ElasticSearch使用Grafana监控服务状态-Docker版
版本信息
ElasticSearch:7.14.2
elasticsearch_exporter:1.7.0(latest)
Grafana:10.0.10
构建docker-compose.yml
创建并进入目录
mkdir /opt/docker-es-monitor
cd /opt/docker-es-monitor
创建配置文件
vim /opt/docker-es-monitor/docker-compose.yml
注意:配置文件中不能使用tab,需要是用空格
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
deploy:
resources:
limits:
cpus: '0.8' # cpus: '0.8'表示该服务的CPU使用限制为主机CPU的80%。这意味着,无论主机的CPU有多强大,该服务只能使用其80%的计算能力。
memory: 12G # memory: 12G表示该服务的内存使用限制为12GB。这意味着,该服务使用的内存不会超过12GB。
privileged: true # privileged: true是一个选项,它允许容器访问主机系统的所有设备,并允许容器中的进程获取几乎与主机系统相同的权限。在某些情况下,你可能需要容器具有更高的权限来执行特定的任务,例如直接操作网络设备或硬件,或者访问主机系统的特定文件。在这些情况下,你可以在Docker Compose文件中为特定的服务设置privileged: true。
ports: # ports字段用于定义容器的端口映射。格式为- <主机端口>:<容器端口>
- 9090:9090
volumes: # volumes字段用于定义容器的卷映射。格式为- <主机路径>:<容器路径>
- /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
depends_on: # depends_on字段用于定义服务的启动顺序,grafana服务会在当前服务之前启动
- grafana
environment:
- TZ=Asia/Shanghai # 设置服务的时区
grafana:
image: grafana/grafana:10.0.10-ubuntu
hostname: grafana
container_name: grafana
ports:
- 3000:3000
environment:
- TZ=Asia/Shanghai
