【PostgreSQL】从零开始:(六)PostgreSQL-数据库目录文件结构及作用说明
数据库文件目录结构?
├── bin #系统工具目录
│?? ├── clusterdb
│?? ├── createdb
│?? ├── createuser
│?? ├── dropdb
│?? ├── dropuser
│?? ├── ecpg
│?? ├── initdb
│?? ├── pg_amcheck
│?? ├── pg_archivecleanup
│?? ├── pg_basebackup
│?? ├── pgbench
│?? ├── pg_checksums
│?? ├── pg_config
│?? ├── pg_controldata
│?? ├── pg_ctl
│?? ├── pg_dump
│?? ├── pg_dumpall
│?? ├── pg_isready
│?? ├── pg_receivewal
│?? ├── pg_recvlogical
│?? ├── pg_resetwal
│?? ├── pg_restore
│?? ├── pg_rewind
│?? ├── pg_test_fsync
│?? ├── pg_test_timing
│?? ├── pg_upgrade
│?? ├── pg_verifybackup
│?? ├── postgres
│?? ├── psql
│?? ├── reindexdb
│ └── vacuumdb
├── include #系统文件目录
├── lib #引用库目录
└── share #插件及配置文件
├── extension #存放插件目录
initdb
创建一个新的 PostgreSQL 数据库
initdb [option...] [ --pgdata | -D ] directory- 创建数据库集群包括创建集群数据所在的目录,生成共享目录表(属于整个集群而不是任何特定数据库的表) ,以及创建 postgres、 template1和 template0数据库。Postgres 数据库是一个默认的数据库,供用户、实用程序和第三方应用程序使用。Template1和 template0意味着作为源数据库,将由以后的 CREATEDATABASE 命令复制。Template0不应该被修改,但是您可以向 template1添加对象,默认情况下,这些对象将被复制到稍后创建的数据库中。
- 尽管 initdb 将尝试创建指定的数据目录,但是如果所需数据目录的父目录为 root 所有,它可能没有权限。要在这样的设置中进行初始化,请创建一个空的 data 目录作为 root 用户,然后使用 chown 将该目录的所有权分配给数据库用户帐户,然后使用 su 成为运行 initdb 的数据库用户。
- Initdb 必须作为拥有服务器进程的用户运行,因为服务器需要访问 initdb 创建的文件和目录。由于服务器不能以 root 身份运行,因此也不能以 root 身份运行 initdb。(它实际上将拒绝这么做。)
- 出于安全原因,在默认情况下,集群所有者只能访问 initdb 创建的新集群。Allow-group-access 选项允许与集群所有者在同一组中的任何用户读取集群中的文件。这对于作为非特权用户执行备份非常有用。
- Initdb 初始化数据库集群的默认语言环境和字符集编码。在创建每个数据库时,也可以为它们分别设置。Initdb 确定模板数据库的这些设置,这些设置将作为所有其他数据库的默认设置。
- 默认情况下,initdb 使用区域设置提供程序 libc 。Libc 区域设置提供程序从环境获取区域设置,并从区域设置确定编码。
- 若要为集群选择不同的区域设置,请使用选项--locale。还有一些单独的选项--lc-* 和--icu-locale (参见下面) ,用于设置各个区域设置类别的值。请注意,不同区域设置类别的不一致设置可能会产生无意义的结果,因此应谨慎使用。
- 或者,initdb 可以使用 ICU 库通过指定--locale-Provider = ICU 来提供区域设置服务。服务器必须建立与 ICU 的支持。要选择要应用的特定 ICU 区域设置 ID,请使用选项--ICU-locale。注意,出于实现原因和支持遗留代码,initdb 在使用 ICU 区域设置提供程序时仍将选择和初始化 libc 区域设置。
- 当 initdb 运行时,它将打印出它所选择的区域设置。如果您有复杂的需求或指定的多个选项,最好检查结果是否符合预期。
- 要更改默认编码,请使用--coding。
clusterdb
聚簇一个PostgreSQL数据库
clusterdb [connection-option...] [ --verbose | -v ] [ --table | -t table ] ... [dbname]
clusterdb [connection-option...] [ --verbose | -v ] --all | -a- clusterdb是一个工具,它用来对一个PostgreSQL数据库中的表进行重新聚簇。它会寻找之前已经被聚簇过的表,并且再次在最后使用过的同一个索引上对它们重新聚簇。没有被聚簇过的表将不会被影响。
- clusterdb是 SQL 命令CLUSTER
的一个包装器。在通过这个工具和其他方法访问服务器来聚簇数据库之间没有实质性的区别。
pg_controldata
显示 PostgreSQL 数据库簇控制信息.
