基于Docker-Compose实现ELK+Kafka搭建分布式日志采集系统
ELK+Kafka搭建日志采集系统
ELK概述
ELK是指Elasticsearch、Logstash和Kibana这三个主要的开源软件工具,它们通常一起被用于实时日志分析和数据可视化。另外,在日志采集系统中,ELK通常结合Kafkka一起使用。
1、Elasticsearch
Elasticsearch是一个开源的分布式搜索和分析引擎,基于Lucene库构建。它设计用于处理大规模数据集,能够快速地进行全文搜索、结构化搜索、分析和实时数据处理。Elasticsearch具有高可扩展性和高可靠性,可以自动处理数据的分片和复制,支持分布式搜索和聚合操作。
2.Logstash:
Logstash是一个开源的数据收集和处理引擎,用于将各种类型的数据(如日志、事件、度量等)从多个来源采集、处理和传输到Elasticsearch或其他存储和分析工具。Logstash支持多种数据输入源和输出目的地,可以进行数据转换、标准化、过滤和增强,使数据具备一致性和结构性。
3.Kibana:
Kibana是一个开源的数据可视化平台,用于在Elasticsearch上创建和共享实时的数据可视化仪表盘。它提供了丰富的图表、表格、地图和仪表盘等可视化组件,使用户能够以直观的方式探索和分析数据。Kibana还支持交互式查询和过滤,能够快速演示和共享数据的见解。
4.Kafka
Kafka是数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
搭建与配置
使用Docker Compose实现ELK(Elasticsearch、Logstash、Kibana)和Kafka日志采集
docker-compose.yml
创建docker-compose.yml文件,使用以下服务:
ZooKeeper:用于Kafka的依赖服务,监听在2181端口
Kafka:用于消息队列和日志采集,监听在9092端口,并连接到ZooKeeper
Elasticsearch:用于存储和索引日志数据,监听在9200端口
Logstash:用于从Kafka接收日志数据并转发到Elasticsearch
Kibana:用于可视化和检索日志数据,监听在5601端口,并连接到Elasticsearch
vim docker-compose.yml
version: '3.7'
services:
zookeeper:
image: zookeeper:3.8
container_name: zookeeper
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
restart: always
kafka:
image: bitnami/kafka:3.3.2
container_name: kafka1
hostname: kafka
volumes:
- ./kafka_data:/bitnami/kafka # 赋予kafka_data目前权限:chmod 777 kafka_data
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181 #kafka链接的zookeeper地址
KAFKA_ENABLE_KRAFT: no # 是否使用kraft,默认值:是,即Kafka替代Zookeeper
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092 # 定义kafka服务端socket监听端口,默认值:PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://192.168.30.30:9092 # 定义外网访问地址(宿主机ip地址和端口),默认值:PLAINTEXT://:9092
