【小沐学Python】Python实现语音识别(Whisper)
文章目录
1、简介
https://github.com/openai/whisper

1.1 whisper简介
Whisper 是一种通用的语音识别模型。它是在包含各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
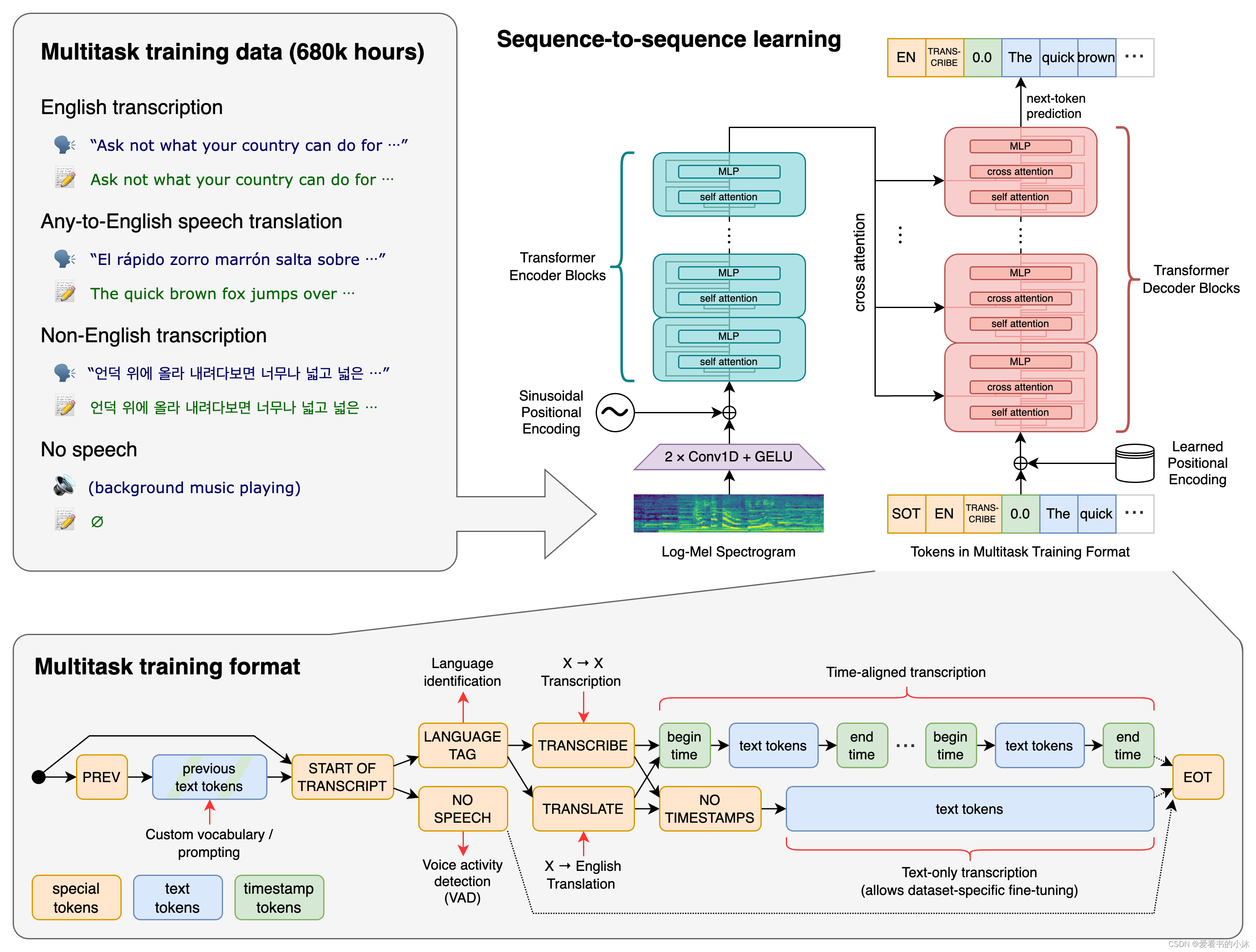
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供的自动语音辨识(Automatic Speech Recognition,ASR)模型是被训练来运行语音辨识与翻译任务的,它们能将各种语言的语音变成文本,也能将这些文本翻译成英文。
1.2 whisper模型
以下是可用模型的名称及其相对于大型模型的近似内存要求和推理速度;实际速度可能因许多因素而异,包括可用的硬件。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | smal | l ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
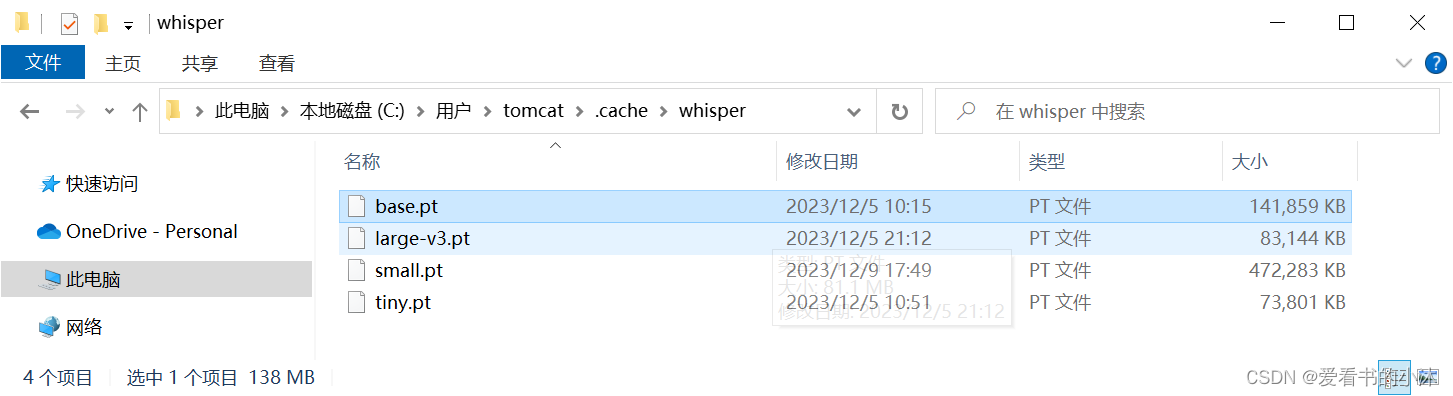
它自动下载的模型缓存,如下:
2、安装
2.1 whisper
pip install -U openai-whisper
# pip install git+https://github.com/openai/whisper.git
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
pip install zhconv
pip3 install wheel
pip3 install torch torchvision torchaudio
