Python机器学习19——常用六种机器学习的异常值监测方法(孤立森林,数据支持描述,自编码器,高斯混合,DBSCAN,LOF)
案例背景
异常值监测是机器学习的一个重要领域,博主以前做预测多,异常值监测涉及得少,但之后的工作可能需要做异常值方面的工作,所以大致总结了一下常用的机器学习来做异常值监测的方法以及代码。
标题的这些机器学习方法基本都可以调包,使用sklearn库实现。不需要装很多包。
(那些传统统计学的方法就不多介绍了,什么三西格玛(方差)准则,t检验,95%分位点啥的,那太简单了,本文主要介绍机器学习的方法。)
方法思路简介
一般来说最简单的思路就是2分类嘛,有监督学习,把异常值归为一类,正常值归为一类,然后做机器学习分类问题就行。
但是,一般来说,异常值情况都在样本中出现得就很少,去分类的话很容易造成样本不平衡的问题。这种不平衡肯定不是简单做一些数据抽样和数据增强处理能解决的,这是一种极度不平衡的情况。而且大部分情况的数据都是没有标签的,没有响应变量告诉你他是不是正常值,所以做不了分类问题的有监督学习。
所以异常值监测大多数都是无监督学习,从数据本身找异常。
当然也有半监督学习,即告诉他哪些是异常值,哪些不是。或者像自编码器这样使用自监督学习。
但是大体上这些方法都是训练的时候只使用特征变量,只使用X,不需要y,然后给结果的时候类似于预测给出每个样本是1(正常)还是-1(异常)。
代码实现
生成模拟数据
我们先导入包,然后生成一个包含异常值的模拟数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import OneClassSVM
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import IsolationForest
from sklearn.metrics import accuracy_score# 生成数据:正常数据和异常数据
np.random.seed(77)
X_normal = 0.3 * np.random.randn(800, 2)
X_abnormal = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack([X_normal, X_abnormal])
print(X_normal.shape,X_abnormal.shape)
# 标准化数据
scaler = StandardScaler()
scaled = scaler.fit(X_normal)
X_scaled=scaled.transform(X)
X_normal_scaled=scaled.transform(X_normal)
X_abnormal_scaled=scaled.transform(X_abnormal)
print(X_scaled.shape)
true_labels = np.hstack([np.ones(len(X_normal_scaled)), -1 * np.ones(len(X_abnormal_scaled))])
print(true_labels.shape)
可以看到从正态分布中生成了800个点,从均匀分布中生成了20个点作为异常点。然后为了对比模型效果我们记录了数据是不是异常值的标签(真实数据集一般没有)。这个正常和异常的比例差距很大,如下图:
pd.Series(true_labels).value_counts().plot.bar(figsize=(2,2))?
差不多一般真实数据集也是这种比例,正常值:异常值=40:1。
下面开始异常值监测方法的代码 。
支持向量数据描述
支持向量数据描述(Support Vector Data Description,SVMD)是一种用于异常检测的机器学习方法。它基于支持向量机(SVM)的概念,但专门用于无监督学习,尤其是在数据集主要由正常样本组成时。SVMD 试图找到一个能够包含大部分正常样本的最小球体,而将异常值排除在外。
在 Python 中实现 SVMD 可以通过使用 scikit-learn 库中的 OneClassSVM 类来完成。
svmd = OneClassSVM(nu=0.025, kernel="rbf", gamma=0.1)
# Fit the SVM model only on normal data (X_normal)
svmd.fit(X_scaled) # Ensure to use scaled normal data
y_pred = svmd.predict(X_scaled)
print(y_pred.shape)
上面已经把标准化的数据进行了训练和预测,下面我们来看准确率:
X_pred_normal = X[y_pred == 1]
X_pred_abnormal = X[y_pred == -1]
# Correctly and incorrectly predicted points
correctly_predicted = y_pred == true_labels
incorrectly_predicted = ~correctly_predicted
# Calculating accuracy using sklearn's accuracy_score function
accuracy_simple = accuracy_score(true_labels,y_pred)
accuracy_simple????????
