MySQL HeatWave Lakehouse
在今年的Oracle Cloud World,Oracle宣布将发布一款数据库湖仓产品——MySQL HeatWave Lakehouse用以解决存储在数据库之外的文件数据等非结构化数据的查询和处理。
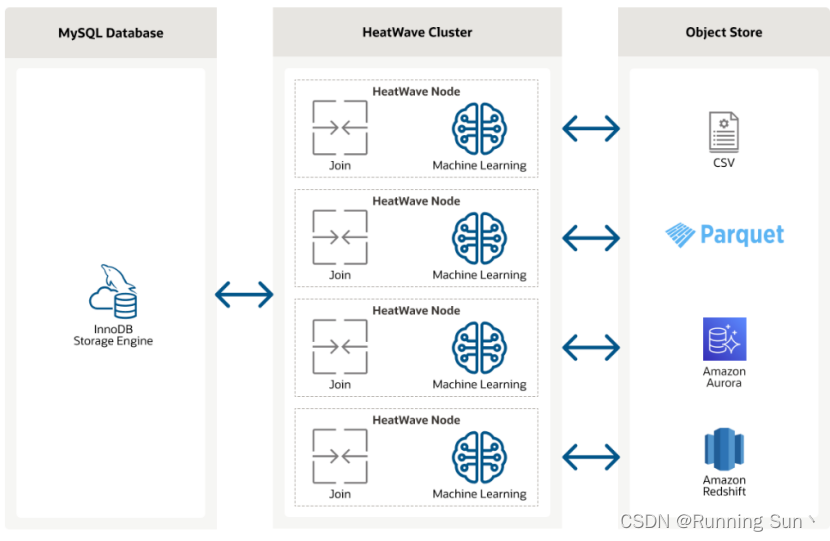
MySQL HeatWave是一个完全管理的数据库服务,将事务处理、分析处理和机器学习服务合并到一个MySQL数据库的云服务,提供简单、实时、安全的分析,无需ETL,并且没有延迟。
IDC预测,保存在数据库之外的文件数据的将呈爆发式增长,产生的数据从2021年的79 ZB到2025年的180 ZB,数据增长将超过一倍,其中99.5%的数据都未被利用,因为没有能够有效处理这些数据的服务。
MySQL HeatWave扩展到MySQL HeatWave Lakehouse,让用户能够处理和查询保存在云对象存储中的数百TB使用文件格式的数据,如CSV、Parquet和Aurora/Redshift备份文件。客户使用标准的MySQL命令既可以查询MySQL数据库中的事务性数据,又可以查询对象存储中各种格式的数据,或者将两者结合进行查询,并能够做到查询数据库中的数据与查询对象存储中的数据速度一样快。
MySQL HeatWave集群可扩展到512个节点,MySQL HeatWave Lakehouse允许客户查询高达400TB的数据。400 TB TPC-H基准测试证明MySQL HeatWave Lakehouse的查询性能比Snowflake快17倍,比Amazon Redshift快6倍。加载性能比Amazon Redshift快8倍,比Snowflake快2.7倍。
MySQL HeatWave Lakehouse现在已经发布了测试版供客户试用,计划在2023年上半年全面上市。
1.MySQL HeatWave Lakehouse介绍
MySQL HeatWave Lakehouse除了具有MySQL HeatWave的优势,还提供了以下功能:
1).向外扩展的体系结构,可以快速摄取、管理和执行查询,最多可处理400 TB的数据,同时可以将HeatWave集群扩展到512个节点。
2).MySQL Autopilot,将常见的数据管理任务自动化,包括半结构化数据的自动模式推断和自动加载。
3).数据库和数据湖数据的统一查询引擎。
4).MySQL HeatWave Lakehouse自动将所有数据源转换为单一优化的内部格式。提供了优化和执行查询的能力,无论使用哪种数据源(InnoDB存储引擎中的数据或数据湖中的数据,例如CSV和Parquet格式的数据),都能获得一致的高性能。
5).无需对MySQL进行任何更改,MySQL HeatWave Lakehouse 100%符合MySQL语法。
6).高可用的托管数据库服务,它可以在计算节点故障的情况下自动恢复加载到HeatWave集群中的数据——无需从外部数据格式重新转换。
