爬虫实例:链家二手房数据爬取
爬虫实例:链家二手房数据爬取
? 需求:根据用户所选省份及城市爬取对应的二手房数据及图片,并将数据保存到excel中,图片保存到文件夹中,得到的数值类型的单价、总价和关注度,并画出单价与关注度,总价与关注度的图像,并找出关注度最高的二手房单价和总价。
? 链接:链家
1、爬取一级页面的省份及城市信息
1.1解析省份信息
? 浏览器F12打开开发者工具,选择document类型
? 拿到标头的User-Agent内容,在响应中搜索一个省份,得到如下图的内容
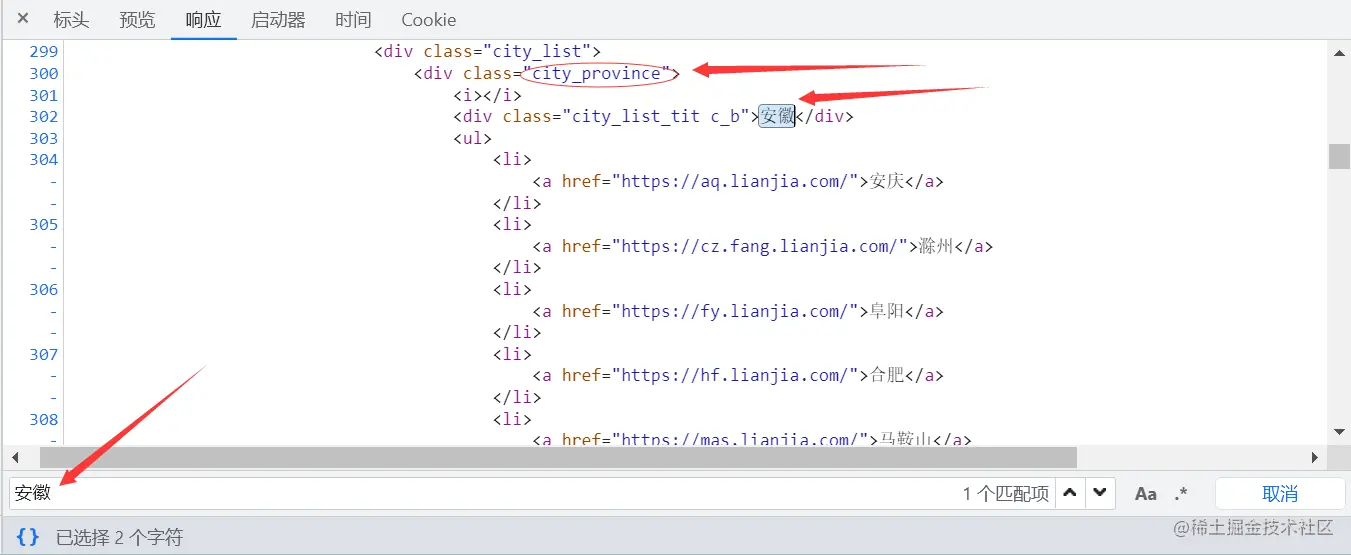
? 多次查找可以发现规律,省份信息在class属性为city_province的div下的一个div文本里,因此可以写出下面的beautifulsoup4解析语法,得到的是一个序号对应省份的字典数据,以便用户选择
# 解析主页面的省份信息,返回序号与省份的字典
def analyse_province(data):
bs_data = BeautifulSoup(data, 'lxml')
provinces_data = bs_data.find_all('div', {'class': 'city_list_tit c_b'})
provinces = {}
for i in range(len(provinces_data)):
provinces[i] = (provinces_data[i].string)
return provinces
# analyse_province函数返回的内容
{0: '安徽', 1: '北京', 2: '重庆', 3: '福建', 4: '广东', 5: '广西', 6: '贵州', 7: '甘肃', 8: '河北', 9: '海南', 10: '湖南', 11: '河南', 12: '湖北', 13: '黑龙江', 14: '江西', 15: '江苏', 16: '吉林', 17: '辽宁', 18: '内蒙古', 19: '宁夏', 20: '山东', 21: '四川', 22: '陕西', 23: '山西', 24: '上海', 25: '天津', 26: '新疆', 27: '云南', 28: '浙江'}
1.2解析城市信息
? 接着根据用户所选省份解析出该省份下的城市
# 解析所选省份的城市信息,返回序号与城市的字典及经过处理的城市二手房网址
def analyse_city(data, province):
bs_data = BeautifulSoup(data, 'lxml')
# 根据所选省份得到源码中省份的整个div内容
p_data = bs_data.find_all('div', {'class': 'city_province'})[province]
x_data = etree.HTML(str(p_data))
# 用xpath语法对得到的div进行解析,得到该省份下的城市和主页链接
city_list = x_data.xpath('//div[@class="city_province"]/ul/li/a/text()')
urls = x_data.xpath('//div[@class="city_province"]/ul/li/a/@href')
citys = {}
for i in range(len(city_list)):
citys[i] = city_list[i]
# 这里作这样的处理是为了二级页面直接是二手房板块
urls[i] = urls[i] + 'ershoufang/pg{}/'
return citys, urls
? 这个函数返回的链接是经过处理的,主要是以便后续的爬取,简化爬取的流程。因为爬取的只是单个城市的二手房板块,分析多个城市的二手房链接可以发现,每个城市二手房板块都有ershoufang/的后缀。而pg{}/是便以爬取多页所做的操作,因为有pg1/和没有pg1/都是会跳转到第一页的,如aq.lianjia.com/ershoufang/…
1.3解析页数
? 接下来就要获取所选城市的二手房数据的页数了,查找可以得到页数的数据所在的位置

? 上图是在元素界面中找到的,但我们爬取的数据不是这样的,下图是实际得到的数据所在的位置

? 这里的totalPage数据才是我们爬到的真正形式,因此可以写出下面获取页数的函数
# 获取所爬城市页面的页数
def get_page(data):
x_path = etree.HTML(data)
total_page = x_path.xpath('//div[@class="page-box fr"]/div/@page-data')
# 上面得到是{"totalPage":100,"curPage":1}的数据,得到页数还要进一步解析
page = re.match(r'.*?talPage":(.*?),"curPage', str(total_page))
return int(str(page.group(1))) # 以int类型返回,直接用在循环中
? 得到页数后就可以循环爬取了
2、爬取二级页面的二手房信息
? 因这部分中每一小部分的代码是紧密联系的,所以代码会放在这部分最后
2.1解析二手房标题和链接
? 查找发现二手房的标题都是以下面的形式在html代码里的,这里的有我们需要的标题和链接
<div class="title">
<a class="" href="https://aq.lianjia.com/ershoufang/103126425051.html" target="_blank" data-log_index="22" data-el="ershoufang" data-housecode="103126425051" data-is_focus="" data-sl="">婚房装修,户型方正,满五税费低,看房方便,诚心出售</a>