pg_controldata [option...] [ -D | --pgdata ]datadirpg_controldata打印那些在initdb过程中初始化的信息, 比如表版本。它还显示有关预写日志和检查点处理相关的信息。这些信息是集群范围内有效的, 并不和某个数据库相关。- 这个命令只应该由安装服务器的用户运行,因为它要求对数据目录的读访问权限。 你可以在命令行上声明数据目录,或者使用
PGDATA环境变量。 这个工具支持-V和--version选项,可以打印 pg_controldata的版本然后退出。还支持?-?和--help选项,输出支持的参数。
pg_archivecleanup
?清理PostgreSQL?WAL归档文件
pg_archivecleanup [option...] archivelocation oldestkeptwalfile- pg_archivecleanup被设计来用作archive_cleanup_command, 在作为备用服务器运行时清理WAL文件归档。?pg_archivecleanup也可以用作一个单独的程序清理WAL文件归档。
要配置备用服务器使用pg_archivecleanup,将下列代码放入?recovery.conf配置文件中:
archive_cleanup_command = 'pg_archivecleanup archivelocation %r'
这里的archivelocation是应该被移除的WAL段文件的目录。
- 当在archive_cleanup_command
中使用时,所有逻辑上在%r?参数值之前的WAL文件都将从archivelocation中移除。 这在保存崩溃-重启能力时,最小化了需要保留的文件数量。 如果archivelocation是这个特殊的备用服务器的瞬态暂存区域, 那么使用这个参数是合适的,但是在archivelocation?用作长期WAL归档区,或者多个备用服务器是从同一个归档位置恢复而来的时, 是不合适的。 - 当用作独立程序时,所有逻辑上在oldestkeptwalfile?之前的WAL文件都将从archivelocation中移除。 在这个模式中,如果你声明一个.backup文件名, 那么只有文件前缀将被用作oldestkeptwalfile。 这允许你无误的删除所有在一个特定基础备份之前归档的WAL文件。
- 例如,下面的例子将删除所有比WAL文件名000000010000003700000010更老的文件:
pg_archivecleanup -d archive 000000010000003700000010.00000020.backup pg_archivecleanup: keep WAL file "archive/000000010000003700000010" and later pg_archivecleanup: removing file "archive/00000001000000370000000F" pg_archivecleanup: removing file "archive/00000001000000370000000E"
pg_archivecleanup假设archivelocation?是一个服务器所有者用户可读和可写的目录。
pg_test_fsync
PostgreSQL判断最快的?wal_sync_method
pg_test_fsync [option...]pg_test_fsync是想告诉你在特定的系统上,哪一种?wal_sync_method
最快,还可以在发生认定的 I/O 问题时提供诊断信息。不过,pg_test_fsync?显示的区别可能不会在真实的数据库吞吐量上产生显著的区别,特别是由于 很多数据库服务器被它们的预写日志限制了速度。?pg_test_fsync为?wal_sync_method报告以微秒计的平均文件同步操作时间, 也能被用来提示用于优化commit_delay
值的方法。
pg_test_timing
测量定时开销
pg_test_timing [ option ...]?pg_test_timing 是一种工具,用于测量系统上的计时开销,并确认系统时间永远不会向后移动。收集时序数据的系统较慢,可能会产生不太准确的EXPLAIN ANALYZE结果。
pg_upgrade?
升级服务器实例
pg_upgrade -b oldbindir [-B newbindir] -d oldconfigdir -D newconfigdir [option...]- pg_update (以前称为 pg _ Migator)允许将存储在 PostgreSQL 数据文件中的数据升级到稍后的 PostgreSQL 主版本,而不需要进行主版本升级所需的数据转储/恢复,例如从12.14升级到13.10或从14.9升级到15.5。对于较小的版本升级,例如,从12.7升级到12.8或从14.1升级到14.5,则不需要它。
- 主要的 PostgreSQL 版本定期添加新的特性,这些特性通常会改变系统表的布局,但是内部数据存储格式很少改变。pg_update 使用这个事实来执行快速升级,方法是创建新的系统表并简单地重用旧的用户数据文件。如果未来的主要版本改变了数据存储格式,使旧的数据格式变得不可读,pg_update 将不能用于这种升级。(社会人士会尽量避免出现这种情况。)
- pg_update 尽最大努力确保新旧集群是二进制兼容的,例如,通过检查兼容的编译时设置,包括32/64位二进制文件。任何外部模块都必须是二进制兼容的,尽管 pg_update 无法检查这一点。pg_update 支持从9.2.X 升级到 PostgreSQL 的当前主要版本,包括快照和 beta 版本。
pg_resetwal
重置 PostgreSQL 数据库集群的预写日志和其他控制信息
pg_resetwal [ -f | --force ] [ -n | --dry-run ] [option...] [ -D | --pgdata ]datadirpg_resetwal清除预写日志?WAL,并可选地重置pg_control文件中的一些其他控制信息。当?WAL?文件或?pg_control?控制文件损坏时,导致数据库无法启动时,该操作将作为数据库修复的最后手段使用。- 通过?
pg_resetwal?修复而启动数据库后,可能会由于部分提交的事务,导致数据库可能存在数据不一致的情况。所以,应该立即转储数据,建议重新初始化新的数据库恢复。恢复后再检查不一致,并根据需要进一步修复。 pg_resetwal只能由安装数据库用户运行,因为它需要对数据目录进行读/写访问。注意:考虑安全原因,pg_resetwal不使用环境变量 PGDATA,所以必须在命令行上指定数据目录。- 如果?