98.9%,准确率还挺高 。
进行了一些筛选准备,我下面画了三张图,一张是原始数据中的正常数据和异常数据对比。一张是预测出来的正常数据和异常数据。还有一张是预测准确的点和预测错误的点。
# Plotting
plt.figure(figsize=(15, 5))
# Original data plot
plt.subplot(1, 3, 1)
plt.scatter(X_normal[:, 0], X_normal[:, 1], color='blue', label='Normal',s=20,marker='x')
plt.scatter(X_abnormal[:, 0], X_abnormal[:, 1], color='red', label='Abnormal',s=20,marker='x')
plt.title("Original Data")
plt.legend()
# Predicted data plot
plt.subplot(1, 3, 2)
plt.scatter(X_pred_normal[:, 0], X_pred_normal[:, 1], color='b', label='Predicted Normal',s=20,marker='x')
plt.scatter(X_pred_abnormal[:, 0], X_pred_abnormal[:, 1], color='r', label='Predicted Abnormal',s=20,marker='x')
plt.title("Predicted Data")
plt.legend()
# Prediction accuracy plot
plt.subplot(1, 3, 3)
plt.scatter(X[correctly_predicted, 0], X[correctly_predicted, 1], color='gold', label='Correctly Predicted',s=20,marker='x')
plt.scatter(X[incorrectly_predicted, 0], X[incorrectly_predicted, 1], color='purple', label='Incorrectly Predicted',s=20,marker='x')
plt.title("Prediction Accuracy")
plt.legend()
plt.show()
真实数据就是中间蓝色那一堆,旁边的红色散点就是异常值。黄色是预测正确,紫色是预测错误。
可以看到SVMD预测错误的点也没啥规律,就是把周围一些异常的点判断为了正常。效果一般。
孤立森林?
孤立森林(Isolation Forest)是一种有效的异常值检测方法,特别适用于高维数据集。它与传统的基于密度或基于距离的异常检测方法有所不同。下面是孤立森林的一些关键特点:
1. 基本原理:
孤立森林的核心思想是随机“孤立”每个数据点。这个方法假设异常点更容易被孤立,因为它们的数量少,且与正常点有较大差异。
-
孤立树(Isolation Trees):孤立森林由多个孤立树组成。每棵孤立树都是通过随机选择一个特征,然后随机选择该特征的切分值来递归地划分数据,直到每个数据点被孤立,或达到限定的树深度。
-
路径长度:一个数据点被孤立所需的路径长度被用作异常评分的依据。异常点通常在较短的路径长度下就会被孤立,因为它们通常远离大部分点。
2. 优点:
- 效率:对于大规模数据集,孤立森林的运行效率较高。
- 适用性:对于高维数据集也很有效,不像某些基于距离的方法那样受到“维数灾难”的影响。
- 无需预设分布:不像基于统计的方法,孤立森林不需要事先假定数据遵循特定的分布。
