【系统设计】如何确保消息不会丢失?
一、前言
对于大部分业务系统来说,丢消息意味着数据丢失,是完全无法接受的。其实,现在主流的消息队列产品都提供了非常完善的消息可靠性保证机制,完全可以做到在消息传递过程中,即使发生网络中断或者硬件故障,也能确保消息的可靠传递,不丢消息。
绝大部分丢消息的原因都是由于开发者不熟悉消息队列,没有正确使用和配置消息队列导致的。虽然不同的消息队列提供的 API 不一样,相关的配置项也不同,但是在保证消息可靠传递这块儿,它们的实现原理是一样的。
这节课我们就来讲一下,消息队列是怎么保证消息可靠传递的,这里面的实现原理是怎么样的。当你熟知原理以后,无论你使用任何一种消息队列,再简单看一下它的 API 和相关配置项,就能很快知道该如何配置消息队列,写出可靠的代码,避免消息丢失。
二、检测消息丢失的方法
我们说,用消息队列最尴尬的情况不是丢消息,而是消息丢了还不知道。一般而言,一个新的系统刚刚上线,各方面都不太稳定,需要一个磨合期,这个时候,特别需要监控到你的系统中是否有消息丢失的情况。
如果是 IT 基础设施比较完善的公司,一般都有分布式链路追踪系统,使用类似的追踪系统可以很方便地追踪每一条消息。如果没有这样的追踪系统,这里我提供一个比较简单的方法,来检查是否有消息丢失的情况。
我们可以利用消息队列的有序性来验证是否有消息丢失。原理非常简单,在 Producer 端,我们给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。
如果没有消息丢失,Consumer 收到消息的序号必然是连续递增的,或者说收到的消息,其中的序号必然是上一条消息的序号 +1。如果检测到序号不连续,那就是丢消息了。还可以通过缺失的序号来确定丢失的是哪条消息,方便进一步排查原因。
大多数消息队列的客户端都支持拦截器机制,你可以利用这个拦截器机制,在 Producer 发送消息之前的拦截器中将序号注入到消息中,在 Consumer 收到消息的拦截器中检测序号的连续性,这样实现的好处是消息检测的代码不会侵入到你的业务代码中,待你的系统稳定后,也方便将这部分检测的逻辑关闭或者删除。
如果是在一个分布式系统中实现这个检测方法,有几个问题需要你注意。
首先,像 Kafka 和 RocketMQ 这样的消息队列,它是不保证在 Topic 上的严格顺序的,只能保证分区上的消息是有序的,所以我们在发消息的时候必须要指定分区,并且,在每个分区单独检测消息序号的连续性。
如果你的系统中 Producer 是多实例的,由于并不好协调多个 Producer 之间的发送顺序,所以也需要每个 Producer 分别生成各自的消息序号,并且需要附加上 Producer 的标识,在 Consumer 端按照每个 Producer 分别来检测序号的连续性。
Consumer 实例的数量最好和分区数量一致,做到 Consumer 和分区一一对应,这样会比较方便地在 Consumer 内检测消息序号的连续性。
三、确保消息可靠传递
讲完了检测消息丢失的方法,接下来我们一起来看一下,整个消息从生产到消费的过程中,哪些地方可能会导致丢消息,以及应该如何避免消息丢失。
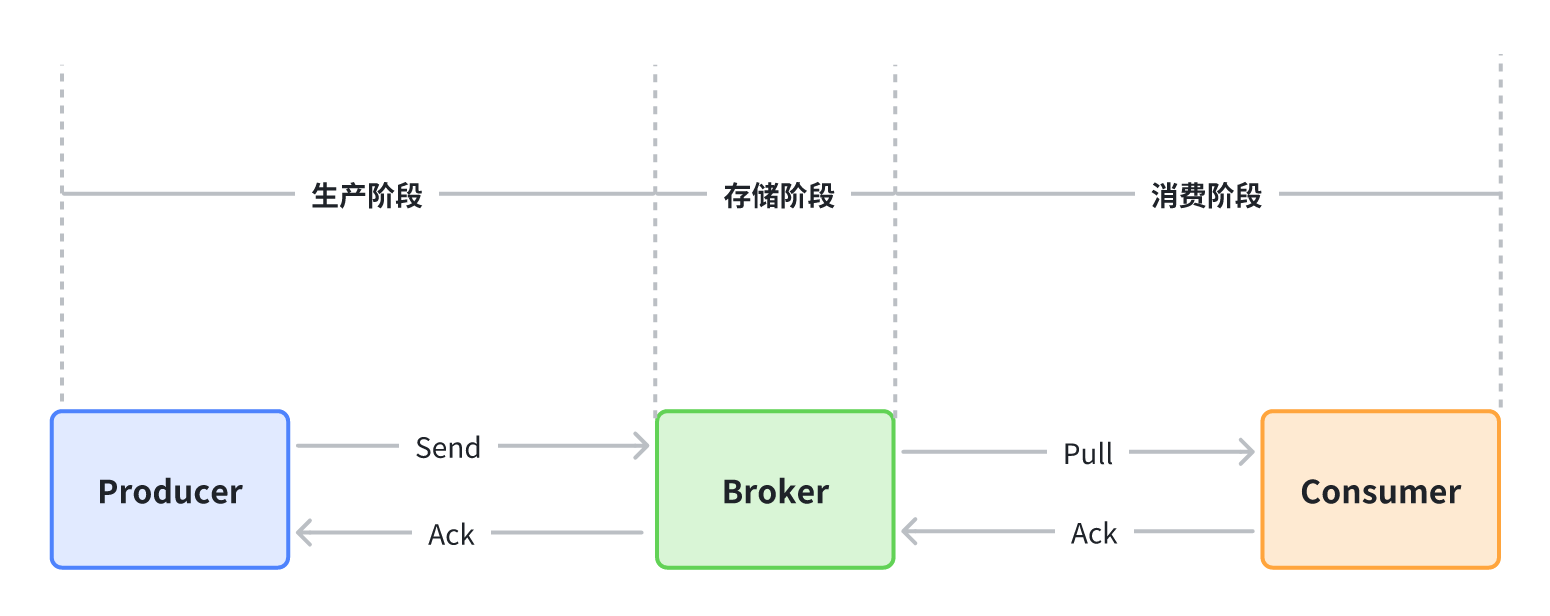
-
生产阶段: 在这个阶段,从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
-
存储阶段: 在这个阶段,消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。
-
消费阶段: 在这个阶段,Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。
3.1、生产阶段
