【爬虫实战】2024可视化版—爬取微博任意关键词搜索结果、自动翻页、多线程
2024-01-01 11:43:08
大家好,应同学们私信要求,出一篇关于微博关键词搜索脚本可视化的案例,于是整理了一下,仅供学习参考。
项目功能简介:
1.可视化式配置;
2.任意关键词;
3.自动翻页;
4.支持指定最大翻页页码;
5.数据保存到csv文件;
6.程序支持打包成exe文件;
7.项目操作说明文档;
8.多线程并发(根据系统内核数、输入的线程数、关键词数量,计算出最合理的最终线程数);
9.支持爬虫暂停;
10.预留数据库配置,方便二次开发;
可视化版—2024爬取微博任意关键词、自动翻页、多线程
一.最终效果
参数校验:
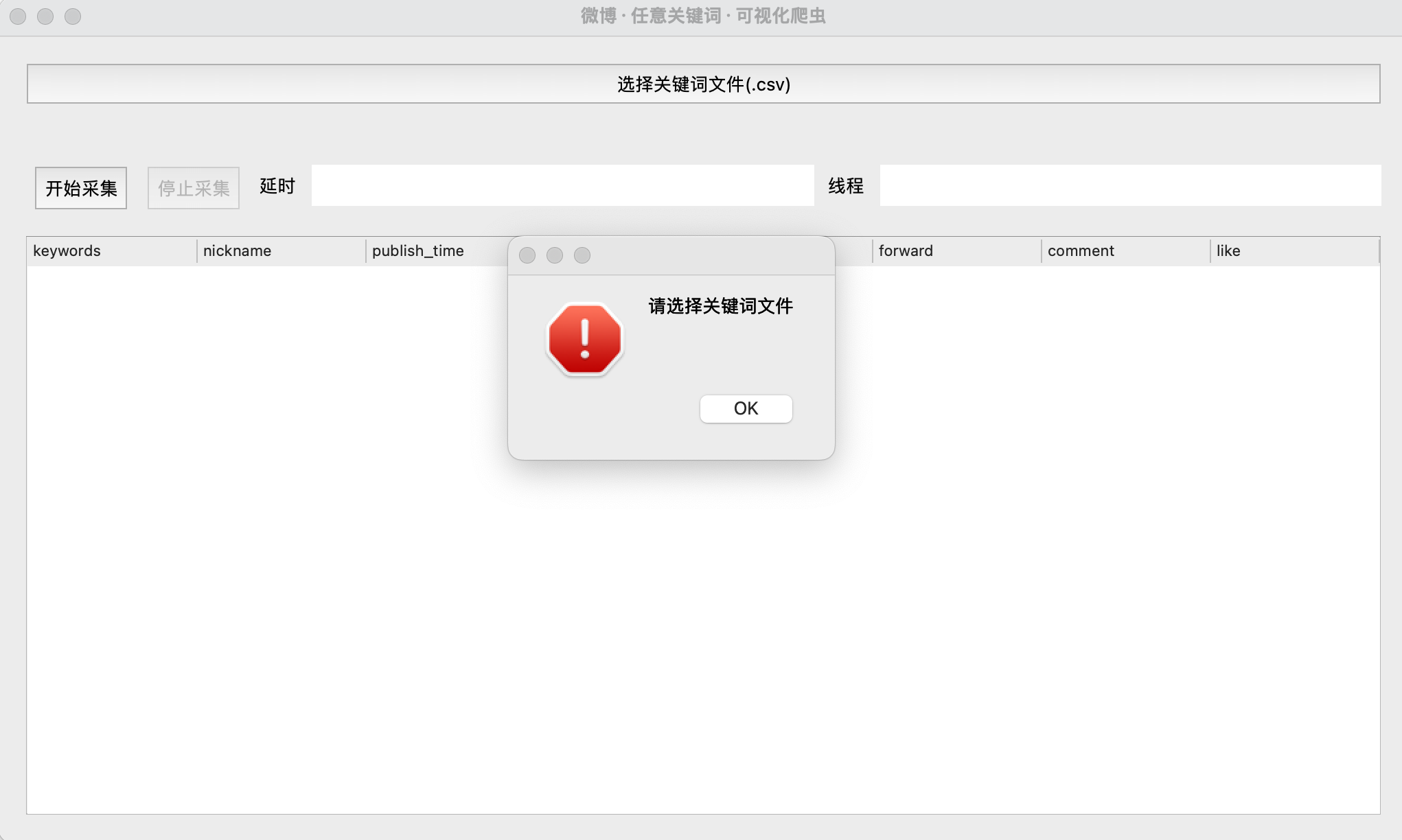
运行过程:
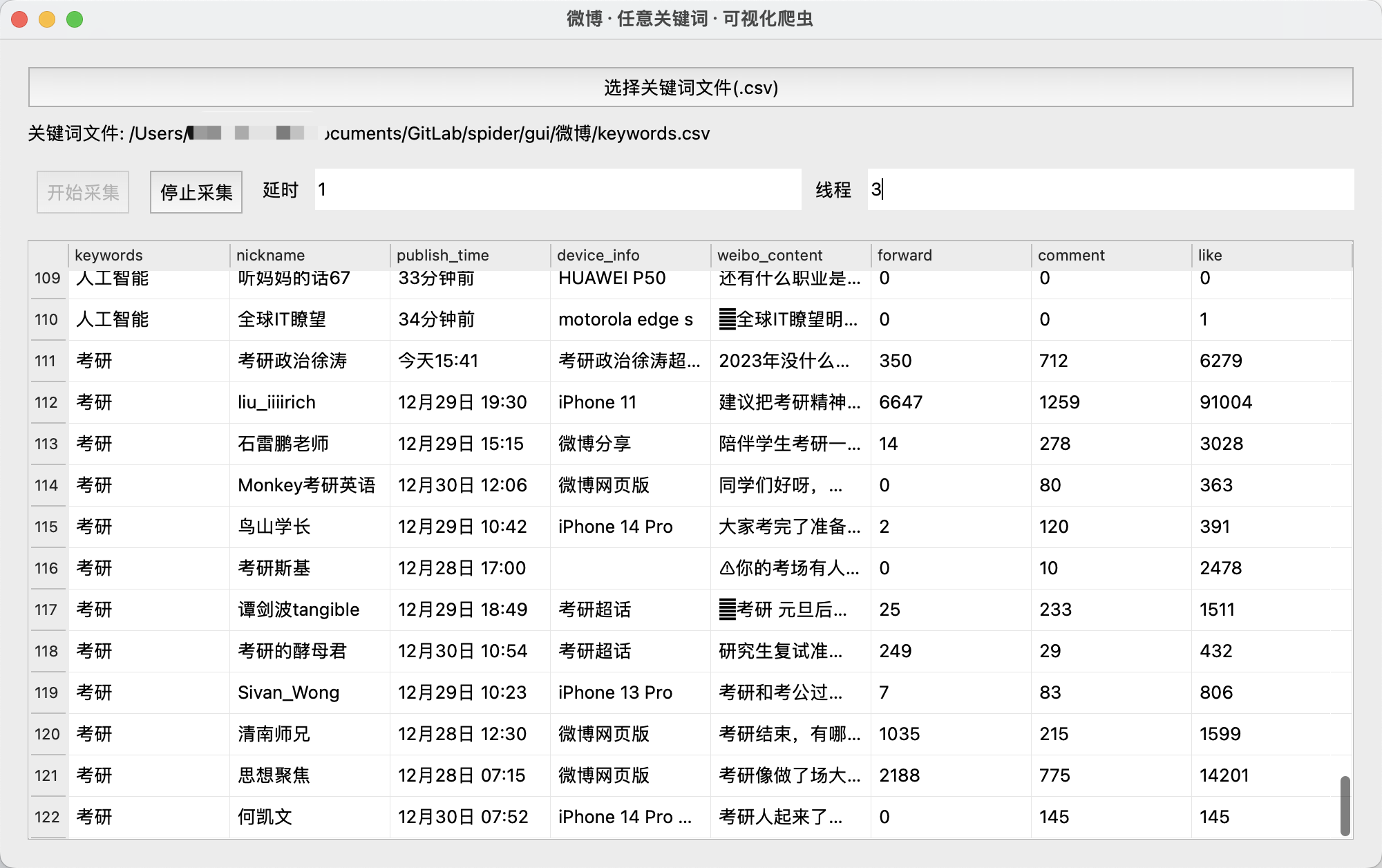
保存数据到csv:

二.项目代码
2.1 编写界面
该脚本的界面使用PyQt5库开发,经过测试这个库的运行时性能要优于Tkinter,特别是实在多数据数据表单滑动,Tkinter卡顿太严重,因此我们使用性能出色的PyQt5来实现,界面编写过程大致如下:
class MyForm(QWidget):
update_table_signal = pyqtSignal(dict)
def __init__(self):
super().__init__()
...
self.initUI()
def initUI(self):
# 设置窗口属性
self.setGeometry(100, 100, 1000, 600)
self.setWindowTitle('微博·任意关键词·可视化爬虫')
self.center_on_screen()
# 在垂直布局中添加第一排和第二排的水平布局
self.layout = QVBoxLayout()
self.fileButton = QPushButton('选择关键词文件(.csv)', self)
self.fileButton.clicked.connect(self.openFileDialog)
self.layout.addWidget(self.fileButton)
self.directoryLabel = QLabel(self) # 添加一个标签来显示用户选择的目录路径
self.layout.addWidget(self.directoryLabel)
# 第二排
self.layout_row2 = QHBoxLayout()
self.btn_start = QPushButton('开始采集')
self.btn_stop = QPushButton('停止采集')
self.btn_stop.setEnabled(False)
self.label_delay = QLabel('延时')
...
