【改进YOLOv8】鸟类图像分类系统:引入上下文引导网络(CGNet)改进YOLOv8
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
近年来,随着计算机视觉技术的快速发展,目标检测成为了计算机视觉领域的一个重要研究方向。其中,YOLO(You Only Look Once)系列算法以其高效的实时性能和准确的检测结果而备受关注。然而,对于复杂场景和小目标的检测,YOLOv8仍然存在一些局限性。
鸟类图像分类是生物学、生态学和环境保护等领域的重要研究内容。鸟类在生态系统中扮演着重要的角色,对于生态平衡的维持和生物多样性的保护具有重要意义。因此,开发一种高效准确的鸟类图像分类系统对于鸟类研究和保护工作具有重要意义。
然而,由于鸟类的外貌特征多样且复杂,鸟类图像分类面临着一些挑战。首先,鸟类的姿态、光照条件和背景等因素会对图像造成干扰,导致分类准确率下降。其次,鸟类的种类众多,存在一些相似的物种,容易造成分类错误。此外,鸟类图像通常具有较高的分辨率和复杂的纹理,对于传统的图像分类算法来说,计算复杂度较高。
为了解决上述问题,研究者们提出了一种改进YOLOv8的鸟类图像分类系统,引入上下文引导网络(CGNet)。CGNet是一种基于深度学习的上下文引导网络,可以有效地提取图像中的上下文信息,从而提高目标检测的准确性和鲁棒性。
CGNet的核心思想是通过引入上下文信息来辅助目标检测。传统的目标检测算法通常只关注目标本身的特征,而忽略了目标周围的上下文信息。然而,上下文信息对于目标的识别和分类具有重要作用。例如,在鸟类图像分类中,鸟类的生活环境和行为习性等上下文信息可以提供额外的特征来区分不同的鸟类。
CGNet通过引入上下文引导模块来提取上下文信息。该模块包括两个关键组件:上下文特征提取器和上下文特征融合器。上下文特征提取器用于提取图像中的上下文特征,例如背景、环境和其他物体等。上下文特征融合器将上下文特征与目标特征进行融合,从而得到更加准确的目标检测结果。
通过引入CGNet改进YOLOv8的鸟类图像分类系统,可以有效地提高鸟类图像分类的准确性和鲁棒性。首先,CGNet可以提取图像中的上下文信息,从而提供更多的特征来区分不同的鸟类。其次,CGNet可以减少背景、光照和姿态等因素对图像分类的干扰,提高分类的准确率。最后,CGNet可以降低计算复杂度,提高系统的实时性能。
综上所述,改进YOLOv8的鸟类图像分类系统引入上下文引导网络(CGNet)具有重要的研究意义和应用价值。该系统可以为鸟类研究和保护工作提供一种高效准确的图像分类方法,为生态学、生物学和环境保护等领域的研究提供有力支持。同时,该系统的研究成果也可以推广到其他目标检测领域,具有广泛的应用前景。
2.图片演示



3.视频演示
【改进YOLOv8】鸟类图像分类系统:引入上下文引导网络(CGNet)改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集DirdDatasets。
下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random
# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'
# 确保输出文件夹存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):
input_subdir_path = os.path.join(input_dir, subdir)
# 确保它是一个子文件夹
if os.path.isdir(input_subdir_path):
output_subdir_path = os.path.join(output_dir, subdir)
# 在输出文件夹中创建同名的子文件夹
if not os.path.exists(output_subdir_path):
os.makedirs(output_subdir_path)
# 获取所有文件的列表
files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]
# 随机选择四分之一的文件
files_to_move = random.sample(files, len(files) // 4)
# 移动文件
for file_to_move in files_to_move:
src_path = os.path.join(input_subdir_path, file_to_move)
dest_path = os.path.join(output_subdir_path, file_to_move)
shutil.move(src_path, dest_path)
print("任务完成!")
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset
-----dataset
|-----train
| |-----class1
| |-----class2
| |-----.......
|
|-----valid
| |-----class1
| |-----class2
| |-----.......
|
|-----test
| |-----class1
| |-----class2
| |-----.......
