R 批量对多个变量进行单因素方差分析 批量计算均值±标准差
2024-01-10 06:05:17
多个变量批量进行单因素方差 R实现
一、批量生成均值±标准差 P值
数据结构如下,1-54列变量为欲分析的连续变量,tert为分组变量,此外还包括如age,BMI等可能用到的协变量。
数据已经过处理,无缺失值
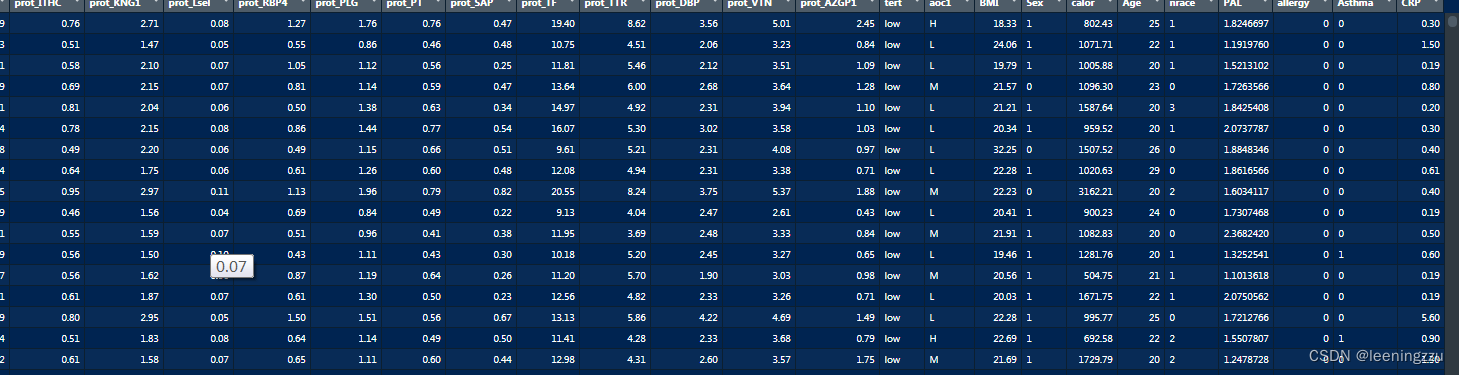
步骤如下:
- .使用 lapply 函数对数据框 df2 的前 54 列进行循环处理。每次迭代都执行一次方差分析,其中自变量为 x,因变量为 df2$tert,并将结果存储在 results 列表中。
- 使用 sapply 函数对 results 列表中的每个方差分析结果进行循环处理,提取出每个分析结果的 p 值,并将这些 p 值存储在 p_values 向量中。
- 使用 aggregate 函数对 df2 的前 54 列进行聚合操作,按照 tert 列的值分组,并计算每个组的均值,将结果存储在 means 数据框中。同样计算每个组的标准差,将结果存储在 sds 数据框中。
- results_df <- data.frame(var = colnames(df2[,1:54]), low_mean_sd = NA, medium_mean_sd = NA, high_mean_sd = NA, p_value = round(p_values, 3)):创建一个新的数据框 results_df,其中包含了变量名、低、中、高三个分组的均值和标准差,以及方差分析的 p 值。初始时,这些列都被设置为 NA,而 p_values 向量经过取小数点后三位后被赋值给 p_value 列。
- results_df l o w m e a n s d < ? p a s t e 0 ( r o u n d ( m e a n s [ m e a n s low_mean_sd <- paste0(round(means[means lowm?eans?d<?paste0(round(means[meansGroup.1 == “low”, -1], 2), " ± ", round(sds[sds G r o u p . 1 = = " l o w " , ? 1 ] , 2 ) ) :使用 p a s t e 0 函数将低分组的均值和标准差合并为一个字符串,并赋值给 r e s u l t s d f 的 l o w m e a n s d 列。 r o u n d 函数用于将均值和标准差保留两位小数。类似地, r e s u l t s d f Group.1 == "low", -1], 2)):使用 paste0 函数将低分组的均值和标准差合并为一个字符串,并赋值给 results_df 的 low_mean_sd 列。round 函数用于将均值和标准差保留两位小数。类似地,results_df Group.1=="low",?1],2)):使用paste0函数将低分组的均值和标准差合并为一个字符串,并赋值给resultsd?f的lowm?eans?d列。round函数用于将均值和标准差保留两位小数。类似地,resultsd?fmedium_mean_sd 和 results_df$high_mean_sd 列也被赋值为中分组和高分组的均值与标准差的合并字符串。
# 进行方差分析
results <- lapply(df2[,1:54], function(x) {