<span class="goodhouse_tag tagBlock">必看好房</span>
</div>
2.2解析二手房详情信息
? 同样将要爬取的信息找出来,这里有需要的户型,面积信息
<div class="address">
<div class="houseInfo">
<span class="houseIcon"></span>
2室1厅 | 80平米 | 南 北 | 精装 | 中楼层(共11层) | 板塔结合
</div>
</div>
2.3解析二手房关注度信息
? 这里的关注人数要解析,同时发布的时间也要解析出来
<div class="followInfo">
<span class="starIcon"></span>
0人关注 / 14天以前发布
</div>
2.4解析图片链接
? 经检查可以得知第二个img标签中的data-original属性的内容是图片的网址
<a class="noresultRecommend img LOGCLICKDATA" href="https://aq.lianjia.com/ershoufang/103126266829.html" target="_blank" data-log_index="21" data-el="ershoufang" data-housecode="103126266829" data-is_focus="" data-sl="">
<!-- 热推标签、埋点 -->
<img src="https://s1.ljcdn.com/feroot/pc/asset/img/vr/vrlogo.png?_v=20230510102110" class="vr_item">
<img class="lj-lazy" src="https://s1.ljcdn.com/feroot/pc/asset/img/blank.gif?_v=20230510102110" data-original="https://image1.ljcdn.com/110000-inspection/pc1_AXUil88p4_1.jpg.296x216.jpg" alt="安庆迎江区龙狮桥乡">
</a>
? 得到链接后向图片链接发起请求,得到图片的二进制数据并保存,图片的名字以爬到的标题命名。要注意的是,图片的命名不能含有某些特定的字符,要将这些字符去除。还有些二手房的图片信息还没有,所以也要加上一个异常处理的代码。
# 向图片链接发起请求,保存图片
def save_png(png_url, title):
name = str(title.string)
# 图片命名不能有以下字符,所以要将这些字符去除
if '*' in name:
name = name.replace('*', '')
if '\\' in name:
name = name.replace('\\', '')
if '/' in name:
name = name.replace('/', '')
if ':' in name:
name = name.replace(':', '')
if '?' in name:
name = name.replace('?', '')
if '"' in name:
name = name.replace('"', '')
if '<' in name:
name = name.replace('<', '')
if '>' in name:
name = name.replace('>', '')
if '|' in name:
name = name.replace('|', '')
# 创建保存图片的文件夹
if not os.path.exists('{}png'.format(citys[city_ind])):
os.makedirs('{}png'.format(citys[city_ind]))
else:
# 尝试向图片发起请求,因有些网站中出现图片拍摄中的情况,这样写避免程序终止
try:
png_data = requests.get(png_url, headers).content
with open('{}png/'.format(citys[city_ind]) + name + '.jpg', 'wb') as f:
f.write(png_data)
except:
print('爬取图片错误,错误位置:', name)
2.5解析二手房总价
<div class="totalPrice totalPrice2">
<i></i>
<span class="">98</span>
<i>万</i>
</div>
2.6解析二手房单价
<div class="unitPrice" data-hid="103126266829" data-rid="8827132282022856" data-price="8089">
<span>8,089元/平</span>
</div>
? 这里可以发现span标签中的文本是我们想要的内容,同时也发现div的data-price属性的值也是单价,这里我一开始用了直接解析data-price属性值,但到爬取到某些城市时发现data-price的值有些是0,而span中的文本确实是正常的,所以最后直接解析span中的文本更靠谱。
# 解析房屋户型信息
def get_model(infor):
model = re.match('^(.*?)\s', infor)