pg_resetwal 提示无法确定pg_control的有效数据,可以通过指定-f(force)选项强制继续执行。大多数字段可以自动匹配,但下一个OID、下一个事务ID和epoch、下一多事务ID和偏移量以及WAL起始位置字段值可能需要手动指定。可以使用一些选项设置这些字段值。如果无法确定这些字段的正确值,也可使用-f,但必须对恢复的数据库更为严谨的处理:必须立即转储和恢复。在转储之前,不要在数据库中执行任何数据修改操作,因为任何此类操作都可能会使损坏更严重。
createdb
创建一个新的PostgreSQL数据库
createdb [connection-option...] [option...] [dbname [description]]- 通常,执行这个命令的数据库用户将成为新数据库的所有者。但是,如果执行用户具有合适的权限,可以通过
-O选项指定一个不同的所有者。 - createdb是SQL命令CREATE DATABASE的一个包装器。在通过这个工具和其他方法访问服务器来创建数据库之间没有实质性的区别。
createuser
定义一个新的PostgreSQL用户账户
createuser [connection-option...] [option...] [username]- createuser创建一个新的PostgreSQL用户(或者更准确些,是一个角色)。只有超级用户和具有
CREATEROLE特权的用户才能创建新用户,因此createuser必须被以上两种用户调用。 - 如果你希望创建一个新的超级用户,你必须作为一个超级用户连接,而不仅仅是具有
CREATEROLE特权。作为一个超级用户意味着绕过数据库中所有访问权限检查的能力,因此超级用户访问权限不能轻易被授予。 - createuser是SQL命令CREATE ROLE的一个包装器。在通过这个工具和其他方法访问服务器来创建用户之间没有实质性的区别。
dropdb
移除一个PostgreSQL数据库
dropdb [connection-option...] [option...] dbname- dropdb毁掉一个现有的PostgreSQL数据库。执行这个命令的用户必须是一个数据库超级用户或该数据库的拥有者。
- dropdb是SQL命令?DROP DATABASE的一个包装器。 在通过这个工具和其他方法访问服务器来删除数据库之间没有实质性的区别。
dropuser
移除一个PostgreSQL用户账户
- dropuser移除一个已有的PostgreSQL用户。只有超级用户以及具有
CREATEROLE特权的用户能够移除PostgreSQL用户(要移除一个超级用户,你必须自己是一个超级用户)。 - dropuser是SQL命令?DROP ROLE的一个包装器。 在通过这个工具和其他方法访问服务器来删除用户之间没有实质性的区别。
ecpg
ecpg [option...] file...嵌入式 SQL C 预处理器
ecpg是用于 C 程序的嵌入式 SQL 预处理器。它通过将 SQL 调用替换为特殊函数调用把带有嵌入式 SQL 语句的 C 程序转换为普通 C 代码。输出文件可以被任何 C 编译器工具链处理。ecpg将把命令行中给出的每一个输入文件转换为相应的 C 输出文件。 如果输入文件名没有任何扩展名,则假定为.pgc。文件扩展名将由?.c替换以构造输出文件名。 但是输出文件名可以使用-o选项覆盖。- 如果输入文件名只是
-,ecpg从标准输入 读取程序(并写入标准输出,除非用-o重写)。
pg_amcheck
在一个或多个PostgreSQL数据库中检查损坏
pg_amcheck [option...] [dbname]- pg_amcheck支持对一个或多个数据库运行amcheck的损坏检查函数,并提供选项来选择要检查的模式、表和索引、要执行的检查类型以及是否并行执行检查,如果是,按并行数建立连接并使用。
- 当前仅支持表关系和btree索引。其他关系类型将自动跳过。
- 如果指定了
dbname,则它应该是要检查的单个数据库的名称,并且不应该存在其他数据库选择选项。否则,如果存在任何数据库选择选项,将检查所有匹配的数据库。如果不存在此类选项,将选中默认数据库。数据库选择选项包括--all,--database和--exclude-database。它们还包括--relation,--exclude-relation,?--table,--exclude-table,--index,和--exclude-index,但仅当这些选项与三段式模式一起使用时(例如,mydb*.myschema*.myrel*)。最后,它们包括--schema和--exclude-schema?当这些选项与两段式模式一起使用时(例如mydb*.myschema*)。 dbname也可以是一个链接字符串.
pg_basebackup
?获得一个PostgreSQL集簇的一个基础备份
pg_basebackup [option...]- ?pg_basebackup被用于获得一个正在运行的PostgreSQL数据库集簇的基础备份。获得这些备份不会影响数据库的其他客户端,并且可以被用于时间点恢复以及用作一个日志传送或流复制后备服务器的开始点。
- pg_basebackup对数据库群集的文件进行精确复制,同时确保服务器自动进入和退出备份模式。备份总是从整个数据库集簇获得,不可能备份单个数据库或数据库对象。关于选择性备份,必须使用一个像pg_dump的工具。
- 备份通过一个使用复制协议常规PostgreSQL连接制作。该连接必须由一个具有REPLICATION权限(或者具有超级用户权限的用户ID建立,并且pg_hba.conf必须允许该复制连接。该服务器还必须被配置,使max_wal_senders设置得足够高以提供至少一个walsender用于备份以及一个用于WAL流(如果使用流)。
- 在同一时间可以有多个pg_basebackup运行,但是从性能的角度来说,只进行一次备份并且复制结果通常更好。
- pg_basebackup不仅能从主控机也能从后备机创建一个基础备份。要从后备机获得一个备份,设置后备机让它能接受复制连接(也就是,设置max_wal_senders和hot_standby,并且适当配置其pg_hba.conf)。你将也需要在主控机上启用full_page_writes。
- 注意在来自后备机的备份中有一些限制:?
- 不会在被备份的数据库集簇中创建备份历史文件
- pg_basebackup不能强制备用服务器在备份结束时切换到新的WAL文件。 当正在使用-X none时,如果服务器上的写活动比较低,pg_basebackup可能需要等待很长时间,以便切换和归档备份所需要的最后的WAL文件。 在这种情况下,在主服务器上运行pg_switch_wal以触发立即的WAL文件切换可能是有用的。
- 如果在备份期间后备机被提升为主控机,备份会失败。
- 备份所需的所有 WAL 记录必须包含足够的全页写,这要求你在主控机上启用full_page_writes并且不使用一个类似pg_compresslog的工具以archive_command从 WAL 文件中移除全页写。
?每当pg_basebackup进行基本备份时,服务器的pg_stat_progress_basebackup视图将报告备份的进度。?
