Faster Transformer
Faster Transformer
- FasterTransformer包含transformer块的高度优化版本的实现,该块包含编码器和解码器部分。
- 基于高效率的开发语言和工具: C++, CUDA, cuBLAS and cuBLASlt
- 支持的模型数据格式:FP32, FP16, BF16, INT8 (limited models) and FP8 (limited models)
- FasterTransformer提供了TensorFlow集成(使用TensorFlow op)和PyTorch集成(使用PyTorch op)。FasterTransformer还提供了Triton集成作为后端。
- 支持MGMN: Multi-GPU Multi-node服务
- 8bit量化:SmoothQuant (int8 weight only). (PTQ): less cost, lower accuracy
- 支持flash attention for long sequence on multi-head attention
- Optimization of fused mha and indirect k/v
FasterTransformer有两个部分:
- 第一个是用于将经过训练的Transformer模型转换为可用于分布式推理的优化格式
- 第二部分是用于在多个GPU上执行模型的后端
FT 适用于计算能力 >= 7.0 的 GPU,例如 V100、A10、A100 等。
支持的模型格式
Megatron-LM,GPT-3,GPT-J,BERT,ViT,Swin Transformer,Longformer,T5,XLNet等
faster transformer支持的格式
瓶颈
TransFormer的瓶颈
对于编码器-解码器架构,解码器占用了大部分时间(约90%),解码器是瓶颈。根据Amdahl的定律,优化解码器更为重要。
- 计算冗余:在Transformer的自注意力机制中,每个输入序列的每个元素都需要与其他所有元素进行交互,这导致了大量的冗余计算。
- 内存瓶颈:由于Transformer的自注意力机制,模型需要存储所有的中间状态,这在处理长序列时会导致内存瓶颈。
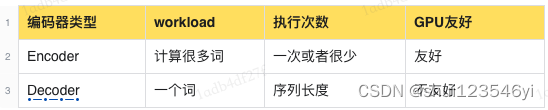
- “Kernels are too small” -> “Kernel launch bound"为 “内核太小” -> “内核启动受限”。这是指当CUDA内核的规模太小,无法充分利用GPU的并行处理能力,导致GPU的利用率不高,这种情况被称为"内核启动受限”。
整体优化思路
- 并行计算充分利用硬件设计特性
- 内存复用减少内存使用
- 减少重复计算
- 定位耗时的计算操作尝试优化
- 减少数据传输耗时
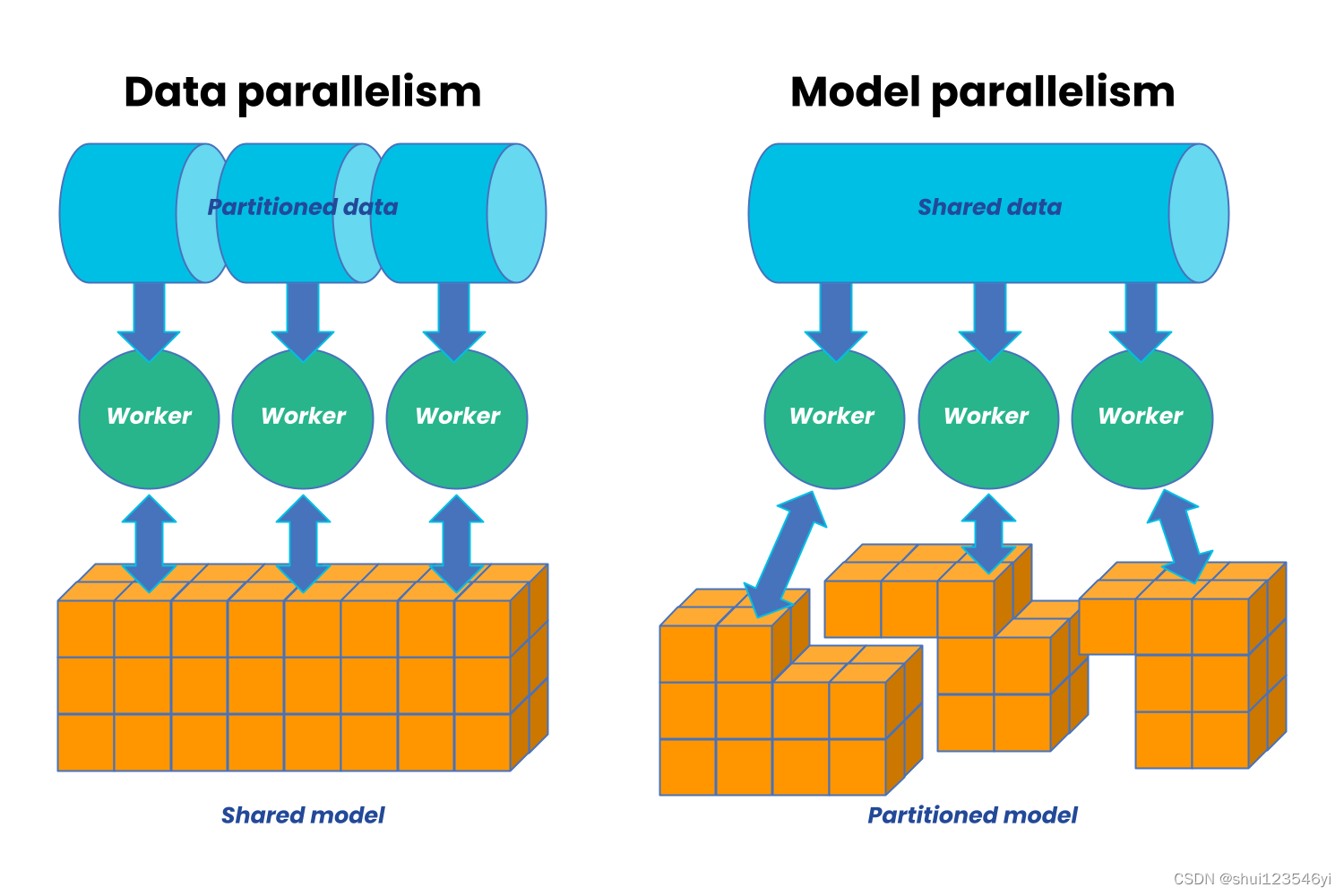
Parallelism
- Tensor (Intra-Layer) Parallelism
- Pipeline (Inter-Layer) Parallelism
Tensor parallelism(Intra-Layer)
每个tensor分割成多个子块后放到不同的GPU上运算。处理的过程中各个子块是分别单独并行处理的。最后再把多个结果结合。更多的数据交换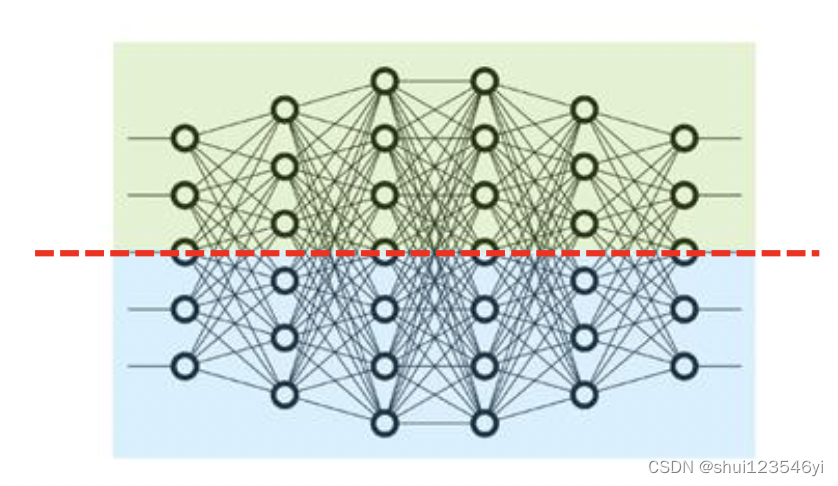
