比起 Pandas, 你更需要 Polars:详细指南

在数据分析领域,Python 由于其多功能性和广泛的库生态系统而成为一种流行的语言。数据处理和分析在提取见解和做出明智决策方面发挥着至关重要的作用。然而,随着数据集的规模和复杂性不断增长,对高性能解决方案的需求变得至关重要。
有效地处理大型数据集需要能够提供快速计算和优化操作的工具。这就是 Polars 出现的原因。Polars 是一个强大的开源库,专为 Python 中的高性能数据操作和分析而设计。
Polars 功能
Polars?是一个完全用 Rust 编写的 DataFrame 库,旨在为 Python 开发人员提供可扩展且高效的数据处理框架,并被认为是非常流行的 pandas 库的替代品。它提供了广泛的功能,便于各种数据操作和分析任务。使用 Polars 的一些主要功能和优势包括:
1.速度和性能
Polars 在设计时充分考虑了性能。它利用并行处理和内存优化技术,使其处理大型数据集的速度明显快于传统方法。
2. 数据操作能力
Polars 为数据操作提供了一个全面的工具包,包括过滤、排序、分组、联接和聚合数据等基本操作。虽然由于其相对新颖,Polars 可能没有像 Pandas 那样广泛的功能,但它涵盖了 Pandas 中大约 80% 的常见操作。
3. 富有表现力的语法
Polars 采用简洁直观的语法,使其易于学习和使用。它的语法让人想起流行的 Python 库,如 Pandas,允许用户快速适应 Polars 并利用他们现有的知识。
4. DataFrame 和序列结构
Polars 的核心是 DataFrame 和 Series 结构,它们为处理表格数据提供了熟悉且强大的抽象。Polars 中的 DataFrame 操作可以链接在一起,从而实现高效、简洁的数据转换。
5. Polars 支持延迟评估
Polars 包含延迟评估,这涉及检查和优化查询以提高其性能并最大限度地减少内存消耗。使用 Polars 时,该库会分析您的查询,并寻找机会加快查询的执行速度或减少内存使用量。相比之下,Pandas 只支持立即评估,即在遇到表达式时立即对其进行评估。
有了 Pandas,为什么还要?Polars
Pandas?是一个被广泛采用的库,以其灵活性和易用性而闻名。然而,在处理大型数据集时,由于 Pandas 依赖于单线程执行,它可能会遇到性能瓶颈。随着数据集大小的增加,处理时间可能会变得非常长,从而限制了工作效率。
Polars 专为高效处理大型数据集而设计。凭借其惰性评估策略和并行执行能力,Polars 擅长快速处理大量数据。通过在多个 CPU 内核之间分配计算,Polars 利用并行性来提供令人印象深刻的性能提升。
安装 Polars
Polars 可以通过 Python 包管理器 pip 进行安装。打开命令行界面并运行以下命令:
pip install polars使用 Polars 中加载数据集
Polars 提供了从各种来源加载数据的便捷方法,包括 CSV 文件、Parquet 文件和 Pandas DataFrames。读取 CSV 或 parquet 文件的方法与 Pandas?库相同。
# read csv file
import polars as pl
data = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
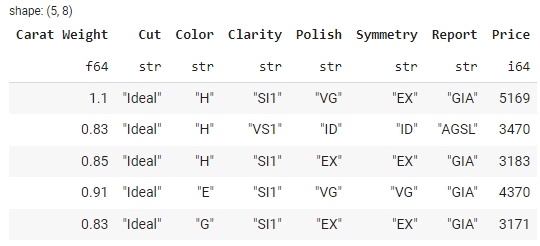
# check the head
data.head()
输出:
的类型是:polars.DataFrame
type(data)
>>> polars.dataframe.frame.DataFrame
Polars 的常见数据操作函数
Polars 提供了一套全面的数据操作功能,让您可以轻松选择、过滤、排序、转换和清理数据。让我们来看一些常见的数据操作任务,以及如何使用 Polars 完成这些任务:
1. 选择和筛选数据
若要从 DataFrame 中选择特定列,可以使用?select() 该方法。下面是一个示例:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
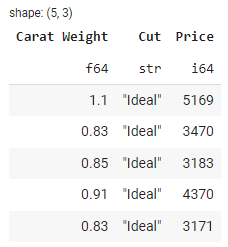
# Select specific columns: carat, cut, and price
selected_df = df.select(['Carat Weight', 'Cut', 'Price'])
# show selected_df head
selected_df.head()
输出:
可以使用?filter()方法根据某些条件筛选行。例如,要筛选克拉大于 1.0 的行,您可以执行以下操作:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
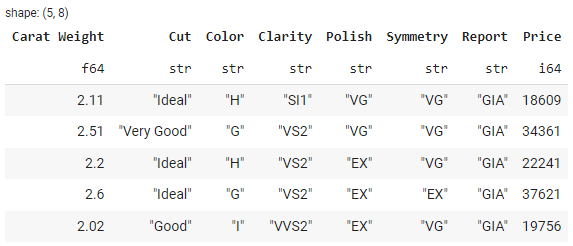
# filter the df with condition
filtered_df = df.filter(pl.col('Carat Weight') > 2.0)
# show filtered_df head
filtered_df.head()
输出:
2. 对数据进行排序和排序
Polars 提供了基于一列或多列对 DataFrame 进行排序的方法:sort()。下面是一个示例:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# sort the df by price
sorted_df = df.sort(by='Price')