7).高效地使用集群内存,通过自动压缩相关列,提供高达2倍的压缩比——确保用户从所提供的HeatWave集群中获得最大收益。
8).安全的访问控制方法(如Pre-Authenticated Request (PAR)?或OCI Resource Principal机制)对数据湖源的访问进行完全控制。
2.端到端的扩展架构
MySQL HeatWave Lakehouse由一个大规模并行、高性能、内存查询处理引擎提供动力,优化后可以在节点集群中管理0.5PB级的数据大小。设计一个向外扩展的湖仓系统,不仅需要向外扩展查询处理,还需要将半结构化数据加载并转换为HeatWave的混合列格式。一旦转换成HeatWave内部格式,外部数据就可以大规模被HeatWave并行内存查询处理引擎使用。此外,还需面临如何扩展数据摄取,以及如何将多种文件格式高效地转换为混合列内存数据等挑战。因此,开发团队设计了HeatPump,这是一个大规模并行和可扩展的数据转换引擎,它充分利用集群中的所有节点和核心,提供一个真正向外扩展的湖仓架构。
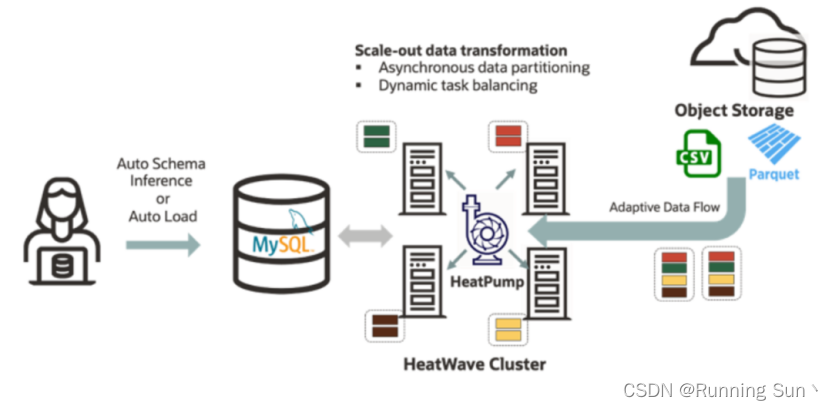
3.HeatPump经过精心优化,通过以下方式随着节点和数据大小的增加有效地向外扩展:
分布式跨集群扩展数据读取和转换任务,在执行数据驱动的分区时可能会遇到挑战。通过引入虚拟分区的超级分块(super chunking)进程,HeatPump进行了优化,以避免节点间的任何同步。
跨集群的动态任务负载平衡,通过确保集群中没有CPU核心处于空闲状态,从落后节点移取任务,避免掉队。
自适应数据流控制,协调利用跨大型节点集群的对象存储的网络带宽。如果没有自适应的数据流控制,单个节点的过多读请求将导致可伸缩性变差。
4.MySQL Autopilot新功能(适用于MySQL HeatWave Lakehouse)
MySQL Autopilot为MySQL HeatWave提供基于机器学习的自动化。现有的MySQL Autopilot功能,如自动配置和自动查询计划改进已经为MySQL HeatWave Lakehouse进行了增强,进一步减少了数据库管理开销并提高了性能。
当涉及到数据湖时,常见的数据湖文件格式可能不是结构化的,而且通常为此类数据源定义严格的数据模型也不是一件容易的事。具体来说,CSV是半结构化文件的一个很好的例子,其中列类型没有在文件中预定义。如果没有相关经验,用户通常会选择保守的数据类型和大小,这会造成浪费或无法达到最优的查询性能(例如,对所有类型使用varchar)。使用MySQL Autopilot,该过程是完全自动化和数据驱动的,消除了用户的猜测(如下所述)。
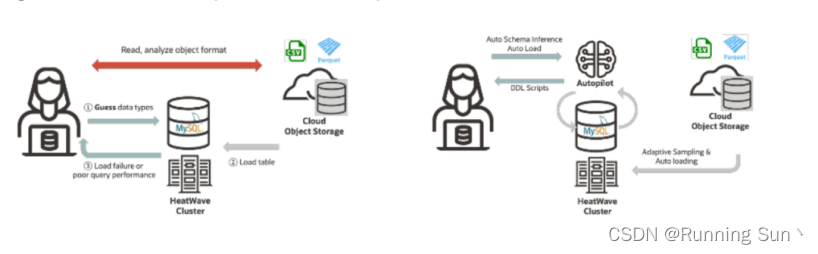
MySQLMySQL Autopilot追加了新功能用于MySQL HeatWave Lakehouse。