Pipeline parallelism(Inter-Layer)
一个模型的不同层分布在不同的GPU上。比较少的数据交换
FasterTransformer优化点
网络层融合
优化方案
尽可能多的融合除了GEMMs以外的所有kernels
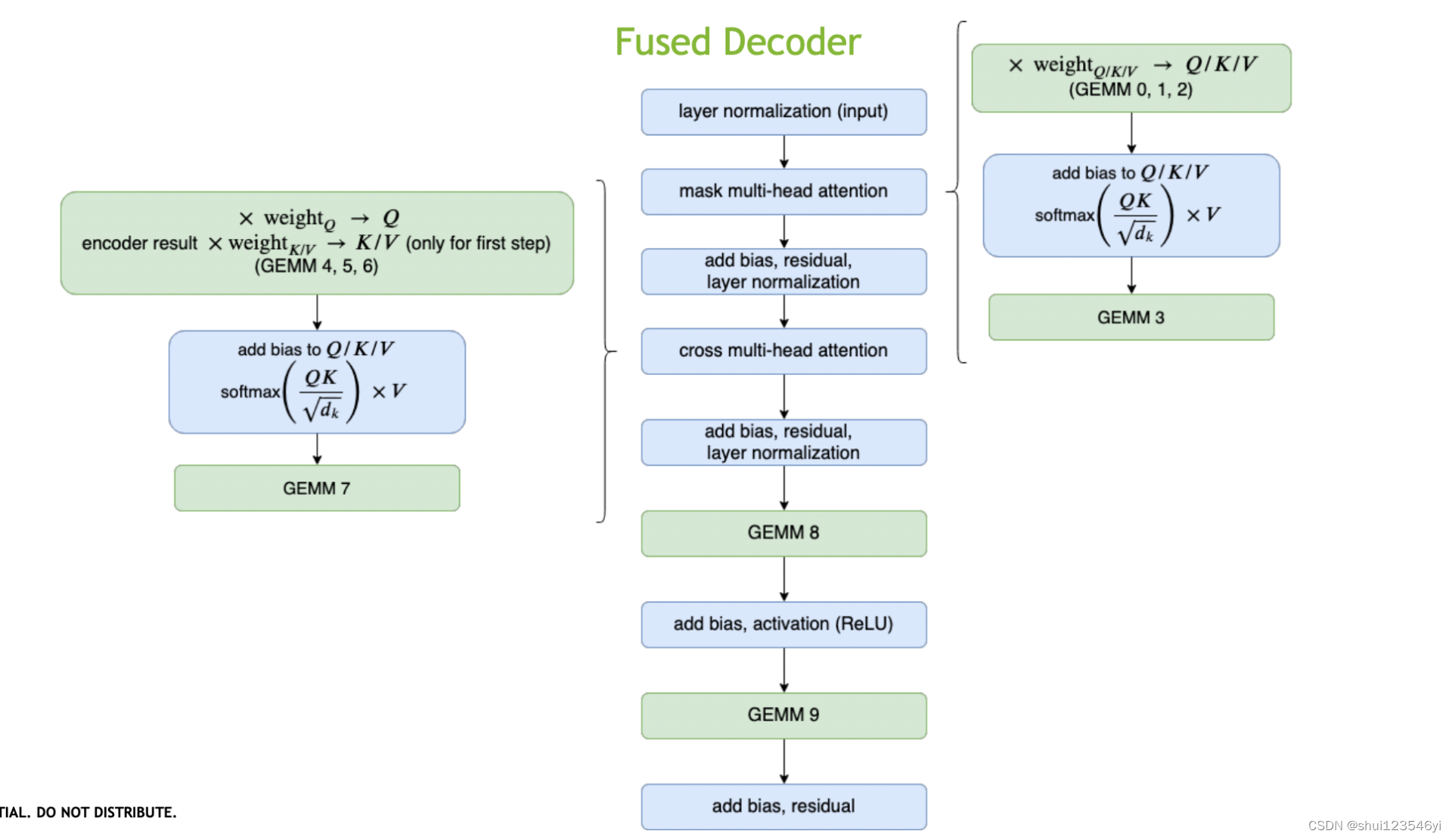
- 将multi-head attention合并为一个kernel(add bias, transpose, batch multiplication)
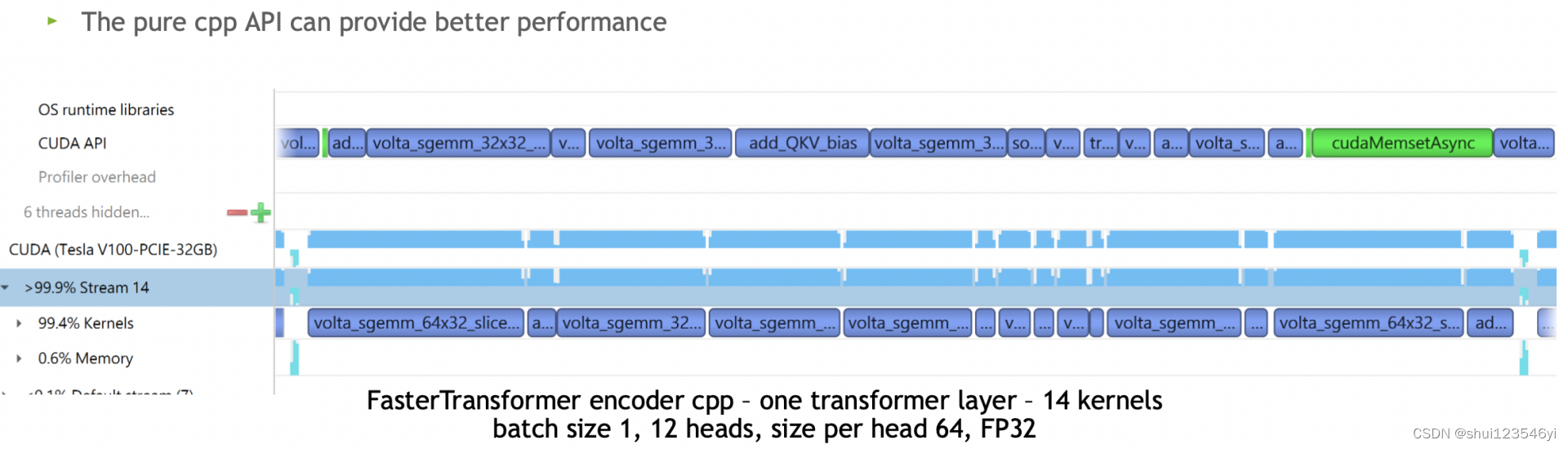
- 预处理阶段将多层神经网络融合成一个单独的神经网络,该网络将用一个单一的Kernel进行计算。这种技术减少了数据传输并增加了计算密度,从而加速了推理阶段的计算。例如,多头注意力块中的所有操作都可以组合到一个Kernel中。Faster Transformer将70个kernels压缩为16个kernels。
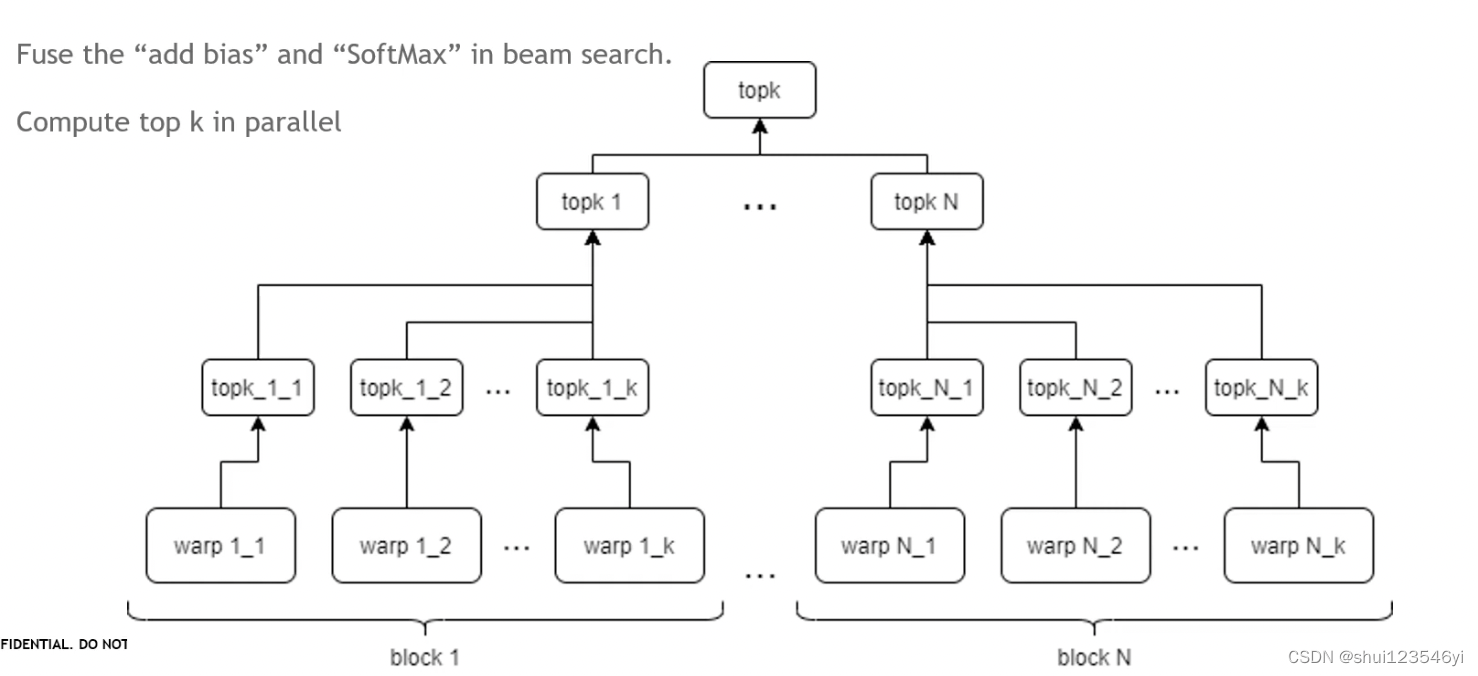
- 在beam search中融合“add bias”和“SoftMax”。
- 并行计算top k,在并行计算top-k的过程中,FasterTransformer首先将数据分割成多个小块,并在GPU的多个线程上并行处理这些小块。每个线程会计算其对应的小块中的top-k元素。然后,FasterTransformer会使用一个并行归约算法,将所有线程的结果合并起来,得到最终的top-k元素。这个并行归约算法是高效的,因为它可以充分利用GPU的并行处理能力。
自回归模型的推理优化/激活缓存
