MapReduce分布式编程
目录
一、MapReduce概述
(一)MapReduce定义
????????MapReduce是一个分布式运算程序的编程框架,用于大规模数据集的并行处理,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
????????MapReduce将一个数据处理过程拆分为Map和Reduce两部分:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。开发人员只需通过编写Map和Reduce函数,不需要考虑分布式计算框架内部的运行机制,即可在Hadoop集群上实现分布式运算。引入MapReduce框架后,开发人员可将精力集中在业务逻辑的开发上,分布式计算的复杂性交由框架来处理。MapReduce把对数据集的大规模操作分发到计算节点,计算节点会周期性地返回其工作的最新状态和结果。如果节点保持沉默超过一个预设时间,主节点则标记该节点为死亡状态,并把已分配给这个节点的数据发送到别的节点重新计算,从而实现数据处理任务的自动调度。
MapRedcue分布式编程的主要步骤:

(1)编写Hadoop中org.apache.hadoop.mapreduce.Mapper类的子类,并实现map方法;
(2)编写Hadoop中org.apache.hadoop.mapreduce.Reducer类的子类,并实现reduce方法;
(3)编写main程序,设置MapReduce程序的配置,并指定任务的Map程序类(第一步的Java类)、Reduce程序类等(第二步的Java类),指定输入/输出文件及格式,提交任务等;
(4)将(1)~(3)的类文件与Hadoop自带的包打包为jar文件,并分发到Hadoop集群的任意节点;
(5)运行main程序,任务自动在Hadoop集群上运行;
(6)到指定文件夹查看计算结果。?
(二)MapReduce优缺点?
1、优点
(1)MapReduce易于编程
????????它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
(2)良好的扩展性
????????当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
????????MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
(4)适合PB级以上海量数据的离线处理
????????可以实现上千台服务器集群并发工作,提供数据处理能力。
2、缺点
(1)不擅长实时计算
????????MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
(2)不擅长流式计算
????????流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
