【湖仓一体尝试】MYSQL和HIVE数据联合查询
2023-12-21 21:29:40
爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。
先来个完工环境照:
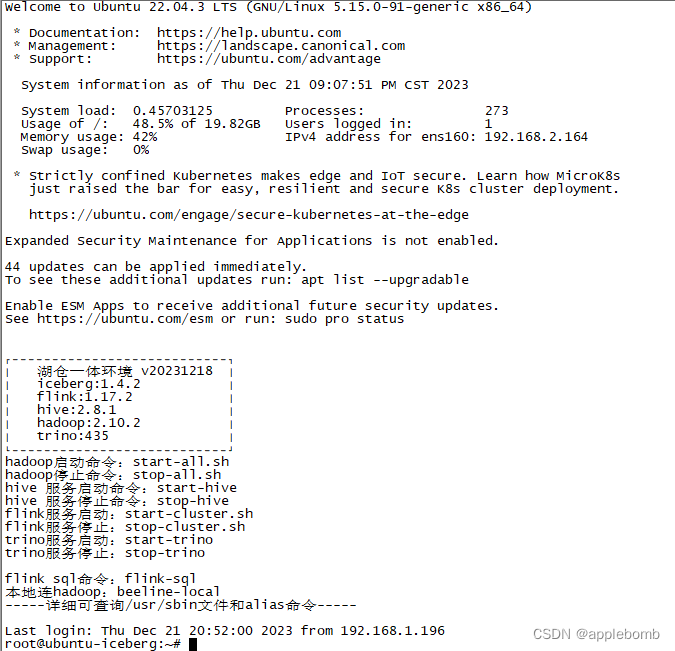
mysql+hadoop+hive+flink+iceberg+trino
得益于IBM OPENJ9的优化,完全启动后的内存占用:
1)执行联合查询后的
2)其中trino由于必须使用ORACLE或OPENJDK,只能再安装多一个JDK21的环境

HIVE里ICEBERG的表和数据:
-- iceberg.test.my_tbl definition
CREATE TABLE iceberg.test.my_tbl (
user_id integer,
user_name varchar,
country varchar,
birthday date
)
WITH (
format = 'PARQUET',
format_version = 2,
location = 'hdfs://localhost:9000/user/hive/warehouse/test.db/my_tbl',
partitioning = ARRAY['country']
);

MYSQL里的表和数据:
-- dict.dict.country definition
CREATE TABLE dict.dict.country (
country_name varchar(2) NOT NULL,
country_cn varchar(20) NOT NULL
);

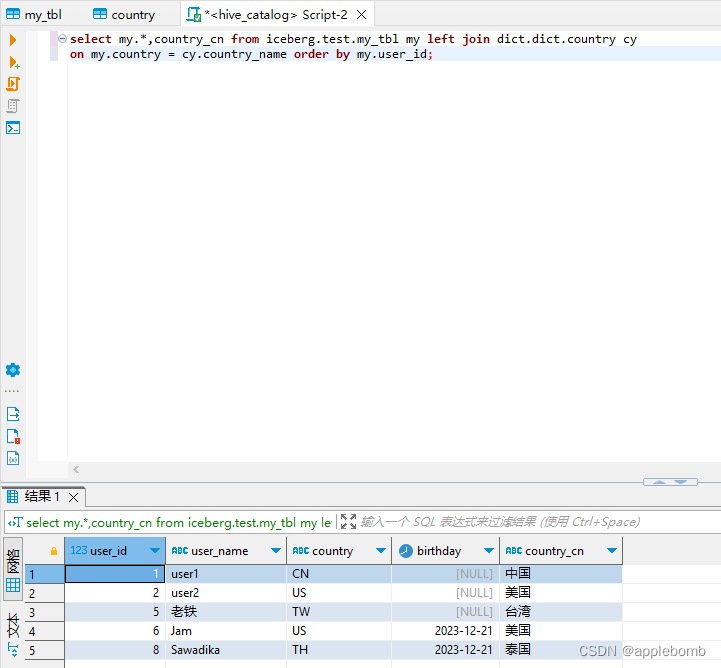
联合查询的执行结果:
文章来源:https://blog.csdn.net/applebomb/article/details/135140050
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!