
5.表格对象删除数据
# 删除行
df.drop(0)
# 删除列
df.drop(1)
6.表格对象数据的修改
语法:访问某个元素的代码=需要赋予的值
注意:赋值需要使用=,不是==,==是判断符号
(二)分组分析相关概念
?
分组分析又叫分组聚合,先分组,后聚合
分组指根据某个类别型变量进行分组
聚合指计算每个组的某个指标的聚合值,聚合值指求和、最值、均值这类由多个值聚合而类的指标
分组的作用:主要用来分析不同的数据之间的差异
groupby()方法:
语法:表格对象.groupby(分组变量')
语法:表格对象.groupby(分组变量’)[聚合变量']
聚合函数即统计量相关函数:?max/min/mean/median/count/sum/...
语法:表格对象.groupby(分组变量")['聚合变量']聚合函数()

语法:表格对象.groupby(['分组变量1';分组变量2'])[聚合变量'].聚合函数())
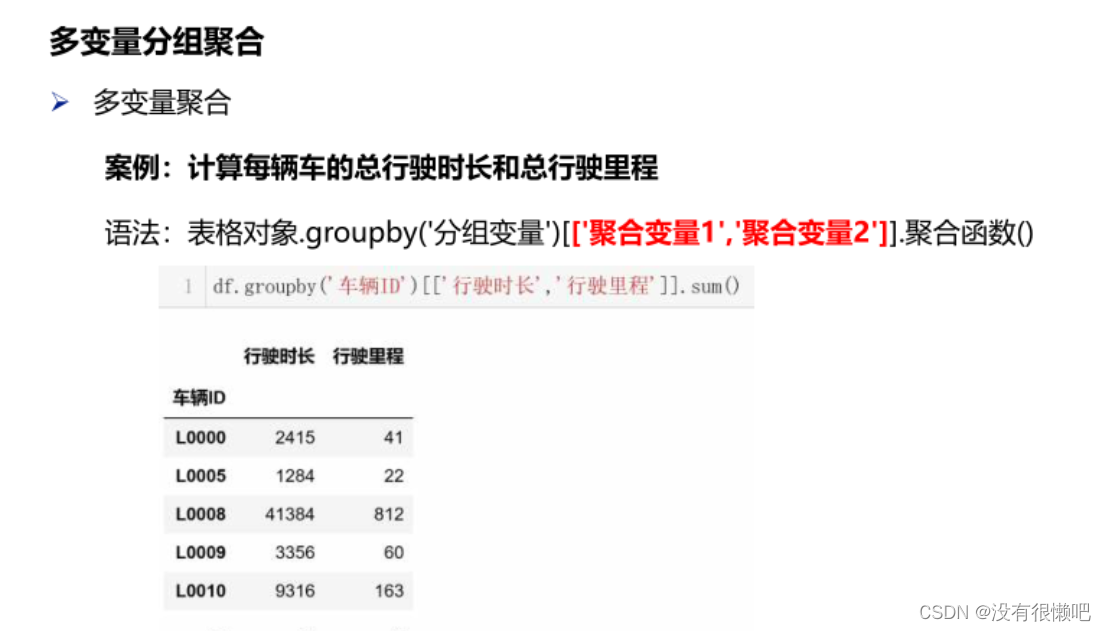
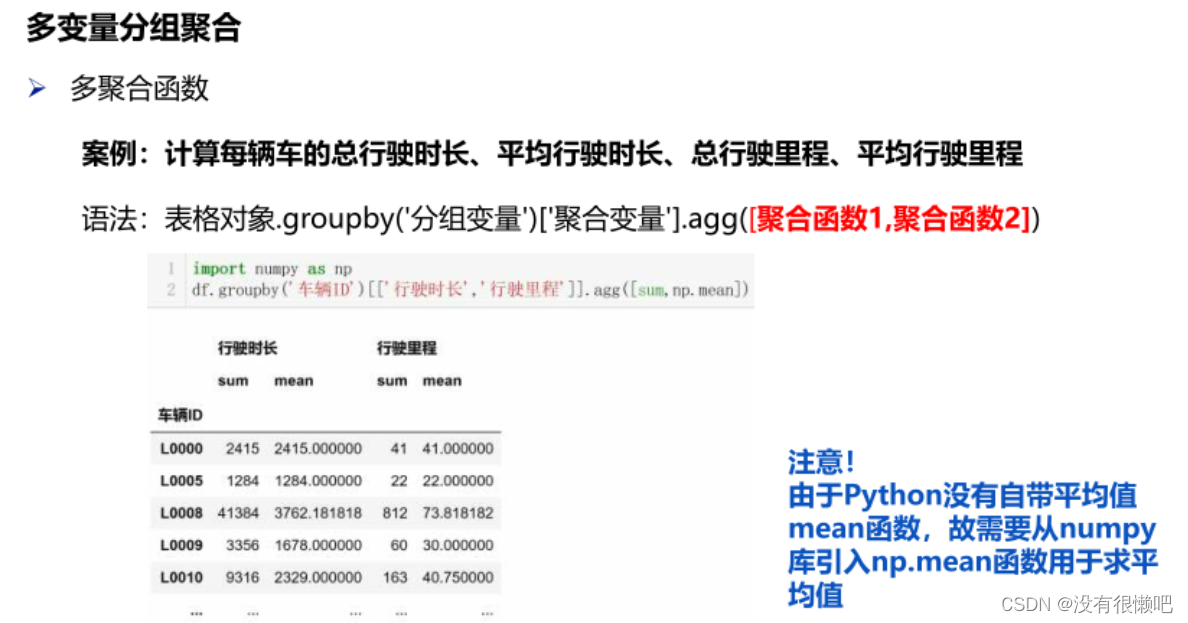
四、Python可视化基础
Matplotlib是Python中一个基础的绘图库,可以用于绘制各种静态、动态、交互式的可视化图表。通过Matplotlib,我们可以轻松地绘制出折线图、柱状图、散点图等常见的图表。此外,Matplotlib还支持定制化绘图,可以自定义图表的样式、颜色等属性。
