基于Bboss快速构建高效、可靠、安全的Elasticserach全文检索以及统计分析应用
一、简介
Bboss后端基于Gradle模块化构建,灵活便捷。框架模块丰富,涵盖数据同步ETL工具、J2ee开发框架、微服务、数据库、中间件、安全、配置、缓存、国际化、elasticsearch client、web session共享、redis、kafka、mongodb工具包等常用模块,最大程度满足开发需要。同时,严格遵守WEB安全规范,从根本上避免SQL注入、XSS攻击、CSRF攻击等常见的 Web 攻击手段。支持主流的分布式微服务架构,快速构建高可用服务集群。
Bboss基于Apache License开源协议,由开源社区bboss发起和维护,主要由以下三部分构成:
-
Elasticsearch Highlevel Java Restclient?, 一个高性能高兼容性的Elasticsearch/Opensearch java客户端框架
-
数据采集同步ETL?,一个基于java语言实现数据采集作业的强大ETL工具,提供丰富的输入插件和输出插件,可以基于插件规范轻松扩展新的输入插件和输出插件
-
流批一体化计算框架,提供灵活的数据指标统计计算流批一体化处理功能的简易框架,可以结合数据采集同步ETL工具,实现数据流处理和批处理计算,亦可以独立使用;计算结果可以保存到各种关系数据库、分布式数据仓库Elasticsearch、Clickhouse等,特别适用于数据体量和规模不大的企业级数据分析计算场景,具有成本低、见效快、易运维等特点,助力企业降本增效。
此外,B-BOSS还是中国移动面向商业客户的后台业务支撑系统,功能上不仅涵盖了集团客户和合作伙伴的计费(部分)、结算、账务、业务等方面,并且尝试建立对于全电信业务的综合服务开通,服务保障机制。
二、功能特色
-
ORM和DSL二者兼顾,类mybatis方式操作ElasticSearch,提供丰富的开发API和开发Demo;
-
采用XML文件配置和管理检索dsl脚本,简洁而直观;提供丰富的逻辑判断语法,在dsl脚本中可以使用变量、脚本片段、foreach循环、逻辑判断、注释;基于可扩展DSL配置管理机制可以非常方便地实现数据库、redis等方式管理dsl;配置管理的dsl语句支持在线修改、自动热加载,开发和调试非常方便;
-
提供Elasticsearch集群节点自动负载均衡和容灾恢复机制,Elasticsearch节点断连恢复后可自动重连,高效可靠;