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这个程序文件是一个名为predict.py的文件,它是一个用于预测基于检测模型的类DetectionPredictor的定义。这个类继承自BasePredictor类,并包含了一个postprocess方法用于后处理预测结果。在postprocess方法中,预测结果经过非最大抑制处理后,将被转换为Results对象的列表并返回。这个文件还导入了一些其他的模块和函数,用于处理预测过程中的一些操作。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ?? 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这是一个用于训练目标检测模型的程序文件。它使用了Ultralytics YOLO库,并继承了BaseTrainer类。以下是该程序文件的主要功能:
- 导入所需的库和模块。
- 定义了一个名为DetectionTrainer的类,该类继承自BaseTrainer类。
- 实现了构建YOLO数据集、构建数据加载器、预处理批次、设置模型属性等方法。
- 定义了获取模型、获取验证器、标记损失项、打印训练进度、绘制训练样本和绘制指标等方法。
- 在主函数中,创建了一个DetectionTrainer对象,并调用其train方法进行模型训练。
该程序文件的主要功能是使用Ultralytics YOLO库训练目标检测模型,并提供了一些辅助方法用于数据处理、模型设置和结果可视化等。
5.4 ui.py
#### 5.5 backbone\EfficientFormerV2.py
```python
import torch
import torch.nn as nn
import math
class Attention4D(nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8, attn_ratio=4, resolution=7, act_layer=nn.ReLU, stride=None):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = key_dim * num_heads
if stride is not None:
self.resolution = math.ceil(resolution / stride)
self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim))
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2
self.N2 = self.N
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + self.nh_kd * 2
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim))
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim))
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d))
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d))
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.proj = nn.Sequential(act_layer(),
nn.Conv2d(self.dh, dim, 1),
nn.BatchNorm2d(dim))
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not