aov(x ~ df2$tert)
})
# 提取 P 值
p_values <- sapply(results, function(x) {
summary(x)[[1]][["Pr(>F)"]][1]
})
# 计算均值和标准差
means <- aggregate(df2[,1:54],, by=list(df2$tert), FUN=mean)
sds <- aggregate(df2[,1:54],, by=list(df2$tert), FUN=sd)
# 创建一个新的数据框来存储结果
results_df <- data.frame(var = colnames(df2[,1:54]), low_mean_sd = NA, medium_mean_sd = NA, high_mean_sd = NA, p_value = round(p_values, 3))
# 计算均值±标准差
results_df$low_mean_sd <- paste0(round(means[means$Group.1 == "low", -1], 2), " ± ", round(sds[sds$Group.1 == "low", -1], 2))
results_df$medium_mean_sd <- paste0(round(means[means$Group.1 == "medium", -1], 2), " ± ", round(sds[sds$Group.1 == "medium", -1], 2))
results_df$high_mean_sd <- paste0(round(means[means$Group.1 == "high", -1], 2), " ± ", round(sds[sds$Group.1 == "high", -1], 2))
# 查看结果
head(results_df)
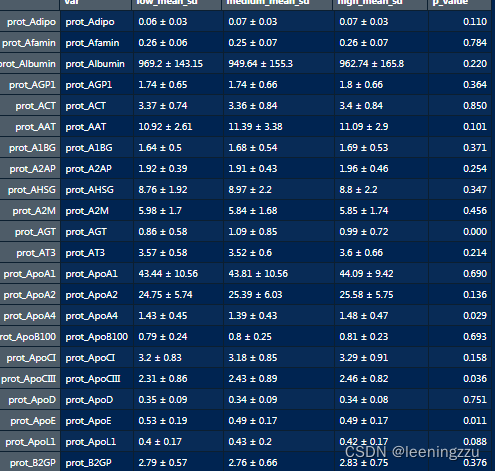
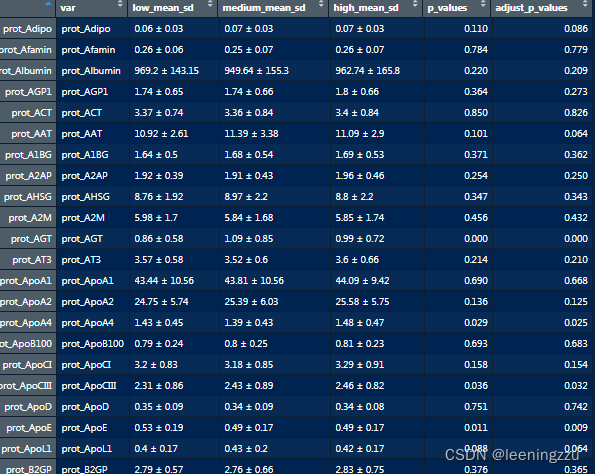
二、添加协变量单因素方差分析,生成校正P值
代码如下:
##########################ancova adjust covariate
# 进行方差分析
results <- lapply(df2[,1:54], function(x) {
aov(x ~ df2$tert + df2$BMI+df2$Age+df2$nrace+df2$PAL+df2$calor+df2$allergy+df2$Asthma+df2$CRP)
})
# 提取 P 值
p_values <- sapply(results, function(x) {
summary(x)[[1]][["Pr(>F)"]][1]
})
resultssummary <- cbind(results_df,round(p_values, 3))
colnames(resultssummary)[5:6] <- c("p_values", "adjust_p_values")
write.csv(resultssummary, file = "resultssummary.csv", row.names = FALSE)
三、在分层情况下进行单因素方差分析
如果在另一分层因素aoc1(L\M\H)情况下进行单因素方差分析
#整理数据
long_df <- df2 %>%