为了防止重新计算以前的Keys和Values,FT在每个步骤分配一个缓冲区来存储它们。尽管FT需要一些额外的内存使用,但它可以节省重新计算的成本、在每个步骤分配缓冲区的成本以及concatenation的成本。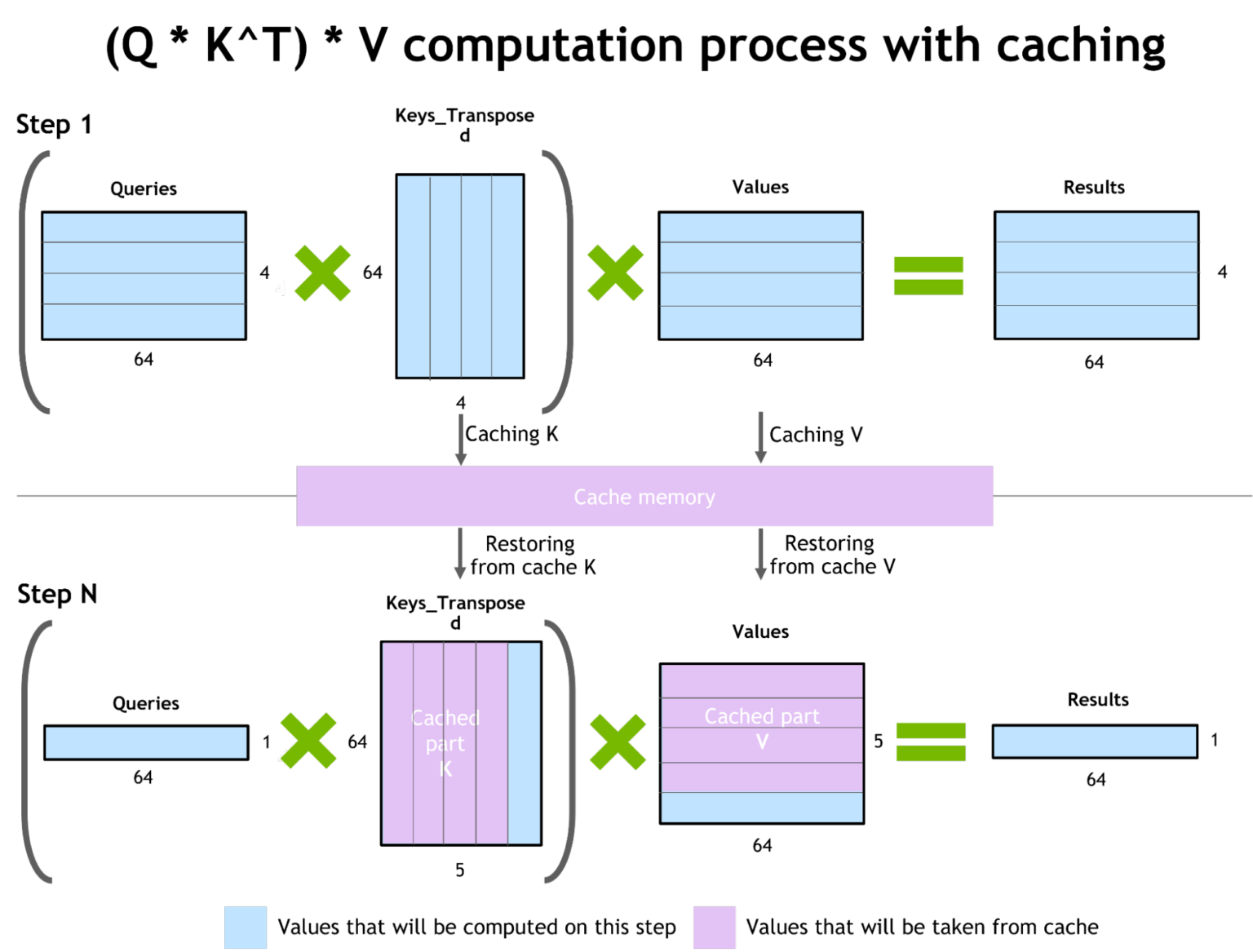
显存优化
大规模Transformer模型拥有多达数万亿个参数,占用数百GB的存储空间。GPT-3 175b模型采用半精度存储,也需要占用350GB的存储空间。为了降低其他部分的内存使用,在FasterTransformer中,可以通过在不同decoder层中重复使用激活/输出的内存缓冲区来减少内存使用。具体来说,当我们在解码器的每一层中进行前向传播时,我们需要存储每一层的激活(或输出)。在传统的实现中,每一层都会有自己的内存缓冲区来存储这些激活。而在Faster Transformer中,只使用一个内存缓冲区,并在每一层之间重用它。这是通过在每一层完成前向传播后,立即释放这些激活,从而为下一层的激活腾出空间来实现的。这样,我们就可以在不同的层之间重用同一个内存缓冲区,而不需要为每一层都分配新的内存。
这种方法的一个关键前提是,我们在完成前向传播后不再需要这些激活。这通常是在使用Transformer模型进行推理(而不是训练)时才成立的,因为在推理过程中,我们通常不需要进行反向传播。例如:GPT-3中包含96个解码器层,因此只需要原来1/96的内存量来存储激活。
使用MPI and NCCL支持model prallelism
FasterTransormer 同时提供tensor parallelism和pipeline parallelism. 节点间/节点内通信依赖于MPI和NVIDIA NCCL
