链表入门:“单链表“的基本操作详解(C语言)
目录
一,了解链表
链式存储结构——借助指示元素存储地址的指针表示数据
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?元素间的逻辑关系:(逻辑相邻,物理不一定相邻)
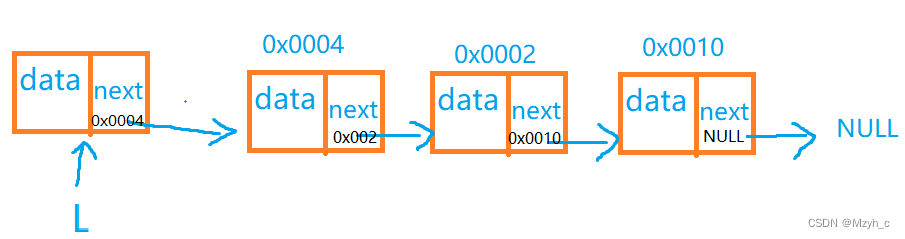
链表是由一系列结点(链表中每一个元素称为结点)组成,每个结点包括两个部分:数据域(存储本结点的数据元素)和指针域(存储下一个结点的地址)。
由于链表在运行时可以动态生成结点,所以链表相比于数组,具有动态分配内存、方便插入和删除、节省空间等优点。
链表按照节点的连接方式可以分为单链表、双向链表和循环链表三种类型。这里我们只讨论单链表。
一些概念的了解
- 头结点(在链表的首元结点之前附设的一个结点)是用来辅助链表操作的,它本身并不算作链表的节点,因此在统计链表长度时需要将头结点去掉。头结点的数据域通常不赋值
- 头指针:指向第一个结点(链表有头结点的时候就是头结点)
- 空链表:链表中无元素(有头结点)
- ?下图是一个带有头结点的单链表?
二,基本操作的实现
对数据的进行的操作基本就是“增删查改”。
1.? 在代码开头的预处理和声明
#include<stdio.h>
#include<stdlib.h>
typedef struct node
{
int data; //数据域
struct node* next; //指针域
}LinkNode;如果你使用的是Visual Studio进行编写的代码,请在第一行添加:
#define _CRT_SECURE_NO_WARNINGS
2.? 对链表进行初始化
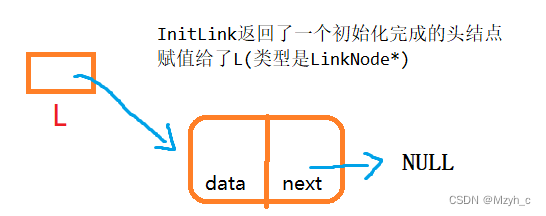
LinkNode* InitList()
{
//创建一个结构体指针并进行分配空间
LinkNode* temp = (LinkNode*)malloc(sizeof(LinkNode));
//将结构体指针的指针域赋值为NULL
temp->next = NULL;
//返回初始化完成的结构体指针
return temp;
}
- ?malloc向内存申请一块连续可用的空间,开辟成功会返回指向这块空间的指针(类型为void*), 开辟失败返回NULL, 所以得判断是否开辟成功并对指向空间的指针的类型的强制转换。
?在main函数中创建指向结构体L的指针来接收已经初始化完成的链表(只有头结点)。
//创建一个指向结构体的指针来记录头结点
LinkNode* L = InitList();
一个错误案例的分析:
对下面错误的代码进行分析:
void InitList(LinkNode* pL){ pL = (LinkNode*)malloc(sizeof(LinkNode)); pL->next = NULL; } int main() { LinkNode L;//创建一个结构体变量 InitList(&L);//初始化链表 //... return 0; }在main函数中创建了一个L结构体变量(L已经有了自己的地址),将L的地址传递给InitList()函数,InitList()函数内接收一个指向结构体变量L的指针pL。