(3)不擅长DAG(有向图)计算
????????多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
(三)MapReduce核心原理
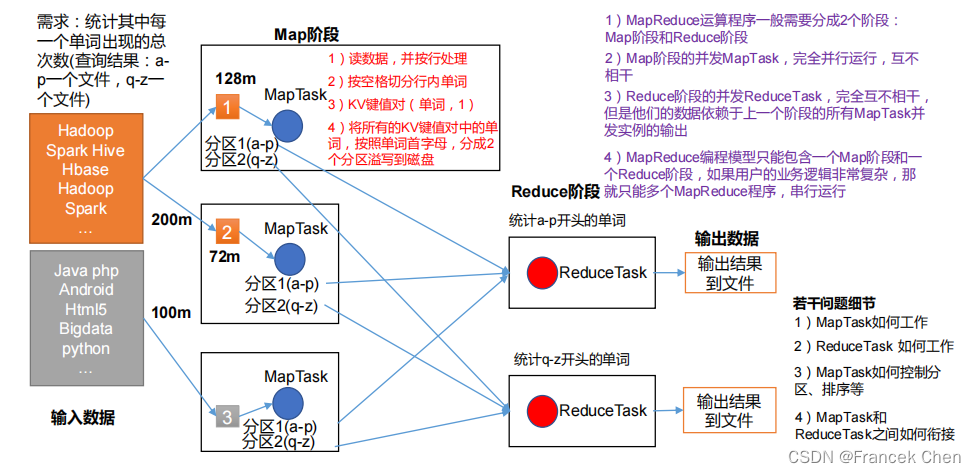
1、分布式的运算程序往往需要分成至少2个阶段。
2、第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3、第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4、MapReduce 编程模型只能包含一个Map阶段和一个 Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
二、MapReduce编程示例
1、首先,启动hdfs和yarn进程。
[root@bigdata mycode]# start-all.sh2、在家目录下创建文件夹mycode,在该文件下创建文件word.txt,并在该文件中输入如下内容:
[root@bigdata zhc]# mkdir mycode
[root@bigdata zhc]# cd mycode
[root@bigdata mycode]# pwd
/home/zhc/mycode
[root@bigdata mycode]# vi word.txthello world
hello hadoop
hello mapreduce
hadoop is good
3、 在HDFS系统中创建文件夹input,并将本地的word.txt文件上传到HDFS文件系统的/input目录下。
[root@bigdata mycode]# hdfs dfs -mkdir /input
[root@bigdata mycode]# hdfs dfs -put word.txt /input
2023-12-09 19:01:37,929 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[root@bigdata mycode]# hdfs dfs -ls /input
Found 1 items
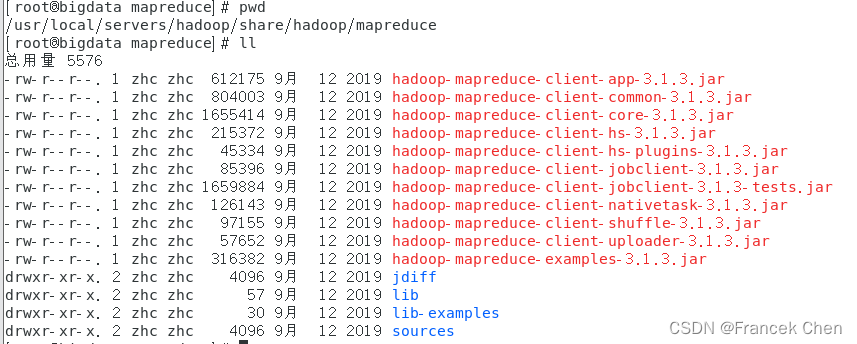
-rw-r--r-- ? 1 root supergroup ? ? ? ? 56 2023-12-09 19:01 /input/word.txt4、先切换到/hadoop/share/hadoop/mapreduce目录下,再使用hadoop-mapreduce-examples-3.1.3.jar程序对/input目录下的文件进行单词个数统计。(注意:指定输出结果的路径/output,该路径不能已存在)
[root@bigdata zhc]# cd /usr/local/servers/hadoop/share/hadoop/mapreduce