elasticsearch_exporter:
image: quay.io/prometheuscommunity/elasticsearch-exporter:latest
command:
- '--es.uri=http://172.16.24.199:9200' # ElasticSearch集群地址
- '--es.all' # 通过es.uri获取全部节点状态,如果不设置,仅仅获取了配置的那个节点信息
- '--es.indices' # 查询集群中所有索引的统计信息
- '--es.indices_settings' # 查询集群中所有索引的设置统计信息
- '--es.indices_mappings' # 查询集群所有索引映射的统计信息
- '--es.shards' # 查询集群中所有索引的统计信息,包括分片级别的统计信息
- '--es.timeout=20s'
restart: always
ports:
- "172.16.24.224:9114:9114" # elasticsearch_exporter 对外提供的端口,通过该端口可以获取到监控信息,ip为部署docker的机器IP
参数说明
-
scrape_interval: 指定 Prometheus 抓取数据的时间间隔,默认为 15 秒。这意味着 Prometheus 每隔 15 秒抓取一次数据。 -
evaluation_interval: 指定规则评估的时间间隔,默认为 15 秒。这影响了 Prometheus 对规则的评估频率。 -
alertmanagers: 告警管理器配置,这里定义了一个静态的告警管理器的目标地址为10.0.0.101:9093。这是 Alertmanager 的地址,Prometheus 会将告警发送到这里。 -
rule_files: 规则文件的配置,这里指定了一个名为 “node_down.yml” 的规则文件。这个文件用于定义 Prometheus 告警的规则。 -
scrape_configs: 抓取配置的主要部分。Prometheus 通过这里的配置定期从目标服务抓取指标数据。- Job ‘prometheus’: 针对 Prometheus 本身的抓取配置,指定了抓取的目标为
10.0.0.101:9090。这个是用于监控 Prometheus 本身的指标。 - Job ‘node’: 针对节点的抓取配置,设置了较短的抓取间隔(8 秒)并指定了两个目标节点