- 使用malloc开辟空间会返回一块空间的地址,而函数中 pL 是一个记录着 结构体变量L 地址的指针。如果把 开辟的空间地址 给到 pL ,则 pL 就指向了为malloc开辟的大小为sizeof(LinkNode)的空间的地址,此时pL不再记录的是结构体变量L的地址,后面的 pL->next = NULL;也只修改pL这个指针指向的空间的变量。当执行走出函数体后,pL这个指针就会被销毁,在main函数中,L还是未初始化。
- 上面例子的正确修改: 把InitList函数中的 malloc开辟空间赋值给pL 的代码去掉。
LinkNode* L? ? 指向链表的某一个结点。(只能修改所指向结点中的内容)
LinkNode** L? 指向记录链表地址的指针,可以修改链表。(可以改变一级指针的地址)
一级指针记录变量的地址,二级指针记录一级指针的地址。
一级指针只能修改所记录变量的内容,二级指针可以修改一级指针的内容(即一级指针的地址)。
3.? 对链表进行“增”操作
(1) “头插法”在链表头结点之后插入结点
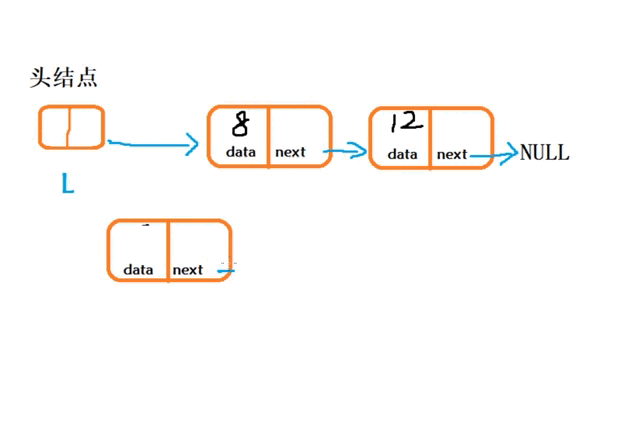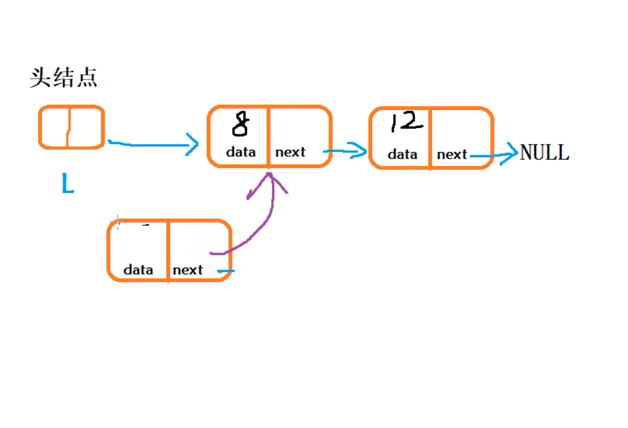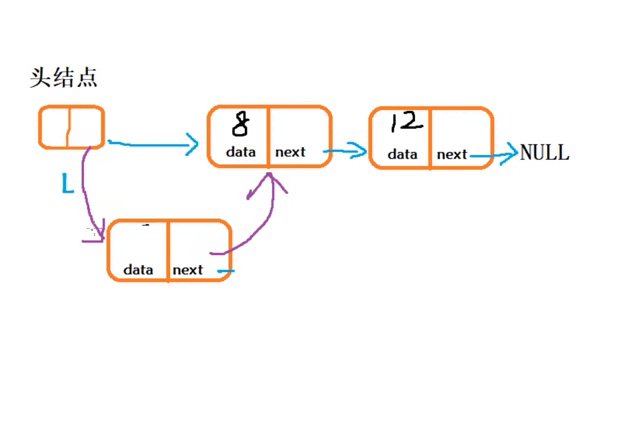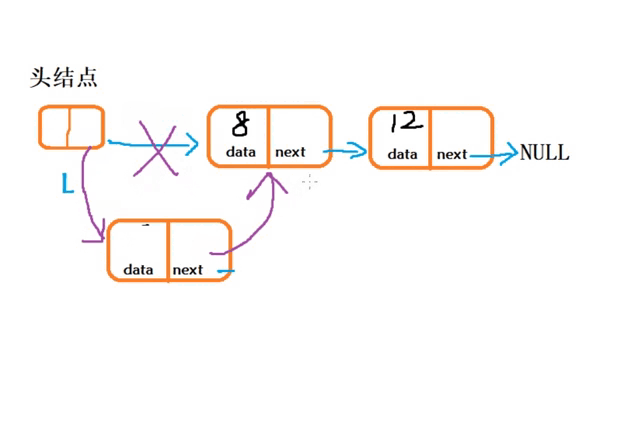
1. 从一个空表开始,重复读入数据:
2.生成新结点,将读入数据存放到新结点的数据域中3. 从最后一个结点开始,依次将各结点插入到链表的前端void CreateLink_H() { //创建一个带头结点的单链表 LinkNode* L = (LinkNode*)malloc(sizeof(LinkNode)); L->next = NULL; int n = 3, e = 0;//n为创建的新结点个数,e为结点的数据 for (int i; i < n; i++) { //生成新结点P LinkNode* P = (LinkNode*)malloc(sizeof(LinkNode)); //给新结点P的数据域赋值 printf("请输入新结点元素e的值:\n"); scanf("%d", &e); P->data = e; //将新结点插入表头 P->next = L->next; L->next = P; } }
(2) “尾插法”在链表的最后一个结点后插入结点

1.从一个空表L开始,将新结点逐个插入到链表的尾部,尾指针r指向链表的尾结点。
2.初始时,r同L均指向头结点。每读入一个数据元素则申请一个新结点,将新结点插入到尾结点后,r指向新结点。void CreateLink_R(LinkNode* L) { //创建一个带头结点的单链表 LinkNode* L = (LinkNode*)malloc(sizeof(LinkNode)); L->next = NULL; //创建一个尾指针指向头结点(空链表中的头就是尾) LinkNode* r = L; int n = 3, e = 0;//n为创建的新结点个数,e为结点的数据 for (int i; i < n; i++) { //创建一个新结点 LinkNode* P = (LinkNode*)malloc(sizeof(LinkNode)); //给新结点P的数据域赋值 