EfficientFormerV2.py是一个用于图像分类的模型文件。该文件定义了EfficientFormerV2模型的结构和各个组件的实现。
EfficientFormerV2模型是一个基于注意力机制的模型,它由多个EfficientFormerBlock组成。每个EfficientFormerBlock由一个Attention4D模块和一个FeedForward模块组成。Attention4D模块用于提取图像特征并进行注意力计算,FeedForward模块用于对特征进行线性变换和非线性激活。
EfficientFormerV2模型还包括一些辅助函数和辅助模块,如stem函数用于构建模型的初始卷积层,LGQuery模块用于生成局部和全局的查询向量,Attention4DDownsample模块用于下采样特征图并进行注意力计算,Embedding模块用于将输入图像转换为特征图。
EfficientFormerV2模型的参数和结构可以根据不同的配置进行调整,如模型的宽度和深度可以根据EfficientFormer_width和EfficientFormer_depth进行设置,不同的配置对应不同的模型大小和性能。
5.6 backbone\efficientViT.py
class EfficientViT_M0(nn.Module):
def __init__(self, num_classes=1000, in_chans=3, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=False, drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0):
super(EfficientViT_M0, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i])
for i in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.head.weight, std=0.02)
nn.init.zeros_(self.head.bias)
def forward_features(self, x):
x = self.patch_embed(x)
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
该程序文件是一个用于下游任务的EfficientViT模型架构。它定义了多个模块和类,包括Conv2d_BN、PatchMerging、Residual、FFN、CascadedGroupAttention和LocalWindowAttention等。
Conv2d_BN是一个包含卷积和批归一化的序列模块,用于构建卷积层和批归一化层。
PatchMerging模块用于将输入的图像块进行合并,通过卷积和批归一化操作将输入的特征图转换为输出的特征图。
Residual模块实现了残差连接,将输入与经过一系列操作后的特征图相加。
FFN模块是一个前馈神经网络,通过两个卷积层和激活函数ReLU对输入进行处理。
CascadedGroupAttention模块实现了级联组注意力机制,用于对输入特征图进行注意力计算。
LocalWindowAttention模块实现了局部窗口注意力机制,根据输入特征图的大小和窗口大小选择不同的计算方式。
整个程序文件定义了多个模块和类,用于构建EfficientViT模型的不同部分,以实现高效的视觉注意力机制。
6.系统整体结构
下表总结了每个文件的功能:
| 文件 | 功能 |
|---|---|
| export.py | 导出模型为ONNX、TensorFlow等格式 |
| predict.py | 使用训练好的模型进行预测 |
| train.py | 训练模型 |
| ui.py | 创建GUI界面,用于目标检测 |
| backbone\EfficientFormerV2.py | EfficientFormerV2模型的实现 |
