Re58:读论文 REALM: Retrieval-Augmented Language Model Pre-Training
2023-12-13 16:55:11
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:REALM: Retrieval-Augmented Language Model Pre-Training
模型名称:Retrieval-Augmented Language Model pre-training (REALM)
本文是2020年ICML论文,作者来自谷歌,关注RAG+LLM。目标是解决纯用LM参数储存知识就得让LM尺寸越来越大+模块化+可解释。解决方案思路不复杂,就是从维百里找文章,加到输入里面做QA,预训练检索表征模块,在微调时隔好几步就重新更新一下检索表征。检索是可以更新的(可以在老数据上预训练,在新数据上做表征)
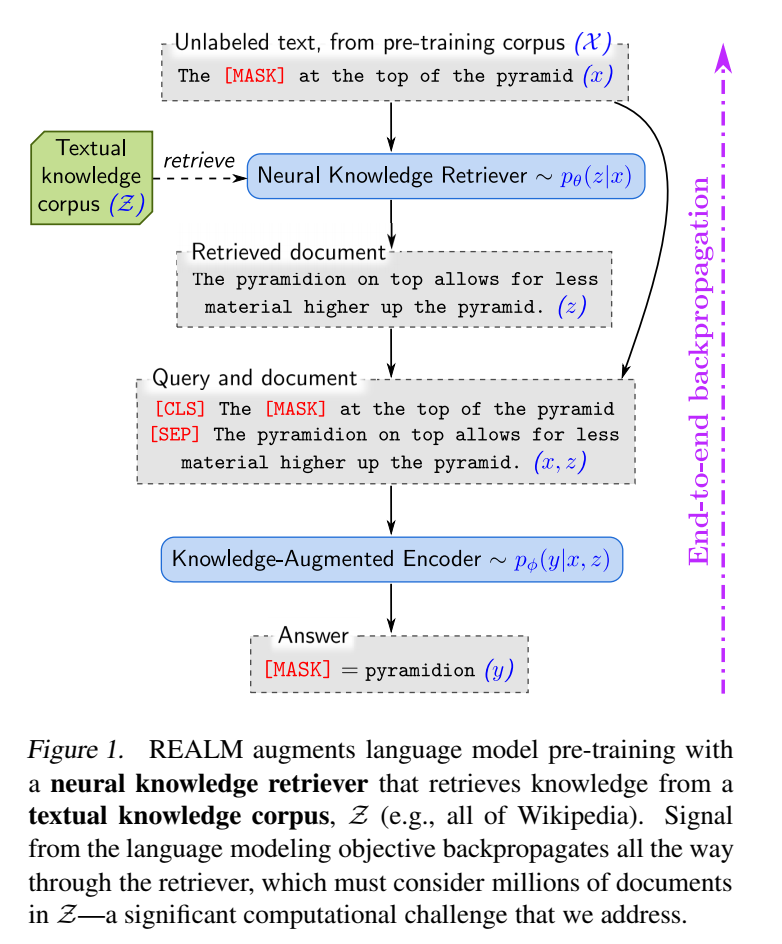
这玩意也能端到端真是太牛逼了
retrieve-then-predict
从维百中检索知识(检索到文章),将原文和检索到的文本拼一起预训练
这个具体如何实现端到端训练其实我没太看懂,总之就是说想了个办法,这个检索文档的过程可以定义为Maximum Inner Product Search (MIPS)
下游任务是Open-QA,传统解决方案是从语料库中找出问题对应的原文(retrieval-based),或者直接生成(generation-based)