[root@bigdata mapreduce]# pwd
/usr/local/servers/hadoop/share/hadoop/mapreduce
[root@bigdata mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
5、输入命令查看HDFS文件系统中/output目录下的结果。
[root@bigdata mapreduce]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2023-12-09 19:16 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 49 2023-12-09 19:16 /output/part-r-00000
[root@bigdata mapreduce]# hdfs dfs -cat /output/part-r-00000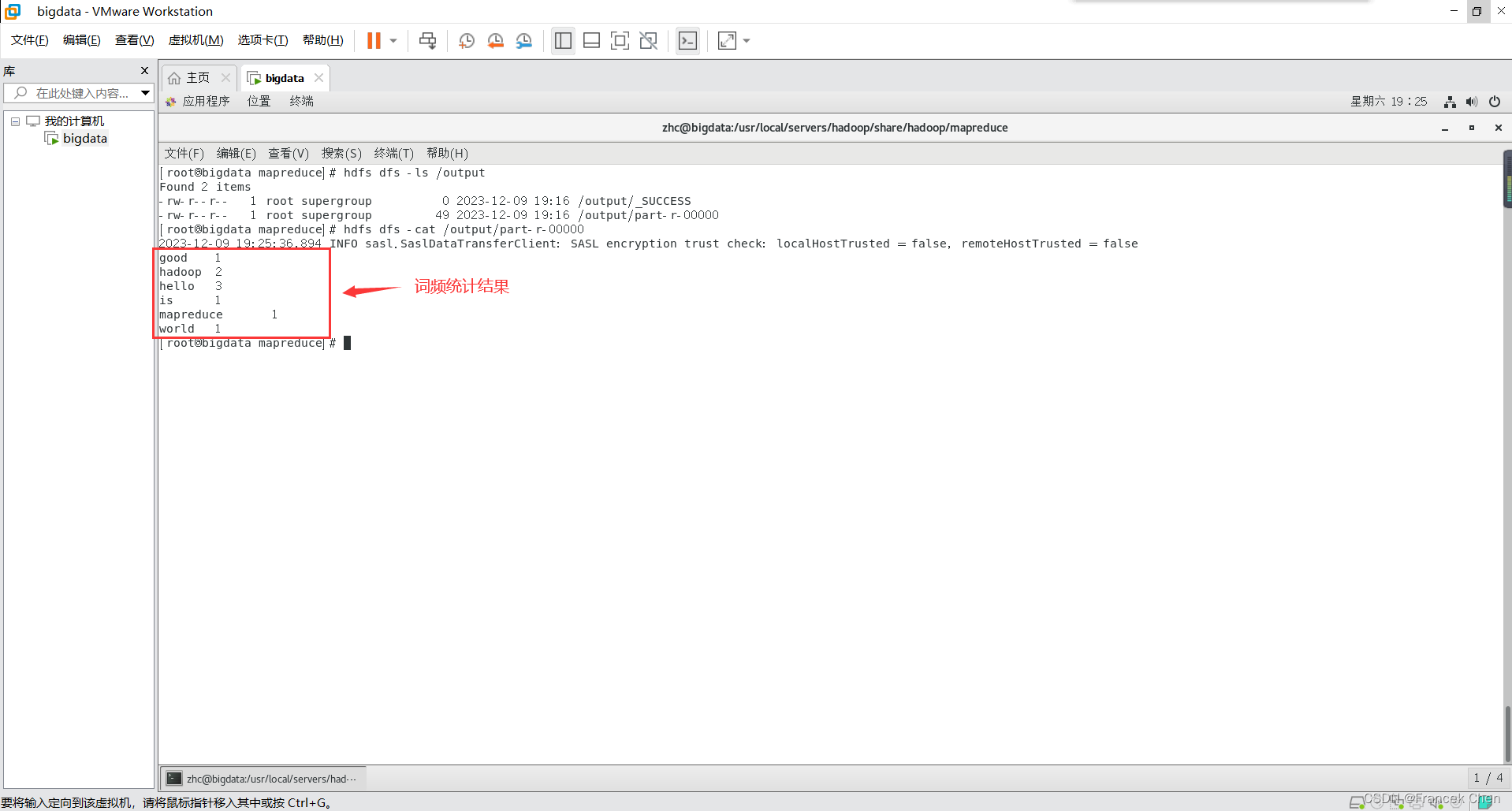
三、任务调度框架
????????对MapReduce编程,程序员只需关心map和reduce函数实现即可,有关文件IO,在集群中数据交换、任务调度问题都是由Hadoop?框架自动完成的。但理解MapReduce任务调度框架有助于开发高质量的应用程序,下面分别介绍Hadoop?2.0前后MapReduce任务调度模型。Hadoop?2.0前的调度模型我们称之为经典MapRedcue任务调度模型,或者MR?V1;当前主流的调度框架采用YARN,或者称为MR?V2。
(一)经典MapReduce任务调度模型
1、基本架构
????????经典MapReduce任务调度模型采用主从结构(Master/Slave),包含4个组成部分:Client、JobTracker、TaskTracker、Task。支撑MapReduce计算框架的是JobTracker和TaskTracker两类后台进程。基本框架结构如下所示:
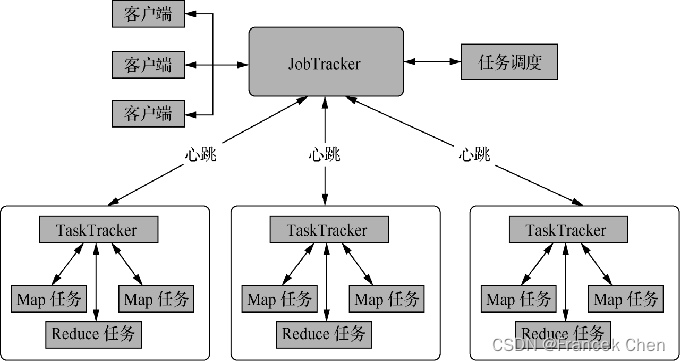
1、Client?
????????每一个Job在Client端将运行MapReduce程序所需要的所有Jar文件和类的集合,打包成一个Jar文件存储在HDFS中,并把文件路径提交到JobTracker。
2、JobTracker?
????????JobTracker主要负责资源的监控和作业调度,一个Hadoop集群只有一个JobTracker,并不参与具体的计算任务。根据提交的Job,JobTracker会创建一系列Task(即MapTask和ReduceTask),分发到每个TaskTracker服务中去执行。常用的作业调度算法主要包括FIFO调度器(默认)公平调度器、容量调度器等。
3、TaskTracker?