在生产阶段,消息队列通过最常用的请求确认机制,来保证消息的可靠传递:当你的代码调用发消息方法时,消息队列的客户端会把消息发送到 Broker,Broker 收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到响应后,完成了一次正常消息的发送。
只要 Producer 收到了 Broker 的确认响应,就可以保证消息在生产阶段不会丢失。有些消息队列在长时间没收到发送确认响应后,会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户。
你在编写发送消息代码时,需要注意,正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。以 Kafka 为例,我们看一下如何可靠地发送消息:
同步发送时,只要注意捕获异常即可。
try {
RecordMetadata metadata = producer.send(record).get();
System.out.println(" 消息发送成功。");
} catch (Throwable e) {
System.out.println(" 消息发送失败!");
System.out.println(e);
}异步发送时,则需要在回调方法里进行检查。这个地方是需要特别注意的,很多丢消息的原因就是,我们使用了异步发送,却没有在回调中检查发送结果。
producer.send(record, (metadata, exception) -> {
if (metadata != null) {
System.out.println(" 消息发送成功。");
} else {
System.out.println(" 消息发送失败!");
System.out.println(exception);
}
});如果超过一定超时时间还是失败,那就抛出异常,由发者自己在应用层面进行处理,手动重试发送 或者 记录失败消息后续补偿。
不过我们需要特别注意是,RocketMQ支持多种「消息类型」,但是并不是对所有「消息类型」 都会有「消息确认机制」和「失败重试机制」。
RocketMQ生产消息时,支持多种「消息类型」和「消息发送模式」。咱们白话为主,就不展开源码了,有兴趣同学可以参考
org.apache.rocketmq.client.producer.MQProducer这个接口定义即可。
消息类型:
-
普通消息:发送普通消息,异常时默认重试。
-
普通有序消息:发送普通有序消息,通过指定「消息筛选器selector」,动态决定发送哪个队列。异常默认不重试,可以用户自己重试,并发送到其他队列。
-
严格有序消息:发送严格有序消息,通过指定队列,保证严格有序,异常默认不重试。
消息发送模式:
-
同步:调用发送消息方法后,同步阻塞,直到返回SendResult。配置retryTimesWhenSendFailed重试次数。
-
异步:调用发送消息方法后,立即返回,发送结果会通过开发者自己注册的回调函数SendCallback进行处理。配置retryTimesWhenSendAsyncFailed重试次数。
-
单向发送:这种方法完全不关心发送后的返回结果。显然,它具有最大吞吐量,但也存在消息丢失的潜在风险。
发送消息的模式和消息类型,可以通过 消息确认、mq-client自动「失败重试机制」、业务自定义重试 等方式,确保消息发送不丢失。
3.2、存储阶段
在存储阶段正常情况下,只要 Broker 在正常运行,就不会出现丢失消息的问题,但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
对于单个节点的 Broker,需要配置 Broker 参数,在收到消息后,将消息写入磁盘后再给 Producer 返回确认响应,这样即使发生宕机,由于消息已经被写入磁盘,就不会丢失消息,恢复后还可以继续消费。例如,在 RocketMQ 中,需要将刷盘方式 flushDiskType 配置为 SYNC_FLUSH 同步刷盘。