KAFKA_KRAFT_CLUSTER_ID: FDAF211E728140229F6FCDF4ADDC0B32 # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_BROKER_ID: 1 # broker.id,必须唯一
restart: always
elasticsearch:
image: elasticsearch:7.4.2
container_name: elasticsearch
hostname: elasticsearch
volumes:
- ./es_data:/usr/share/elasticsearch/data # 赋予es_data目前权限:chmod 777 es_data
restart: always
environment:
- "discovery.type=single-node"
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- "9200:9200"
logstash:
image: logstash:7.4.2
container_name: logstash
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
- ./logstash.yml:/usr/share/logstash/config/logstash.yml
depends_on:
- elasticsearch
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms128m"
ELASTICSEARCH_HOST: "http://192.168.30.30:9200"
kibana:
image: kibana:7.4.2
restart: always
container_name: kibana1
ports:
- 5601:5601
environment:
ELASTICSEARCH_URL: "http://192.168.30.30:9200"
depends_on:
- elasticsearch
配置日志采集规则
创建kafka的数据存储目录,并赋予目前权限:
chmod 777 kafka_data
创建ES的数据存储目录,并赋予目前权限:
chmod 777 es_data
创建logstash.yml配置文件,修改ES连接地址
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.30.30:9200" ]
创建logstash.conf配置文件,定义日志采集规则
input {
kafka {
bootstrap_servers => "192.168.30.30:9092"
topics => "user_logs"
}
}
filter {
}
output {
elasticsearch {
hosts => "192.168.30.30:9200"
index => "user_logs"
}
}
启动服务
在docker-compose.yml文件目录,运行以下命令来启动服务:
docker-compose up -d
所有容器都启动完毕后,可以通过访问http://192.168.30.30:5601/来访问Kibana,开始对日志数据进行可视化和查询分析
模拟发送日志消息
创建一个日志发送队列,配合线程,从队列中获取日志内容,然后以异步的形式发送消息到MQ
日志发送队列