tensor parallelism:FasterTransformer 按照 Megatron的思路对self-attention block和feed-forward network并行改造,。基于矩阵乘法的性质,FT按行拆分第一矩阵的权重,按列拆分第二矩阵的权重,分配给一个不同的处理器进行计算。这样,每个处理器只需要处理一部分的数据,从而实现并行计算。
在Transformer模型中,"reduction operation"通常指的是在多头自注意力(Multi-head Self-Attention)部分中,将不同头的输出合并(或者说“减少”)为一个单一的输出。这个过程通常涉及到一些矩阵运算,如矩阵乘法和加法。
在原始的Transformer模型中,每个Transformer块可能需要进行多次这样的减少操作。但在FasterTransformer(FT)中,通过优化,每个Transformer块的减少操作可以减少到两次。这是通过在计算过程中重用一些中间结果,以及优化矩阵运算的方式来实现的。
对于pipeline parallelism,是通过将整个批次的请求分割成多个micro-batch来实现的。减少了不必要的等待数据传输的空闲时间。我们可以在多个处理器上并行处理这些微批次。当一个处理器完成一个微批次的处理后,它可以立即开始处理下一个微批次,而不需要等待其他处理器。这样,我们可以最大限度地利用处理器的计算能力,而不会有空闲的时间。此外,FasterTransformer会根据不同的情况自动调整微批次的大小。
GEMM自动调优