如果是 Broker 是由多个节点组成的集群,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。这样当某个 Broker 宕机时,其他的 Broker 可以替代宕机的 Broker,也不会发生消息丢失。
在Kafka中,可以设置以下参数:
-
replication.factor >= 3
该参数表示分区副本的个数(之前已经介绍过了副本的概念)。
replication.factor =3建议设置大于1,至少有一个副本,随着业务的重要性提升可以增加副本数量。如果 Leader 副本出现不可用,Follower 副本会被选举为新的 Leader 副本继续提供服务。冗余存储数据,做备份本身就是一种提升消息可靠性的办法。
-
unclean.leader.election.enable = false
该参数表示有哪些 Follower 可以有资格被选举为 Leader 。
unclean.leader.election.enable = false如果一个 Follower 的数据落后 Leader 太多,那么一旦它被选举为新的 Leader, 数据就会丢失,因此我们要将其设置为false,防止此类情况发生。
-
min.insync.replicas > 1
该参数表示消息至少要被写入成功到 ISR 多少个副本才算"已提交",默认值是1,建议设置 min.insync.replicas > 1,这样才可以提升消息持久性,保证数据不丢失。
min.insync.replicas = 2另外我们还需要确保一下replication.factor > min.insync.replicas,如果相等,只要有一个副本不可以,整个 partition 将无法正常提供服务。
为了保证消息持久性的同时还要保证可用性,推荐设置成:replication.factor =min.insync.replicas +1, 最大限度保证系统可用性。
3.3、消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从 Broker 拉取消息后,执行用户的消费业务逻辑,成功后,才会给 Broker 发送消费确认响应。如果 Broker 没有收到消费确认响应,下次拉消息的时候还会返回同一条消息,确保消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。
你在编写消费代码时需要注意的是,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。
同样,我们以用 Python 语言消费 RabbitMQ 消息为例,来看一下如何实现一段可靠的消费代码:
def callback(ch, method, properties, body):
print(" [x] 收到消息 %r" % body)
# 在这儿处理收到的消息
database.save(body)
print(" [x] 消费完成 ")
# 完成消费业务逻辑后发送消费确认响应
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(queue='hello', on_message_callback=callback)你可以看到,在消费的回调方法 callback 中,正确的顺序是,先是把消息保存到数据库中,然后再发送消费确认响应。这样如果保存消息到数据库失败了,就不会执行消费确认的代码,下次拉到的还是这条消息,直到消费成功。
如果在尝试消费的过程中达到了最大重试次数(通常为16次),仍然无法成功消费,则消息将被发送到死信队列,以确保消息存储的可靠性。后续业务可以根据死信队列,来做相关补偿措施。
四、参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!