????????TaskTracker主要负责汇报心跳和执行JobTracker分发的任务。TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,JobTracker会根据心跳信息和当前作业运行情况为TaskTracker下达任务,主要包括启动任务、提交任务、杀死任务和重新初始化命令等。
4、Task?
????????Task分为MapTask和ReduceTask两种,均由TaskTracker启动,执行JobTracker分发的任务。MapTask解析每条数据记录,传递给用户编写的map函数并执行,最后将输出结果写入HDFS;ReduceTask从MapTask的执行结果中,对数据进行排序,将数据按分组传递给用户编写的reduce函数执行。
????????TaskTracker分布在Map-Reduce集群每个节点上,主要是监视所在机器的资源情况和当前机器的tasks运行状况。TaskTracker通过HeartBeat发送给JobTracker,JobTracker会根据这些信息给新提交的job分配计算节点。
????????经典MapReduce框架MR?V1模型简单直观,但是不能满足大规模集群任务调度的需要。主要表现为以下四点:
(1)JobTracker是MapReduce?的集中处理点,存在单点故障问题;
(2)当MapReduce?job非常多的时候,会造成很大的内存开销,就增加了JobTracker失败的风险,业界普遍认为该调度模型支持的上限为4000个节点;
(3)在TaskTracker端,以Map/Reduce?Task?的数目作为资源的表示过于简单,没有考虑到CPU/内存的占用情况,如果两个大内存消耗的Task被调度到一起,就很容易出现内存消耗殆尽的问题;
(4)TaskTracker把资源强制划分为Map?Task?Slot和Reduce?Task?Slot,如果当系统中只有Map?Task?或者只有Reduce?Task时,会造成资源的浪费,导致集群资源利用不足。
2、工作流程
????????MapReduce运行阶段数据传递经过输入文件、Map阶段、中间文件、Reduce阶段、输出文件五个阶段,用户程序只与Map阶段和Reduce阶段的Worker直接相关,其他事情由Hadoop平台根据设置自行完成。

从用户程序User Program开始,用户程序User Program链接了MapReduce库,实现了最基本的map函数和reduce函数。
(1)MapReduce库先把User Program的输入文件划分为M份(M为用户定义),每一份通常16MB~64MB,如图4.5左方所示将数据分成了分片0~4;然后使用fork将用户进程复制到集群内其他机器上。
(2)User Program的副本中有一个称为Master,其余称为Worker,Master是负责调度的,为空闲Worker分配作业(Map作业或者Reduce作业),Worker的数量也是可以由用户指定的。
(3)被分配了Map作业的Worker,开始读取对应分片的输入数据,Map作业数量是由输入文件划分数M决定的,和分片一一对应;Map作业将输入数据转化为键值对表示形式,传递给map函数,map函数产生的中间键值对被缓存在内存中。
(4)缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给Master,Master负责将信息转发给Reduce Worker。
(5)Master通知分配了Reduce作业的Worker负责数据分区,Reduce Worker读取键值对数据并依据键排序,使相同键的键值对聚集在一起。注意,同一个分区可能存在多个键的键值对,而reduce函数的一次调用的键值是唯一的,所以必须进行排序处理。
(6)Reduce Worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会写回到数据分区的输出文件中。
(7)当所有的Map和Reduce作业都完成了,Master唤醒User Program,MapReduce函数调用返回User Program。
(二)Yarn资源调度器
