Affective Image Content Analysis: Two DecadesReview and New Perspectives (综述)
摘要:
图像可以传达丰富的语义,引发观众的各种情绪。近年来,随着情绪智力的快速发展和视觉数据的爆炸式增长,情感图像内容分析(AICA)得到了广泛的研究。在这项调查中,我们将全面回顾近二十年来AICA的发展,特别是关注最先进的方法,涉及三个主要挑战-情感差距,感知主观性,标签噪声和缺失。我们首先介绍了在AICA中广泛使用的关键情感表示模型,并描述了可用的数据集,用于通过标签噪声和数据集偏差的定量比较进行评估。然后,我们总结和比较了以下方面的代表性方法:(1)情感特征提取,包括手工特征和深度特征;(2)主导情感识别、个性化情感预测、情感分布学习和从噪声数据或少标签中学习的学习方法;(3)基于AICA的应用。最后,我们讨论了图像内容与上下文理解、群体情感聚类和观众-图像交互等未来研究的挑战和前景。
Index Terms—Affective computing, image emotion, emotion feature extraction, machine learning, emotional intelligence’
1 INTRODUCTION
在《心智社会》(the Society of Mind)一书[1]中,明斯基(1970年图灵奖得主)声称:“问题不在于智能机器能否拥有任何情感,而在于机器能否在没有情感的情况下变得智能。”尽管情感在机器和人工智能中发挥着至关重要的作用,但情感计算的关注远远少于客观语义理解,例如计算机视觉中的对象分类。人工智能的快速发展在语义理解方面取得了令人瞩目的成就,对情感交互提出了更高的要求。
例如,能够识别和表达情感的伴侣机器人,可以为人类,特别是老人和单身儿童提供更和谐的陪伴。要想拥有类似人类的情感,机器首先要了解人类是如何通过多种渠道表达情感的,比如语音、手势、面部表情和生理信号[2]。
虽然其他信号很容易被抑制或掩盖,但由交感神经系统控制的生理信号不依赖于人的意志,因此提供了更可靠的信息。然而,捕捉准确的生理信号是相当困难和不切实际的,因为它需要特殊类型的可穿戴传感器。另一方面,近年来移动设备上摄像头的便捷接入和社交网络(如Twitter、Flickr、Weibo)的广泛普及,使得人们习惯性地将图片、视频与文字结合在一起,在网上分享自己的经历和表达自己的观点[3]。认识到这些大量多媒体数据的情感内容为理解用户的行为和情感提供了另一种方法。
正如我们所知,“一图胜千言”,这表明图像可以传达丰富的语义。情感图像内容分析(affective image content analysis, AICA)不同于现有的分析图像感知方面的研究,如对象检测、语义分割等,它侧重于对更高层次的语义理解——认知层面,即理解图像在观看者中可能引起的情绪,这更具挑战性。利用AICA对人的情绪状态进行自动推断,有助于评估人的心理健康状况,发现情感异常,防止对自己乃至对整个社会的极端行为。例如,在图1中,发布图片的用户(b)比发布图片的用户(a)更容易产生负面情绪。
1.1 Main Goals and Challenges
Main Goals
给定一个输入图像,AICA的主要目标是
(1)识别特定观众或大多数人可能产生的情绪(基于心理学,情绪可能以不同的模型表示,例如分类或维度。请参阅第2节了解详细信息。)
(2)分析图像中包含的哪些刺激能唤起这种情绪(例如,特定的物体或颜色组合);
(3)将识别的情绪应用于不同的现实世界中,以提高情商的能力。
Challenges.