return model.group(1)
# 解析房屋面积信息
def get_area(infor):
area = re.match('^(.*?)\s\|\s(.*?)\s\|\s', infor)
return area.group(2)
# 解析房屋关注度信息
def get_follow(atten):
follow = re.match('^(\d+)人关注', atten)
return follow.group(1)
# 解析房屋发布时间信息
def get_day(atten):
day = re.match('.*?关注\s/\s(.*?)$', atten)
return day.group(1)
# 解析单价
def get_unitprice(up):
p = re.match('^(\d+),(\d+)元/平$', up)
return int(str(p.group(1))+str(p.group(2)))
# 解析所选城市的单页信息,返回所有信息综合的二维列表
def analyse_house(data):
val = BeautifulSoup(data, 'lxml')
titles = val.find_all('a', {'target': '_blank', 'data-el': 'ershoufang'})[1::2]
x_val = etree.HTML(data)
pngs = x_val.xpath('//img[@class="lj-lazy"]/@data-original')
prices = val.find_all(class_='totalPrice totalPrice2')
infors = x_val.xpath('//div[@class="houseInfo"]/text()')
attens = x_val.xpath('//div[@class="followInfo"]/text()')
ups = x_val.xpath('//div[@class="unitPrice"]/span/text()')
information = [[], [], [], [], [], [], [], []]
for title, p, infor, atten, png, up in zip(titles, prices, infors, attens, pngs, ups):
information[0].append(title.string) # 地址
information[1].append(get_model(infor)) # 户型
information[2].append(get_area(infor)) # 面积
information[3].append(get_unitprice(up)) # 单价
information[4].append(float(str(p.span.string))) # 总价
information[5].append(int(get_follow(atten))) # 关注度
information[6].append(get_day(atten)) # 发布时间
information[7].append(title['href']) # 链接
save_png(png, title) # 保存图片
return information
? 至此,所有要爬取的字段信息都解析出来了。
3、分析数据的特征
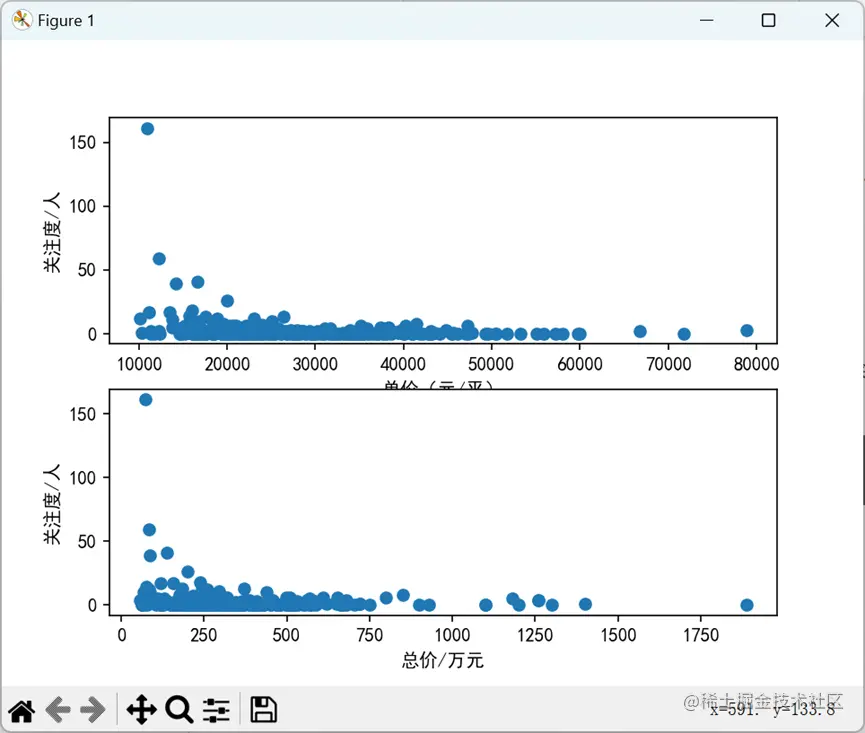
3.1关注度与单价,总价的图像
? 这里的all_data是爬取了所有页的所有数据集,是一个二维列表,数据依次为地址、户型、面积、单价、总价、关注度、发布时间。画图用到了matplotlib这个库的pyplot模块。
# 可视化函数,画出分析单价与关注度、总价与关注度之间的散点图并保存
def draw_picture(all_data, name):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(2, 1, 1)
plt.xlabel('单价(元/平)')
plt.ylabel('关注度/人')
plt.scatter(all_data[3], all_data[5])
plt.subplot(2, 1, 2)
plt.xlabel('总价/万元')
plt.ylabel('关注度/人')
plt.scatter(all_data[4], all_data[5])
plt.savefig('{}二手房可视化图像.jpg'.format(name)) # 填入爬取的城市名
plt.show()
3.2关注度最高的二手房的单价和总价
# 获取关注度最高的单价和总价信息
def get_max(all_data):
# 获取关注度最高的下标
max_follow = all_data[5].index(max(all_data[5]))
return all_data[3][max_follow], all_data[4][max_follow]
4、保存数据到excel中
# 保存所有数据到excel中
def save_data(all_data):
all_data = np.array(all_data)
all_data = all_data.T
# 增加表头
name = ['地址', '户型', '面积', '单价', '总价', '关注度', '发布时间', '链接']
all_data = np.insert(all_data, 0, name, axis=0)