# 注:没科学上网会下载有可能很慢,可以替换成国内镜像加快下载速度
pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 pytorch
https://pytorch.org/
选择的是稳定版,windows系统,pip安装方式,python语言、cpu版本的软件。
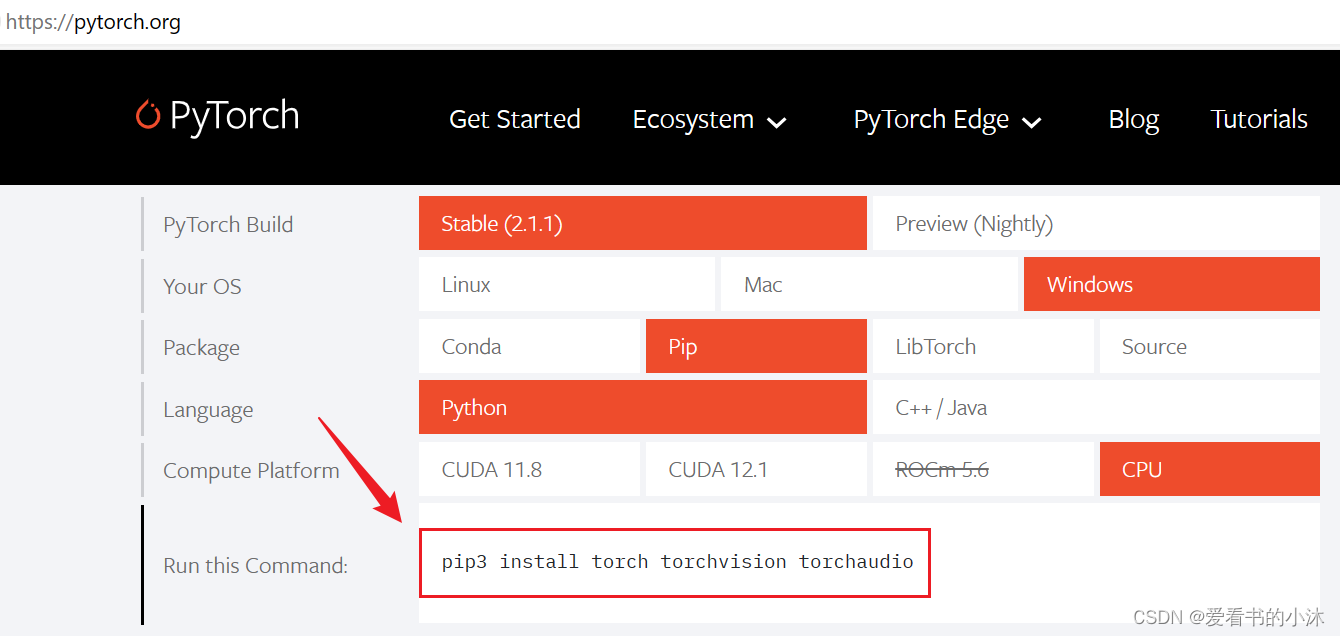
pip3 install torch torchvision torchaudio
2.3 ffmpeg
https://github.com/BtbN/FFmpeg-Builds/releases
解压后,找到bin文件夹下的“ffmpeg.exe”,将它复制到一个文件夹中,假设这个文件夹的路径是"D:\software\ffmpeg",然后将"D:/software/ffmpeg"添加到系统环境变量PATH。
3、测试
3.1 命令测试
whisper audio.mp3
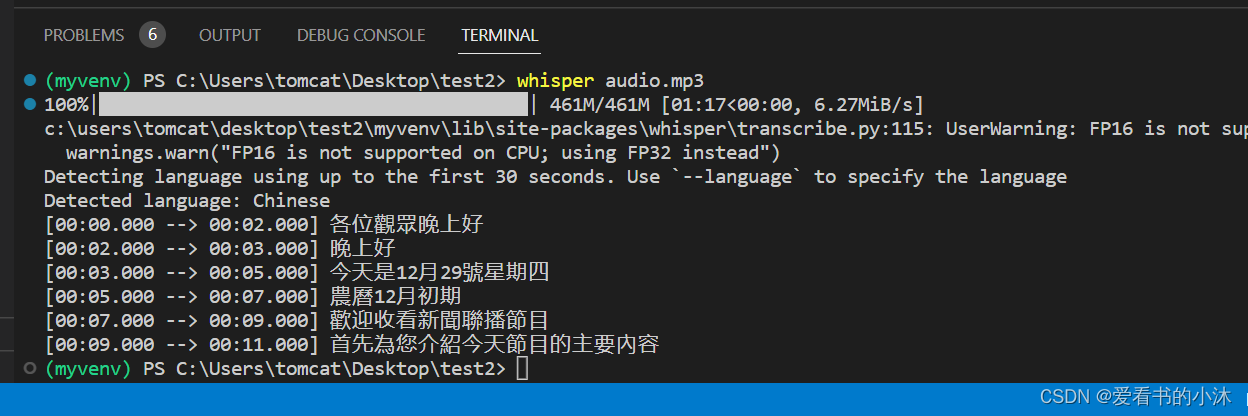
以上whisper audio.mp3的命令形式是最简单的一种,它默认使用的是small模式的模型转写,我们还可以使用更高等级的模型来提高正确率。 比如:
whisper audio.mp3 --model medium
whisper japanese.wav --language Japanese
whisper chinese.mp4 --language Chinese --task translate
whisper audio.flac audio.mp3 audio.wav --model medium
whisper output.wav --model medium --language Chinese