pgbench
在PostgreSQL上运行一个基准测试
pgbench -i [option...] [dbname]
pgbench [option...] [dbname]- pgbench是一种在PostgreSQL上运行基准测试的简单程序。它可能在并发的数据库会话中一遍一遍地运行相同序列的 SQL 命令,并且计算平均事务率(每秒的事务数)。默认情况下,pgbench会测试一种基于 TPC-B 但是要更宽松的场景,其中在每个事务中涉及五个
SELECT、UPDATE以及INSERT命令。但是,通过编写自己的事务脚本文件很容易用来测试其他情况。
pg_config
获取已安装的PostgreSQL的信息
pg_config [option...]- pg_config工具打印当前安装版本的PostgreSQL的配置参数。它的设计目的之一是便于想与PostgreSQL交互的软件包能够找到所需的头文件和库。
pg_dump
把PostgreSQL数据库抽取为一个脚本文件或其他归档文件
pg_dump [connection-option...] [option...] [dbname]- pg_dump是用于备份一种PostgreSQL数据库的工具。即使数据库正在被并发使用,它也能创建一致的备份。pg_dump不阻塞其他用户访问数据库(读取或写入)。
- pg_dump只转储单个数据库。要备份一个集簇或者集簇中 对于所有数据库公共的全局对象(例如角色和表空间),应使用?pg_dumpallpg_dumpallpg_dumpall。
- 转储可以被输出到脚本或归档文件格式。脚本转储是包含 SQL 命令的纯文本文件,它们可以用来重构数据库到它被转储时的状态。要从这样一个脚本恢复,将它喂给psql。脚本文件甚至可以被用来在其他机器和其他架构上重构数据库。在经过一些修改后,甚至可以在其他 SQL 数据库产品上重构数据库。
- 另一种可选的归档文件格式必须与pg_restorepg_restorepg_restore配合使用来重建数据库。它们允许pg_restore能选择恢复什么,或者甚至在恢复之前对条目重排序。归档文件格式被设计为在架构之间可移植。
- 当使用归档文件格式之一并与pg_restore组合时,pg_dump提供了一种灵活的归档和传输机制。pg_dump可以被用来备份整个数据库,然后pg_restore可以被用来检查归档并/或选择数据库的哪些部分要被恢复。最灵活的输出文件格式是“自定义”格式(
-Fc)和“目录”格式(-Fd)。它们允许选择和重排序所有已归档项、支持并行恢复并且默认是压缩的。“目录”格式是唯一一种支持并行转储的格式。 - 当运行pg_dump时,我们应该检查输出中有没有任何警告(打印在标准错误上),特别是考虑到下面列出的限制。
pg_dumpall
将一个PostgreSQL数据库集簇抽取到一个脚本文件中
pg_dumpall [connection-option...] [option...]- pg_dumpall工具可以一个集簇中所有的PostgreSQL数据库写出到(“转储”)一个脚本文件。该脚本文件包含可以用psql的输入SQL命令来恢复数据库。它会对集簇中的每个数据库调用pg_dump来完成该工作。pg_dumpall还转储对所有数据库公用的全局对象(pg_dump不保存这些对象),也就是说数据库角色和表空间都会被转储。 目前这包括适数据库用户和组、表空间以及适合所有数据库的访问权限等属性。
- 因为pg_dumpall从所有数据库中读取表,所以你很可能需要以一个数据库超级用户的身份连接以便生成完整的转储。同样,你也需要超级用户特权执行保存下来的脚本,这样才能增加角色和组以及创建数据库。
- SQL 脚本将被写出到标准输出。使用?
-f/--file?选项或者 shell 操作符可以把它重定向到一个文件。 - pg_dumpall需要多次连接到PostgreSQL服务器(每个数据库一次)。如果你使用口令认证,可能每次都会要求口令。这种情况下使用一个
~/.pgpass会比较方便。
pg_isready
?检查一个PostgreSQL服务器的连接状态
pg_isready [connection-option...] [option...]- pg_isready是一个用来检查一个PostgreSQL数据库服务器的连接状态的工具。其退出状态指定了连接检查的结果。
pg_receivewal
以流的方式从一个PostgreSQL服务器得到预写式日志
pg_receivewal [option...]- pg_receivewal被用来从一个运行着的PostgreSQL集簇以流的方式得到预写式日志。预写式日志会被使用流复制协议以流的方式传送,并且被写入到文件的一个本地目录。这个目录可以被用作归档位置来做一次使用时间点恢复的恢复(见第?26.3?节)。
- 当预写式日志在服务器上被产生时,pg_receivewal实时以流的方式传输预写式日志,并且不像archive_command那样等待段完成。由于这个原因,在使用pg_receivewal时不必设置archive_timeout。
- 与 PostgreSQL 后备服务器上的 WAL 接收进程不同,pg_receivewal默认只在一个 WAL 文件被关闭时才刷入 WAL 数据。要实时刷入 WAL 数据,必须指定选项
--synchronous。 由于pg_receivewal不应用于WAL,当synchronous_commit等于?remote_apply时,你将不允许它成为同步备用。 如果发生这样的情况,它将成为一个永远不能拉起的备用数据库,并且会导致事务提交阻塞。 为了避免这种情况,你应该为synchronous_standby_names配置一个适当的值,或规定为pg_receivewal?的application_name?与它不匹配,或将synchronous_commit的值更改为remote_apply以外的内容。 - 预写式日志在一个常规PostgreSQL连接上被以流式传送,并且使用复制协议。连接必须由一个具有
REPLICATION权限的用户或者一个超级用户建立,并且pg_hba.conf必须允许复制连接。服务器也必须被配置一个足够高的max_wal_senders来至少留出一个可用会话给流。
? ? ? ?The starting point of the write-ahead log streaming is calculated when?pg_receivewal?starts:
? ? ? ?1.首先,扫描WAL段文件所写入的目录,并发现最新完成的段文件,作为下一个段文件的开始的起始点。 这是独立计算的,根据用于压缩每个段的压缩方法。
? ? ? ?2.如果用前面的方法无法计算出起点,最新的WAL刷写位置用作由服务器通过IDENTIFY_SYSTEM命令的报告。
- 如果该连接丢失,或者它一开始就由于一个非致命错误而没有被建立,pg_receivewal将无限期地重试连接并且尽可能重新建立流。为了避免这种行为,使用