10.0.0.101:9100和10.0.0.102:9100。这用于监控节点的指标。 - Job ‘cadvisor’: 针对 cAdvisor 的抓取配置,同样设置了较短的抓取间隔并指定了两个 cAdvisor 实例的目标地址。
- Job ‘prometheus’: 针对 Prometheus 本身的抓取配置,指定了抓取的目标为
创建Prometheus配置文件
vim /etc/prometheus/prometheus.yml
这个位置对应
docker-compse.ymlPrometheus配置文件挂载的目录
修改内容
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'prometheus' # prometheus默认的
static_configs:
- targets: ['172.16.24.224:9090']
- job_name: 'elasticsearch' # 监控ElasticSearch的job名称,自定义即可
scrape_interval: 60s
scrape_timeout: 30s
metrics_path: "/metrics" # 监控后缀
static_configs:
- targets: ['172.16.24.224:9114'] # 刚刚配置的elasticsearch_exporter监控地址
启动
docker-compose -f docker-compose.yml up -d
验证
访问Prometheus UI :http://172.16.24.224:9090 可以看到是否监控成功
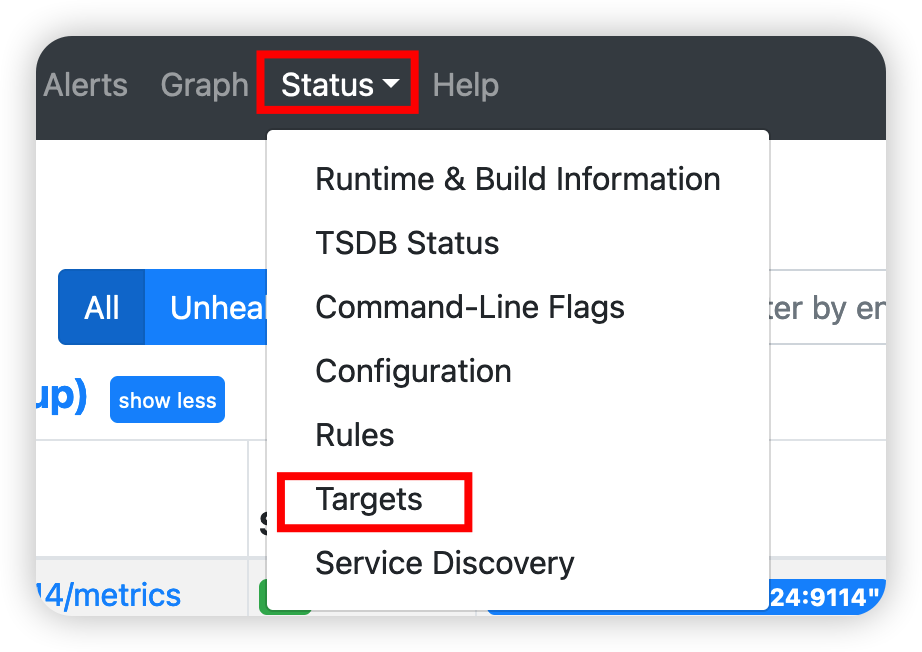
可以看到状态为UP,说明Prometheus监控到了ElasticSearch信息

配置Grafana
访问地址:http://172.16.24.224:3000 可以进入Grafana页面,默认账号密码:admin/admin
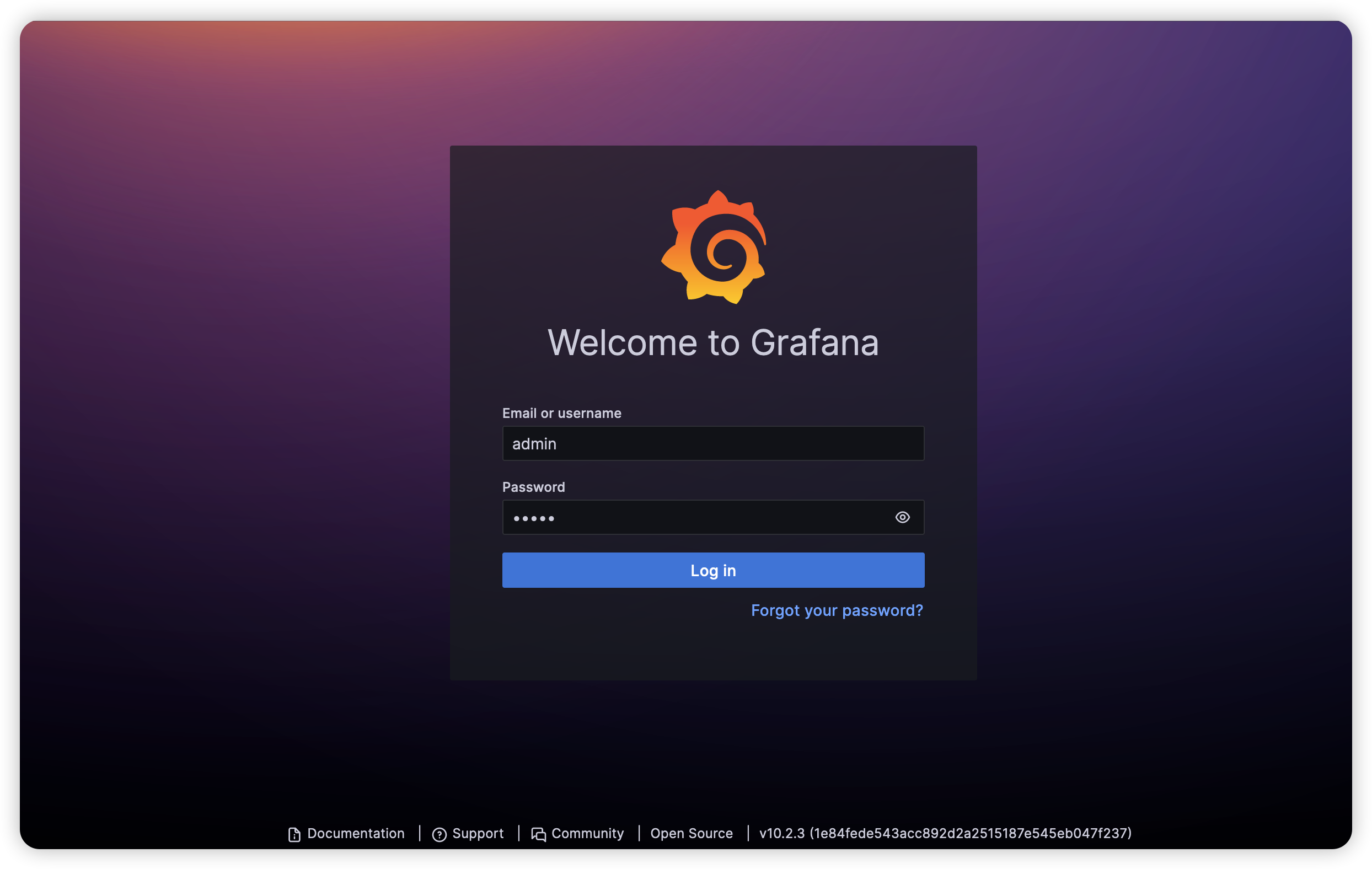
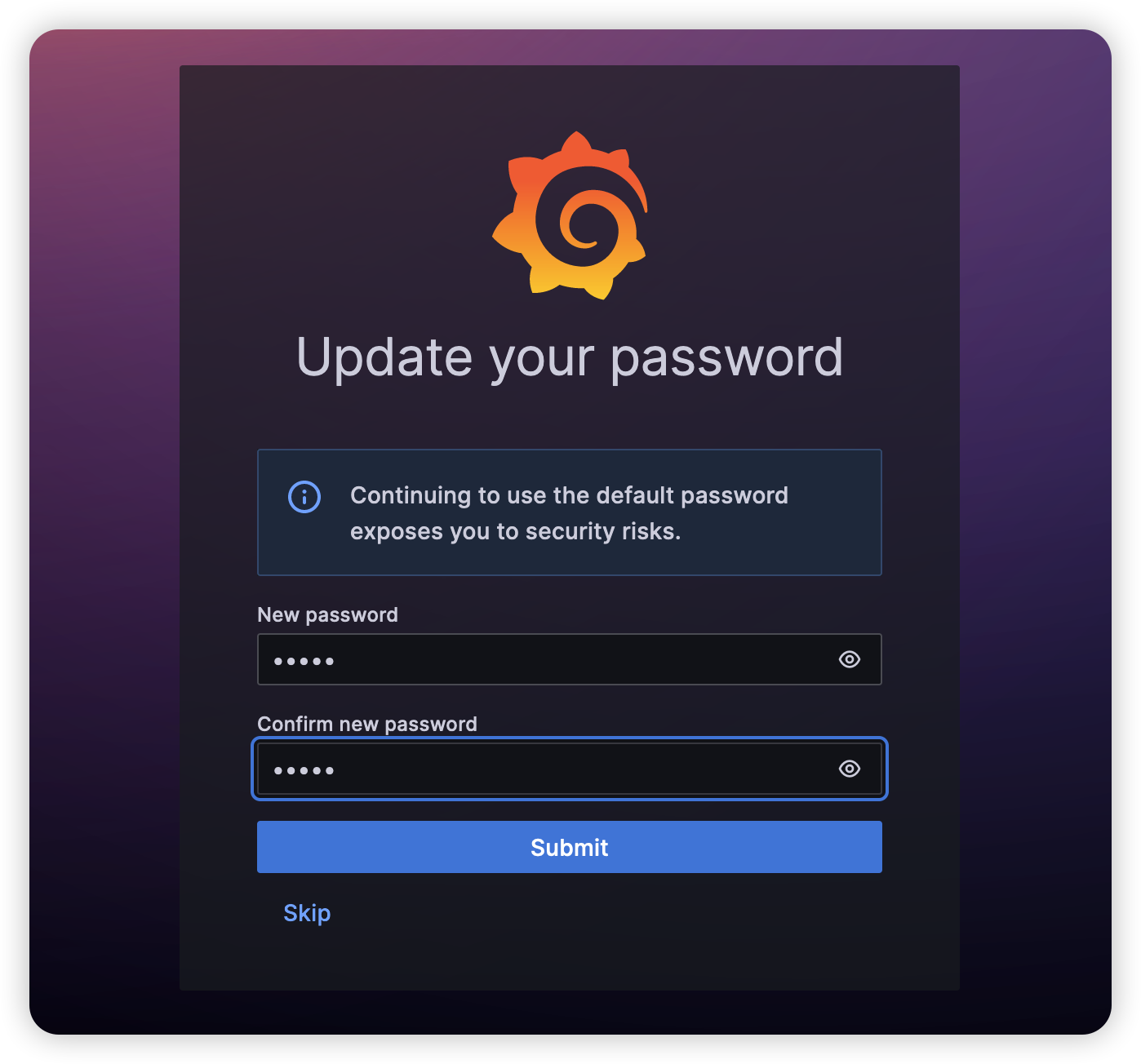
首次登录需要修改密码
创建数据源
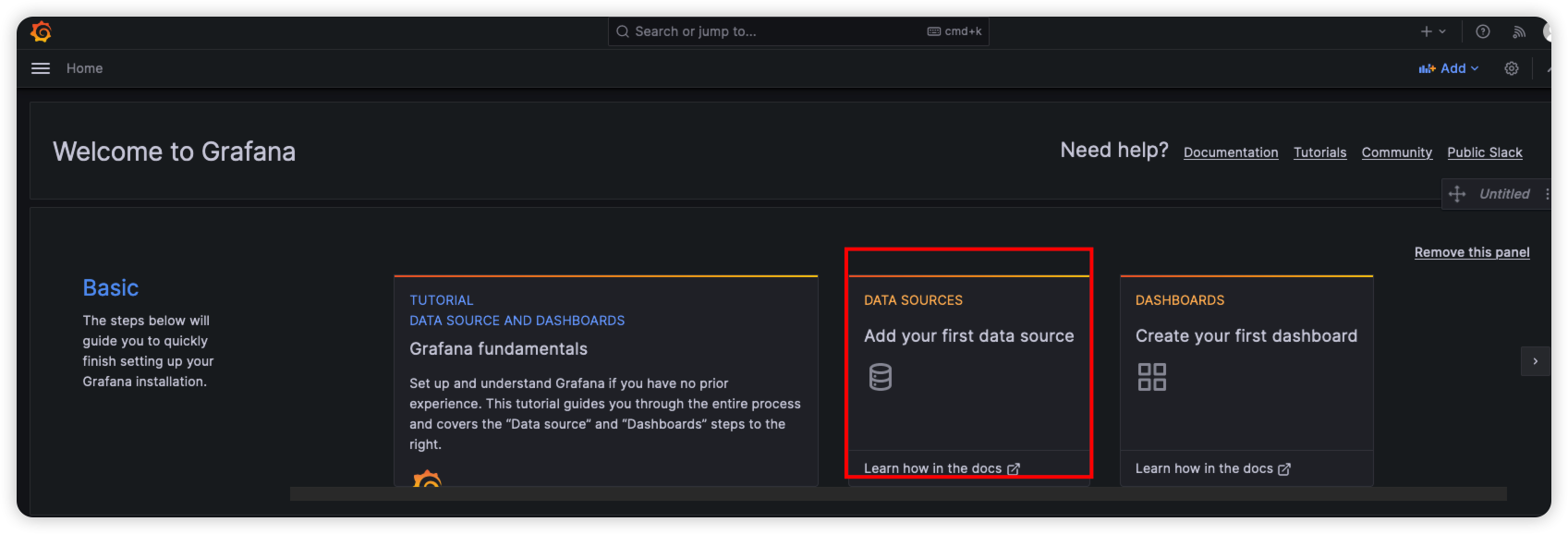
选择Prometheus
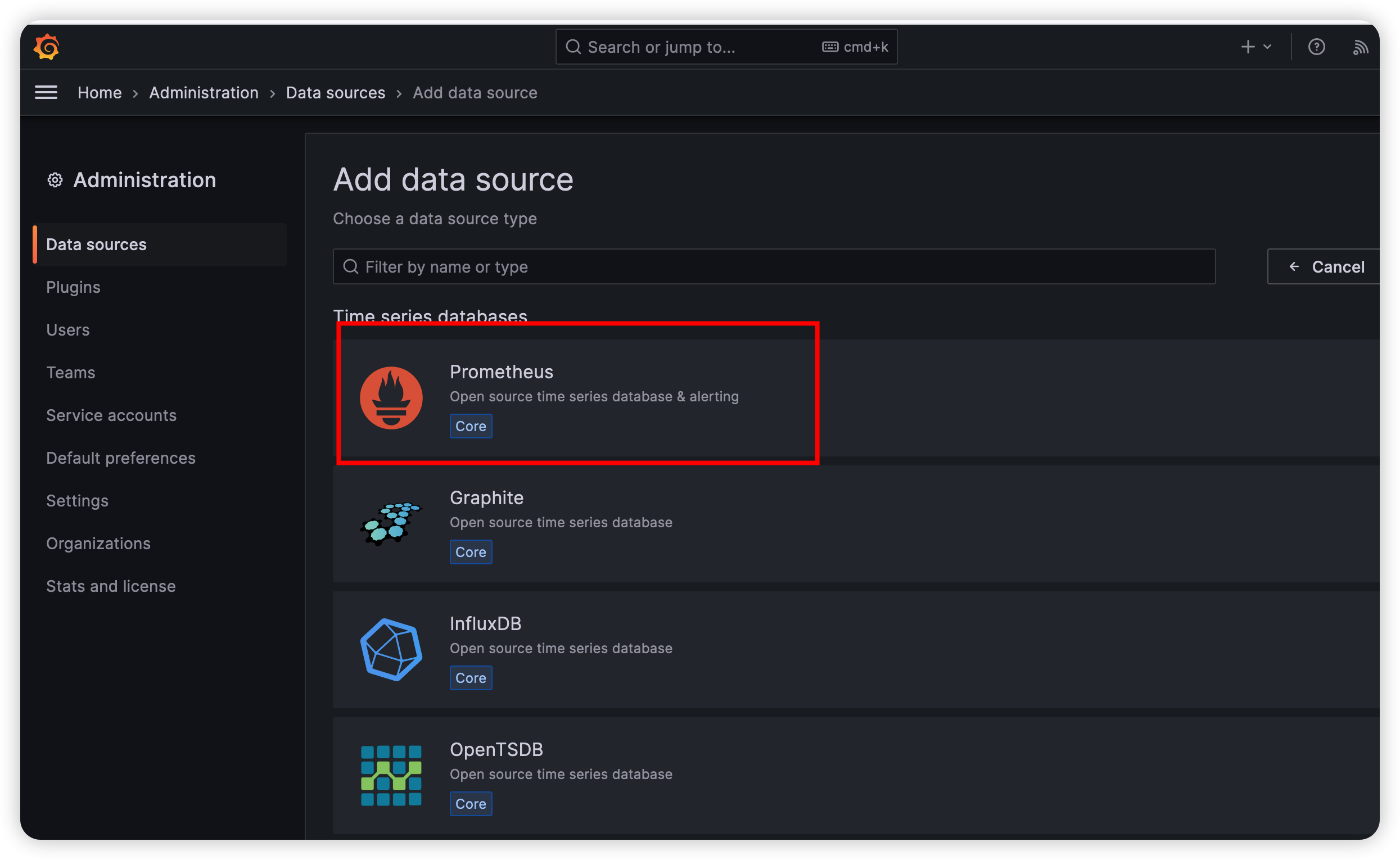
输入地址

点击保存
会提示成功

导入监控模板

模板说明
官方模板:编号为2322
推荐模板:
13071: Dashboard for Elasticsearch Cluster Stats