printf("请输入新结点元素e的值:\n"); scanf("%d", &e); P->data = e; //将新结点插入表尾 P->next = NULL; r->next = P; //r指向新的尾结点 r = P; } }
(3) 在指定位置插入结点
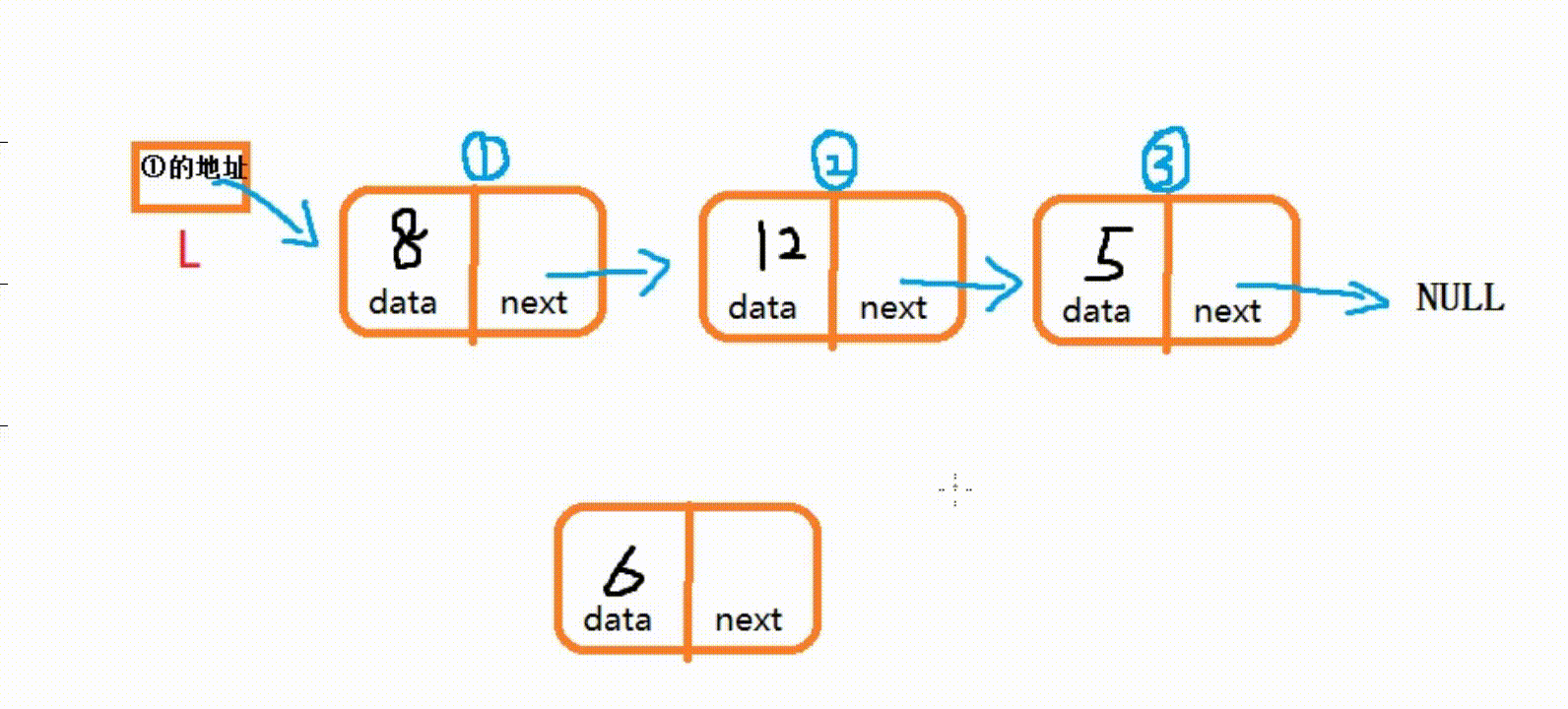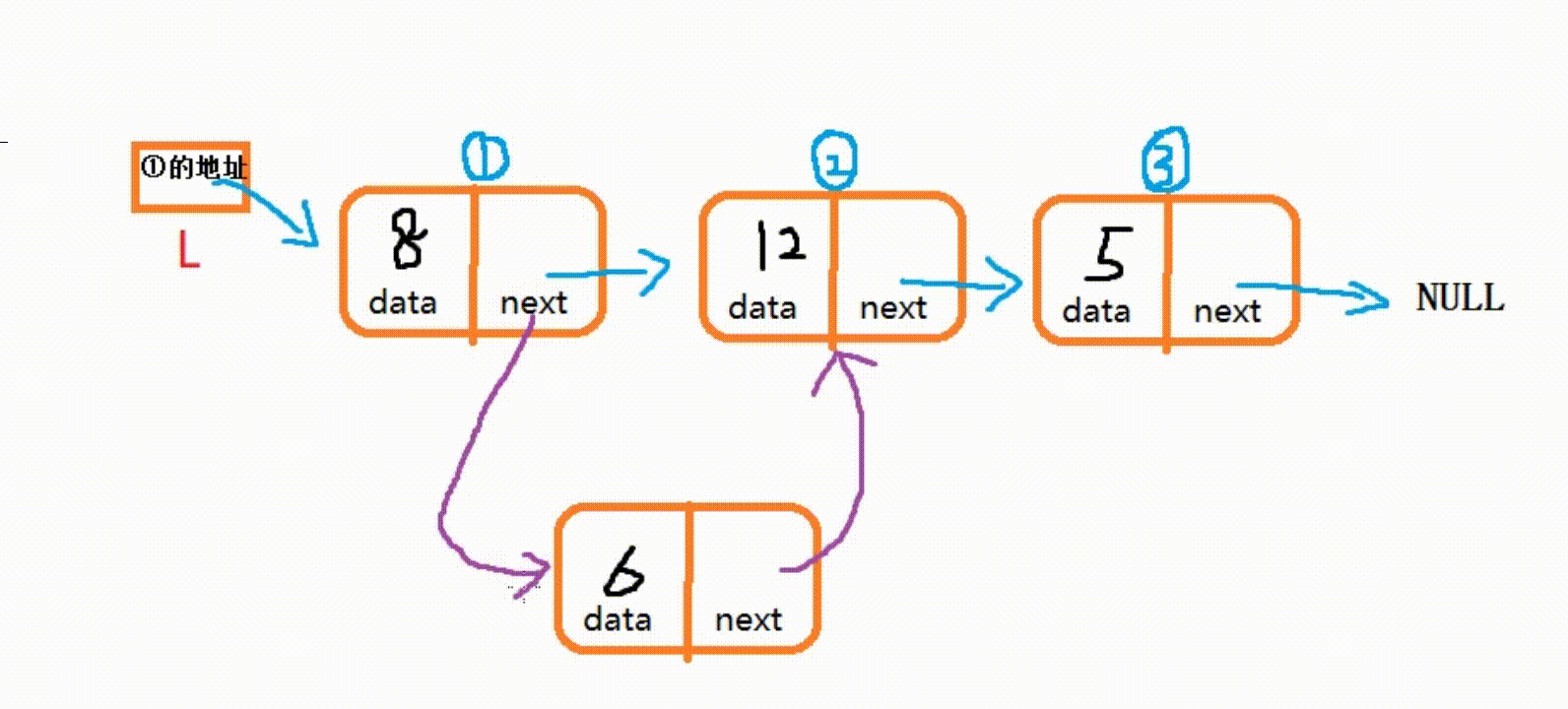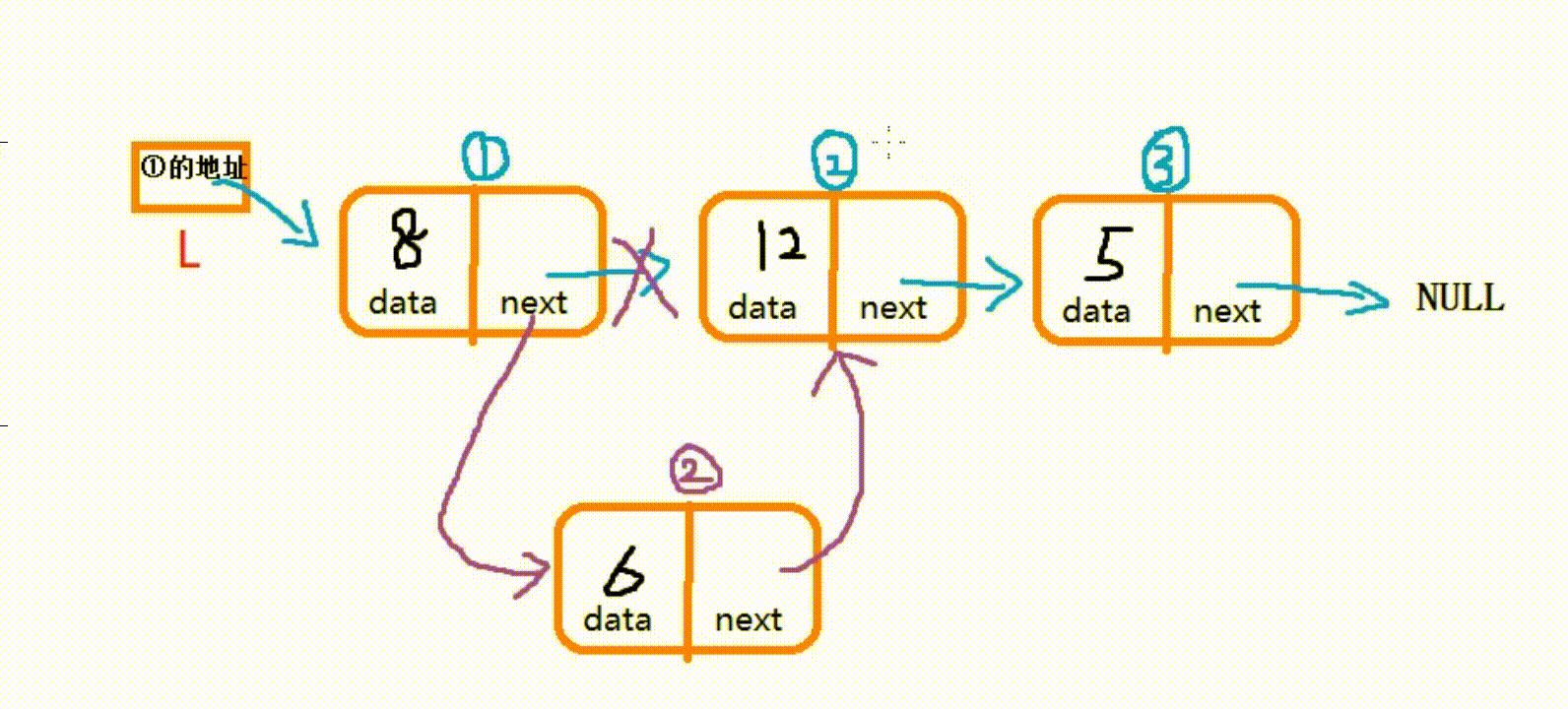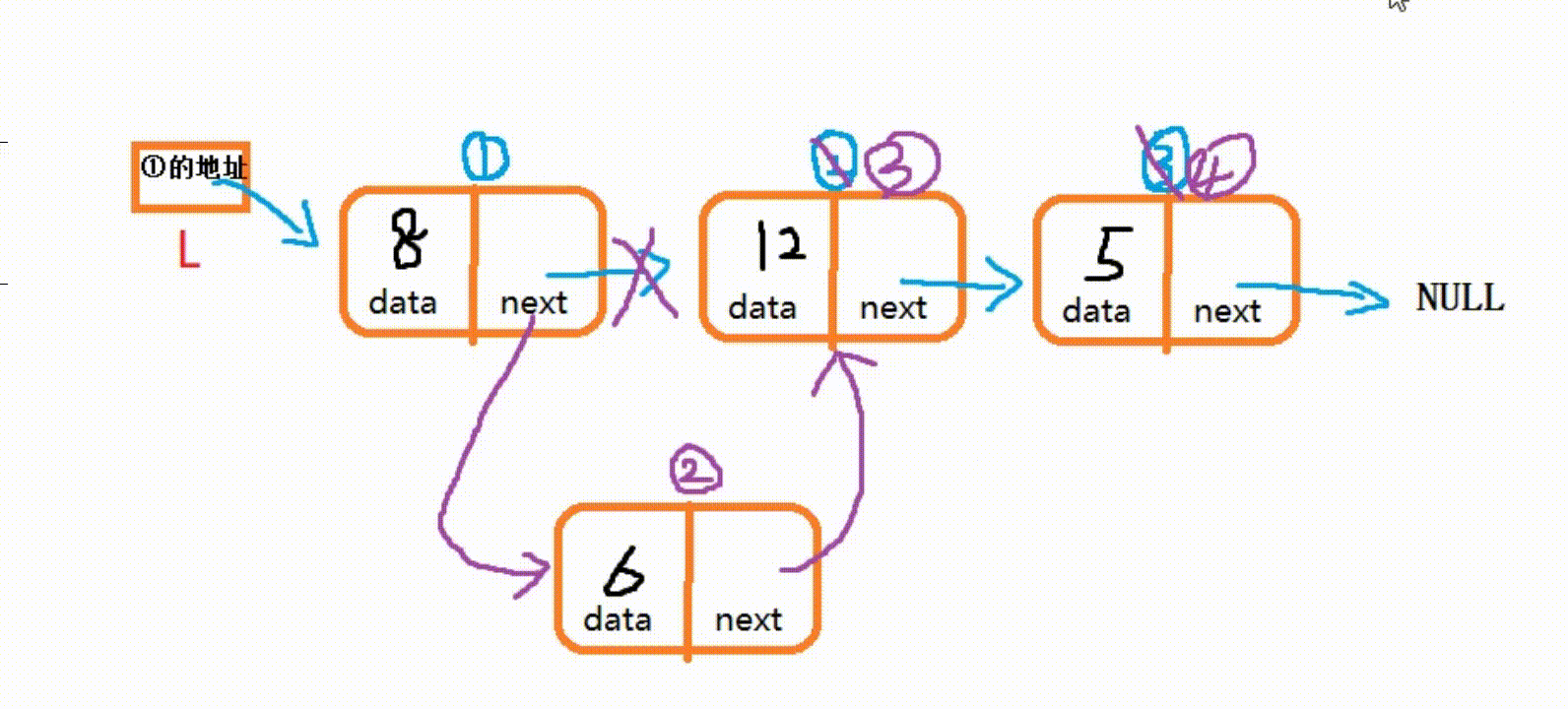

- 在 i 位置插入新元素, 需要找到第 i-1?个结点, 将第 i-1 个结点的指针域赋值给新结点P的指针域,然后将第 i-1 个结点的next赋值为新结点P的地址。
int LinkInsert(LinkNode* L, int i, int e) { //L为记录头结点的指针, i为插入位置, e为插入元素 LinkNode* temp = L; int count = 0; //默认长度为0 while (temp->next && count < i - 1) { //寻找第i个结点,并使temp指向第i-1个结点 temp = temp->next; count++; } if (count < i - 1) { ///第i个位置不存在,则进行提示并返回0 printf(">>>访问越界,请重试!