-n参数。 - 如果不出现致命错误,pg_receivewal将一直运行直至被SIGINT信号(Control+C)终止。
pg_recvlogical
控制?PostgreSQL?逻辑解码流
pg_recvlogical [option...]pg_recvlogical控制逻辑解码复制槽以及来自这种复制槽的流数据。- 它会创建一个复制模式的连接,因此它受到和
?pg_receivewal相同的约束,还有逻辑复制的约束。 pg_recvlogical与逻辑解码SQL接口的peek和get模式没有等效性。它咋接收到数据以及干净地退出时,它会惰性地发送数据的确认。为了检查一个槽上还未消费的待处理数据,可以使用
pg_logical_slot_peek_changes。
pg_restore
从一个由pg_dump创建的归档文件恢复一个PostgreSQL数据库
pg_restore [connection-option...] [option...] [filename]- pg_restore是一个用来从pg_dump创建的非文本格式归档恢复PostgreSQL数据库的工具。它将发出必要的命令把该数据库重建成它被保存时的状态。这些归档文件还允许pg_restore选择恢复哪些内容或者在恢复前对恢复项重排序。这些归档文件被设计为可以在不同的架构之间迁移。
- pg_restore可以在两种模式下操作。如果指定了一个数据库名称,pg_restore会连接那个数据库并且把归档内容直接恢复到该数据库中。否则,会创建一个脚本,其中包含着重建该数据库所必要的 SQL 命令,它会被写入到一个文件或者标准输出。这个脚本输出等效于pg_dump的纯文本输出格式。因此,一些控制输出的选项与pg_dump的选项类似。
- 显然,pg_restore无法恢复不在归档文件中的信息。例如,如果归档使用“以
INSERT命令转储数据”选项创建,?pg_restore将无法使用COPY语句装载数据。
pg_verifybackup
验证PostgreSQL集群的基础备份的完整性
pg_verifybackup [option...]- pg_verifybackup用于根据备份时服务器生成的
backup_manifest检查使用pg_basebackup进行的数据库群集备份的完整性。备份必须以“普通”格式存储;“tar”格式的备份可以在解压缩后进行检查。 - 需要注意的是,由pg_verifybackup执行的验证不包括也不可能包括运行中的服务器在尝试使用备份时执行的所有检查。 即使使用此工具,也应执行测试还原,并验证生成的数据库是否按预期工作,以及它们是否包含正确的数据。但是,pg_verifybackup可以检测到由于存储问题或用户错误而经常出现的许多问题。
- 备份验证分四个阶段进行。首先,
pg_verifybackup读取backup_manifest文件。如果该文件不存在、无法读取、格式不正确或无法根据其内部校验和进行验证,pg_verifybackup?将以致命错误终止。 - 其次,
pg_verifybackup?将尝试验证当前存储在磁盘上的数据文件是否与服务器打算发送的数据文件完全相同,下面将介绍一些例外情况。 除了少数例外,额外和丢失的文件将被检测到。此步骤将忽略?postgresql.auto.conf、standby.signal?和?recovery.signal?的存在与否或对其的任何修改,因为预计这些文件可能是在备份过程中创建或修改的。它也不会抱怨目标目录中的?backup_manifest?文件或?pg_wal?中的任何内容,即使这些文件不会列在备份清单中。只检查文件;不验证目录的存在与否,除非间接验证:如果目录丢失,则它应该包含的任何文件也必然会丢失。 - 接下来,
pg_verifybackup将对所有文件进行校验和计算,将校验和与清单中的值进行比较,并对计算出的校验和与清单中存储的校验和不匹配的任何文件发出错误。对于在上一步中产生错误的任何文件,不执行此步骤,因为已知这些文件存在问题。在上一步中被忽略的文件在此步骤中也被忽略。 - 最后,
pg_verifybackup?将使用清单来验证恢复备份所需的预写式日志记录是否存在,并且它们可以被读取和解析。?backup_manifest?包含有关需要哪些预写式日志记录的信息,并且?pg_verifybackup?将使用该信息来调用?pg_waldump?来解析这些预写式日志记录。?--quiet?标志将被使用,因此?pg_waldump?只会报告错误,而不会产生任何其他输出。虽然这种级别的验证足以检测明显的问题,例如丢失的文件或内部校验和不匹配的问题,但它们还不足以检测尝试恢复时可能出现的所有问题。例如,此方法无法检测到产生具有正确校验和但指定无意义操作的预写式日志记录的服务器错误。 - 请注意,如果存在不需要恢复备份的额外 WAL 文件,则此工具不会检查它们,尽管可以为此使用单独的?
pg_waldump?调用。 另请注意,WAL 验证是特定于版本的:您必须使用?pg_verifybackup?的版本,因此是?pg_waldump?的版本,它与正在检查的备份有关。 相比之下,数据文件完整性检查应适用于生成?backup_manifest?文件的任何版本的服务器。
psql
PostgreSQL的交互式终端
psql [option...] [dbname [username]]- psql是一个PostgreSQL的基于终端的前端。它让你能交互式地键入查询,把它们发送给PostgreSQL,并且查看查询结果。或者,输入可以来自于一个文件或者命令行参数。此外,psql还提供一些元命令和多种类似 shell 的特性来为编写脚本和自动化多种任务提供便利。
reindexdb
重索引一个PostgreSQL数据库
reindexdb [connection-option...] [option...] [ -S | --schema schema ] ... [ -t | --table table ] ... [ -i | --index index ] ... [dbname]
reindexdb [connection-option...] [option...] -a | --all
reindexdb [connection-option...] [option...] -s | --system [dbname]- reindexdb是用于重建一个PostgreSQL数据库中索引的工具。
- reindexdb是 SQL 命令REINDEX
的一个包装器。 在通过这个工具和其他方法访问服务器来重索引数据库之间没有实质性的区别。
vacuumdb
vacuumdb — 对一个PostgreSQL数据库进行垃圾收集和分析
vacuumdb [connection-option...] [option...] [ -t | --table table [( column [,...] )] ] ... [dbname]