13072: Dashboard for Elasticsearch Index Stats
13073: Dashboard for Elasticsearch Node Stats
13074: Dashboard for Elasticsearch History Stats
这里我们使用推荐的模板,比较全
输入模板编号,并点击load
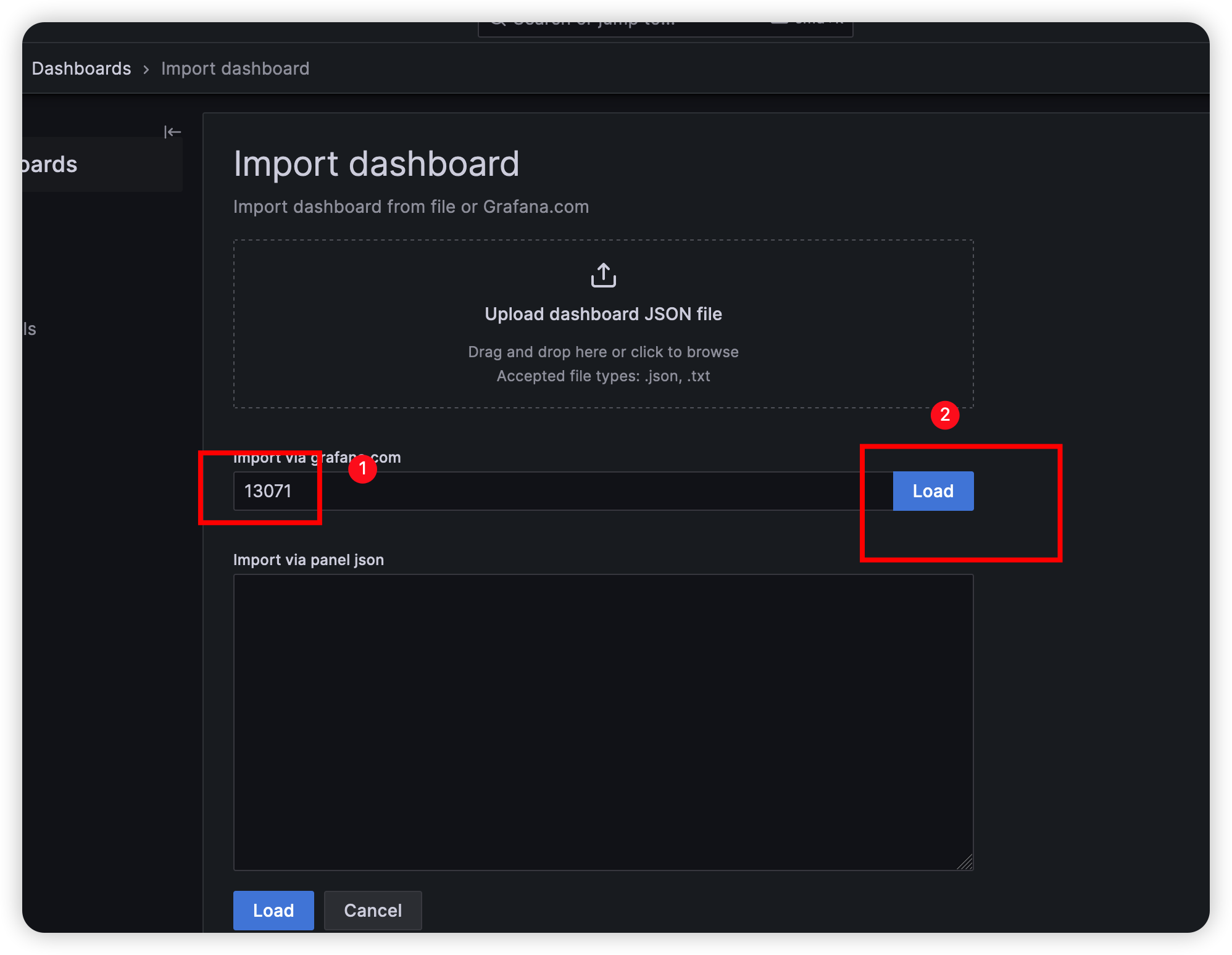
选择数据源,并点击Import

导入完成后可以看到监控信息
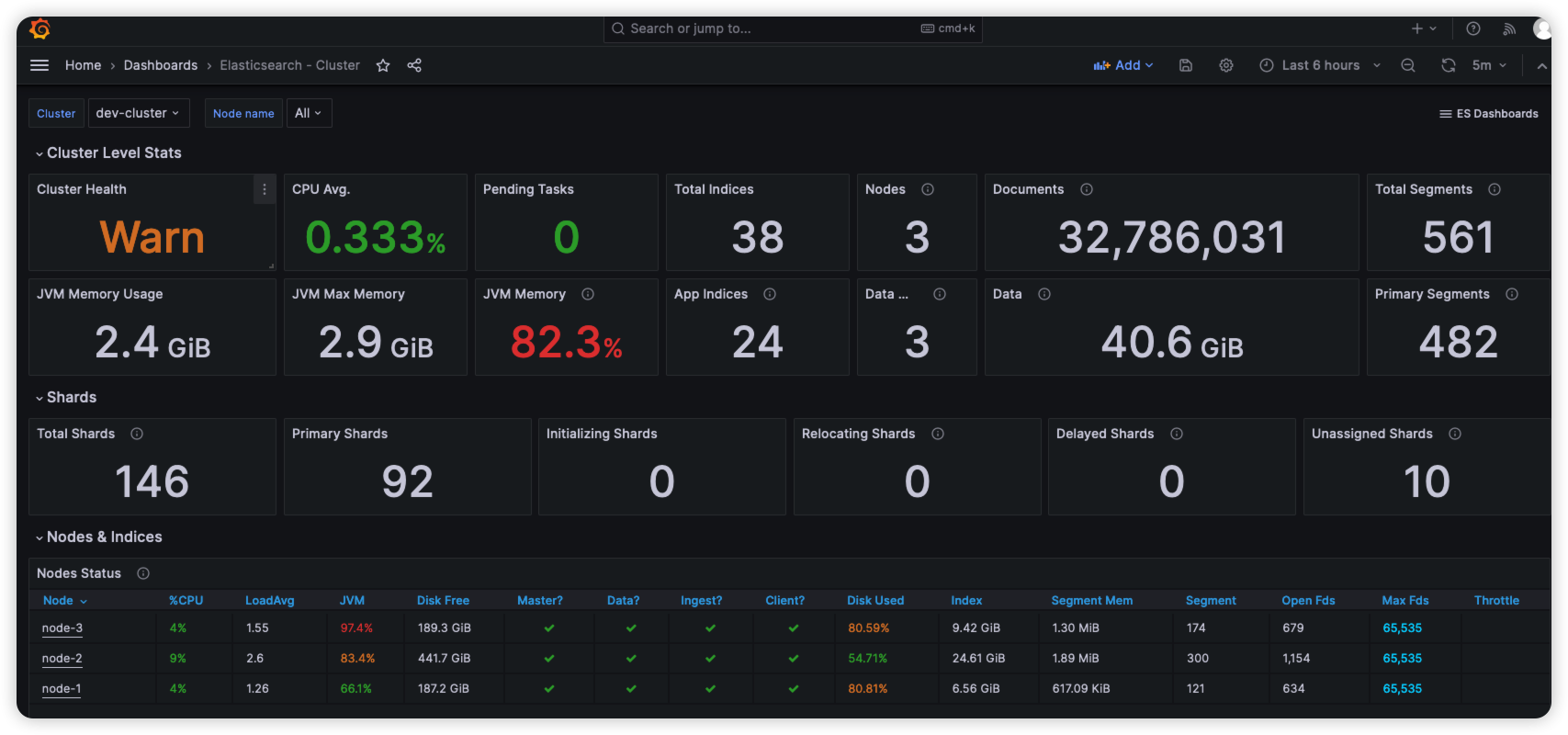
其他三个模板安装上面方式导入即可。
参考资料
参考:https://download.csdn.net/blog/column/12357358/131353971
官网说明:https://github.com/prometheus-community/elasticsearch_exporter
https://blog.csdn.net/u011487470/article/details/124302479
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!