2.2 解析数据
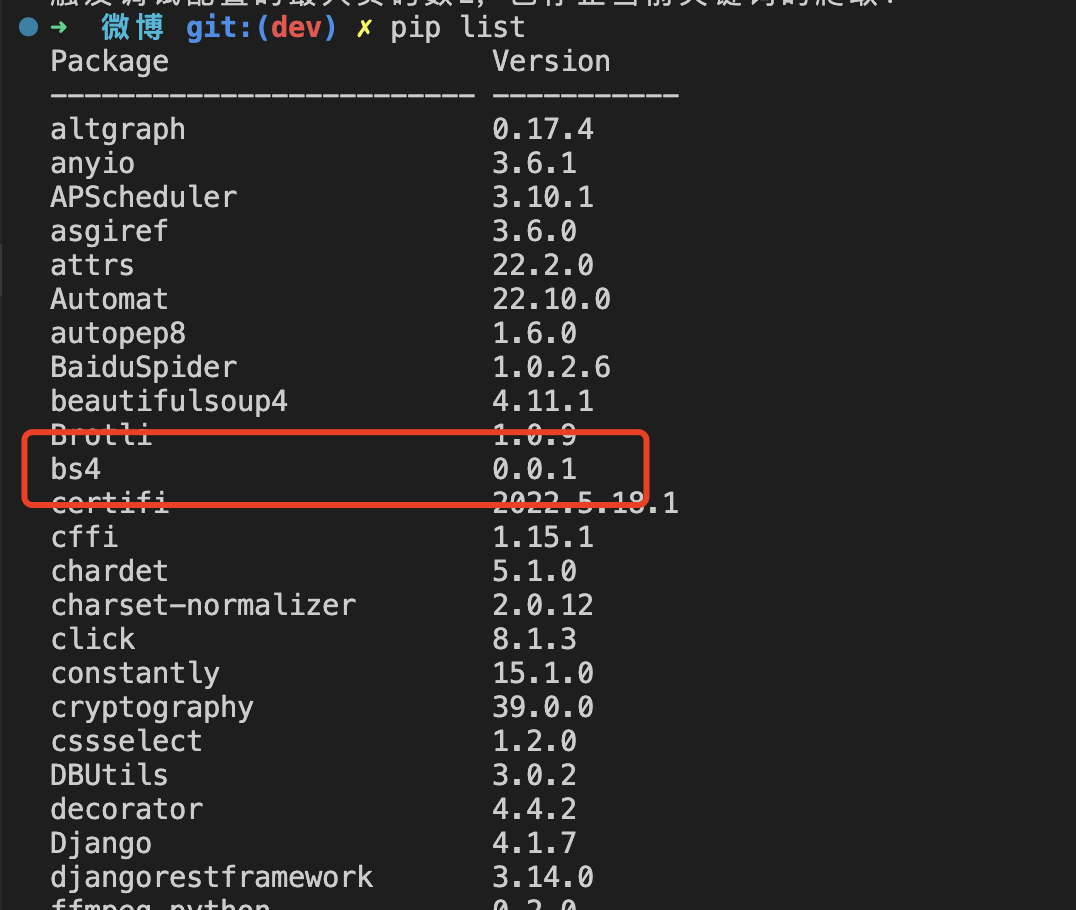
由于微博数据不是前后端分离,所以还是需要解析html,使用bs4库,使用前请确保已经安装成功: pip install bs4,查看本地是否已经安装: pip list,如下图:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
elements = soup.select('#pl_feedlist_index .card-wrap')
三.批量保存数据
数据保存继续使用pandas库,安装: pip install pandas,使用pandas批量保存,用法如下:
import pandas as pd
list = [
{
"keywords":"",
...
"like":"",
},{
"keywords":"",
...
"like":"",
}
]
df = pd.DataFrame(list)
df.to_csv('result.csv', index=False, columns=["keywords", "nickname", "publish_time", "device_info", "weibo_content", "forward", "comment", "like"])
四.运行日志
多线程日志:
开始请求第1页...
开始请求第1页...
开始解析第1页数据...
开始解析第1页数据...
数据保存中...
数据保存中...
共有50页:
共有50页:
开始请求第2页...
开始请求第2页...
开始解析第2页数据...
数据保存中...
开始解析第2页数据...
数据保存中...
开始请求第3页...
开始请求第3页...
开始解析第3页数据...
数据保存中...
触发调试配置的最大页码数3,已停止当前关键词的爬取!
开始解析第3页数据...
数据保存中...
触发调试配置的最大页码数3,已停止当前关键词的爬取!
五.项目说明文档
项目说明
安装 python3
到官网下载 python 3.8.x 版本安装包,根据提示安装(windows 请勾选添加环境变量复选框)
注意:
python是3.8.x,不能是3.9+(否则pyinstaller打包时可能报错)
本地运行
pip install pandas bs4 PyQt5
python3 main.py
开始打包
pyinstaller -F -w --name '微博·任意关键词·可视化爬虫' main.py (没有 main.spec 文件用此命令)
或者
pyinstaller main.spec (有 main.spec 文件可用此命令)
六.获取完整源码
本次案例的完整源码,已上传微信公众号:一个努力奔跑的snail,后台回复 微博可视化 即可获取。
文章来源:https://blog.csdn.net/li11_/article/details/135321047
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!