-
提供Elasticsearch集群节点自动发现机制:自动发现Elasticsearch服务端节点增加和下线操作并变更客户端集群可用节点地址清单;
-
提供http 连接池管理功能,提供精细化的http连接池参数配置管理;
-
支持在应用中访问和操作多个Elasticsearch集群,每个Elasticsearch集群的版本可以不同;
-
支持基于X-Pack和searchguard两种安全认证机制;
-
支持Elasticsearch-SQL-ORM和Elasticsearch-JDBC;
-
提供高效的BulkProcessor处理机制;
-
提供按时间日期ES历史数据清理工具;
学习成本低,上手快,代码简洁,安全高效,客户端负载容灾,兼容性好,易于集成。
三、应用场景
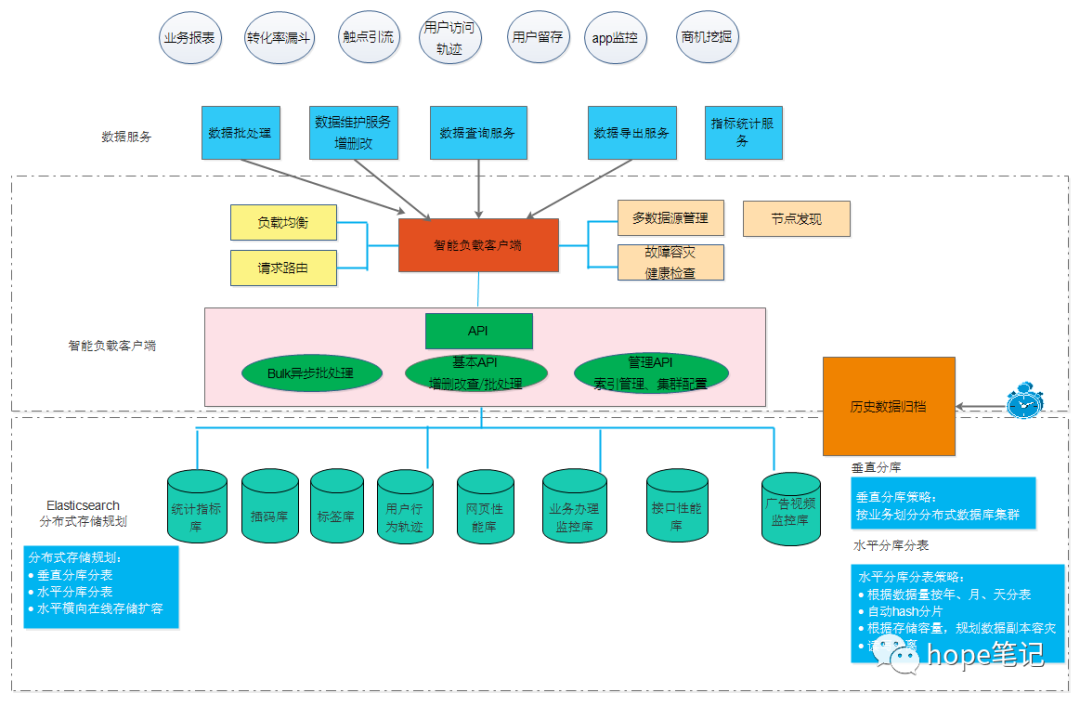
四、Elasticsearch Highlevel Java Restclient
Bboss Elasticsearch Highlevel Java Restclient是一套基于query dsl语法操作和访问分布式搜索引擎Elasticsearch/Opensearch的o/r mapping高性能开发库
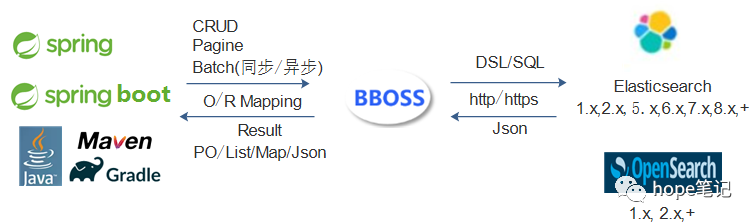
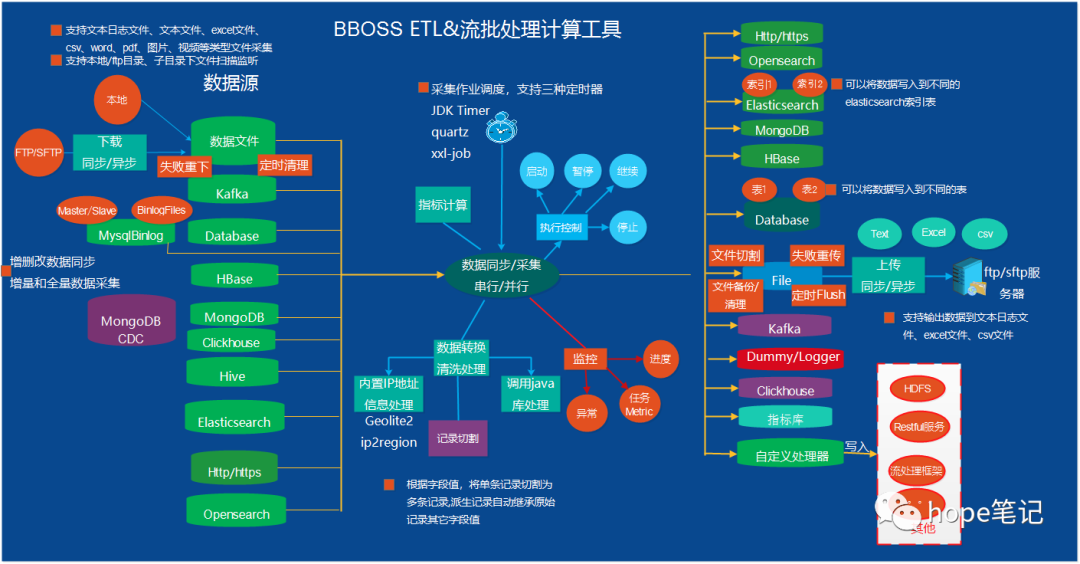
五、数据采集同步ETL以及流批一体化计算框架
数据采集同步ETL以及流批一体化计算框架,基于灵活的插件体系结构,提供数据采集、数据清洗转换处理和数据入库以及数据指标统计计算流批一体化处理功能,提供丰富的输入插件和输出插件,可以基于插件规范轻松扩展新的输入插件和输出插件:
六、数据采集ETL
数据采集同步ETL以及流批一体化计算作业分为作业配置态和运行态,作业可以独立调度运行,亦可以嵌入到应用中运行,同时也可以和各种主流的调度引擎(quartz、xxl-job等)结合运行:
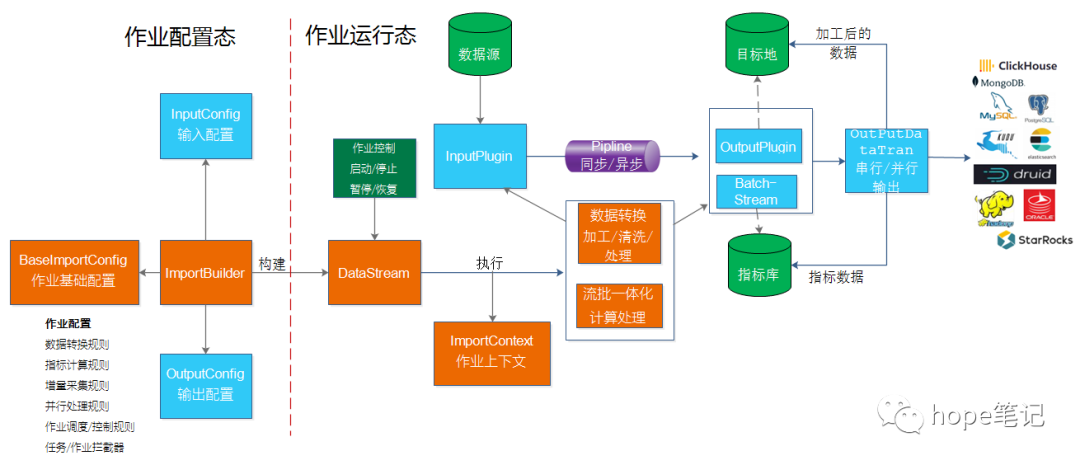
通过bboss可以灵活定制具备各种功能的数据采集统计作业:
1) 只采集和处理数据作业;
2) 采集和处理数据、指标统计计算混合作业--通过ImportBuilder注册ETLMetrics+其他数据源Output插件结合实现;