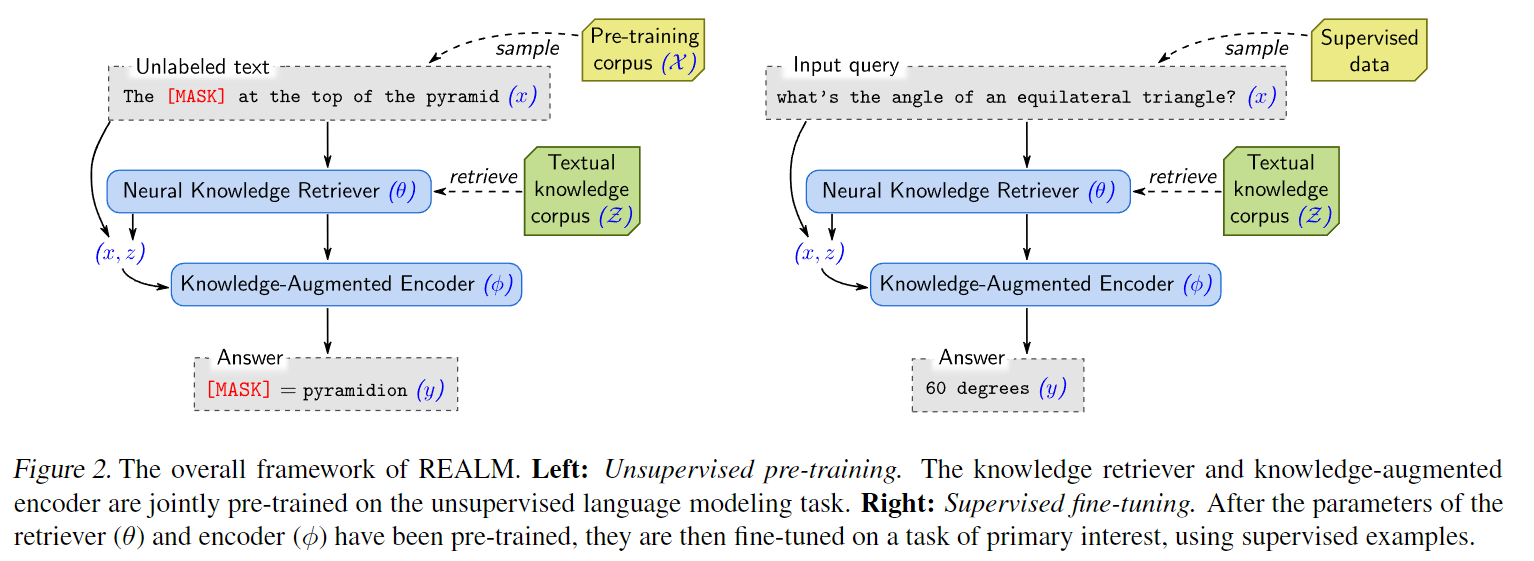
1. REALM模块
- 预训练:MLM
retrieve, then predict
检索文档 z z z
预测: p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)

- 微调:Open-QA
- neural knowledge retriever:内积
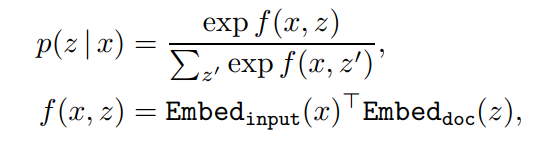
表征模型:BERT-style Transformers

对[CLS]表征做线性转换降维:

这玩意儿还专门分开表征标题和正文,真详细啊。 - knowledge-augmented encoder
join x x x and z z z
MLM预训练:
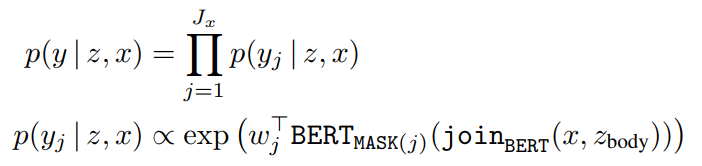
微调时假设答案 y y y 是 z z z 中的连续tokens。 S ( z , y ) S(z,y) S(z,y)是spans:
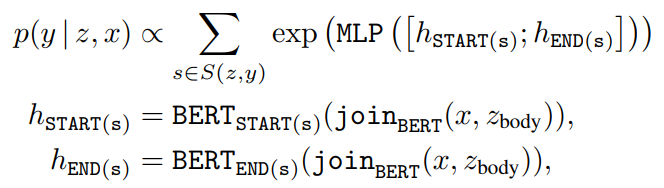
所有span指向的可能性是加总 - 训练:最大似然
简化在所有语料库文档上的求和→top k文档求和
然后这里有一块我没看懂的MIPS,略,大概就是说需要经常重算 ( z ∣ x ) (z|x) (z∣x) 以简化计算balabala