pivot_longer(cols = starts_with("prot_"), names_to = "protein", values_to = "value")
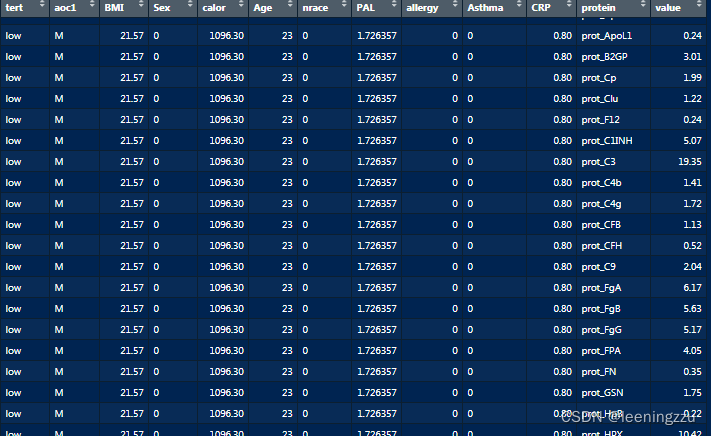
result <- long_df %>%
group_by(aoc1, tert, protein) %>%
summarize(mean = mean(value), sd = sd(value)) %>%
mutate(mean_sd = paste0(round(mean, 2), "±", round(sd, 2))) %>%
select(-mean, -sd) %>%
pivot_wider(names_from = c(aoc1, tert), values_from = mean_sd)
anova_results <- long_df %>%
group_by(protein,aoc1) %>%
do(tidy(aov(value ~ tert,data=.))) %>%
filter(term == "tert") %>%
select(protein,aoc1,p.value) %>%
spread(key=aoc1,value=p.value)%>%
mutate(across(where(is.numeric), round, digits = 3))
final_result <- left_join(result,anova_results)
步骤如下:
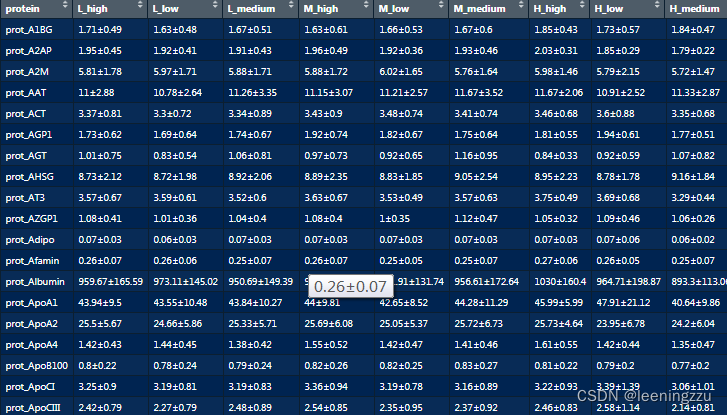
- .对 long_df 数据框进行分组操作,按照 “aoc1”、“tert” 和 “protein” 进行分组,然后计算每个组别的均值和标准差,并将均值和标准差合并为一个字符串,并将结果保存在 “mean_sd” 列中。接着,移除 “mean” 和 “sd” 列,然后使用 pivot_wider 函数将数据重新转换,将 “aoc1” 和 “tert” 的组合作为列名,“mean_sd” 列的值作为对应的值。
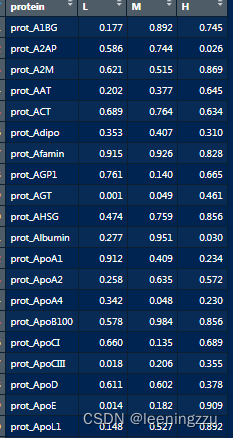
- 对 long_df 数据框进行分组操作,按照 “protein” 和 “aoc1” 进行分组,然后使用 tidy(aov(value ~ tert,data=.)) 函数计算方差分析,并将结果转换为长格式。接着,筛选出 “term” 列为 “tert” 的行,并选择 “protein”、“aoc1” 和 “p.value” 列。使用 spread 函数将 “aoc1” 的值作为列名,“p.value” 的值作为对应的值进行展开。最后,使用 mutate 函数将所有数值型列的值保留三位小数。
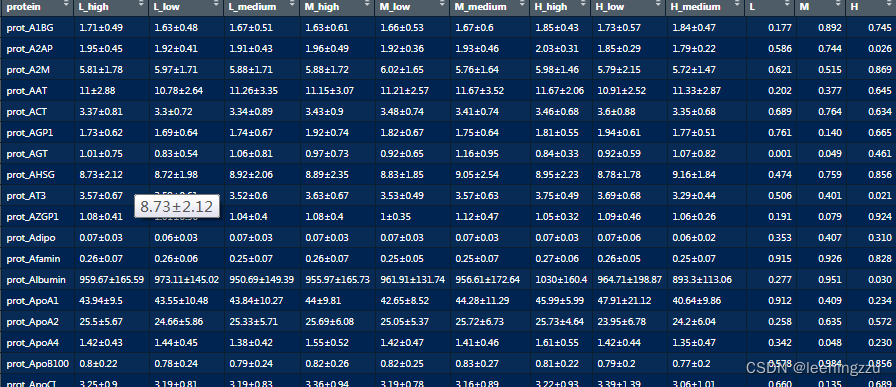
3.使用 left_join 函数将 result 数据框和 anova_results 数据框进行左连接,将它们基于共同的列进行合并,并将结果保存在 final_result 中。
四、添加协变量和交互项的单因素方差分析,生成交互项的P值
计算交互项的 P 值是通过使用 anova 函数计算模型之间的 F 检验来实现的。
在R代码中,anova 函数被用于比较两个线性回归模型的拟合优度,并返回模型之间的方差分析表。通过提取方差分析表中的 P 值,可以得到模型之间的 F 检验的 P 值。