importBuilder.setDataTimeField("logOpertime");
importBuilder.addMetrics(keyMetrics);//通过importBuilder注册指标计算器,对采集数据进行指标计算并保存指标计算结果到各种数据库
ElasticsearchOutputConfig elasticsearchOutputConfig = new ElasticsearchOutputConfig();
elasticsearchOutputConfig
.setTargetElasticsearch("default")
.setIndex("dbdemo")
.setEsIdField("log_id")//设置文档主键,不设置,则自动产生文档id
.setDebugResponse(false)//设置是否将每次处理的reponse打印到日志文件中,默认false
.setDiscardBulkResponse(false);//设置是否需要批量处理的响应报文,不需要设置为false,true为需要,默认false
importBuilder.setOutputConfig(elasticsearchOutputConfig);//设置Elasticsearch输出插件,保存加工后的原始数据3) 采集数据只做指标统计计算作业--通过指标插件MetricsOutputConfig实现;
MetricsOutputConfig metricsOutputConfig = new MetricsOutputConfig();
metricsOutputConfig.setDataTimeField("logOpertime");
metricsOutputConfig.addMetrics(keyMetrics);//通过Metrics输出插件注册指标计算器,对采集数据进行指标计算并保存指标计算结果到各种数据库
importBuilder.setOutputConfig(metricsOutputConfig);//设置Metrics输出插件4)可以在应用中单独集成和使用指标统计功能;
七、数据采集特点
Bboss支持全量和增量数据采集,增量数据采集默认基于sqlite数据库管理增量采集状态,可以配置到其他关系数据库管理增量采集状态,提供对多种不同数据来源增量采集机制:
-