\n"); return 0; } //在链表的第i个位置插入新结点P LinkNode* P = (LinkNode*)malloc(sizeof(LinkNode)); P->data = e; P->next = temp->next; //将temp下一个结点给P的地址域 temp->next = P; //将P的地址赋值给temp的地址域 return 1; //成功插入则返回1 }
?分析:
int count = 0; while (temp->next && count < i - 1) { temp = temp->next; count++; }
temp->next?判断当前结点的下一个结点是否存在,如果不存在说明已经到达链表末尾。count < i - 1?判断遍历过的结点个数是否小于?i - 1,即判断是否找到了第?i - 1?个结点。- 2个条件一起使用可以确保 temp 指针移动到第 i-1个结点的位置(i-1不大于表长时),并避免访问空指针导致的错误。
if (count < i - 1) { ///第i个位置不存在,则进行提示并返回0 printf(">>>访问越界,请重试!\n"); return 0; }? ? 在上面循环的while中已经根据 i 对count的值进行计数,count最大时等于链表长度,
? ? 当 i-1 大于链表长度时,则无法访问到 i 结点(没有 i 这个结点). 则进行提示并返回。
·要注意的是:①结点的指针域记录着②结点的地址,所以不可以先把新结点的地址赋值给①结点
(temp->next = P;)。而是先把②结点的地址赋给P的指针域,再把P的地址赋值给①结点的指针域,才能正确链接.