vacuumdb [connection-option...] [option...] -a | --all- vacuumdb是用于清理一个PostgreSQL数据库的工具。vacuumdb也将产生由PostgreSQL查询优化器所使用的内部统计信息。
- vacuumdb是 SQL 命令VACUUM的一个包装器。 在通过这个工具和其他方法访问服务器来清理和分析数据库之间没有实质性的区别。
数据库Data目录文件结构
├── base #存储数据库用户所创建的各个数据库,同时也包括postgres、template0和template1的pg_defaulttablespace。
├── global #存储集群范围的各个表和相关视图。(pg_database、pg_tablespace)
├── pg_commit_ts #存储已提交事务的时间
├── pg_dynshmem #存储动态共享内存子系统使用的文件。
├── pg_hba.conf #认证配置文件,配置了允许哪些IP访问数据库,及认证方式等信息。 #存储 committed serializable transactions 信息
├── pg_ident.conf #"ident"认证方式的用户映射文件。
├── pg_logical #存储包含逻辑解码的状态数据
│?? ├── mappings
│?? ├── replorigin_checkpoint
│?? └── snapshots
├── pg_multixact #该目录包含多事务状态数据。(等待锁定的并发事务)
├── pg_notify #该目录包含LISTEN/NOTIFY状态数据。
├── pg_replslot #该目录包含复制槽数据。
├── pg_serial
├── pg_snapshots #存储导出的snapshots(快照)。
├── pg_stat #存储统计子系统的永久文件。
├── pg_stat_tmp #存储统计子系统的临时文件。
├── pg_subtrans #存储子事务状态数据。
│?? └── 0000
├── pg_tblspc #存储指向表空间的符号链接
│?? └── 16399 -> /data/16.1/tablespace/dba_circle #表空间软连接
├── pg_twophase #该目录包含预备事务的状态文件。
├── PG_VERSION #记录了数据库版本号信息。
├── pg_wal #存储wal日志。(undo,redo)
│?? ├── 000000010000000000000003
│?? ├── 000000010000000000000004
│?? └── archive_status
├── pg_xact #存储事务提交状态数据。
├── postgresql.auto.conf #作用同 postgresql.conf ,优先级高于 postgresql.conf,在数据库中通过alter命令更改的参数记录在此文件中。
├── postgresql.conf #数据库实例主配置文件,基本上所有的数据库参数配置都在此文件中。
├── postmaster.opts #存储上一次启动该数据库时用到的命令。
└── postmaster.pid #锁文件,只有在 postgresql 服务运行时存在,存储当前 postmaster 的 PID,PGDATA,postmaster 启动时间,端口号,Unix-domain socket 目录,第一个有效的 listen_address,共享内存的 segment ID
base目录
base目录存储用户创建的数据库文件,及隶属于用户数据库的所有关系,比如表、索引等。
base目录结构分为两级,第一级结构如下图所示,一级目录名是用户数据库对象的OID,1代表的是postgres数据库,一级目录内的二级子文件都是隶属于该数据库对象的关系,包括表、索引、视图等。
- pg_filenode.map 是pg_class里relfilenode为0的系统表,OID与文件的硬编码映射。
- pg_internal.init 是系统表的cache文件,用于加快读取。默认不存在,查询系统表后自动产生。
- PG_VERSION 是当前数据库数据格式对应的版本号
- 其它文件是需要到pg_class里根据OID查到对应的relfilenode来与文件名匹配的。
- 纯数字的是
主表数据文件或索引数据文件。 - 以“_fsm”后缀的就是Free Space Mapping文件。
- 以”vm”后缀的就是visibility map。
├── base
│?? ├── 1 #用户数据库对象的OID,1代表的是postgres数据库
│?? │?? ├── 112 #隶属于该数据库对象的关系,包括表、索引、视图等。
│?? │?? ├── ...
│?? │?? ├── 828
│?? │?? ├── pg_filenode.map
│?? │?? └── PG_VERSION
│?? ├── 4
│?? │?? ├── 112 #以关系OID命名的是主数据文件
│?? │?? ├── 113
│?? │?? ├── 1247
│?? │?? ├── 1247_fsm #以_fsm结尾的是空闲空间映射文件
│?? │?? ├── 1247_vm #以_vm结尾的是可见性映射文件
│?? │?? ├── ...
│?? │?? ├── 828
│?? │?? ├── pg_filenode.map
│?? │?? └── PG_VERSION
│?? └── 5
│?? ├── 112
│?? ├── 113
│?? ├── 1247
│?? ├── 1247_fsm
│?? ├── 1247_vm
│?? ├── ...
│?? ├── 828
│?? ├── pg_filenode.map
│?? └── PG_VERSION
- 主数据文件存储隶属于对应数据库下的数据库关系文件,包括数据、索引等,客户最重要的业务- 数据便是存储在主数据文件中。
- 当关系文件大小低于RELSEG_SIZE × BLCKSZ时,数据库引擎创建名称为pg_class.relfilenode的单文件,反之会切分为名称如pg_class.relfilenode.segno的多个文件。单个关系文件内部被划分为默认8K固定大小的多个page并存储在磁盘上,8K可以在initdb时通过BLCKSZ参数修改配置。主数据文件写入时,会先将元组数据从行指针数组的底部开始堆叠,直到空间耗尽。
- 用户通过SQL查询到的单行数据记录对应单个元组(tuple),因为MVCC机制的原因,元组可能是无法查询到旧版本数据,也可能是活跃的新版本数据,旧版本数据会在未来的某个时刻被清理。当查询没有命中索引触发顺序扫描时,数据库引擎顺序扫描page的行指针读取到元组,反之如果命中B树索引,引擎会通过索引文件的元组,通过索引键的TID值读取到元组。
主数据文件的层级结构图?
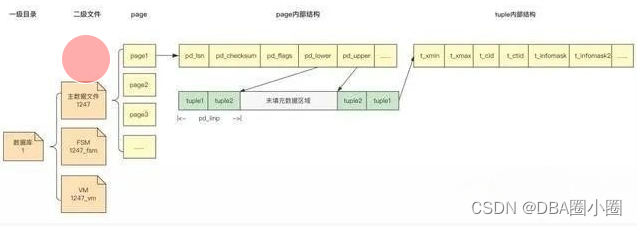 ??
??