????????为了从根本上解决经典MapReduce框架的性能瓶颈,Hadoop的MapReduce框架完全重构,叫做Yarn或者MR?V2。Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
1、基本架构
????????Yarn的基本思想就是将经典调度框架中JobTracker的资源管理和任务调度/监控功能分离成两个单独的组件,即一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。ResourceManager?负责整个系统资源的管理和分配,而ApplicationMaster?则负责单个应用程序的资源管理。
????????Yarn调度框架包括ResourceManager、?ApplicationMaster、?NodeMananger及Container等组件概念。下图为Yarn基本架构。
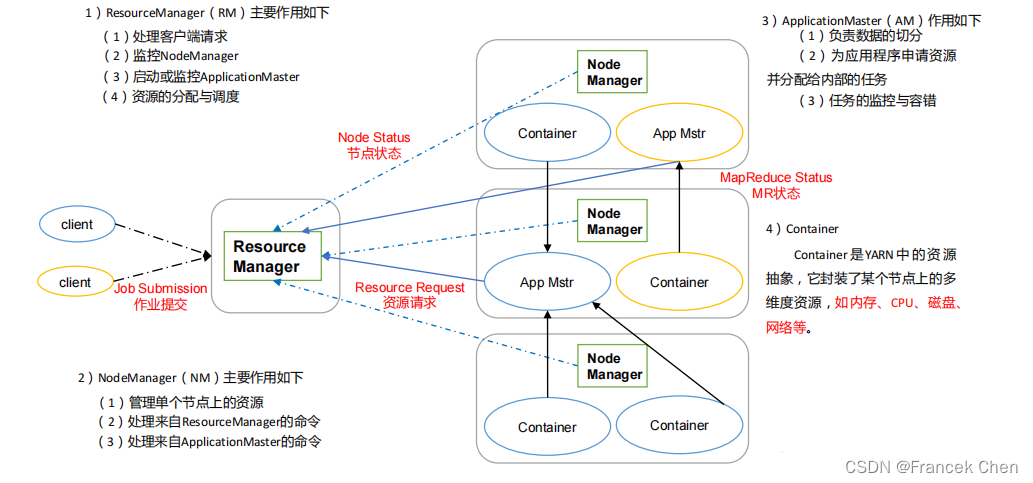
????????ResourceManager是基于应用程序对资源的需求进行调度的。每一个应用程序需要不同类型的资源,因此就需要不同的容器。这些资源包括内存、CPU、磁盘、网络等。
????????ApplicationMaster负责向调度器申请、释放资源,请求Node?Manager运行任务、跟踪应用程序的状态和监控它们的进程。
????????NodeManager是Yarn中单个节点的代理,负责与应用程序的ApplicationMaster和集群管理者ResourceManager交互;从ApplicationMaster上接收有关Container的命令并执行(例如,启动、停止Container);向ResourceManager汇报各个Container执行状态和节点健康状况,并读取有关Container?的命令;执行应用程序的容器、监控应用程序的资源使用情况并且向ResourceManager?调度器汇报。
????????Container是Yarn中资源的抽象,它封装了节点上一定量的资源(CPU和内存等)。一个应用程序所需的Container分为两类:一类是运行ApplicationMaster?的Container,是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;另一类是运行各类任务的Container,是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信后启动。
2、工作流程
????????用户向Yarn提交一个应用程序后,Yarn将分为两个阶段运行该应用程序:第一个阶段是启
动ApplicationMaster;第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行成功。
????????Yarn任务调度流程如图所示。

(1)用户向Yarn提交应用程序;
(2)ResourcelManager为该应用程序在某个NodeManager分配一个Container,并要求Nodemanger?启动应用程序的ApplicationMaster;
(3)ApplicationMaster启动后立即向ResourceManager注册,此时用户可以直接通过Resource?Manager查看应用程序的运行状态,然后它将为各个任务申请分布在某Nodemanager上的容器资源,并监控它的运行状态(步骤(4)~(7)),直到运行结束;
(4)ApplicationMaster采用轮询的方式向ResourceManager申请和领取资源;
(5)ApplicationMaster申请到资源后,即与资源容器所在的NodeManager通信,要求其在容器
内启动任务;
(6)NodeManager为任务初始化运行环境(包括环境变量、jar包、二进制程序等),启动任务;
(7)运行各个任务的容器通过向ApplicationMaster汇报自己的状态和进度,使ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。用户可以向ApplicationMaster查询应用程序的当前运行状态;
