RocketMQ系统性学习-RocketMQ高级特性之消息存储在Broker的文件布局
🌈🌈🌈🌈🌈🌈🌈🌈
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
RocketMQ 高级特性
消息在 Broker 的文件布局
RocketMQ 的混合存储
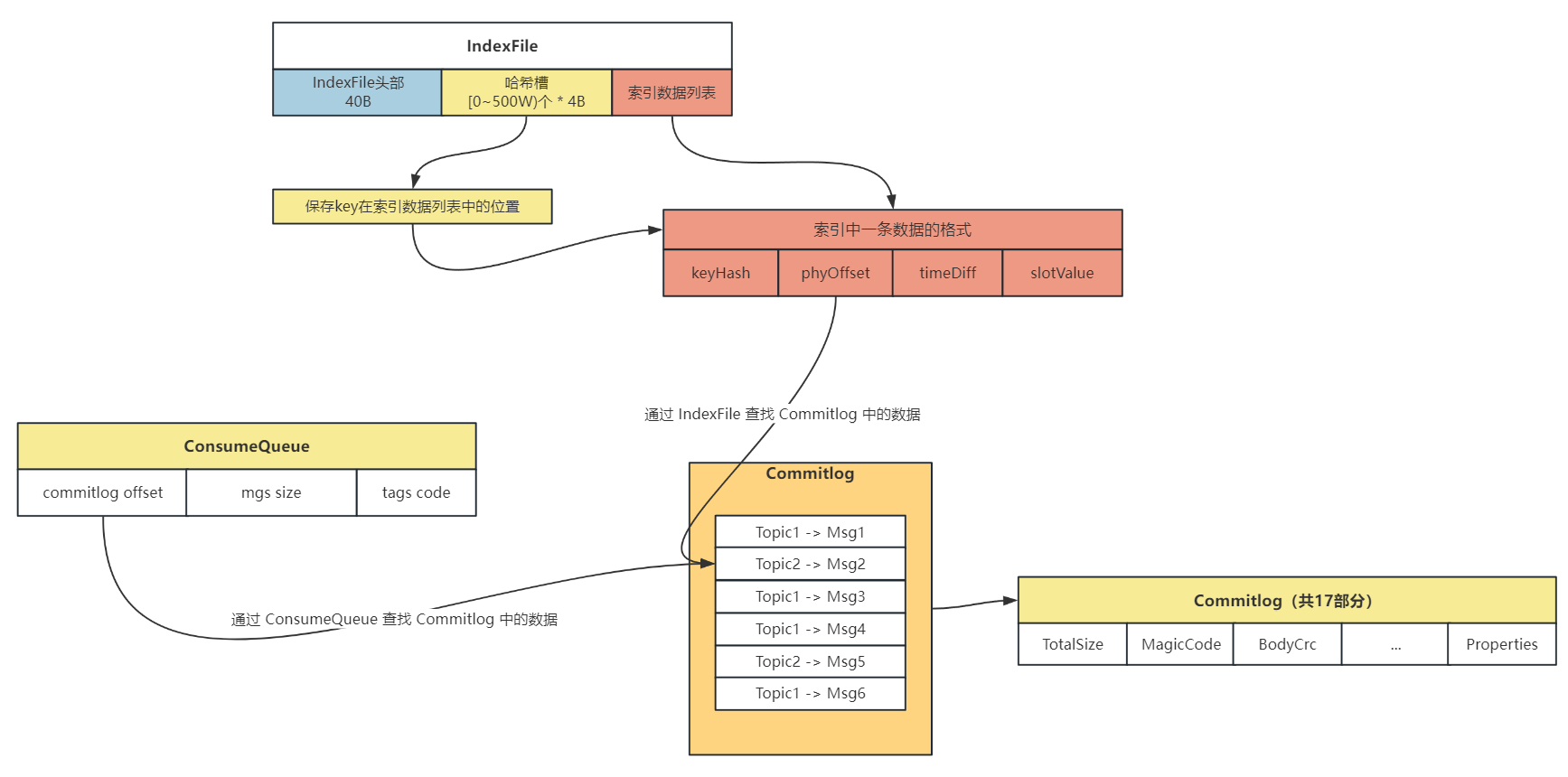
在 RocketMQ 存储架构中,采用混合存储,其中有 3 个重要的存储文件:Commitlog、ConsumeQueue、IndexFile
- Topic 的消息实体存储在
Commitlog中,顺序进行写入 ConsumeQueue可以看作是基于 Topic 的 Commitlog 的索引文件,在 ConsumeQueue 中记录了消息在 Commitlog 中的偏移量、消息大小的信息,用于进行消费IndexFile提供了可以通过 key 来查询消息的功能,key 是由topic + msgId组成的,可以很方便地根据 key 查询具体的消息
消费者去 Broker 中消费数据流程如下:
- 先读取 ConsumeQueue,拿到具体消息在 Commitlog 中的偏移量
- 通过偏移量在 Commitlog 读取具体 Topic 的信息
消费者去寻找 Commitlog 中的数据流程图如下:
那么先来看一下 Commitlog 文件在哪里进行写入
从 SendMessageProcessor # processRequest 作为入口,
经过层层调用 this.sendMessage() -> this.brokerController.getMessageStore().putMessage(msgInner) -> DefaultMessageStore # asyncPutMessage ,最终到达 asyncPutMessage() 方法中,在这里会进行消息的磁盘写的操作:
-
创建消息存储所对应的 ByteBuffer:
putMessageThreadLocal.getEncoder().encode(msg)在这个方法中,会对 Commitlog 文件进行写入:
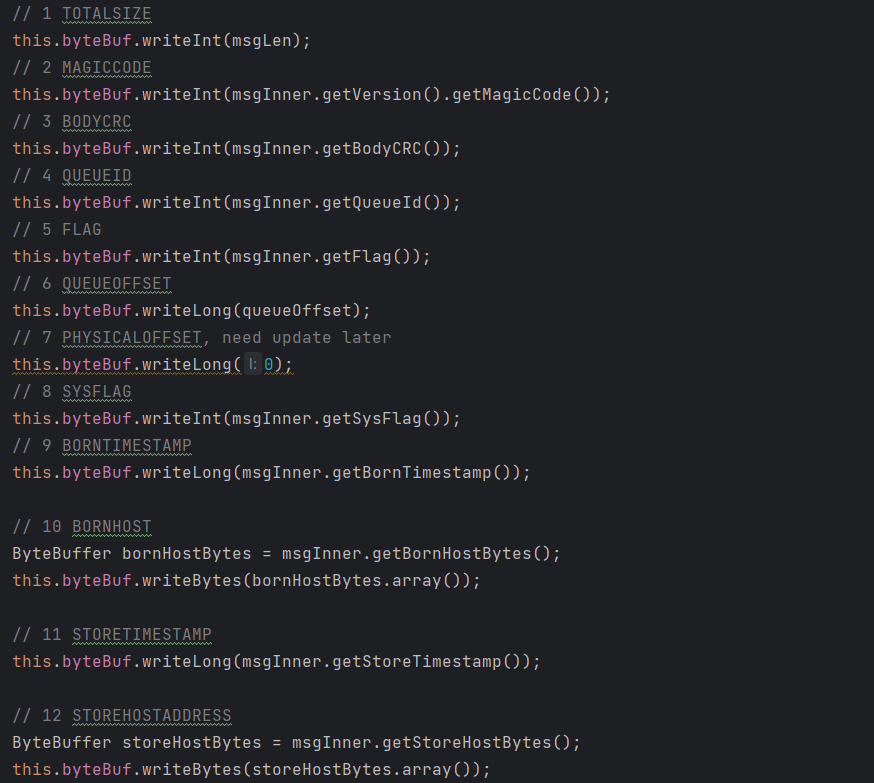
这里的 byteBuffer 也就是 Commitlog 文件的结构如下:

-
将创建的 ByteBuffer 设置到 msg 中去:
msg.setEncodedBuff(putMessageThreadLocal.getEncoder().getEncoderBuffer()) -
开始向文件中追加消息:
result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext)
在 appendMessage 方法中主要是写入消息之后,Commitlog 中一些数据会发生变化,因此需要进行修改,还是经过层层调用 appendMessage()-> appendMessagesInner()-> cb.doAppend(),最终到达 doAppend 方法,接下来看这个方法都做了些什么:
-
首先取出来在上边创建消息对应的 ByteBuffer:
ByteBuffer preEncodeBuffer = msgInner.getEncodedBuff() -
接下来修改这个 ByteBuffer 中的一些数据:
这个 ByteBuffer 在创建的时候已经将一些默认信息设置好了,这里只需要对写入消息后会变化的信息进行修改!