# show sorted_df head
sorted_df.head()
输出:
3. 处理缺失值
Polars 提供了处理缺失值的便捷方法。该方法允许您删除包含任何缺失值的行:drop_nulls()
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# drop missing values
cleaned_df = df.drop_nulls()
# show cleaned_df head
cleaned_df.head()
输出:
或者,可以使用?fill_nulls()方法将缺失值替换为指定的默认值或填充方法。
4. 根据特定列对数据进行分组
若要根据特定列对数据进行分组,可以使用?groupby()方法。以下示例按列 Cut对数据进行分组,并计算每个组 Price的平均值:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# group by cut and calc mean of price
grouped_df = df.groupby(by='Cut').agg(pl.col('Price').mean())
# show grouped_df head
grouped_df.head()
输出:
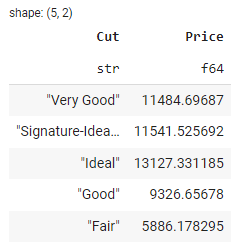
在上面的输出中,您可以按?Cut 查看钻石的平均价格。
5. 连接和组合 DataFrame
Polars 为连接和组合数据帧提供了灵活的选项,允许您合并和连接来自不同来源的数据。若要执行联接操作,可以使用?join()方法。以下示例演示了基于公共列的两个 DataFrame 之间的内部联接:
import polars as pl
# Create the first DataFrame
df1 = pl.DataFrame({
'id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David']
})
# Create the second DataFrame
df2 = pl.DataFrame({
'id': [2, 3, 5],
'age': [25, 30, 35]
})
# Perform an inner join on the 'id' column
joined_df = df1.join(df2, on='id')
# Display the joined DataFrame
joined_df
输出:

在此示例中,我们使用构造函数创建两个 DataFrames(df1 和 df2)。第一个 DataFrame 包含 id和 name,第二个 DataFrame 包含 id 和 age。然后,我们使用join()方法对列执行内部联接。
集成和互通性
Polars 提供与其他常用 Python 库的无缝集成,使数据分析师能够利用各种工具和功能。让我们来探讨一下集成的两个关键方面:与其他库的配合以及与 Pandas 的互通性。
将 Polars 与其他 Python 库集成
Polars 可方便地与 NumPy 和 PyArrow 等库集成,使用户能够在其数据分析工作流程中结合多种工具的优势。通过 NumPy 集成,Polars 利用 NumPy 强大的科学计算能力,毫不费力地在 Polars DataFrames 和 NumPy 数组之间进行转换。这种集成确保了数据的平稳过渡,并允许分析师将 NumPy 函数直接应用于 Polars 数据。
同样,通过利用 PyArrow,Polars 优化了 Polars 和基于 Arrow 的系统之间的数据传输。这种集成可以无缝处理以 Arrow 格式存储的数据,并利用 Polars 的高性能数据处理功能。
将 Polars DataFrames 转换为 Pandas DataFrames
Polars 提供 Polars DataFrames 到 Pandas DataFrames 的无缝转换。下面是一个示例,说明了从 Polars 到 Pandas 的转换。
import polars as pl
import pandas as pd
# Create a Polars DataFrame
df_polars = pl.DataFrame({
'column_A': [1, 2, 3],
'column_B': ['apple', 'banana', 'orange']
})
# Convert Polars DataFrame to Pandas DataFrame
df_pandas = df_polars.to_pandas()
# Display the Pandas DataFrame
df_pandas
输出:
结论
Polars?是一个强大的库,用于在 Python 中进行高性能数据操作和分析。它的速度和性能优化使其成为高效处理大型数据集的理想选择。
凭借其富有表现力的语法和 DataFrame 结构,Polars 为数据操作任务提供了熟悉且直观的界面。此外,Polars 与 NumPy 和 PyArrow 等其他 Python 库无缝集成,扩展了其功能并允许用户利用多样化的工具生态系统。
将 Polars DataFrames 转换为 Pandas DataFrames的能力确保了互操作性,并有助于将 Polars 集成到现有工作流程中。无论您是在处理复杂的数据类型、处理大型数据集,还是寻求性能改进,Polars 都能提供全面的工具包来释放数据分析工作的全部潜力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!