(一)导入数据库:
????????import matplotlib.pyplot as plt
1.折线图
2.画布
?画布类似画画时的画板,决定了我们的图形的大小,默认的画布为白色,看不见其边界。
?语法:plot.figure(figsize...)
?figsize:?接收元组(a,b),?a表示画布的长,b表示画布的高
3.设置坐标轴

4.添加文本标签
?可以在画布中任意位置一次性添加一个文本信息
语法:plot.text(x,?y,?S,?ha,?va,?fontsize,?color,?..
5.设置标题和图例
?标题显示在画布和图表的正上方。图例-般显示在图表角落,用于描述数据的含义
?显示标题语法:?plot.title(?'标题’?)
?显示图例语法:?plot.legend(?‘数据标签’,?loc,?fontsize,?...
?loc参数:决定图例的位置,如"upper?right"?表示右上方
(二)常见的图型及绘制方法
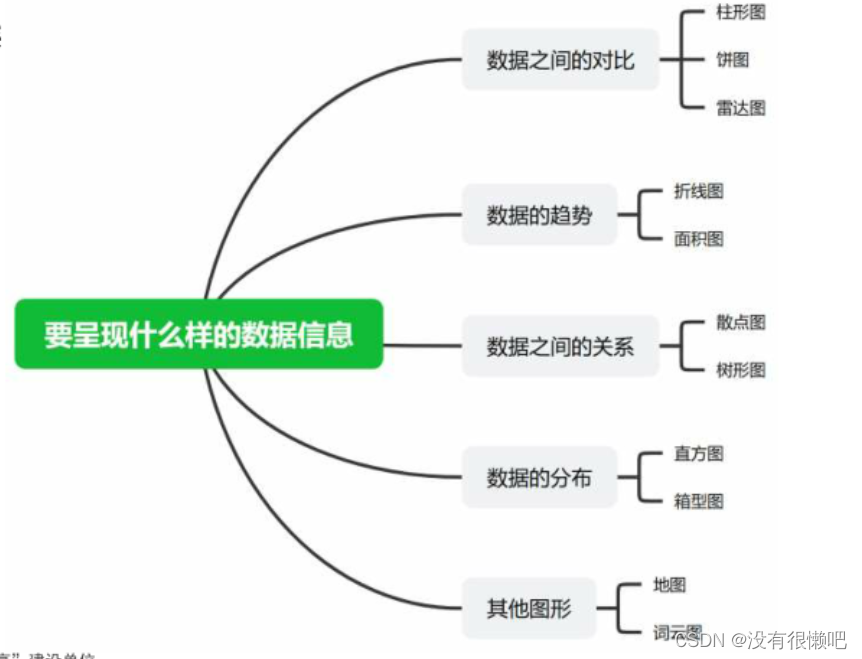
1.柱形图
?柱形图能够查看各项数据的大小差异
绘图函数:?plt.bar(x,?height,?width,?..