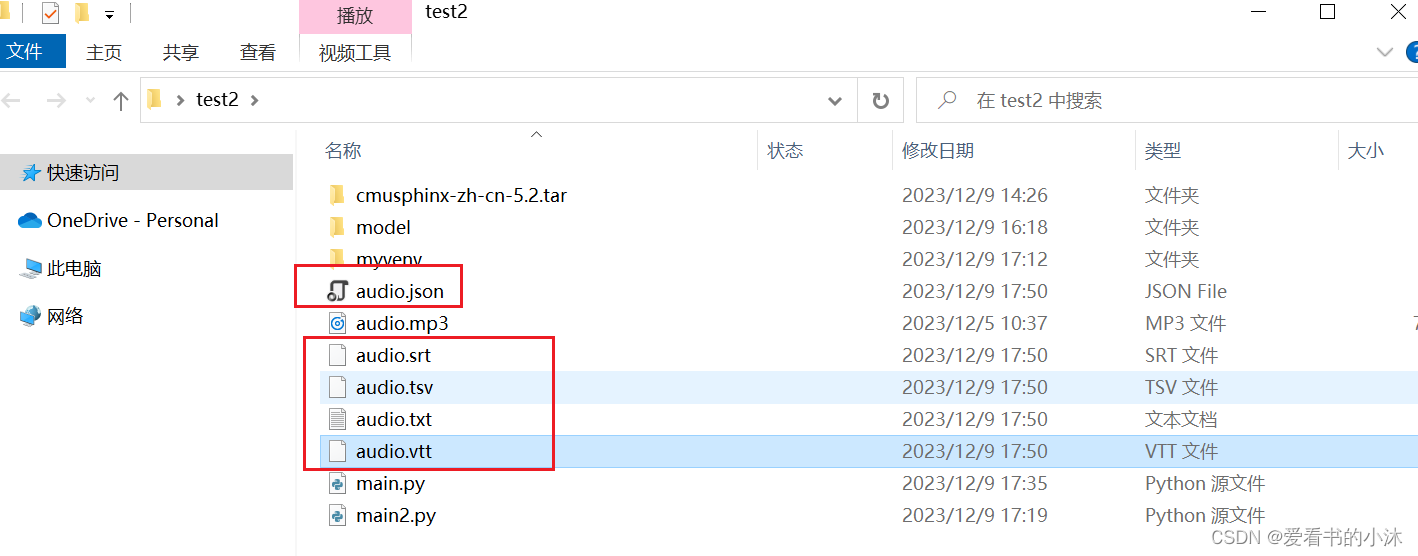
同时默认会生成5个文件,文件名和你的源文件一样,但扩展名分别是:.json、.srt、.tsv、.txt、.vtt。除了普通文本,也可以直接生成电影字幕,还可以调json格式做开发处理。
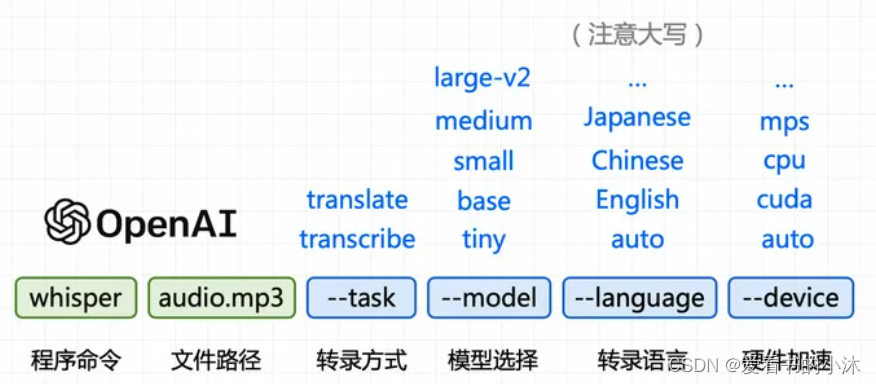
常用参数如下:
--task: 指定转录方式,默认使用 --task transcribe 转录模式,--task translate 则为 翻译模式,目前只支持翻译成英文。
--model:指定使用模型,默认使用 --model small,Whisper 还有 英文专用模型,就是在名称后加上 .en,这样速度更快。
--language:指定转录语言,默认会截取 30 秒来判断语种,但最好指定为某种语言,比如指定中文是 --language Chinese。
--device:指定硬件加速,默认使用 auto 自动选择,--device cuda 则为显卡,cpu 就是 CPU, mps 为苹果 M1 芯片。
--output_format:指定字幕文件的生成格式,txt,vtt,srt,tsv,json,all,指定多个可以用大括号{}包裹,不设置默认all。
-- output_dir: 指定字幕文件的输出目录,不设置默认输出到当前目录下。
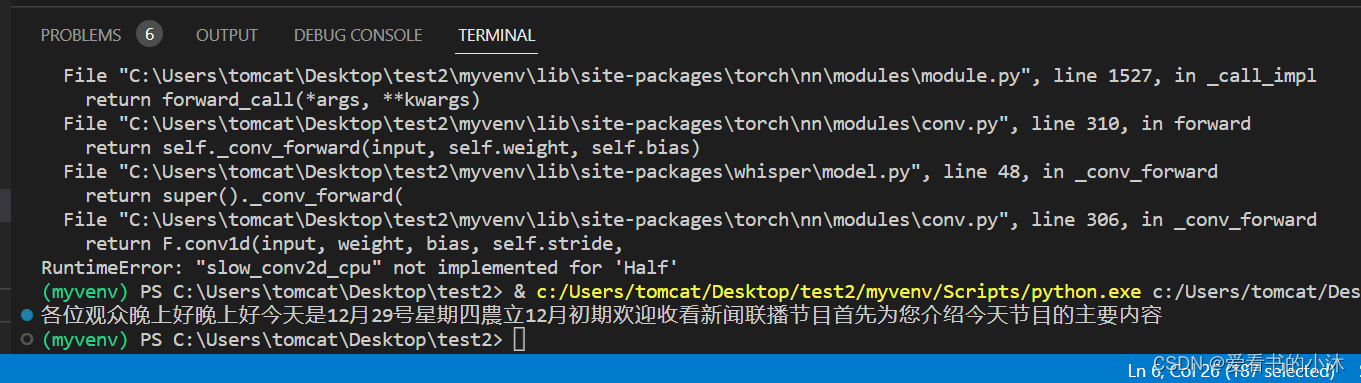
--fp16:默认True,使用16位浮点数进行计算,可以在一定程度上减少计算和存储开销,可能存在精度丢失,笔者CPU不支持,会出现下述警告,指定它为False就不会出现了,即采用32位浮点数进行计算。
3.2 代码测试:识别声音文件
import whisper
if __name__ == '__main__':
model = whisper.load_model("tiny")