3. 应用场景:
孤立森林适用于各种场景,尤其是那些异常数据稀少且不遵循任何特定分布的情况。它被广泛应用于金融欺诈检测、网络安全、故障检测等领域。
4. 使用注意事项:
- 参数调整:孤立森林的性能可能受到树的数量和树深度这些参数的影响。
- 数据规模和类型:虽然它对大型数据集表现良好,但对于包含大量重复值或类别变量的数据集,性能可能会降低。
介绍完了,都能看的出来时某GPT写的。。下面是代码 。
和上面的思路一样的,构建模型,拟合预测,画图,我这里把画图封装为函数了,这样方便下面其他模型使用。免得画图这么一大段代码重复。
值得注意的是孤立森林这个contamination这个参数是异常值在总数据中的占比,真实数据集是不知道的,所以只能给一个大致估计比例。这里是模拟数据就直接给了差不多的值。
from sklearn.ensemble import IsolationForest
# Create and fit the Isolation Forest model
iso_forest = IsolationForest(contamination=float(len(X_abnormal)) / len(X))
iso_forest.fit(X_scaled) #X_normal_scaled
y_pred_iso = iso_forest.predict(X_scaled)
def plot_result(y_pred,model_name=''):
# Splitting the data into predicted normal and abnormal by Isolation Forest
X_k_normal = X[y_pred == 1]
X_k_abnormal = X[y_pred == -1]
# Correctly and incorrectly predicted points by Isolation Forest
correctly_predicted_k = y_pred == true_labels
incorrectly_predicted_k = ~correctly_predicted_k
accuracy_k_simple = accuracy_score(true_labels, y_pred)
print(accuracy_k_simple)
plt.figure(figsize=(15, 5))
# Original data plot
plt.subplot(1, 3, 1)
plt.scatter(X_normal[:, 0], X_normal[:, 1], color='blue', label='Normal',s=20,marker='x')
plt.scatter(X_abnormal[:, 0], X_abnormal[:, 1], color='red', label='Abnormal',s=20,marker='x')
plt.title("Original Data")
plt.legend()
# Predicted data plot (Isolation Forest)
plt.subplot(1, 3, 2)
plt.scatter(X_k_normal[:, 0], X_k_normal[:, 1], color='b', label='Predicted Normal',s=20,marker='x')
plt.scatter(X_k_abnormal[:, 0], X_k_abnormal[:, 1], color='r', label='Predicted Abnormal',s=20,marker='x')