| backbone\efficientViT.py | efficientViT模型的实现 |
| backbone\fasternet.py | fasternet模型的实现 |
| backbone\lsknet.py | lsknet模型的实现 |
| backbone\repvit.py | repvit模型的实现 |
| backbone\revcol.py | revcol模型的实现 |
| backbone\SwinTransformer.py | SwinTransformer模型的实现 |
| backbone\VanillaNet.py | VanillaNet模型的实现 |
| classify\predict.py | 使用训练好的模型进行分类预测 |
| classify\train.py | 训练分类模型 |
| classify\val.py | 验证分类模型的性能 |
| extra_modules\attention.py | 实现注意力机制的模块 |
| extra_modules\block.py | 实现网络块的模块 |
| extra_modules\dynamic_snake_conv.py | 实现动态蛇卷积的模块 |
| extra_modules\head.py | 实现网络头部的模块 |
| extra_modules\kernel_warehouse.py | 存储卷积核的模块 |
| extra_modules\orepa.py | 实现OREPA算法的模块 |
| extra_modules\rep_block.py | 实现重复块的模块 |
| extra_modules\RFAConv.py | 实现RFA卷积的模块 |
| models\common.py | 通用的模型函数和类 |
| models\experimental.py | 实验性的模型函数和类 |
| models\tf.py | TensorFlow模型函数和类 |
| models\yolo.py | YOLO模型函数和类 |
| ultralytics… | Ultralytics库的各个模块和功能 |
| utils… | 通用的工具函数和类 |
这些文件涵盖了模型的构建、训练、预测、导出等各个方面,以及一些辅助模块和工具函数。
7.YOLOv8简介
Yolov8主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上,具体创新如下:
·提供了一个全新的SOTA模型(包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型)。并且,基于缩放系数提供了N/S/M/IL/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
●Backbone:同样借鉴了CSP模块思想,不过将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式—套参数用于所有模型,大幅提升了模型性能。
●Neck:继续使用PAN的思想,但是通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8移除了1*1降采样层。
●Head部分相比YOLOv5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
●Loss计算:使用VFLLoss作为分类损失(实际训练中使用BCE Loss);使用DFLLoss+ClOU Loss作为回归损失。
●标签分配: Yolov8抛弃了以往的loU分配或者单边比例的分配方式,而是采用Task-Aligned Assigner正负样本分配策略。
Yolov8网络结构
Yolov8模型网络结构图如下图所示。
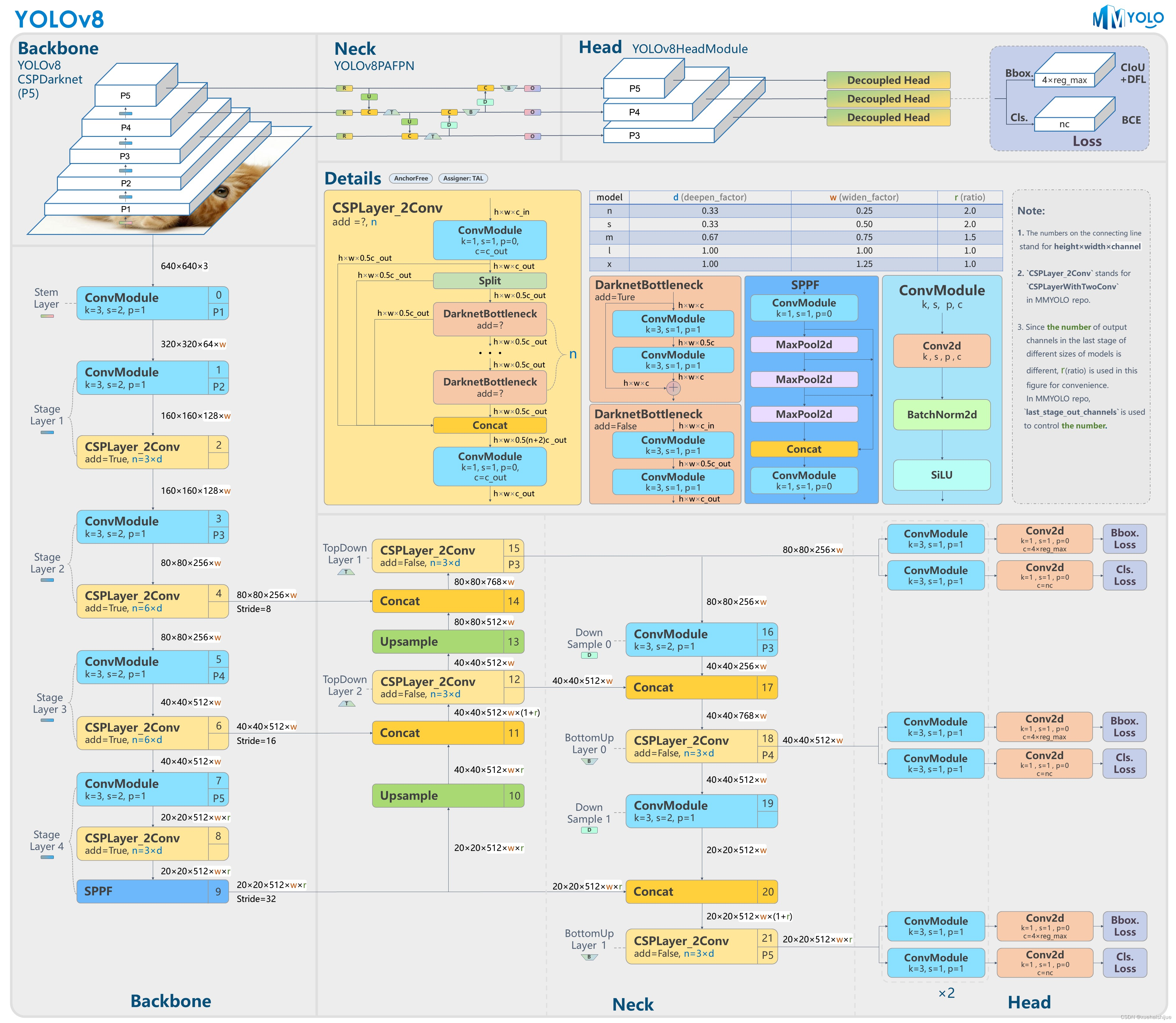
Backbone
Yolov8的Backbone同样借鉴了CSPDarkNet结构网络结构,与Yolov5最大区别是,Yolov8使用C2f模块代替C3模块。具体改进如下:
·第一个卷积层的Kernel size从6×6改为3x3。
·所有的C3模块改为C2f模块,如下图所示,多了更多的跳层连接和额外Split操作。。Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。
8.上下文引导网络(CGNet)简介
高准确率的模型(蓝点),由图像分类网络转化而来且参数量大,因此大多不适于移动设备。
低分辨率的小模型(红点),遵循分类网络的设计方式,忽略了分割特性,故而效果不好。
CGNet的设计:
为了提升准确率,用cgnet探索语义分割的固有属性。对于准确率的提升,因为语义分割是像素级分类和目标定位,所以空间依赖性和上下文信息发挥了重要作用。因此,设计cg模块,用于建模空间依赖性和语义上下文信息。
- 1、cg模块学习局部特征和周围特征形成联合特征
- 2、通过逐通道重新加权(强调有用信息,压缩无用信息),用全局特征改善联合特征
- 3、在全阶段应用cg模块,以便从语义层和空间层捕捉信息。
为了降低参数量:1、深层窄网络,尽可能节约内存 2、用通道卷积
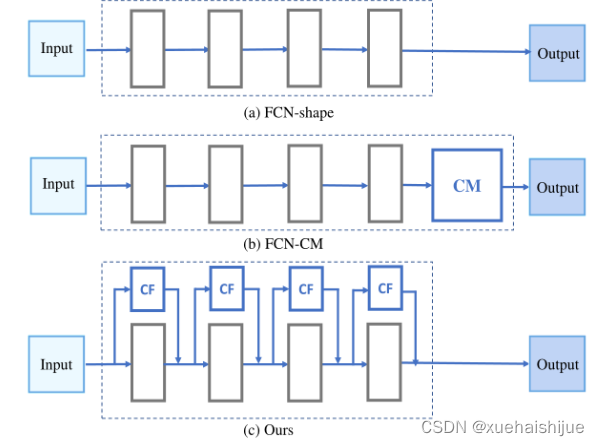
之前的网络根据框架可分三类:
- 1、FCN-shape的模型,遵循分类网络的设计,忽略了上下文信息 ESPNet、ENet、fcn
- 2、FCN-CM模型,在编码阶段后用上下文模块捕捉语义级信息 DPC、DenseASPP、DFN、PSPNet
- 3、(our)在整个阶段捕捉上下文特征
- 4、主流分割网络的下采样为五次,学习了很多关于物体的抽象特征,丢失了很多有鉴别性的空间信息,导致分割边界过于平滑,(our)仅采用三次下采样,利于保存空间信息
cg模块
Cg模块:
思路:人类视觉系统依赖上下文信息理解场景。
如图3,a, 如若仅关注黄色框框,很难分辨,也就是说,仅关注局部特征不容易正确识别目标的类别。 然后,如果加入了目标周围的特征,即图3,b,就很容易识别正确,所以周围特征对于语义分割是很有帮助的。在此基础上,如果进一步用整个场景的特征加以辅助,将会有更高的程度去争正确分类黄色框框的物体,如图3,c所示。 故,周围上下文和全局上下文对于提升分割精度都是有帮助的。
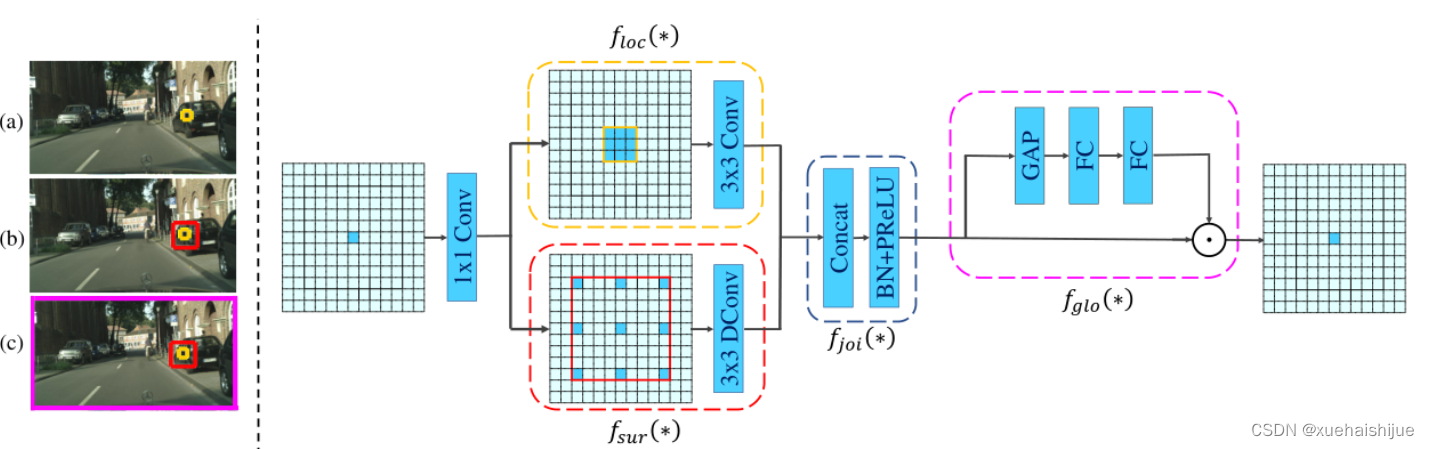
实现:基于此,提出cg模块,利用局部特征,周围上下文以及全局上下文。如图3,d所示。该模块共包含两个阶段。
第一步,floc( ) 局部和 fsur( )周围函数分别学习对应特征。floc( )用3x3卷积从周围8个点提取特征,对应于黄色框框;同时fsur( )用感受野更大的3x3带孔卷积学习周围上下文,对应红色框框。然后fjoi( )是指将前两路特征concat之后经BN,PReLU。此一部分是cg模块的第一步。
对于模块的第二步,fglo( )用于提取全局特征,改善联合特征。受SENet启发,全局上下文被认为是一个加权向量,用于逐通道微调联合特征,以强调有用元素、压缩无用元素。在本论文中,fglo( )用GAP产生聚合上下文特征,然后用多层感知机进一步提取全局上下文。最后,使用一个尺度层对联合特征重新加权用提取的全局上下文。
残差连接有利于学习更复杂的特征以及便于训练时梯度反向传播。两个拟设计方案,LRL局部残差连接和GRL全局残差连接,实验证明(消融实验),GRL效果更好
CGNet网络
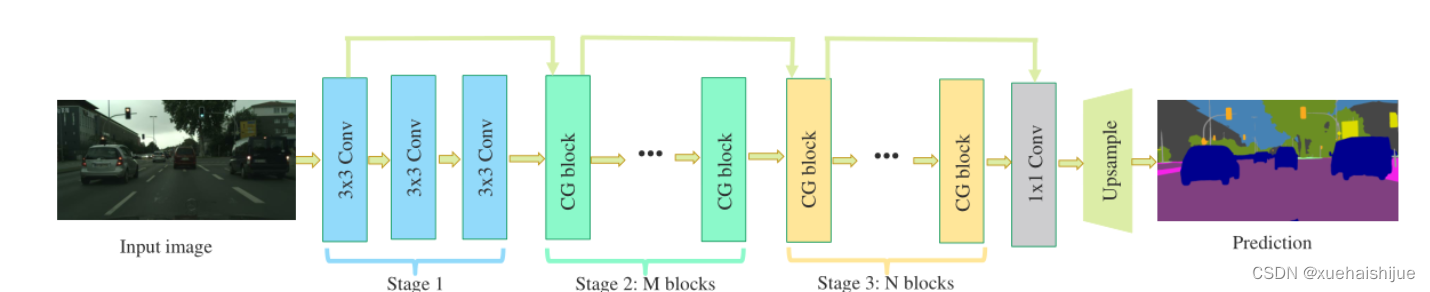
原则:深、瘦(deep and thin)以节省内存。层数少,通道数少,三个下采样。
Stage1,三个标准卷积层,分辨率变成原来的1/2
Stage2和stage3,分别堆叠M和N个cg模块。该两个阶段,第一层的输入是前一阶段第一个和最后一个block的结合(how结合)利于特征重用和特征传播。
将输入图像下采样到1/4和1/8分别输入到第2和3阶段。
最后,用1x1卷积层进行分割预测。