矩阵乘法是基于Transformer的神经网络中的主要和最重的操作。FasterTransformer使用CuBLAS和CuTLASS库的功能来执行这些类型的操作。cuBLAS库中的GEMM函数可以自动根据输入矩阵的大小和形状,选择最优的算法来执行矩阵乘法。这种自动选择的过程就是GEMM的自动调优。
在Faster Transformer中,GEMM用于执行Transformer中的矩阵乘法操作,例如在自注意力机制中计算query、key和value,以及在前馈神经网络中计算权重和输入的乘积。GemmBatchedEx 函数实现的MatMul操作可以使用不同的低级算法在“硬件”级别以数十种不同的方式执行。此外,FT对网络的某些部分(如expf:单精度指数计算,shfl_xor_sync:CUDA 线程间的数据交换)使用硬件加速的low-level函数。
低精度推理
FT拥有支持使用fp16和int8低精度输入数据进行推理的Kernel。由于更少的数据传输量和所需的内存而达到加速的目的。int8和fp16计算可以在特殊的硬件上执行,例如张量核(对于从Volta开始的全部GPU体系架构)以及即将问世的Hopper GPU中的变换器引擎。
其他优化
快速的C++BeamSearch实现 Cumulative log probability for beam search
使用 half2 指令减少 FP16 中的内存读写次数;
使用精度较低但速度较快的函数,如将“expf”替换为“__expf”
支持一个模型的权重部分割给八个GPU
使用 __shfl_xor_sync 加速 reduced operations
GPU加速库介绍
1.cuBLAS:它是BLAS(基本线性代数子程序)库的GPU加速版本。cuBLAS提供高度优化的矩阵运算,如矩阵乘法和矩阵向量乘法,利用GPU的高并行性和高内存带宽。
2.cuBLASLt:它是cuBLAS的扩展,对矩阵运算提供了更细粒度的控制。它允许用户指定矩阵布局、数据类型和计算类型等属性,并可以自动为给定配置选择最佳算法。
3.cuSPARSELt:这是一个用于稀疏线性代数的GPU加速库。它为稀疏矩阵运算提供了优化的例程,这在许多科学和工程应用中很常见。这些库是CUDA工具包的一部分,旨在提供通用线性代数例程的高性能GPU加速实现。在大量使用线性代数的应用中,它们可以显著加快计算速度。
参考
https://github.com/NVIDIA/FasterTransformer
https://developer.nvidia.com/blog/accelerated-inference-for-large-transformer-models-using-nvidia-fastertransformer-and-nvidia-triton-inference-server/
Bo Yang Hsueh, NVIDIA
https://www.nvidia.com/en-us/search/?page=1&q=Bo%20Yang%20Hsueh&sort=relevance
https://developer.nvidia.com/zh-cn/blog/accelerated-inference-for-large-transformer-models-using-nvidia-fastertransformer-and-nvidia-triton-inference-server/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!