自动模式推断:Autopilot自动推断文件数据到数据库中的数据类型的映射。用户不需要手动为MySQL HeatWave lakehouse查询的每个新文件指定映射,从而节省了时间和精力。
自适应数据采样:Autopilot对象存储中的文件部分智能采样,以最小的数据访问收集准确的统计数据。MySQL HeatWave使用这些统计信息来生成和改进查询计划,用于确定最佳模式映射。
自动加载:Autopilot分析数据,预测加载到MySQL HeatWave的时间,确定数据类型的映射,并自动生成加载脚本。用户不必手动指定文件到数据库模式和表的映射。
自适应数据流:MySQL HeatWave Lakehouse动态适应底层对象存储的性能。因此,MySQL HeatWave可以从底层云基础设施中获得最大的可用性能,从而提高整体性能、价格优势和可用性。
5.MySQL HeatWave Lakehouse的性能
官方提供了数据的加载性能测试和查询性能测试。
4小时内向对象存储中加载400TB数据
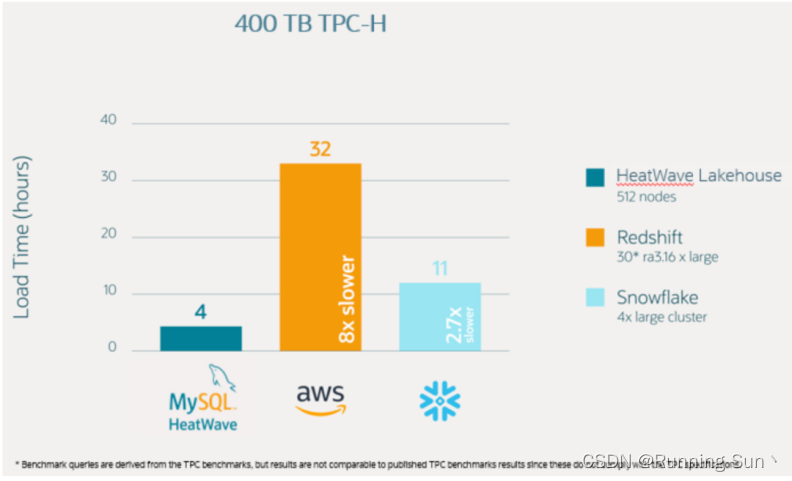
通过一个完全透明的、公开的400 TB TPC-H*基准测试,MySQL HeatWave Lakehouse的加载性能比Amazon Redshift快8倍,比Snowflake快2.7倍。
HeatPump进程的向外扩展架构完美地划分、平衡任务,并利用每一个可用的CPU核心来获得外部文件的查询准备。HeatPump保证了集群中所有512个节点的同时使用,保证了强大的可扩展性。
运行400TB查询——平均42秒
将数据转换为我们专有的混合列格式后,就可以查询外部表。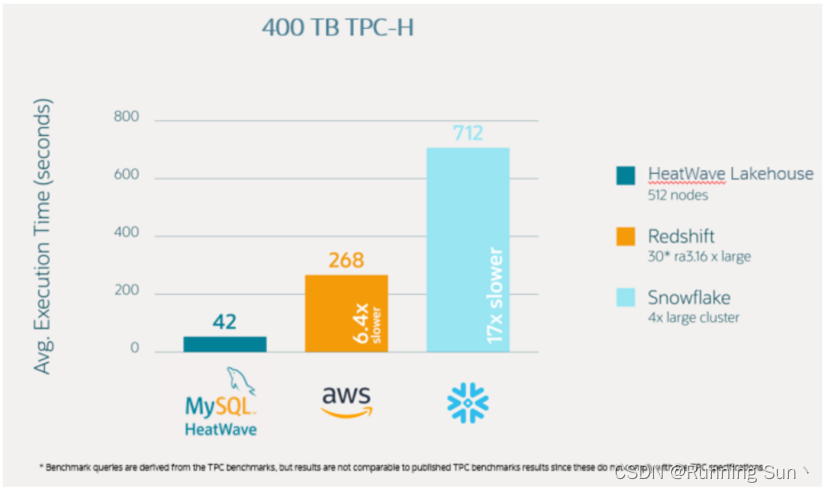
400 TB TPC-H基准测试所示,MySQL HeatWave Lakehouse的查询性能为比Snowflake快17倍,比Amazon Redshift快6倍。
6.查询性能提高了几个数量级,甚至对于大规模的数据湖也是如此,主要有三个原因:
1).MySQL HeatWave查询引擎是大规模并行和高度可扩展的,充分利用集群中的每个核心。
2).在MySQL Autopilot的帮助下,已经准确地识别了半结构化数据集中每一列的数据类型,提高查询处理性能。
3).尽管HeatWave在大型集群的内存中维护所有数据,但对数据进行显著的压缩。
我们正面临着保存在数据库之外的巨大数据增长(社交媒体文件、来自物联网传感器的数据等),企业希望利用这些数据快速生成新的业务驱动。使用MySQL HeatWave Lakehouse,用户可以在对象存储中的数据上利用HeatWave的所有优势,为事务处理、跨数据仓库和数据湖的分析和机器学习提供了无需跨云进行ETL的云服务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!