为进一步降低参数量,局部和周围特征提取器采用了逐通道卷积。之前有的工作在逐通道卷积后采用1x1卷积用以改善通道间的信息流动,本文消融实验显示效果不好,分析:因为cg模块中提取的局部和全局特征需要保持通道独立性,所以本论文不使用1*1卷积。
9.系统整合

参考博客《【改进YOLOv8】鸟类图像分类系统:引入上下文引导网络(CGNet)改进YOLOv8》
10.参考文献
[1]陆鑫伟,余鹏飞,李海燕,等.基于注意力自身线性融合的弱监督细粒度图像分类算法[J].计算机应用.2021,(5).DOI:10.11772/j.issn.1001-9081.2020071105 .
[2]罗建豪,吴建鑫.基于深度卷积特征的细粒度图像分类研究综述[J].自动化学报.2017,(8).DOI:10.16383/j.aas.2017.c160425 .
[3]Wei, Xiu-Shen,Xie, Chen-Wei,Wu, Jianxin,等.Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization[J].Pattern Recognition: The Journal of the Pattern Recognition Society.2018.76704-714.DOI:10.1016/j.patcog.2017.10.002 .
[4]Bo Zhao,Xiao Wu,Jiashi Feng,等.Diversified Visual Attention Networks for Fine-Grained Object Classification[J].Multimedia, IEEE Transactions on.2017,19(6).1245-1256.DOI:10.1109/TMM.2017.2648498 .
[5]Krizhevsky, Alex,Sutskever, Ilya,Hinton, Geoffrey E..ImageNet Classification with Deep Convolutional Neural Networks[J].Communications of the ACM.2017,60(6).84-90.DOI:10.1145/3065386 .
[6]Deng, Jia,Khosla, Aditya,Bernstein, Michael,等.ImageNet Large Scale Visual Recognition Challenge[J].International Journal of Computer Vision.2015,115(3).
[7]Uijlings, J.R.R.,Van De Sande, K.E.A.,Gevers, T.,等.Selective search for object recognition[J].International Journal of Computer Vision.2013,104(2).154-171.DOI:10.1007/s11263-013-0620-5 .
[8]Demi?ar, Janez,Schuurmans, Dale.Statistical Comparisons of Classifiers over Multiple Data Sets.[J].Journal of Machine Learning Research.2006,7(1).1-30.
[9]S, Hochreiter,J, Schmidhuber.Long short-term memory.[J].Neural computation.1997,9(8).1735-80.
[10]H. V. Henderson,S. R. Searle.On Deriving the Inverse of a Sum of Matrices[J].SIAM Review.1981,23(1).53-60.DOI:10.1137/1023004 .
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!