(P->next = temp->next;?temp->next = P;?)
3,对链表进行“删”操作
?(1) 从链表中删除第 i 个元素

- 对第 i 个结点进行删除, 需要找到第 i -1 个结点, 将其指针域更改为第 i+1 个结点的地址, 然后再对第 i 个结点进行删除。
int LinkDelect(LinkNode* L, int i) { LinkNode* temp = L; int count = 0; while (temp->next && count < i - 1) { //寻找第i个结点,并使temp指向第i-1个结点 temp = temp->next; count++; } if (!(temp->next) || count < i - 1) { ///要删除的位置不存在,则进行提示并返回0 printf(">>>删除位置不合理,请重试!\n"); return 0; } LinkNode* P = temp->next; //临时存储要删除结点的地址,用于后续释放 temp->next = P->next; free(P); //释放被删除的地址 }
?分析:
- ?其中 while 遍历部分, 和 if 判断部分和上面插入的功能是一样的。
LinkNode* P = temp->next; temp->next = P->next;
- 这一部分代码就是将要删除结点( i )的后继结点的地址赋值给 i 的前驱结点的地址域, 当?i 结点删除后,也可以通过 i 的前驱结点内的地址域去访问到 i 的后继结点。
- 在删除某个结点以后,需要将其原先的地址进行释放(防止内存泄漏), 上述代码使用指针P记录了要删除结点( i )的地址, 防止删除结点后地址丢失。
free(P); //释放被删除的地址
?(2) 销毁单链表

void LinkDestroy(LinkNode* L)
{
LinkNode* P;
while (L)//当L为NULL时停止
{
P = L;
L = L->next;
free(P);
}
}
- ?创建一个指针P来指向L当前的结点
- 然后L->next指向下一个结点
- 删除P所指向的地址
- 然后再循环执行上述过程,直到L指向NULL(空结点)
4.? 对链表进行“查”操作

(1) 打印链表中的元素
开头先创建一个结构体指针指向头结点,通过循环遍历来获取每一个结点的数据并打印。
void LinkPrint(LinkNode* L) { LinkNode* P = L->next; printf(">链表中的元素为:"); while (P) { printf(" %d", P->data); P = P->next; } printf("\n"); }
(2) 获取链表中元素的个数
使用计数器思想即可解决!最后记得返回计数器len(返回类型为int)。
int LinkLenght(LinkNode* L) { LinkNode* temp = L; int len = 0; //默认长度为0 while (temp->next) { temp = temp->next; len++; //遍历得到链表长度 } return len; }
(3) 在单链表中查找元素e的位置
整体思路和上面一样。
当指针P遍历找到数据e时,则会退出循环;反之,指针P找不到元素e则会循环到P=NULL。退出循环后进行判断,P为非空指针则表示找到数据e,返回其位置,P为空指针则返回0。
int LocationElem(LinkNode* L, int e) { LinkNode* P = L; int index = 0; while (P && P->data != e) { P = P->next; index++; } if (P) return index; //返回数据e的位置 else return 0; //找不到则返回0 }
?(4) 在单链表中获取 i 位置的元素
整体思路和上面一样。
需要注意的是:输入的 i 小于1(不合理的值)和P为NULL时返回-1
int GetElem(LinkNode* L, int i) { LinkNode* P = L->next;//从第一个结点开始 int count = 1; while (P && count < i) { P = P->next; count++; } if (!P || count > i) { //没找到,或者i的值不合理(小于1)则返回-1 return -1; } //找到则返回对应的元素值 return P->data; }
5.? 对链表进行“改”操作
(1),修改第i个结点的数据
理解上面的代码后,这个基本差不多,就不写了? :3
三,整体的实现和效果
下面代码中没有:1,头插法创建链表;2,尾插法创建链表;3,“查找元素e的位置”
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
typedef struct node
{
int data; //数据域
struct node* next; //指针域
}LinkNode;
LinkNode* InitList()
{
//初始化一个带头结点的链表
LinkNode* temp = (LinkNode*)malloc(sizeof(LinkNode));