result = model.transcribe("audio.mp3", fp16=False, language="Chinese")
print(result["text"])
3.3 代码测试:实时录音识别
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件
def record(time): # 录音程序
# 定义数据流块
CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)
FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式
CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)
RATE = 16000 # 采样率(即每秒采样多少数据)
RECORD_SECONDS = time # 录音时间
WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径
p = pyaudio.PyAudio() # 创建PyAudio对象
stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式
channels=CHANNELS, # 音轨数
rate=RATE, # 采样率
input=True, # Ture代表这是一条输入流,False代表这不是输入流
frames_per_buffer=CHUNK) # 每个缓冲多少帧
print("* recording") # 开始录音标志
frames = [] # 定义frames为一个空列表
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次
data = stream.read(CHUNK) # 每次读chunk个数据
frames.append(data) # 将读出的数据保存到列表中
print("* done recording") # 结束录音标志
stream.stop_stream() # 停止输入流
stream.close() # 关闭输入流
p.terminate() # 终止pyaudio
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件
wf.setnchannels(CHANNELS) # 设置音轨数
wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致
wf.setframerate(RATE) # 设置采样率与RATE要一致
wf.writeframes(b''.join(frames)) # 将声音数据写入文件
wf.close() # 数据流保存完,关闭文件
if __name__ == '__main__':
model = whisper.load_model("tiny")
record(3) # 定义录音时间,单位/s
result = model.transcribe("output.wav",language='Chinese',fp16 = True)
s = result["text"]
s1 = zhconv.convert(s, 'zh-cn')
print(s1)
4、工具
4.1 WhisperDesktop
https://github.com/Const-me/Whisper
OpenAI 的 Whisper 自动语音识别 (ASR) 模型的高性能 GPGPU 推理
This project is a Windows port of the whisper.cpp implementation.