(1)情感鸿沟。与计算机视觉中的语义缺口类似,情感鸿沟是AICA面临的一个主要挑战,可以将其定义为“特征与用户感知信号所带来的预期情感状态之间缺乏一致性”[5],如图2所示。

?为了弥合情感差距,研究人员主要致力于提取能够更好地区分不同情绪之间差异的判别特征,从手工制作的Gabor[6]、Gist[7]、艺术元素[8]、艺术原则[9]、形容词名词对(anp)[10]等特征,到卷积神经网络(cnn)[4]、[11]和区域[12]等深层特征。基于不同观众对图像感知情绪的共识假设,这些AICA方法主要为图像分配优势(平均)情绪类别(DEC)。这个任务可以作为传统的单标签学习问题来执行。
除了提取视觉特征外,结合可用的上下文信息也有助于AICA任务[13],如图3所示。同样的画面在不同的语境下会引起不同的情绪。例如,在图3a中,如果我们只是看到这个孩子,我们可能会根据他的表情感到惊讶;但在孩子吹蜡烛庆祝生日的背景下,这更有可能让我们感到快乐。在图3b中,如果我们看到一个排球运动员在哭泣,我们可能会感到悲伤;但如果有评论说:“十年后,我们终于赢了!”,我们,特别是球队的排球业余爱好者,可能会感到兴奋。

(2)感知主观性。不同的观众对同一幅图像可能会产生完全不同的情绪反应,这是由许多个人和情境因素造成的,如文化背景、个性和社会情境[14],[15],[16]。例如图4a中的“黑暗中的光”,对捕捉自然现象感兴趣的观众可能会对这个奇观感到兴奋,而害怕打雷和风暴的观众可能会感到恐惧。这一事实导致了所谓的主观感知问题。因此,对于这个高度主观的变量,仅仅预测DEC是不够的,因为它不能很好地反映不同观看者之间的差异。
为了解决主观性问题,我们可以执行两种AICA任务[15]:对于每个观众,我们可以预测个性化的情绪感知;对于每个图像,我们可以分配多个情感标签。对于后者,我们可以采用多标签学习方法,将一个图像与多个情感标签相关联。然而,由于不同情绪标签的重要性或程度实际上是不相等的,因此情绪分布学习将更有意义,其目的是学习每种情绪对图像的描述程度[16]
(3)标签噪音和缺席。最近基于深度学习的AICA方法,特别是CNN,已经取得了很好的效果。然而,训练这些模型需要大规模的标记数据,这是非常昂贵和耗时的,不仅因为在ground-truth生成中标记情绪是高度不一致的,而且因为在某些情况下,比如艺术作品,只有专家才能提供可靠的标签。在现实世界的应用程序中,可能只有很少甚至没有标记的情感数据。如何处理这种情况是非常值得研究的。
无监督/弱监督学习和少量/零学习是两个有趣的方向。一种可能的解决方案是利用无限数量的带有相关标签的网络图像作为标签[19]。然而,这样的标签可能是不完整的和嘈杂的。图像可能与不相关或远相关的标签相关联。如何从带有噪声标签的图像中学习是主要的挑战。基于图像和文本之间的语义相关性对视觉表示施加一些约束是一种直接的解决方案。首先以无监督或半监督的方式学习文本模型和嵌入,然后对关键词标签去噪可以帮助“清除”标签噪声。
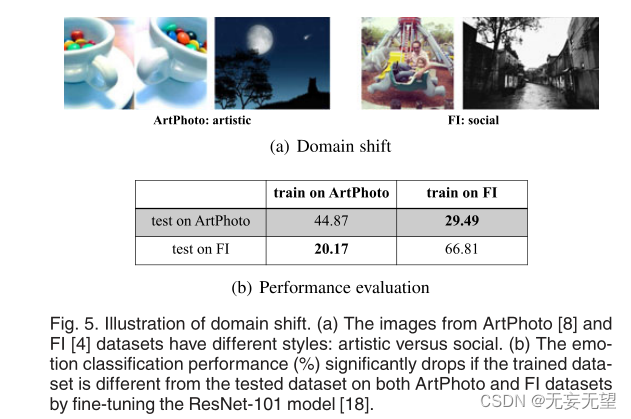
此外,如果我们在一个领域有足够的标记数据,例如抽象绘画,我们如何有效地将训练良好的模型转移到另一个未标记或稀疏标记的领域?由于存在域移位或数据集偏差[20],[21],直接迁移往往导致性能不佳,如图5所示。具体而言,Panda等[22]将AICA中的数据集偏差分为两类。一个是正集偏差。由于源领域中每个情感类别(如娱乐)的视觉概念缺乏多样性,基于这些数据学习的模型很容易记住其所有特质,并失去推广到目标领域的能力。另一种是负集偏差。数据集的其余部分(例如,来自除娱乐以外的其他类别的数据)在源域中并不能很好地代表视觉世界的其余部分。例如,来自目标域的一些负样本与源域的正样本相混淆。因此,学习到的分类器可能会过度自信。领域适应和领域泛化可能有助于解决这个问题。
1.2 Organization of This Survey
在本次调查中,我们重点回顾了AICA的最新研究方法,并概述了研究趋势。首先,我们将介绍1.3节中的简史,并与1.4节中的其他相关主题进行比较。其次,我们在第2节中描述了广泛使用的情绪表征模型。第三,我们总结了第3节中进行AICA评估的可用数据集,并定量比较了标签噪声和数据集偏差。第四,基于1.1节的主要目标和挑战,我们分别总结和比较了第4、5、6节中情绪特征提取、学习方法(用于主导情绪识别、个性化情绪预测、情绪分布学习、从嘈杂数据或少标签中学习)和基于AICA的应用的代表性方法,如图6所示。最后,我们在第7节讨论了可能的研究方向。
1.3 Brief History