plt.title(f"Predicted Data ({model_name})")
plt.legend()
# Prediction accuracy plot (Isolation Forest)
plt.subplot(1, 3, 3)
plt.scatter(X[correctly_predicted_k, 0], X[correctly_predicted_k, 1], color='gold', label='Correctly Predicted',s=20,marker='x')
plt.scatter(X[incorrectly_predicted_k, 0], X[incorrectly_predicted_k, 1], color='purple', label='Incorrectly Predicted',s=20,marker='x')
plt.title(f"Prediction Accuracy ({model_name})")
plt.legend()
plt.show()
plot_result(y_pred_iso,model_name='IsolationForest')
?准确率99.7561%,比SVMD高,只有两个点预测错误。这两个异常点....预测错了真不能怪模型,因为他们和正常值确实长得很接近。
自编码器
- 原理:一种基于神经网络的方法,通过重构输入来检测异常。
- 应用:特别适用于在高维数据中捕捉复杂模式,如在图像或序列数据中检测异常。
自编码器其实是自监督学习,输入的特征变量和响应变量都是X自己,把数据依靠神经网络进行压缩然后解码重构。可以理解为把一把剑融了重新再融一把剑。。。从这个过程中他会从所有样本的数据中学习这个重构的特征,如果一个数据重构后和原来数据比误差很大,说明可能是异常值。
他的思路导致他重构是回归问题,输出的不是类别。从预测的值怎么转为类别呢?
为了将自编码器的输出转换为类别判断(正常或异常),可以设定一个阈值。这个阈值用于决定重构误差多大时将一个数据点视为异常。设置这个阈值的一个常见方法是选择正常数据的重构误差的某个百分位数(例如95%)。数据点的重构误差高于这个阈值时,它们被标记为异常。
在我们的实现中,阈值是根据正常数据的重构误差分布设定的。具体来说,我们选择了正常数据重构误差的95百分位数作为阈值。然后,我们将所有重构误差高于这个阈值的点标记为异常。这样,我们就可以把自编码器的连续输出(重构误差)转换为二元类别(正常/异常)。
按道理来说自编码器需要神经网络框架,TensorFlow或者pytorch,我这里为了简便就直接sklearn库了,也能实现。
构建了一个128编码,32为压缩维度,然后又128解码还原。按照阈值方法转为了类别,用上面自定义的函数进行画图和测评。
from sklearn.neural_network import MLPRegressor
# Creating the autoencoder model
autoencoder = MLPRegressor(hidden_layer_sizes=(128,32,128),activation='relu',
solver='adam', max_iter=2000, random_state=77)
autoencoder.fit(X_scaled,X_scaled)
X_reconstructed = autoencoder.predict(X_scaled)
# Calculating reconstruction error
reconstruction_error = np.mean((X_scaled - X_reconstructed) ** 2, axis=1)