all_data = pd.DataFrame(all_data)
all_data.to_excel('{}二手房数据.xls'.format(citys[city_ind]), sheet_name='数据', index=False)
5、效果展示
选择省份与城市:

爬取过程:

统计结果:

图像:
数据保存:



6、代码汇总
# 导入要使用到的库
from bs4 import BeautifulSoup
from lxml import etree
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import time
import os
import re
def get_data(url, headers):
"""
请求函数,向网页发起请求
:param url: 网址
:param headers: 请求头信息,里面有User-Agent内容
:return:返回得到网页数据
"""
datas = requests.get(url, headers)
return datas.text
def analyse_province(data):
"""
解析主页面的省份信息
:param data: 请求一级网页得到的数据
:return: 返回一个序号对应省份的字典数据
"""
bs_data = BeautifulSoup(data, 'lxml')
provinces_data = bs_data.find_all('div', {'class': 'city_list_tit c_b'}) # 使用beautifulsoup库解析省份
provinces = {}
for i in range(len(provinces_data)):
provinces[i] = (provinces_data[i].string)
return provinces
def analyse_city(data, province):
"""
根据所选的省份解析主页面的城市
:param data:请求一级网页得到的数据
:param province:所选省份的序号
:return:返回一个序号对应该省份的城市的字典数据
"""
bs_data = BeautifulSoup(data, 'lxml')
# 根据所选省份得到源码中省份的整个div内容
p_data = bs_data.find_all('div', {'class': 'city_province'})[province]
x_data = etree.HTML(str(p_data))
# 用xpath语法对得到的div进行解析,得到该省份下的城市和主页链接
city_list = x_data.xpath('//div[@class="city_province"]/ul/li/a/text()')
urls = x_data.xpath('//div[@class="city_province"]/ul/li/a/@href')
citys = {}
for i in range(len(city_list)):
citys[i] = city_list[i]
# 这里作这样的处理是为了二级页面直接是二手房板块
urls[i] = urls[i] + 'ershoufang/pg{}/'
return citys, urls
def get_page(data):
"""
在二级页面的第一页解析出总页数
:param data:请求二级页面的第一页得到的数据
:return:返回一个表示页数的int数据
"""
x_path = etree.HTML(data)
total_page = x_path.xpath('//div[@class="page-box fr"]/div/@page-data')
# 上面得到是一个字典形式的字符串数据,得到页数还要进一步解析
page = re.match(r'.*?talPage":(.*?),"curPage', str(total_page))
return int(str(page.group(1))) # 以int类型返回,直接用在循环中
def save_png(png_url, title):
"""
向图片链接发起请求,保存图片
:param png_url: 图片链接
:param title: 二手房标题,作为图片的命名
:return: null
"""
name = str(title.string)
# 图片命名不能有以下字符,所以要将这些字符去除
if '*' in name:
name = name.replace('*', '')
if '\\' in name:
name = name.replace('\\', '')
if '/' in name:
name = name.replace('/', '')
if ':' in name:
name = name.replace(':', '')
if '?' in name:
name = name.replace('?', '')
if '"' in name:
name = name.replace('"', '')
if '<' in name:
name = name.replace('<', '')
if '>' in name:
name = name.replace('>', '')
if '|' in name:
name = name.replace('|', '')
# 创建保存图片的文件夹
if not os.path.exists('{}png'.format(citys[city_ind])):
