随机森林1(了解整体知识架构)
很多人想学习或者了解随机森林,查到的资料都是先讲熵,再讲决策树,然后再讲随机森林,前面坚持不下来或者一个地方没理解透彻,导致无法向下学习,而且公式讲解不够清晰,例子不够详细,很难让小白彻底搞清楚到底是怎么回事。这里呢就先讲整体知识架构,然后再学习公式,最后和大家手把手计算一遍,体会其中的奥妙。
一、随机森林宏观介绍
随机森林,顾名思义,用随机的的方式构建森林,森林是由树组成的,而随机森林的树就是决策树。为什么认为多个决策树结果比一个决策树结果好呢?大家可以理解为三个臭皮匠顶上一个诸葛亮。这里还要说其他只讲公式博客中忽略的地方,有四点增加大家对随机森林的理解:
1、从样本中选出一份数据集只能画一棵树;
2 、要花多棵树就要选多次数据集,随机森林中的随机指的就是这里;
3 、最终结果由所有决策树投票决定,没涉及到权重;
4 、建树的数量是由多中因素决定的,比如数据集大小、计算资源等,一般来说在几十到 一千之间;
二、决策树宏观介绍
决策树很好理解,就是根据判断条件形成一个树状结构,对结果进行判断,比如下面就是顾客是否会买裤子的决策树模型。构建决策树的重点在于如何选择根节点和内部节点,根节点对应下图中的材料,内部节点对应下图中的裤型、尺寸、价钱。
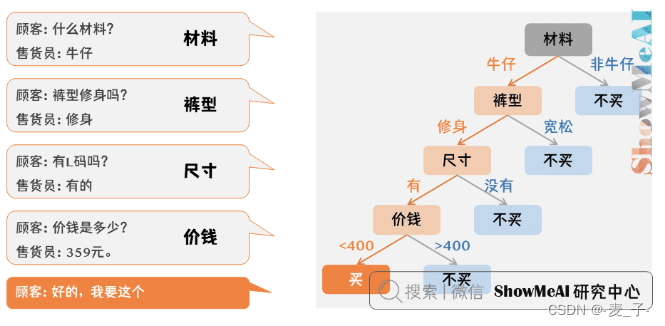
决策树的发展主要经过了三个阶段,这三个阶段本质区别就是如何选择下一个内部节点。这三个阶段分别是:
1 、用信息增益选择下一个内部节点,代表算法是 ID3;
2 、用信息增益率选择下一个内部节点,代表算法是 C4.5;
3 、用基尼指数选择下一个内部节点,代表算法是 CART;
目前,随进森林中的决策树都是根据基尼指数来构建的。
三、随机森林四种实现方法
随机森林是常用的机器学习算法,既可以用于分类问题,也可用于回归问题。本文对 scikit-learn、Spark MLlib、DolphinDB、XGBoost 四个平台的随机森林算法实现进行对比测试。评价指标包括内存占用、运行速度和分类准确性。
测试结果如下: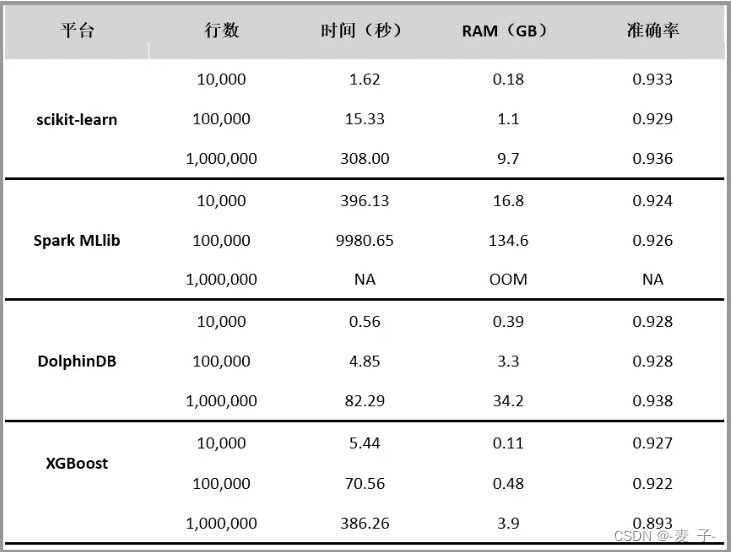
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!