?可以通过多?个plt.bar(绘制多重柱形图)
2.饼图
?饼图能够查看各项数据在总计中的占比情况
?绘图函数:?plt.pie(x,?labels,?radius,?autopt..)
3.折线图
?折线图能够查看时间序列数据的波动趋势
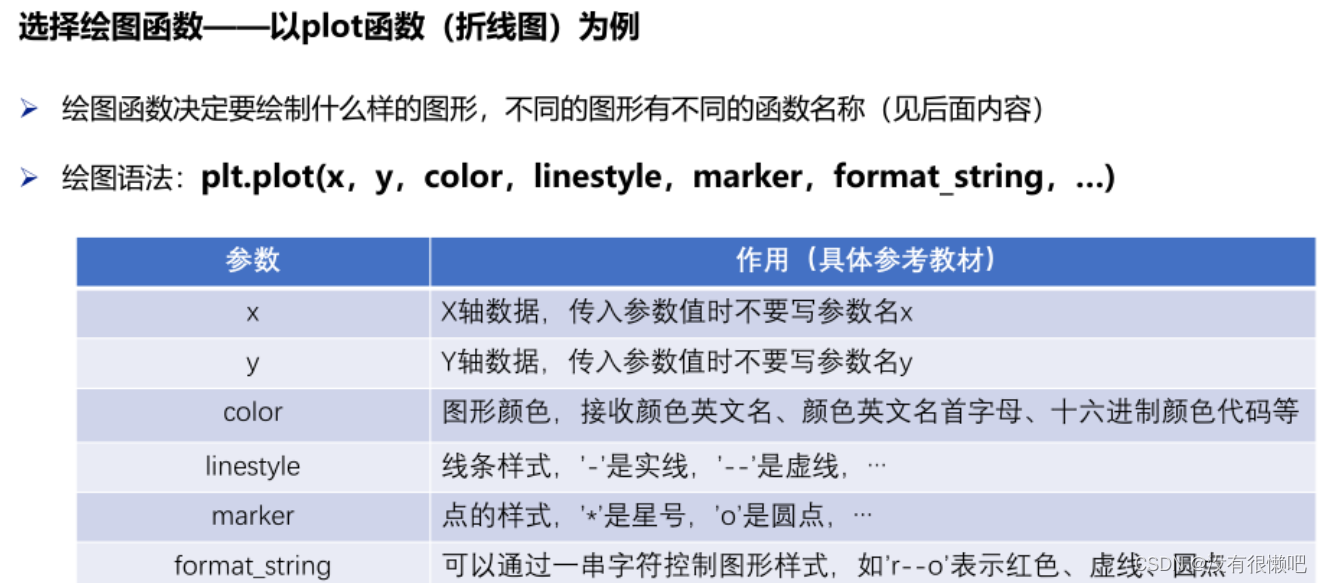
?绘图函数:?plt.plot(x,?y,?color,?linestyle,?marker,?format?string,?..)
4.散点图
?散点图能够查看两个序列数据之间的相关关系
?绘图函数:?plt.scatter(x,?y,?s,?c,?marker,?..)
5.直方图
?直方图能够查看序列数据的分布情况
?数据的分布即统计序列在不同区间内数据的个数
?绘图函数:?plt.hist(x,?bins,?..?.)
6.箱型图
?通过四分位数(Q1\Q2\Q3)?和上限、下限表示数据分布
?上限=Q3+1.5*(Q3-Q1),?下限=Q1-1.5?*(Q3-Q1)
?箱型图通过圆点来显示序列的异常值
?绘图函数:?plt.boxplot(x,?labels,?vert,?whis..)