?page内部结构的元数据信息表
| 名称 | 作用 | |||
|---|---|---|---|---|
| 1 | pd_lsn | 最近一次变更写入的XLOG记录对应的LSN | ||
| 2 | pd_checksum | checksum | ||
| 3 | pd_lower | 指向行指针的末尾 | ||
| 4 | pd_upper | 指向最新堆元组的起始位置 | ||
| 5 | pd_flags | 标记位 | ||
| 6 | pd_linp | 行指针:指向堆元组的指针数组 | ||
第三方
tuple内部结构的元数据信息表
| 名称 | 作用 | |||
|---|---|---|---|---|
| 1 | t_xmin | tuple插入时的XID | ||
| 2 | t_xmax | tuple更新或剧除时的XID | ||
| 3 | t_cid | command Io | ||
| 4 | t_ctid | TID:BLOCK_ID和行指针偏移号 | ||
| 5 | t_infomask | 状态位:方便检查元组xmin和xmax对应事务的状恋,避免频繁访问共享内存 | ||
| 6 | tinfomask2 | 状态位:标记HOT | ||
FSM是空闲空间映射文件,记录着heap和index的每个page的空闲空间信息,有利于快速定位到有充足空闲空间的page以便存储tuple,如果没有定位到则需要扩展新page。除了Hash Index文件没有FSM文件,其他heap和index都需要FSM文件。
总体上,FSM采用3-4级多叉树的结构组织FSM page,单个FSM page内部采用完全二叉树的结构进行管理,高级别FSM page的叶子节点关联低级别的FSM page,低级别FSM Page的叶子节点存储着heap、index page的可用空间数目,而非叶子结点依次存储叶子节点的最大可用空间数目,每个节点占用1个字节。
global目录
global目录存储pg_control及数据库集群维度的数据库及其关系,非客户维度的数据,例如pg_database、pg_class等。目录内的文件结构和base是一致的。
[postgres@postgre-sql data2]$ ls -l global/
总用量 540
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1213
-rw-------. 1 postgres postgres 24576 12月 16 09:37 1213_fsm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1213_vm
-rw-------. 1 postgres postgres 0 12月 16 09:37 1214
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1232
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1233
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1260
-rw-------. 1 postgres postgres 24576 12月 16 09:37 1260_fsm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1260_vm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1261
-rw-------. 1 postgres postgres 24576 12月 16 09:37 1261_fsm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1261_vm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1262
-rw-------. 1 postgres postgres 24576 12月 16 09:37 1262_fsm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 1262_vm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 2396
-rw-------. 1 postgres postgres 24576 12月 16 09:37 2396_fsm
-rw-------. 1 postgres postgres 8192 12月 16 09:37 2396_vm
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2397
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2671
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2672
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2676
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2677
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2694
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2695
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2697
-rw-------. 1 postgres postgres 16384 12月 16 09:37 2698
-rw-------. 1 postgres postgres 0 12月 16 09:37 2846
-rw-------. 1 postgres postgres 8192 12月 16 09:37 2847
-rw-------. 1 postgres postgres 0 12月 16 09:37 2964
-rw-------. 1 postgres postgres 8192 12月 16 09:37 2965
-rw-------. 1 postgres postgres 0 12月 16 09:37 2966
-rw-------. 1 postgres postgres 8192 12月 16 09:37 2967
-rw-------. 1 postgres postgres 0 12月 16 09:37 3592
-rw-------. 1 postgres postgres 8192 12月 16 09:37 3593
-rw-------. 1 postgres postgres 0 12月 16 09:37 4060
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4061
-rw-------. 1 postgres postgres 0 12月 16 09:37 4175
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4176
-rw-------. 1 postgres postgres 0 12月 16 09:37 4177
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4178
-rw-------. 1 postgres postgres 0 12月 16 09:37 4181
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4182
-rw-------. 1 postgres postgres 0 12月 16 09:37 4183
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4184
-rw-------. 1 postgres postgres 0 12月 16 09:37 4185
-rw-------. 1 postgres postgres 8192 12月 16 09:37 4186
-rw-------. 1 postgres postgres 0 12月 16 09:37 6000
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6001
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6002
-rw-------. 1 postgres postgres 0 12月 16 09:37 6100
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6114
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6115
-rw-------. 1 postgres postgres 0 12月 16 09:37 6243
-rw-------. 1 postgres postgres 0 12月 16 09:37 6244
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6245
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6246
-rw-------. 1 postgres postgres 8192 12月 16 09:37 6247
-rw-------. 1 postgres postgres 16384 12月 16 09:37 6302
-rw-------. 1 postgres postgres 16384 12月 16 09:37 6303
-rw-------. 1 postgres postgres 16384 12月 16 09:37 pg_internal.init
-rw-------. 1 postgres postgres 8192 12月 16 09:37 pg_control
-rw-------. 1 postgres postgres 524 12月 16 09:37 pg_filenode.map
- pg_internal.init用于缓存系统表,加快系统表读取速度(每个用户创建的数据库目录下也有同名文件)。
- pg_filenode.map用于将当前目录下系统表的OID与具体文件名进行硬编码映射(每个用户创建的数据库目录下也有同名文件)。
- pg_control用于记录数据库集群控制全局控制信息,包括initdb初始化、WAL和checkpoint的信息。
- 全局系统表文件:数字命名的文件,用于存储系统表的内容。它们在pg_class里的relfilenode都为0,是靠pg_filenode.map将OID与文件硬编码映射。(注:不是所有的系统表的relfilenode都为0)
- 全局系统表文件:数字命名的文件,用于存储系统表的内容。它们在pg_class里的relfilenode都为0,是靠pg_filenode.map将OID与文件硬编码映射。(注:不是所有的系统表的relfilenode都为0)
pg_wal目录
pg_wal是WAL机制中的wal日志存储目录。PG10及之后的高版本改目录名为pg_wal,10之前目录名称是pg_xlog。
WAL(Write-Ahead-Logging)机制:日志先行机制。数据变更优先写入日志文件,事务失败则变更记录被忽略,事务成功再选择合适时机写入数据文件,数据的刷盘速度慢于日志刷盘速度。当数据库系统崩溃后,引擎会从上一次成功的checkpoint点开始依次重放wal记录,如果LSN>pd_lsn则重放wal记录,反之跳过,确保数据记录恢复到崩溃前的状态。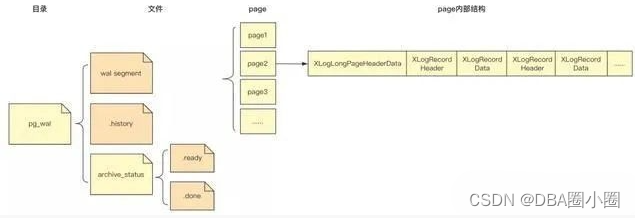 ??