threshold = np.percentile(reconstruction_error[:100], 95)
predicted_anomalies = reconstruction_error <threshold
predicted_anomalies=np.array([1 if i else -1 for i in predicted_anomalies])
plot_result(predicted_anomalies,model_name='autoencoder')
?准确率95%,不是很高,预测错误的点都是左上方的,也不知道为啥。。。
DBSCAN(基于密度的空间聚类的噪声应用)
- 原理:基于密度的聚类算法,将稀疏区域中的点标记为异常值。
- 应用:适用于数据集中的聚类结构不规则或者大小不一的情况。
咋也不太懂这个方法的原理,就直接调包来预测和评价了。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.9, min_samples=5)
dbscan_labels = dbscan.fit_predict(X_scaled)
plot_result(np.where(dbscan_labels == 0, 1, -1),model_name='DBSCAN')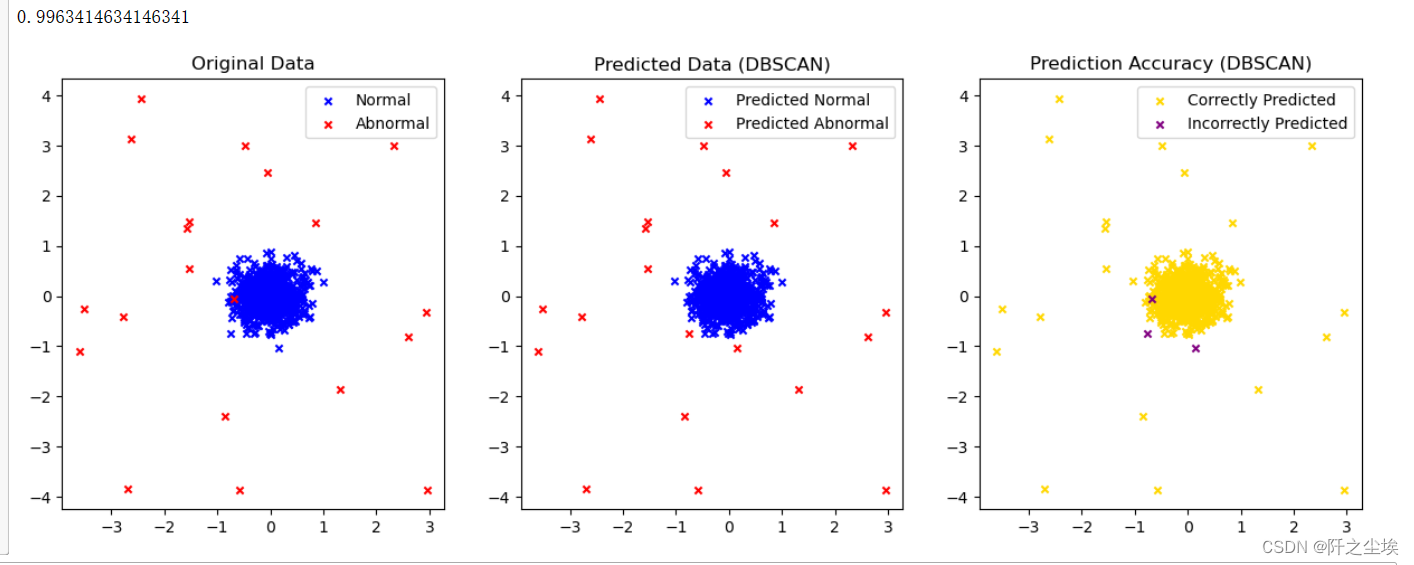
?准确率99.6%,只有三个点预测错误,还是很高。
本地异常因子(Local Outlier Factor, LOF)
- 原理:通过比较一个点与其邻居的局部密度来检测异常。
- 应用:适用于检测邻域密度差异显著的异常点
from sklearn.neighbors import LocalOutlierFactor
lof = LocalOutlierFactor(n_neighbors=10, contamination=0.025)
lof_labels = lof.fit_predict(X_scaled)
plot_result(lof_labels,model_name='LOF')
?准确率99.6%,只有三个点预测错误,还是很高。
高斯混合模型(Gaussian Mixture Model, GMM):
- 原理:使用多个高斯分布的混合来模拟数据,异常值通常不符合这些分布。
- 应用:适用于数据呈现多模态分布时的异常检测。
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=2, random_state=77)
gmm_labels = gmm.fit_predict(X_scaled)
plot_result(np.where(gmm_labels == 0, -1, 1),model_name='GaussianMixture')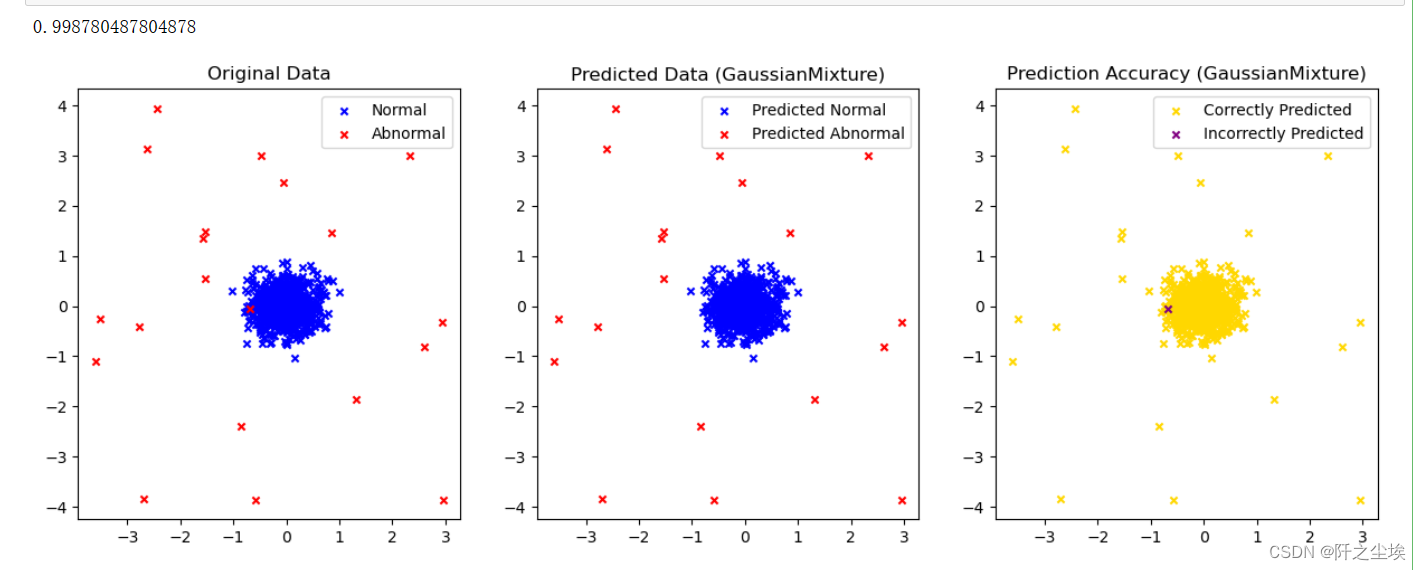
??准确率99.87%,只有1个点预测错误,最高!。而且这个点,和正常值太接近了,预测错了完全可以理解。
总结
从这个模拟的数据集效果来看,高斯混合最好,其次是孤立森林,LOF,DBSCAN,自编码器较差。
深度学习的方法为了较差,我猜可能是数据量小了,深度学习在小数据集表现确实一般不如传统的机器学习。
高斯混合为什么这么好,因为他是基于分布的,而我们则模拟数据集就是从不同分布里面生成的,所以正好对上了他的专长,所以效果会比较好吧。
这只是一个初步使用对比的案例,以后还需要用海量的真实的数据再进行测试才能知道哪些模型真的好用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!