- 先修改 QueueOffset (偏移量为 20 字节):
preEncodeBuffer.putLong(20, queueOffset) - 再修改 PhysiclOffset (偏移量为 28 字节):
preEncodeBuffer.putLong(28, fileFromOffset + byteBuffer.position()) - 再修改 SysFlag、BornTimeStamp、BornHost 等等信息,都是通过偏移量在 ByteBuffer 中进行定位,再修改
- 先修改 QueueOffset (偏移量为 20 字节):
那么通过上边就 完成了对 Commitlog 文件的追加操作 ,ReputMessageService 线程中的 run 方法,会每隔 1ms 就会去 Commitlog 中取出数据,写入到 ConsumeQueue 和 IndexFile 中
那么接下来寻找写 ConsumerQueue 的地方,也是通过调用链直接找到核心方法:
DefaultMessageStore # ReputMessageService # run-> this.doReput()-> DefaultMessageStore.this.doDispatch(dispatchRequest)-> dispatcher.dispatch(req)-> 这里进入到构建 ConsumeQueue 类的 dispatch 方法中:CommitLogDispatcherBuildConsumeQueue # dispatch()-> DefaultMessageStore.this.putMessagePositionInfo(request)-> this.consumeQueueStore.putMessagePositionInfoWrapper(dispatchRequest)-> this.putMessagePositionInfoWrapper(cq, dispatchRequest)-> consumeQueue.putMessagePositionInfoWrapper(request)-> this.putMessagePositionInfo()
这个调用链比较长,如果不想一步一步点的话,直接找到 ConsumeQueue # this.putMessagePositionInfo() 这个方法即可,在这个方法中向 byteBufferIndex 中放了 3 个数据,就是 ConsumeQueue 的组成 = Offset + Size + TagsCode
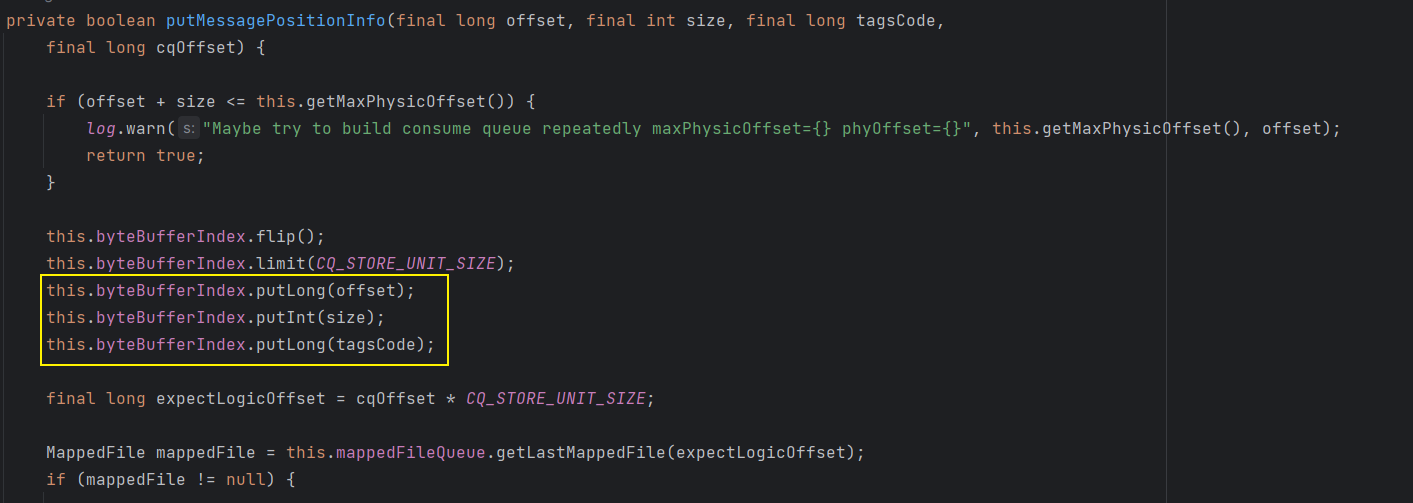
那么 ConsumeQueue 的组成结构就如下所示,通过 ConsumeQueue 主要用于寻找 Topic 下的消息在 Commitlog 中的位置:

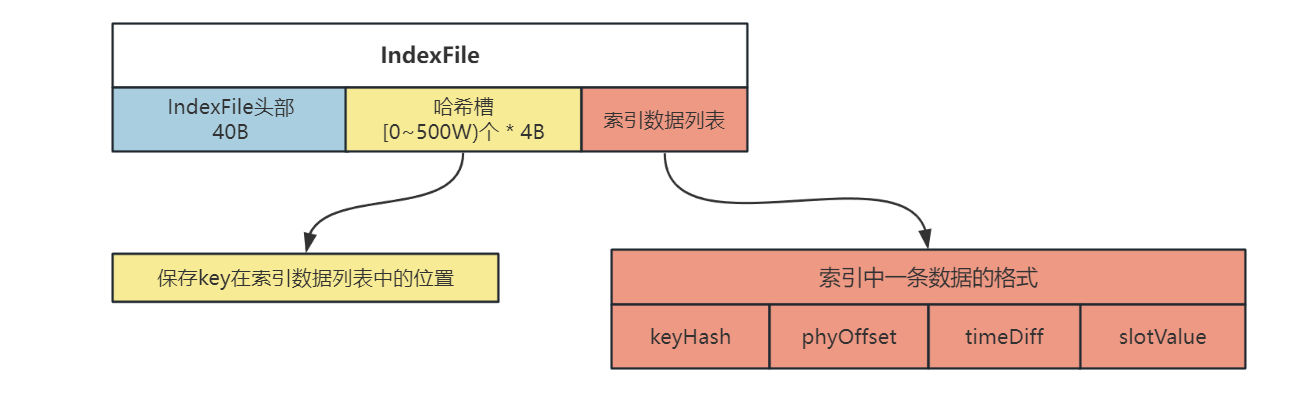
IndexFile 主要是通过 Key(Topic+msgId) 来寻找消息在 Commitlog 中的位置
接下来看一下 IndexFile 结构是怎样的,在上边寻找 ConsumeQueue 的调用链中,有一个 dispatcher.dispatch() 方法,这次我们进入到构建 IndexFile 的实现类的 dispatch 方法中,即:CommitLogDispatcherBuildIndex # dispatch(),那么接下来还是经过调用链到达核心方法:
CommitLogDispatcherBuildIndex # dispatch()-> DefaultMessageStore.this.indexService.buildIndex(request)-> indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()))-> indexFile.putKey(idxKey, msg.getCommitLogOffset(), msg.getStoreTimestamp())
那么核心方法就在 IndexFile # putKey() 中:
-
首先根据 key 计算出哈希值,key 也就是
Topic + 消息的 msgId -
再通过哈希值对哈希槽的数量取模,计算出在哈希槽中的相对位置:
slotPos = keyHash % this.hashSlotNum -
计算 key 在 IndexFile 中的绝对位置,通过
哈希槽的位置 * 每个哈希槽的大小(4B) + IndexFile 头部的大小(40B)代码即:
absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize -
计算索引在 IndexFile 中的绝对位置,通过
absIndexPos = IndexFile 头部大小(40B) + 哈希槽位置 * 哈希槽大小(4B) + 消息的数量 * 消息索引的大小(20B)int absIndexPos = IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize + this.indexHeader.getIndexCount() * indexSize; -
向 IndexFile 的第三部分(索引列表)中放入数据的索引,索引包含 4 部分,共 20B:
keyHash、phyOffset、timeDiff、slotValue
-
向 IndexFile 的第二部分(哈希槽)中放入数据

IndexFile 的结构如下图所示:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!