os.makedirs('{}png'.format(citys[city_ind]))
else:
# 尝试向图片发起请求,因有些网站中出现图片拍摄中的情况,这样写避免程序终止
try:
png_data = requests.get(png_url, headers).content
with open('{}png/'.format(citys[city_ind]) + name + '.jpg', 'wb') as f:
f.write(png_data)
except:
print('爬取图片错误,错误位置:', name)
def get_model(infor):
"""
从一次解析得到的文本中二次解析得到房屋户型信息
:param infor: 一次解析得到的文本
:return: 房屋户型信息的字符串类型
"""
model = re.match('^(.*?)\s', infor)
return model.group(1)
def get_area(infor):
"""
从一次解析得到的文本中二次解析得到房屋面积信息
:param infor: 一次解析得到的文本
:return: 房屋面积信息的字符串类型
"""
area = re.match('^(.*?)\s\|\s(.*?)\s\|\s', infor)
return area.group(2)
def get_follow(atten):
"""
从一次解析的关注度及发布时间文本中二次解析出房屋关注度信息
:param atten: 一次解析的关注度及发布时间文本
:return: 房屋关注度
"""
follow = re.match('^(\d+)人关注', atten)
return follow.group(1)
def get_day(atten):
"""
一次解析的关注度及发布时间文本中二次解析出发布时间信息
:param atten: 一次解析的关注度及发布时间文本
:return: 发布时间字符串类型
"""
day = re.match('.*?关注\s/\s(.*?)$', atten)
return day.group(1)
def get_unitprice(up):
"""
从一次解析的文本中解析出单价数据
:param up: 一次解析的文本
:return: int类型单价数据
"""
p = re.match('^(\d+),(\d+)元/平$', up)
return int(str(p.group(1))+str(p.group(2)))
def analyse_house(data):
"""
解析所选城市的单页信息,调用前面已经定义的函数
:param data: 请求单页返回的数据
:return: 返回一个所有信息综合的二维列表
"""
val = BeautifulSoup(data, 'lxml')
# 解析出标题
titles = val.find_all('a', {'target': '_blank', 'data-el': 'ershoufang'})[1::2]
x_val = etree.HTML(data)
pngs = x_val.xpath('//img[@class="lj-lazy"]/@data-original') # 解析出图片链接
prices = val.find_all(class_='totalPrice totalPrice2') # 解析出总价的板块
infors = x_val.xpath('//div[@class="houseInfo"]/text()') # 解析出户型等信息的文本
attens = x_val.xpath('//div[@class="followInfo"]/text()') # 解析出关注度等信息的文本
ups = x_val.xpath('//div[@class="unitPrice"]/span/text()') # 解析出单价的文本
information = [[], [], [], [], [], [], [], []] # 用来存所有一页信息的二维列表
# 解析出真正想要的数据并保存到information列表中
for title, p, infor, atten, png, up in zip(titles, prices, infors, attens, pngs, ups):
information[0].append(title.string) # 地址
information[1].append(get_model(infor)) # 户型
information[2].append(get_area(infor)) # 面积
information[3].append(get_unitprice(up)) # 单价
information[4].append(float(str(p.span.string))) # 总价
information[5].append(int(get_follow(atten))) # 关注度
information[6].append(get_day(atten)) # 发布时间
information[7].append(title['href']) # 链接
save_png(png, title) # 保存图片
return information
def merge_data(all_data, information):
"""
将多页爬取到的信息汇总成一个二维列表
:param all_data: 存每一页数据的二维列表
:param information: 单页数据的二维列表
:return: 汇总后的总数据列表
"""
for i in range(8):