Which in turn is a C++ port of OpenAI’s Whisper automatic speech recognition (ASR) model.
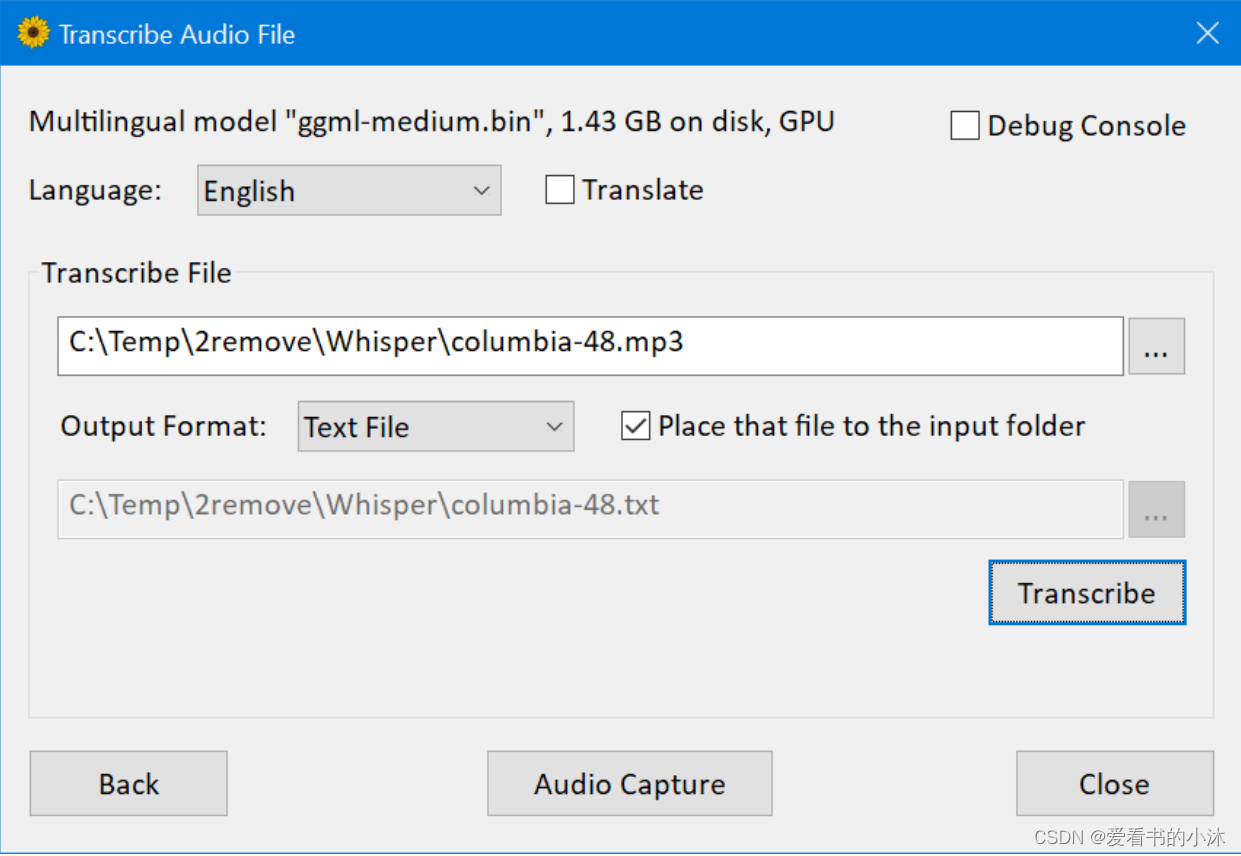
下载 WhisperDesktop 后,点击运行,然后加载模型文件,最后选择文件即可进行转录。由于支持 GPU 硬解,转录速度非常的快。
4.2 Buzz
https://github.com/chidiwilliams/buzz
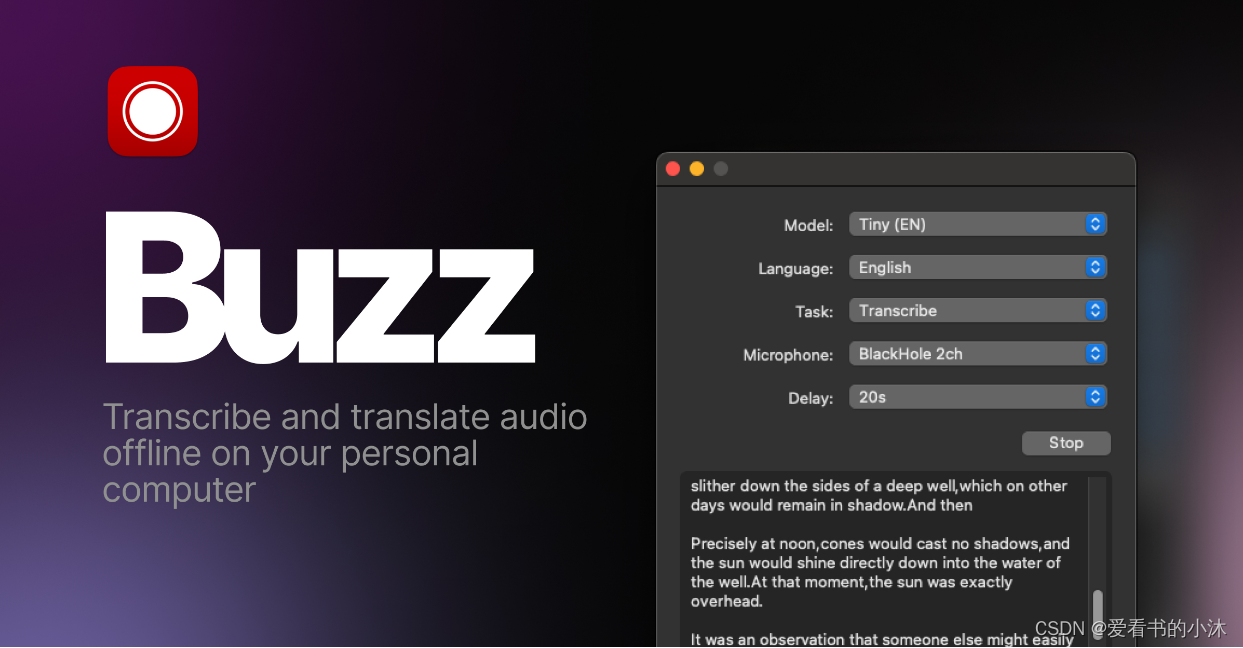
Buzz 在您的个人计算机上离线转录和翻译音频。由 OpenAI 的 Whisper 提供支持。
另一款基于 Whisper 的图形化软件是 Buzz,相比 WhipserDesktop,Buzz 支持 Windows、macOS、Linux。
安装如下:
- (1)PyPI:
pip install buzz-captions
python -m buzz
- (2)Windows:
Download and run the file in the releases page…exe‘
Buzz 的安装包体积稍大,同时 Buzz 使用的是 .pt 后缀名的模型文件,运行后软件会自动下载模型文件。
但最好是提前下好模型文件,然后放在指定的位置。
Mac:~/.cache/whisper
Windows:C:\Users\<你的用户名>\.cache\whisper
但 Buzz 使用的是 CPU 软解 ,目前还不支持 GPU 硬解 。
4.3 Whisper-WebUI
https://github.com/jhj0517/Whisper-WebUI
基于 Gradio 的 Whisper 浏览器界面。你可以把它当作一个简单的字幕生成器!