(三)同时绘制多张图
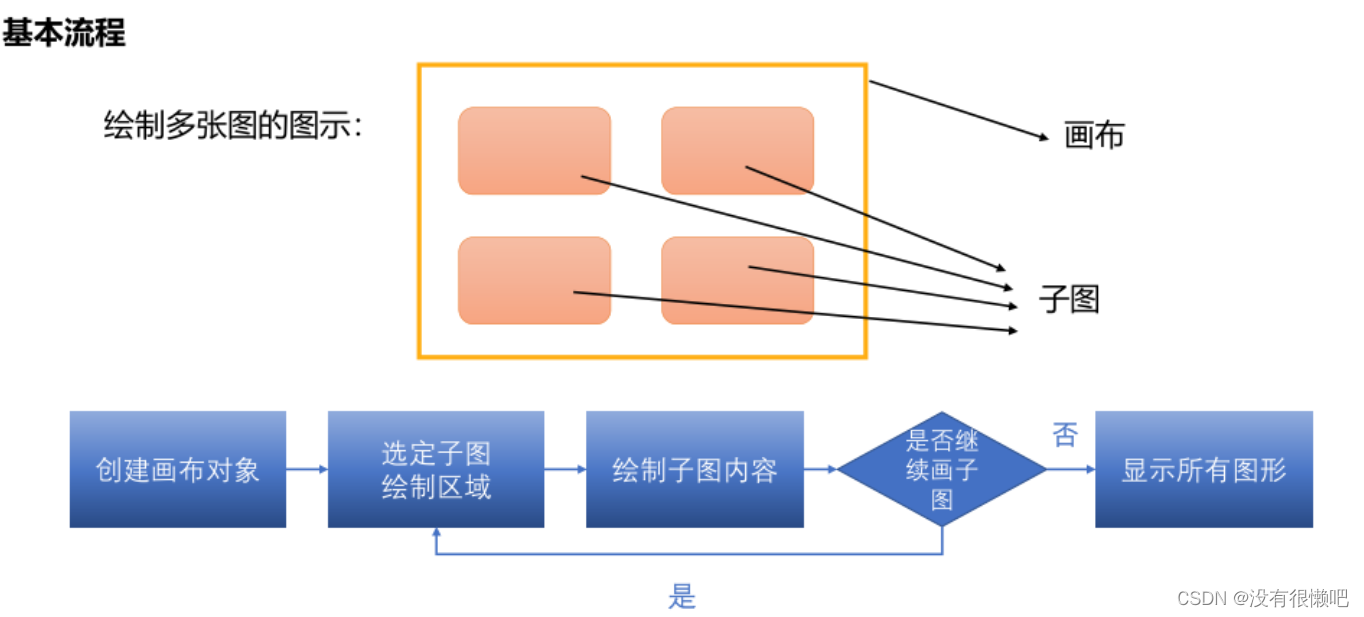
1.创建画布
?生成画布函数:?plt.figure(?figsize=?(a,b))
?figsize:?设置空白画布的大小,接收一个含有两个元素的元组,表示画布的长和宽。
2.添加子图的逻辑
?子图区域选择函数:?plt.subplot(?x,y,z)
执行后会在画布中选定一个区域,由参数xyz决定
?x,y:?表示将画布对象划分为x行y列,共x*y个区域。
?z:表示在上述的x*y个区域中的第z个
(从左到右,从上到下)区域上画图。
3.绘制子图
?绘制子图需要在执行完subplot函数后执行绘图的相关代码
?每次执行完一?个subplot函数选择一个区域后执行绘图代码即可在该位置绘图
五、进阶可视化技巧
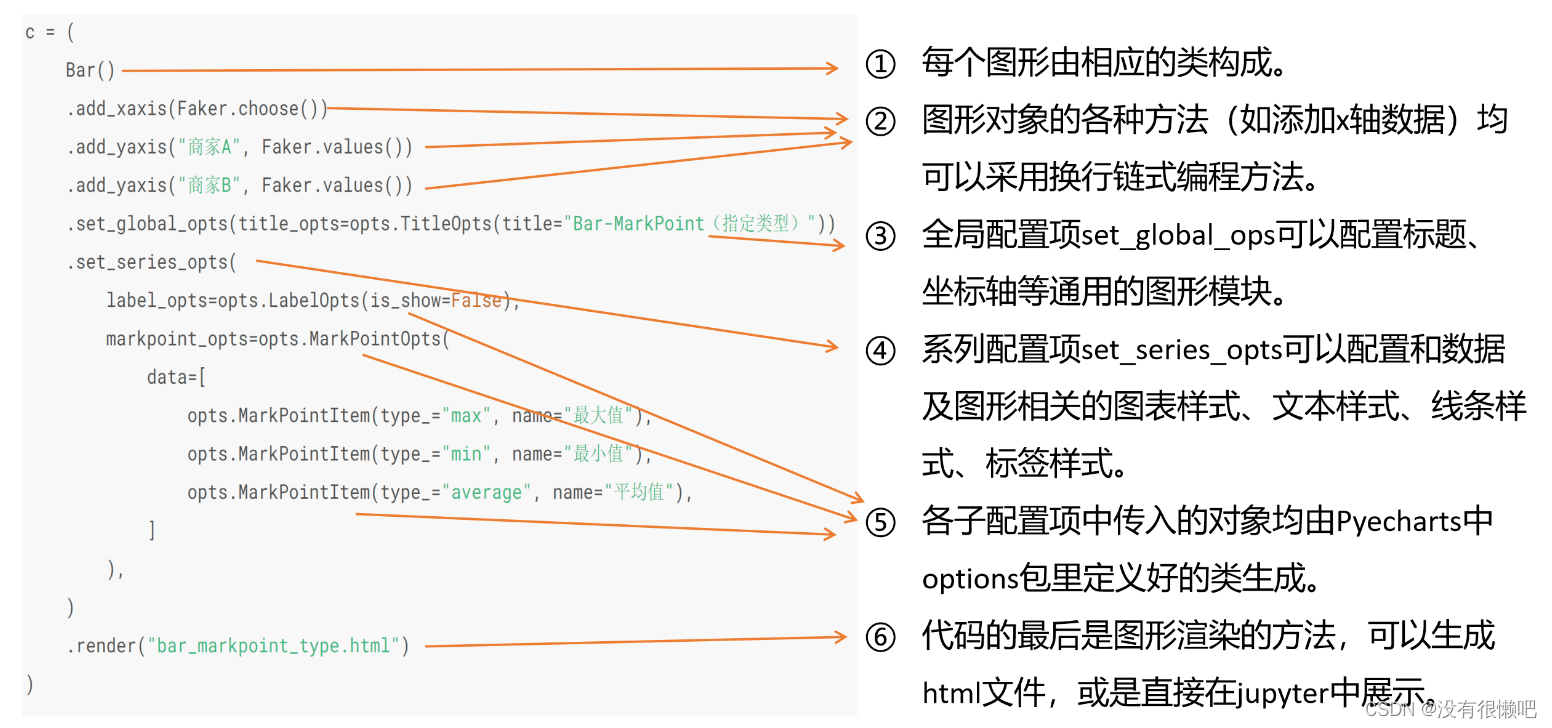
除了基础的图表绘制,我们还可以通过Pyecharts库来绘制更加美观、高级的可视化图表,如热力图、分布图等。
(一)Echarts是一个由百度开源的基于js语言的数据可视化框架,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。
(二)
由于python在数据分析领域的活跃,一个开发团队将echarts库移植到python中,命名为“pyecharts”。
(三)相较于matplotlib而言,pyecharts库绘制的图形种类更多,样式更精美、丰富。
六、数据可视化实战
通过实际案例,我们可以更好地理解数据可视化的应用。例如,我们可以使用Python来分析股票数据,绘制出股票价格走势图;或者使用Python来分析用户行为数据,绘制出用户访问热力图等。此外,我们还可以使用Python进行数据挖掘和机器学习方面的应用,如分类、聚类、回归等。
总结
Python数据分析与可视化是一门技术,也是一种艺术。通过Python,我们可以从海量的数据中提取出有价值的信息,并将其以直观的方式呈现出来。掌握Python数据分析与可视化技能对于现代人来说已经变得越来越重要。无论是数据分析师、数据科学家还是普通的数据爱好者,都可以通过学习Python来提升自己的数据处理和可视化能力。在未来的数据驱动时代,让我们一起用Python说话,用数据驱动未来。
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!