all_data[i] += information[i]
return all_data
def draw_picture(all_data, name):
"""
画出分析单价与关注度、总价与关注度之间的散点图并保存
:param all_data: 所有数据汇总的数据集
:param name: 爬取的城市名
:return: null
"""
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(2, 1, 1) # 绘制子图1
plt.xlabel('单价(元/平)')
plt.ylabel('关注度/人')
plt.scatter(all_data[3], all_data[5])
plt.subplot(2, 1, 2) # 绘制子图2
plt.xlabel('总价/万元')
plt.ylabel('关注度/人')
plt.scatter(all_data[4], all_data[5])
# 保存图片
plt.savefig('{}二手房可视化图像.jpg'.format(name))
# 展示图片
plt.show()
def get_max(all_data):
"""
获取关注度最高的单价和总价信息
:param all_data: 所有数据汇总的数据集
:return: 返回关注度最高的单价和总价信息
"""
max_follow = all_data[5].index(max(all_data[5]))
return all_data[3][max_follow], all_data[4][max_follow]
def save_data(all_data):
"""
保存所有数据到excel中
:param all_data: 所有数据汇总的数据集
:return: null
"""
all_data = np.array(all_data)
all_data = all_data.T
# 增加表头
name = ['地址', '户型', '面积', '单价', '总价', '关注度', '发布时间', '链接']
all_data = np.insert(all_data, 0, name, axis=0)
all_data = pd.DataFrame(all_data)
all_data.to_excel('{}二手房数据.xls'.format(citys[city_ind]), sheet_name='数据', index=False)
# 主函数
if __name__ == '__main__':
# 一级页面
city_url = 'https://www.lianjia.com/city/'
headers = { # 请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
city_data = get_data(city_url, headers)
provinces = analyse_province(city_data)
print(provinces)
index = int(input('请选择省份:')) # 用户选择省份
citys, urls = analyse_city(city_data, index)
print(citys)
city_ind = int(input('请选择城市:')) # 用户选择城市
# 总数据集,保存的依次为地址、户型、面积、单价、总价、关注度、发布时间
all_data = [[], [], [], [], [], [], [], []]
page = get_page(get_data(urls[city_ind].format(1), headers))
# 爬取多页
for pn in range(1, page):
href = urls[city_ind].format(pn)
# 程序暂停2秒,避免爬取过快而被封IP
# time.sleep(2)
print('正在爬取第{}页'.format(pn))
two_hand_data = get_data(href, headers)
information = analyse_house(two_hand_data)
all_data = merge_data(all_data, information)
max_follow_unitprice, max_follow_price = get_max(all_data)
print('关注度最高的单价:', max_follow_unitprice, '元/平')
print('关注度最高的房屋总价:', max_follow_price, '万元')
print('数据量:', len(all_data[0]))
save_data(all_data)
draw_picture(all_data, citys[city_ind])
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
Python全套学习资料

1??零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2??国内外Python书籍、文档
① 文档和书籍资料

3??Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4??Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ?? ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!