具体来说,对于每对模型(一个包含交互项,一个不包含交互项),anova 函数返回一个方差分析表,其中包含了模型之间的 F 统计量和对应的 P 值。通过计算并获得交互项的 P 值,可以评估交互项对于模型的统计显著性。
######################interaction gene*tert
#创建交互项
df2$aoc1_tert <- interaction(df2$aoc1, df2$tert)
#从 df2 数据框中选择前54列作为蛋白数据,并将结果保存在 proteins 变量中
proteins <- df2[, 1:54]
f_test <- function(model1, model2) {
anova(model1, model2)$"Pr(>F)"[2]
}
# 对每个蛋白,分别建立有交互项和无交互项的模型,并用f_test函数比较它们
pvalues <- lapply(proteins, function(x) {
model1 <- lm(x ~ aoc1_tert + BMI+Age+nrace+PAL+calor+allergy+Asthma+CRP, data = df2)
model2 <- lm(x ~ aoc1 + tert + BMI+Age+nrace+PAL+calor+allergy+Asthma+CRP, data = df2)
f_test(model1, model2)
})
# 将pvalues转换为一个向量,并给它命名为proteins
pvalues <- unlist(pvalues)
names(pvalues) <- colnames(proteins)
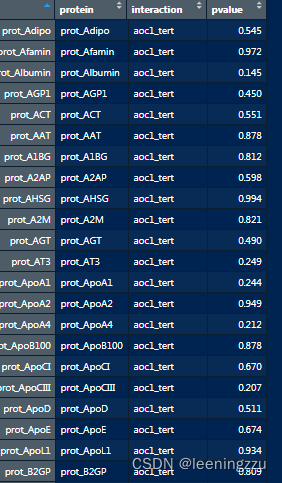
# 创建一个数据框,包含蛋白名称、交互项名称、交互项P值
output <- data.frame(protein = names(pvalues), interaction = "aoc1_tert", pvalue = pvalues)%>%
mutate(across(where(is.numeric), round, digits = 3))
上述代码思路如下:
- .首先,对于每个蛋白数据,使用 lm 函数建立两个线性回归模型:
模型 1:x ~ aoc1_tert + BMI + Age + nrace + PAL + calor + allergy + Asthma + CRP
模型 2:x ~ aoc1 + tert + BMI + Age + nrace + PAL + calor + allergy + Asthma + CRP。
其中 x 是当前蛋白数据,aoc1_tert 是交互项,aoc1 和 tert 是原始变量,其余是控制变量。
- 定义一个函数 f_test,该函数接受两个模型作为输入,并使用 anova 函数计算模型之间的 F 检验值。然后,提取出 F 检验的 P 值。
- 使用 lapply 函数迭代处理每个蛋白数据,并对每个蛋白数据执行以下操作:在模型 1 和模型 2 上调用 f_test 函数,得到交互项的 P 值;将 P 值保存在一个列表中。
- 通过 unlist 函数将列表转换为向量,并使用 names 函数将向量中的元素命名为对应的蛋白名称。
文章来源:https://blog.csdn.net/leeningzzu/article/details/135426684
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!