@Component
public class LogDeque {
/**
* 本地队列
*/
private static LinkedBlockingDeque<String> logMsgs = new LinkedBlockingDeque<>();
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
public void log(String msg) {
logMsgs.offer(msg);
}
public LogDeque() {
new LogThread().start();
}
/**
* 创建线程,从队列中获取日志内容,然后以异步的形式发送消息到MQ
*/
class LogThread extends Thread {
@Override
public void run() {
while (true) {
String msgLog = logMsgs.poll();
if (!StringUtils.isEmpty(msgLog)) {
// 发送消息
kafkaTemplate.send("user_logs", msgLog);
}
// 避免cpu飙高的问题
try {
Thread.sleep(200);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
日志切面
@Aspect
@Component
@Slf4j
public class AopLogAspect {
@Autowired
private LogDeque logDeque;
/**
* 申明一个切点 execution表达式
*/
@Pointcut("execution(* cn.ybzy.demo.controller.*.*(..))")
private void logAspect() {
}
/**
* 请求method前打印内容
*
* @param joinPoint
*/
@Before(value = "logAspect()")
public void methodBefore(JoinPoint joinPoint) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
// 设置日期格式
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_ip", request.getRemoteAddr());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("request_args", Arrays.toString(joinPoint.getArgs()));
// 将日志信息投递到MQ
String logMsg = jsonObject.toJSONString();
log.info("<AOP日志 ===》 MQ投递消息:{}>", logMsg);
// 投递msg
logDeque.log(logMsg);
}
}
配置application.yaml
server:
port: 8888
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=true&serverTimezone=UTC
username: root
password: 123456
application:
# 服务的名称
name: elkk
jackson:
date-format: yyyy-MM-dd HH:mm:ss
kafka:
bootstrap-servers: 192.168.30.30:9092 # 指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group # 群组ID
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
发送日志消息
@Slf4j
@RestController
public class TestController {
@RequestMapping("/test")
public String test() {
return "OK";
}
}
Kibana的使用
要使用Kibana,需要通过配置一个或多个索引模式来告诉它你想探索的Elasticsearch索引,索引模式(index pattern)是kibana可视化的前提。它相当于告诉kibana要使用哪些索引作为数据进行可视化展示。
创建索引模式
一个索引模式标识一个或者多个你想要通过kiabna探索的Elasticsearch索引。Kibana会查找与指定模式匹配的索引名称。模式中的星号 (*) 匹配0个或者多个字符。
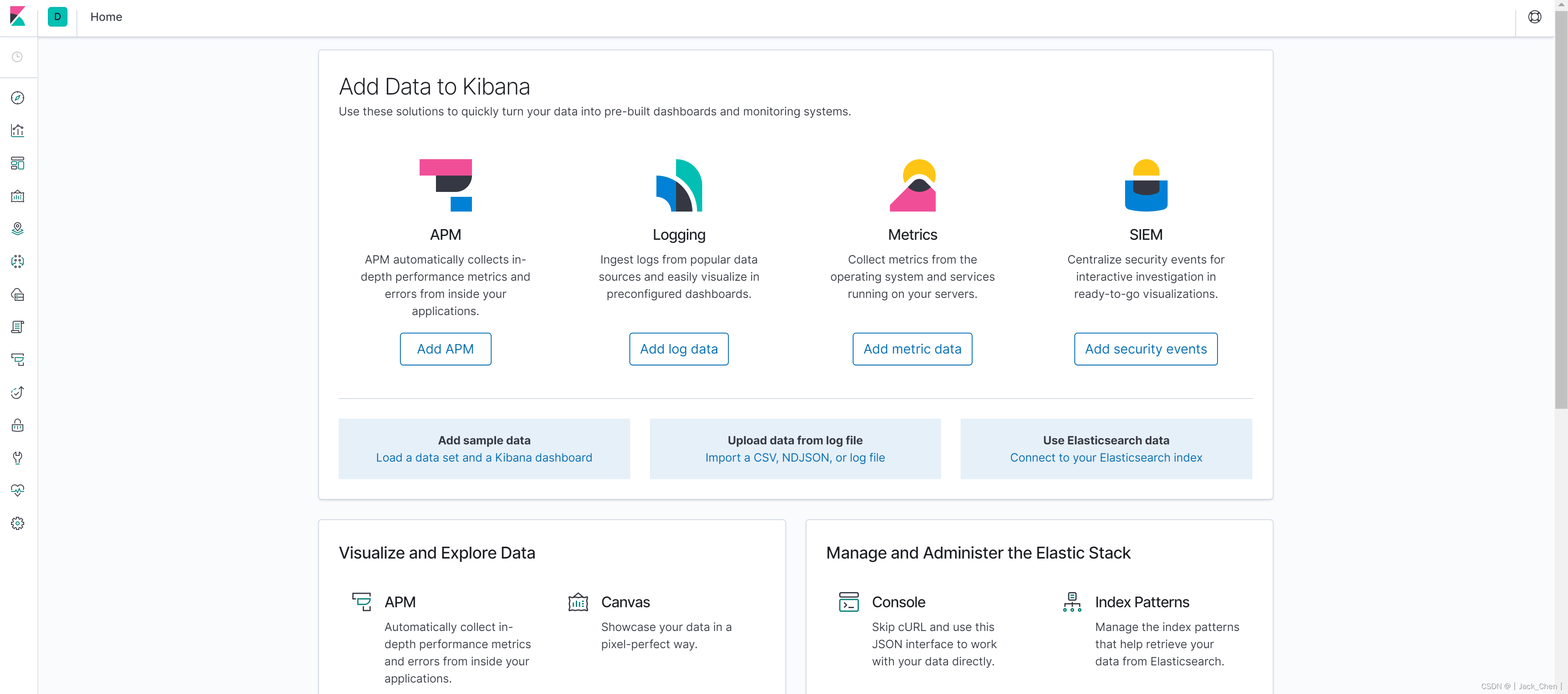
在左侧菜单找到management,然后点击index patterns --> create index pattern。通过输入index pattern的名称,kibana会自动显示匹配的索引,然后点击next
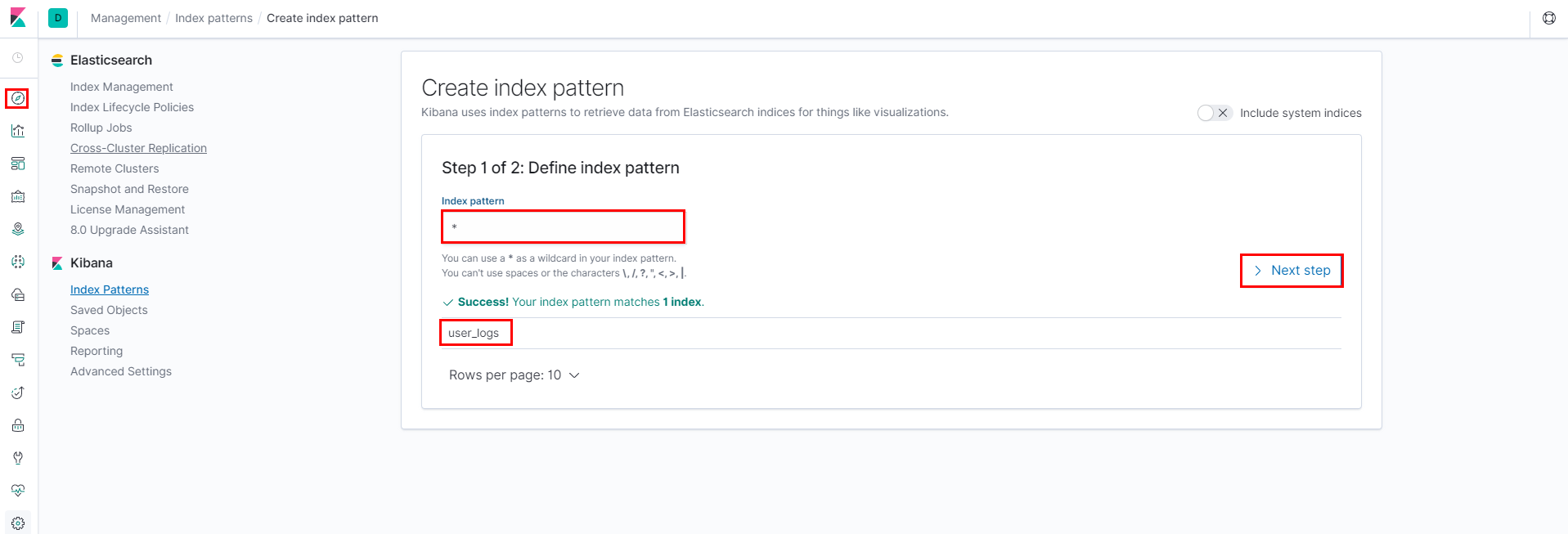
在配置设置Configure settings中, 选择索引中的时间维度的字段,这个时间字段是用来方便基于时间过滤数据用的。这里下拉菜单中选择
@timestamp,单击创建索引模式
Discovery搜索数据
点击Discovery,可以查看到日志相关数据,也可以进行日志搜索

可视化数据
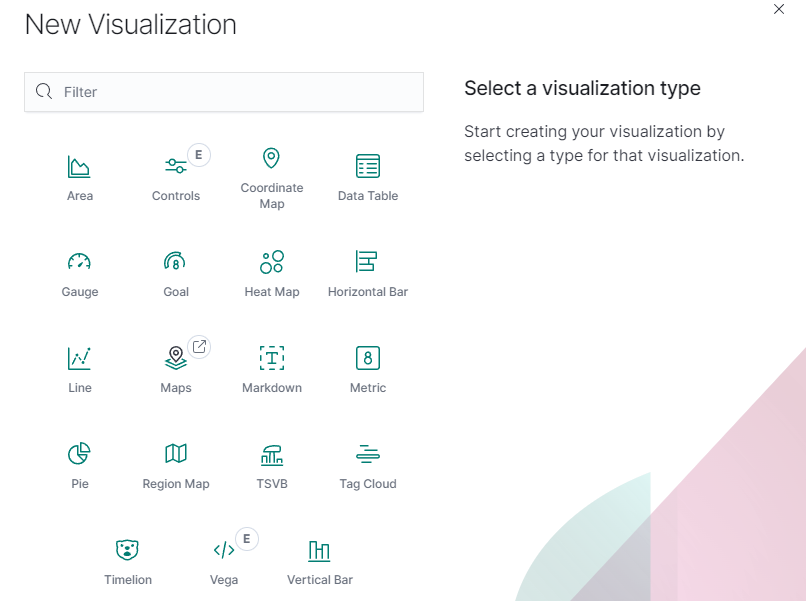
kibana自带了很多可视化的组件,方便对聚合后的结果进行可视化的展示。
左侧菜单选择Visualize,然后点击右边的+号
ELK+RabbitMQ
搭建ELK+Kafka日志采集系统后,同理可搭建ELK+RabbitMQ日志采集系统,他们实现方式类似,以下为参考:
发送日志消息
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void logs(String logMsg) {
for (int i = 0; i < 500000; i++) {
rabbitTemplate.convertAndSend("elk_logs_exchange", "user_logs",logMsg);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
配置日志采集规则
创建logstash.conf配置文件,定义日志采集规则
input {
rabbitmq {
host => "192.168.30.30:5672"
user => "work"
password => "12345678"
vhost => "/"
queue => "user_logs"
durable => true
exchange => "elk_logs_exchange"
key => "user.logs"
codec => "json"
}
}
output {
elasticsearch {
hosts => ["192.168.30.30:9200"]
index => "base_logs"
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!