temp->next = NULL;
return temp;
}
int LinkEmpty(LinkNode* L)
{
if (L)
{
return 1;
}
return 0;
}
int LinkInsert(LinkNode* L, int i, int e)
{
//L为记录头结点的指针, i为插入位置, e为插入元素
LinkNode* temp = L;
int count = 0; //默认长度为0
while (temp->next && count < i - 1)
//确保 temp 指针移动到第 i-1 个结点的位置,并避免访问空指针导致的错误。
{
//寻找第i个结点,并使temp指向第i-1个结点
temp = temp->next;
count++;
}
//上面循环中已经根据i对count的值进行计数,count最大时等于链表长度,
//当i-1大于链表长度时,则无法访问i结点(没有i这个结点)
if (!(temp) || count < i - 1)
{
///第i个位置不存在,则进行提示并返回0
printf(">>>访问越界,请重试!\n");
return 0;
}
//在链表的第i个位置插入新结点P
LinkNode* P = (LinkNode*)malloc(sizeof(LinkNode));
P->data = e;
P->next = temp->next; //将temp下一个结点给P的地址域
temp->next = P; //将P的地址赋值给temp的地址域
return 1; //成功插入则返回1
}
void LinkPrint(LinkNode* L)
{
LinkNode* P = L->next;
printf(">链表中的元素为:");
while (P)
{
printf(" %d", P->data);
P = P->next;
}
printf("\n");
}
int LinkLenght(LinkNode* L)
{
LinkNode* temp = L;
int len = 0; //默认长度为0
while (temp->next)
{
temp = temp->next;
len++; //遍历得到链表长度
}
return len;
}
int LinkDelect(LinkNode* L, int i) {
LinkNode* temp = L;
int count = 0;
while (temp->next && count < i - 1)
{
//寻找第i个结点,并使temp指向第i-1个结点
temp = temp->next;
count++;
}
if (!(temp->next) || count < i - 1)
{
///第i个位置不存在,则进行提示并返回0
printf(">删除位置不合理,请重试!\n");
return 0;
}
LinkNode* P = temp->next;//临时存储要删除结点的地址,用于后续释放
temp->next = P->next;
free(P); //释放被删除的地址
}
void LinkDestroy(LinkNode* L)
{
LinkNode* P;
while (L)//当L为NULL时停止
{
P = L;
L = L->next;
free(P);
}
}
int main()
{
//创建一个结构体变量指针
LinkNode* L = InitList();
printf("^链表初始化成功.\n");
printf("\n");
//判断链表是否为空
int flag = LinkEmpty(L);
flag ? printf(">>>链表不为空\n") : printf(">>>链表为空\n");
printf("\n");
//插入新元素 + 打印链表中的元素
LinkInsert(L, 1, 11);//L,i,e
LinkPrint(L);
LinkInsert(L, 2, 12);
LinkPrint(L);
LinkInsert(L, 3, 13);
LinkPrint(L);
LinkInsert(L, 4, 14);
LinkPrint(L);
LinkInsert(L, 3, 3);
LinkPrint(L);
LinkInsert(L, 6, 5);
LinkPrint(L);
LinkInsert(L, 9, 5);//越界访问
LinkPrint(L);
printf("\n");
//求链表中元素个数
int len = LinkLenght(L);
printf(">>>链表的元素个数为: %d\n", len);
printf("\n");
//从链表中删除第i个元素 并打印
LinkDelect(L, 2);
LinkPrint(L);
LinkDelect(L, 5);
LinkPrint(L);
printf("\n");
//销毁单链表
LinkDestroy(L);
return 0;
}
如果文章有错误的地方,请帮忙指出进行改正,谢谢!??
栈:链栈和顺序栈的实现
https://blog.csdn.net/Mzyh_c/article/details/135180651?spm=1001.2014.3001.5501
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!