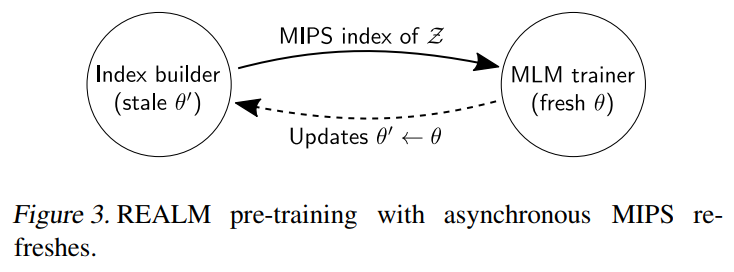
这个仅用于预训练,微调不更新知识库向量
数学分析看不懂,略。
- Injecting inductive biases into pre-training
Salient span masking:mask那种需要world knowledge的span
Null document:不用检索的时候就放个这个
Prohibiting trivial retrievals:这个是考虑到有时给我们找到原句了,这不得行,所以在预训练时直接把这种情况给删了
Initialization:这个主要是担心retriever的表征不好(冷启动问题): Inverse Cloze Task (ICT) 预测句子出处。knowledge-augmented encoder用BERT
2. 实验
数据集里面那个CuratedTrec有点怪啊
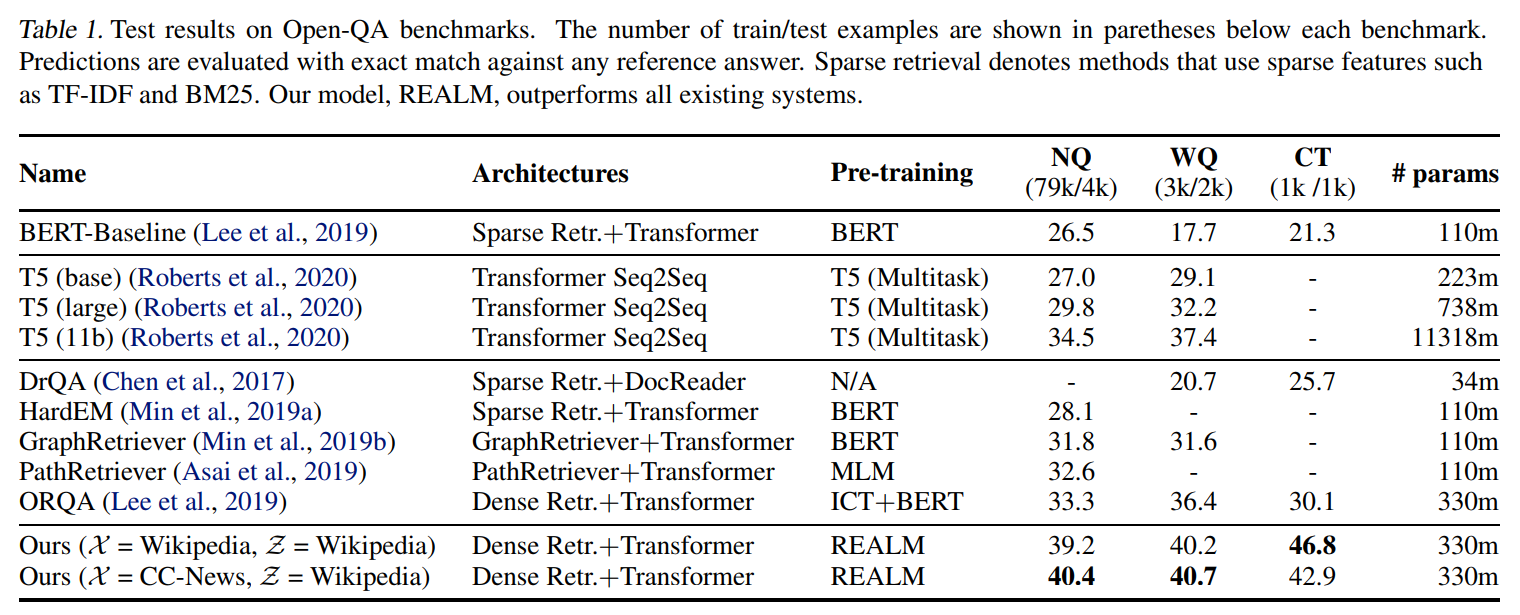
主实验结果:
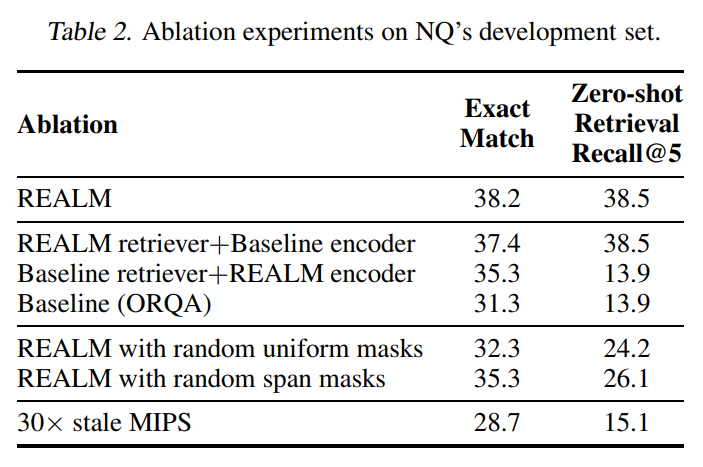
消融实验:

3. 其他
附录开篇上来就是数学公式,害怕。
附录还没看,如果以后有相关研究需求的话再来细看。
文章来源:https://blog.csdn.net/PolarisRisingWar/article/details/134936067
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!