(8)应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭。
Yarn框架和经典的MR V1调度框架相比,主要有以下优化。
(1)ApplicationMaster使得检测每一个Job子任务状态的程序分布式化,减少了JobTracker资源消耗;
(2)在Yarn中,用户可以对不同的编程模型写自己的ApplicationMaster,可以让更多类型的编程模型运行在Hadoop集群上,如Spark基于内存的计算模型。
(3)Container提供Java虚拟机内存的隔离,优化了经典调度框架中Map?Slot和Reduce?Slot分
开造成集群资源闲置的不足。
四、MapReduce的数据类型
????????MapReduce运算将完成的Map任务的计算结果发送给Reduce任务,Reduce收到任务后进行规约计算。Map和Reduce任务多数情况分布在不同的计算节点上,这就要求在网络上传递可序列化的Java对象。对象序列化是指把Java对象转化成字节序列的过程,反序列化是把字节序列转化成对象。Hadoop重新定义Java中常用的数据类型,并让它们具有序列化的特点。
| Java基本类型 | Hadoop封装的类型 | 说明 |
|---|---|---|
| byte | ByteWritable | 单字节数值 |
| int | IntWritable | 整型数值 |
| long | LongWritable | 长整型数值 |
| float | FloatWritable | 浮点型数值 |
| double | DoubleWritable | 双字节数值 |
| boolean | BooleanWritable | 标准布尔型数值 |
| String | Text | UTF8格式存储的文本 |
五、MapReduce的文件输入/输出格式
(一)输入格式
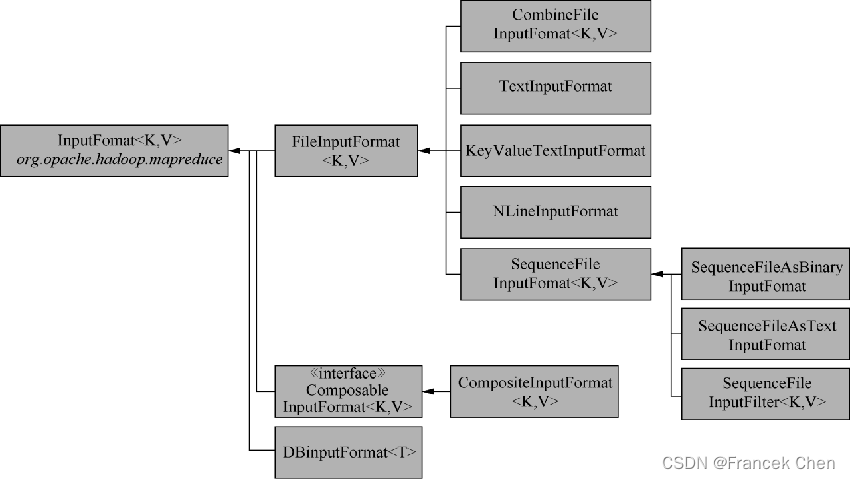
????????Map任务处理的输入块称为输入分片(Split),每个分片被划分为若干条记录,每条记录就是一个键值对,map函数一个接一个地处理记录。输入分片在Java中被表示为InputSplit抽象类的子类的对象。
?
1、FileInputFormat类
????????FileInputFormat是所有文件作为数据源的InputFormat的实现类,主要有两个功能:指定输入文件位置和输入文件生成分片的实现代码段。换句话说,它并不生成分片,只是返回文件位置,并且实现了分片算法。 FileInputFormat提供了四种静态方法指定Job输入路径:
Public static void addInputPath(Job job,Path path);
Public static void addInputPaths(Job job,String paths);
Public static void setInputPaths(Job job,Path ...inputPaths);
Public static void setInputPaths(Job job,String paths);? ? ? ? 其中,addInputPath()和addInputPaths()方法可以将一个或多个路径加入到路径列表,可以调用这两种方法建立路径列表。setInputPaths()方法一次设定完整的路径列表,其中路径可以是一个文件、一个目录,或者一个glob(即一个文件和记录的集合),当路径是一个目录时表示包含目录下的所有文件。
2、TextlnputFormat类
????????TextlnputFormat是FileInputFormat的子类,文本文件的每一行数据就是一条记录。TextlnputFormat的key是LongWritable类型的,存储该行在整个文件的偏移量,value是Text类型,存储该行的内容。