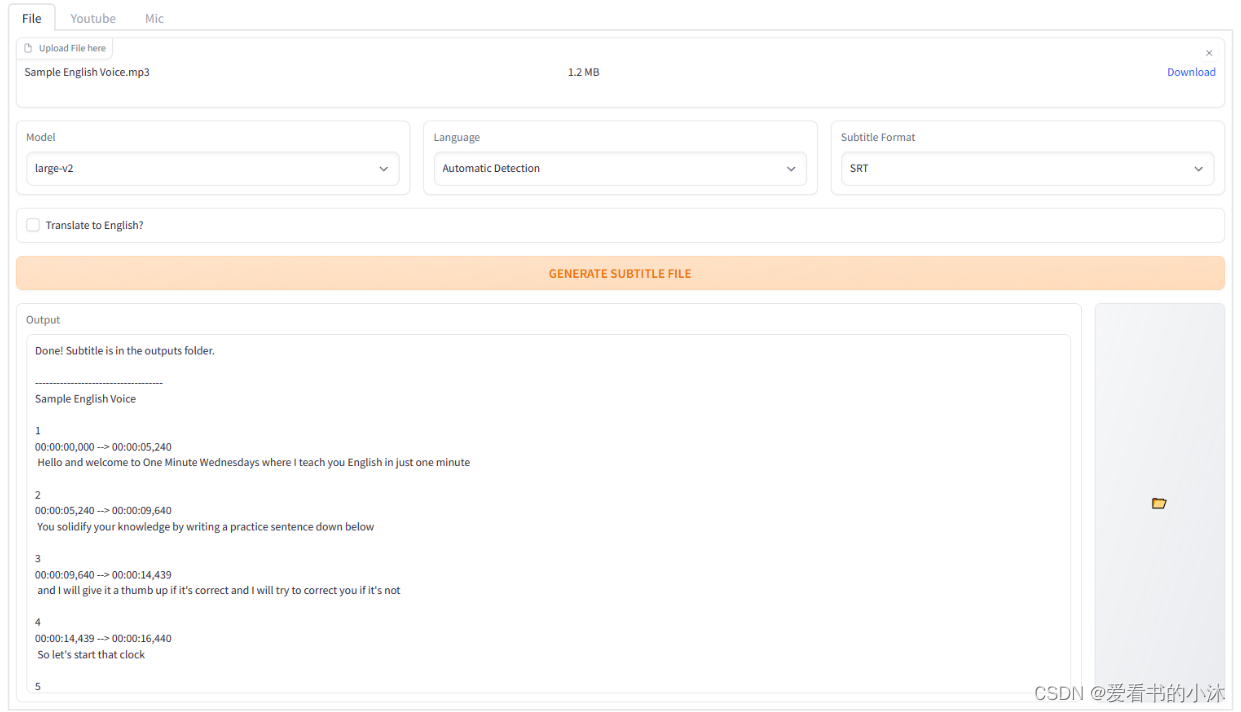
To run Whisper, you need to have , version 3.8 ~ 3.10 and .gitpythonFFmpeg
- git : https://git-scm.com/downloads
- python : https://www.python.org/downloads/
- FFmpeg : https://ffmpeg.org/download.html
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(????)
感谢各位大佬童鞋们的支持!( ′ ▽′ )ノ ( ′ ▽′)っ!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!