??
wal segment 文件存储着数据库行记录明细,每一条记录明细都是服务于数据库恢复操作的,确保前后数据一致。首先针对数据的任意一次修改操作均被记录在wal段文件中,包括insert、update和delete,其次系统的一些管理行为也会被记录在wal段文件中,例如事务提交和vacuum等行为。
wal segment 文件命名形如00000046 00000000 000000F3,文件名共24位,
前8位是timeline,
中间8位是logid
后8位是logseg,
logseg的前6位始终是0,
后2位是lsn的前2位。
根据wal段文件名的最后2位,wal记录根据对应的LSN分别记录在不同的wal段文件中。
-rw-------. 1 postgres postgres 16777216 12月 15 12:28 000000010000000000000003
-rw-------. 1 postgres postgres 16777216 12月 15 11:53 000000010000000000000004
-rw-------. 1 postgres postgres 16777216 12月 15 11:54 00000002.history
-rw-------. 1 postgres postgres 16777216 12月 15 11:54 000000020000000000000001
drwx------. 2 postgres postgres 6 12月 13 15:51 archive_status
- .history文件内容包括原.history文件,当前时间线切换记录和切换原因,作用于数据库的时间点恢复行为。当数据库引擎从多个时间线的备份中恢复时,数据库从.history文件中找到从pg_control的start_timeline到指定的recovery_target_timeline间的所有wal段文件进行恢复。
- archive_status是wal segment 文件的备份目录,包括.ready和.done文件。超出wal_keep_segments数目限制的wal日志会在archive_status目录内被打标,归档操作完成后被进一步移除。
- .ready是同名wal segment 文件在archive_status目录内的标记文件,代表该wal segment 文件可被归档。wal segment 文件在数据目录中的存储文件数量是有上限的,一般通过wal_keep_segments参数来约束,因此数据库引擎在wal segment 文件个数达到上限后会在archive_status目录内增加可移除的wal segment 文件的标记文件,文件名是原wal segment 文件名后增加.ready后缀,等待归档工具进行归档。
- .done是同名wal segment 文件在archive_status目录内的标记文件,代表该wal segment 文件已被归档,可以被清理。数据库引擎默认通过archive_command命令对.ready文件进行归档,归档成功与否取决于archive_command命令返回true还是false,当archive_command返回true时,代表与.ready文件同名的wal段文件已被归档,引擎再将该文件的扩展名重命名为.done,等待数据库引擎在下一次的checkpoint时进一步清理原wal segment 文件。
pg_xact目录
g_xact是事务提交日志(Commit Log)的存储目录,事务提交日志默认256KB,文件名形如NNNN,系统初始化后从0000开始递增至FFFF。PG 10及之后的高版本改目录名为pg_xact,10之前目录名称是pg_clog。
[postgres@postgre-sql data2]$ ls -l pg_xact/
总用量 8
-rw-------. 1 postgres postgres 8192 12月 16 09:37 0000
[postgres@postgre-sql data2]$
Commit Log : 事务提交日志存储数据库的单个事务运行状态。Commit Log由共享内存中一组8KB的page组成,每个page包含一列数组,每个数组元素包含XID和该事物的实时状态。当page不足时,创建新的page来存储新的事务。
pg_ident.conf
当pg_hba.conf使用ident认证方式时,需要建立映射用户或具备同名用户。
ident是Linux下PostgreSQL默认的local认证方式,
凡是能正确登录服务器的操作系统用户(注:不是数据库用户)就能使用本用户映射的数据库用户不需密码登录数据库。
pg_ident.conf就是用来配置哪些操作系统用户映射为哪些数据库用户的。
如果某操作系统用户在本文件中没有映射用户,则默认的映射数据库用户与操作系统用户同名。
pg_ident.conf的格式如下:
# MAPNAME SYSTEM-USERNAME PG-USERNAME
[postgres@postgre-sql data2]$
usermap为映射名,要在pg_hba.conf中用到,多个映射可以共用同一个映射名,username为操作系统用户名,dbuser为映射到的数据库用户。
pg_hba.conf的格式如下:
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
local all all ident map=mapzy
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
[postgres@postgre-sql data2]$
map是pg_hba.conf的auth-options选项,map=mapzy指示该认证条件使用mapzy映射。
指定映射后原本的同名操作系统用户就不能连接数据库了。
postgresql.auto.conf
postgresql.auto.conf的优先级高于postgresql.conf,
如果一个参数同时存在postgresql.auto.conf和postgresql.conf里面,系统会先读postgresql.auto.conf的参数配置。
使用alter system set修改的是postgresql.auto.conf文件的内容,postgresql.conf则是通过文本编辑方式修改。
比如执行alter system set max_wal_size=default将参数设回 default 时,postgresql.auto.conf文件里的max_wal_size这项配置会被删除,重新用回postgresql.conf文件的设置。
postgresql.conf
postgresql.conf文件内容太多, 详细内容另开一篇文件来讲。postgresql.conf文件的参数后面有# (change requires restart),表示必须重启才能生效,使用select pg_reload_conf()或pg_ctl reload不行。
postmaster.pid
[postgres@postgre-sql data]$ cat postmaster.pid
4856
/data/16.1/data
1702532710
5432
/tmp
*
34133634 6
ready
[postgres@postgre-sql data]$ ipcs
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
------------ 共享内存段 --------------
键 shmid 拥有者 权限 字节 nattch 状态
0x0208d682 6 postgres 600 56 6
--------- 信号量数组 -----------
键 semid 拥有者 权限 nsems
[postgres@postgre-sql data]$ echo 0x0208d682 | printf "%d\n" $(cat)
34133634
[postgres@postgre-sql data]$
通过ipcs命令查看共享内存的地址信息
可以看到shared memory segments中的key是0x0208d682
0x0208d682十六进制转换为十进制为34133634,正好等于第一个数字,即为共享内存的key。
第二个数字为shmid的值,即为共享内存的id。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!