????????使用TextlnputFormat类时,reduce函数的键为每行在文件中的字节偏移量。有时候文件的每一行是一个使用某个分界符进行分割的键值对。此时,可以使用KeyValueTextlnputFormat。可以通过mapreduce.input.keyvaluelinerecordreader.key.value.seperator属性指定分隔符。默认是一个制表符,其中这个键是分隔符前的文本,值是分隔符后的文本,其类型都是text类型。如:
key1:this is first line text
key2:this is second line text键、值的分隔符为“:”,则通过KeyValueTextInputFormat读取后,文件被分为两条记录,分别是:
(key1,this is first line text)
(key2,this is second line text) ?3、NLineInputFormat类
????????在TextInputFormat和KeyValueTextInputFormat中,每个Map任务收到的输入行数并不确定,行数取决于输入分片的大小和行的长度。如果希望Map收到固定行数的输入,可以使用NLineInputFormat作为InputFormat。与TextInputFormat一样,键是文件中行的字节偏移量,值是行的内容。N是每个Map任务收到的输入行数,默认是1。可以通过mapreduce.input.lineinputformat.linespermap属性设置。以4行输入为例:
Life is a journey
not the destination
but the scenery along the should be
and the mood at the view.当N=2时,每个输入分片包含两行。一个Map任务收到前两行键值对:
(0,Life is a journey)
(17,not the destination)另一个Map任务收到后两行键值对:
(37,but the scenery along the should be)
(72,and the mood at the view.)4、SequenceFileInputFormat类
????????当需要使用顺序文件作为MapReduce的输入时,应该使用SequenceFileInputFormat。键和值由顺序文件指定,只需要保证Map输入的类型匹配。例如,输入文件中键的格式是DoubleWritable,值是Text,则Mapper的格式应该是Mapper<DoubleWritable,Text,K,V>,K和V是Mapper输出的键和值的类型。SequenceFileAsTextInputFormat是SequenceFileInputFormat的变体,将顺序文件的键和值转化为Text对象;SequenceFileAsBinaryInputFormat是SequenceFileInputFormat的一种变体,获取顺序文件的键和值作为二进制对象。
(二)输出格式
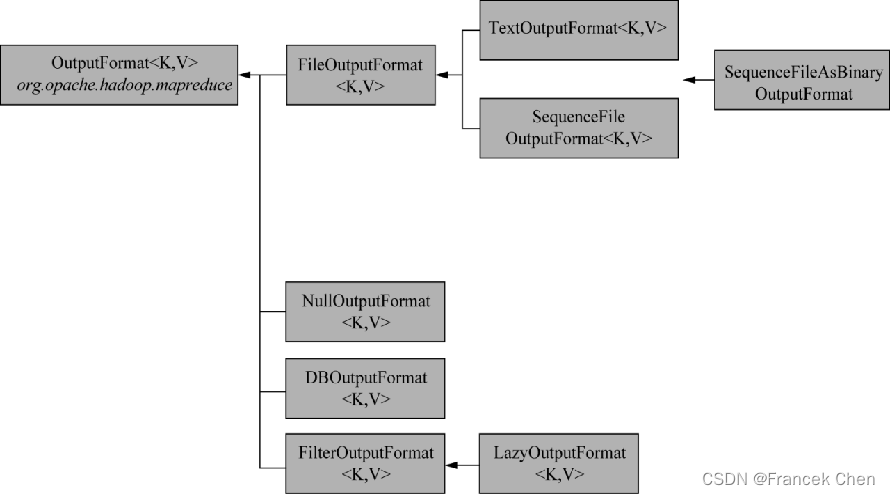
OutputFormat类的层次结构图:
?
1、TextOutputFormat类
????????TextOutputFormat是默认的输出格式,每条记录写为一行。键和值可以是任意类型,因为TextOutputFormat要调用toString()把它们转换为字符串。键值默认使用制表符分割,可以使用mapreduce.output.textoutputformat.separator属性改变分割符。与TextOutputFormat对应的输入格式是KeyValueTextInputFormat,通过可配置的分隔符将键值对文本行分隔。
2、SequenceFileOutputFormat类
????????将输出写为一个顺序文件,当输出需要作为后续的MapReduce输入的时候,这种输出非常合适,因为它格式紧凑,容易被压缩。SequenceFileAsBinaryOutputForamt与SequenceFileAsBinaryInputFormat对应,将输出的键和值作为二进制格式写到SequenceFile容器中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!