基于数字字段增量采集:各种关系数据库、Elasticsearch、MongoDB、Clickhouse等;
-
基于时间字段增量采集:各种关系数据库、Elasticsearch、MongoDB、Clickhouse、HBase等,基于时间增量还可以设置一个截止时间偏移量,比如采集到当前时间前十秒的增量数据,避免漏数据;
-
基于文件内容位置偏移量:文本文件、日志文件基于采集位置偏移量做增量;
-
基于ftp文件增量采集:基于文件级别,下载采集完的文件就不会再采集;
-
支持mysql binlog,实现mysql增删改实时增量数据采集;
八、流批一体化计算特点
-
支持时间维度和非时间维度指标计算;
-
时间维度指标计算:支持指定统计滑动时间窗口,支持设定时间统计窗口类型,在流处理或者离线处理过程中,对于数据到来的先后顺序没有严格要求,乱序数据不影响最终指标计算结果;
-
一个指标支持多个维度和多个度量字段计算,多个维度字段值构造成指标的唯一指标key,支持有限基数key和无限基数key指标计算(维度字段组合形成的唯一指标key的个数是有限的就是有限基数,个数是无限的就是无限基数);
-
一个作业可以支持多种类型的指标,每种类型指标支持多个指标计算;
-
支持准实时指标统计计算和离线指标统计计算;
-
可以从不同的数据输入来源获取需要统计的指标数据,亦可以将指标计算结果保存到各种不同的目标数据源;
九、典型应用案例---互联网用户行为分析监控
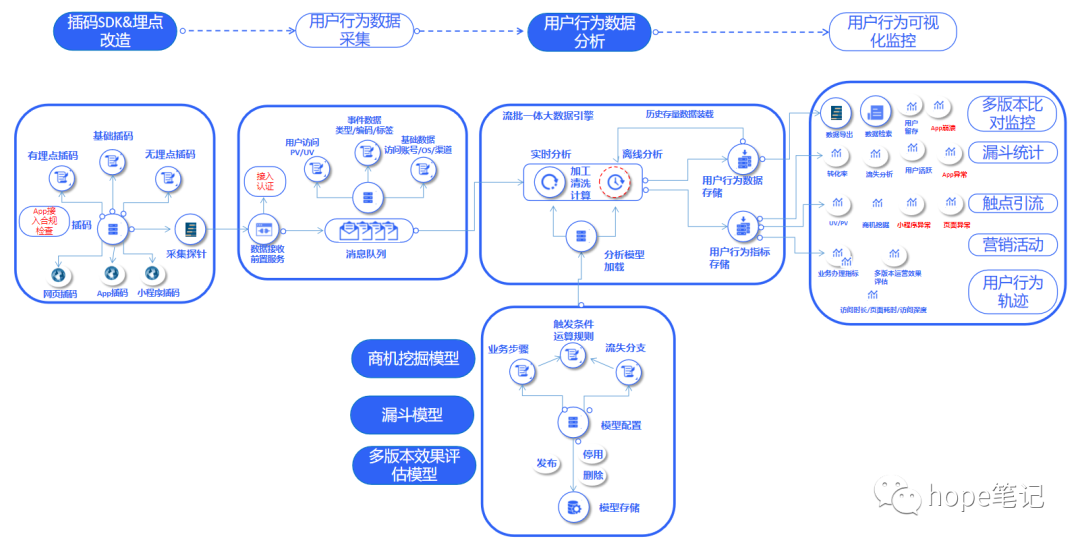
十、兼容性
作为Elasticsearch兼容性最好的java客户端和数据采集&流批一体化计算工具,bboss各版本对Elasticsearch、Spring boot兼容性说明如下:
| bboss | Elasticsearch | spring boot |
|---|---|---|
| all | 1.x | 1.x,2.x,3.x |
| all | 2.x | 1.x,2.x,3.x |
| all | 5.x | 1.x,2.x,3.x |
| all | 6.x | 1.x,2.x,3.x |
| all | 7.x | 1.x,2.x,3.x |
| all | 8.x | 1.x,2.x,3.x |
jdk兼容性:jdk 1.8+

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!