情感计算。在情感计算被称为“情感计算”之前,早期的第一批作品包括1978年申请的一项用于确定说话者语音情绪的分析仪的专利[23],以及1990年关于合成语音中情感生成的科学论文[24],或1992年神经网络识别面部表情的科学论文[25]。
自Minsky提出智能机器的情绪识别问题[1]以来,情绪相关的研究得到了很多关注,如情商的定义[26]。1997年,Picard首次提出了情感计算(affective computing)的概念[27]:“情感计算是指与情感或其他情感现象相关、产生于情感或其他情感现象或有意影响情感现象的计算”。一些有影响的事件包括:2005年由IEEE和AAAI举办的第一届情感计算和智能交互国际会议(ACII), 2007年情感计算进步协会(AAAC)的成立(最初名为HUMAINE协会),2009年在Interspeech举行的第一次公开“情感挑战”,2010年IEEE情感计算交易(TAFFC)的启动,2011年第一届国际视听情感挑战和研讨会(AVEC),2014年ACM多媒体会议提出多媒体领域的情感和社会信号,2018年首届亚洲ACM多媒体会议等。
情感图像内容分析。AICA的发展始于心理学和行为学研究,如国际情感图像系统(International Affective Picture System, IAPS)[28]、[29],目的是研究视觉刺激与情绪之间的关系。最早的情感识别方法之一是基于低级整体Wiccest和Gabor特征[6]。
此后,一些具有代表性的手工特征被设计出来,如低级艺术元素[8]、中级艺术原则[9]和高级形容词名词对(anp)[10]。2014年,迁移学习从CNN开始,通过大规模数据预训练参数[30]。为应对主体性挑战,个性化情绪预测[15]、[31]与情绪预测相结合,考虑分布学习[14]、[32]、[33]、[34]。
最近,针对标签缺失挑战,研究了领域自适应[35]、[36]、[37]和零射击学习[38]。图7总结了一般情感计算和AICA的代表性里程碑。

1.4 Comparison With Other Related Topics?
与其他方式情感计算的比较。
情感内容分析在其他模态上也得到了广泛的研究,如文本[39]、[40]、语音[41]、[42]和语言学[43]、音乐[44]、[45]、声音[46]、面部表情[47]、[48]、[49]、[50]、视频[51]、[52]、生理信号[53]、[54]、[55]和多模态数据[56]、[57]、[58]、[59]。虽然所采用的情感模型和学习方法是相似的,但图像情感计算与其他模式有明显的区别,特别是提取的特征来表示情感。虽然对其他模式的调查进行得很好,但没有对非洲模式进行全面调查。由于图像是表达情感的重要渠道,我们相信对AICA的深入分析可以促进情感计算的发展。我们之前在IJCAI 2018会议论文中介绍了该调查的一个初步版本[60]。与会议论文相比,该期刊版本有以下五个方面的广泛增强。首先,详细的挑战和简要的历史被纳入。其次,我们总结和比较了在情感模型、可用数据集、情感特征和学习方法方面更有代表性的作品。第三,我们进行了大量的实验来公平比较不同的AICA方法的有效性。第四,我们添加了一些基于aica的应用程序。最后,对未来的研究方向进行了展望。
与计算机视觉的比较。AICA的任务通常由三个步骤组成:人工标注、视觉特征提取和学习视觉特征与感知情绪之间的映射[61]。虽然这三个步骤看起来与计算机视觉非常相似(CV,第三步是视觉特征和图像标签(如物体)之间的映射学习),但AICA和CV之间存在显著差异。以对象分类和情感分类为例。(1)即使在对象分类中消除了语义上的差距,仍然存在情感上的差距。例如,一只可爱的狗的图像和一只吠叫的狗的图像可以唤起不同的情绪。(2)对象是一个客观的概念(可爱的狗和吠叫的狗都是狗),而情绪是一个相对主观的概念(快乐和恐惧这两个形象)。(3)相应地,对象分类属于图像的感知层面,而AICA则侧重于认知层面。对象分类主要由CV社区研究,而AICA是一个跨学科的任务,需要心理学、认知科学、多媒体和机器学习等。
2 EMOTION MODELS FROM PSYCHOLOGY
在心理学中,有几个不同的情感计算相关概念,如情感、影响、情绪和情绪。讨论这些概念的区别或关联不在本调查的范围之内。感兴趣的读者可以参考[67]了解更多细节。评价理论以解释情绪体验的发展而闻名[68]。它解释了个体对相同刺激的情绪反应的差异性。根据Ortony, Clore和Collins (OCC)模型[69],情绪的出现源于对事件、主体和客体方面的刺激的认知评价或评价。个体实际感知和解释刺激的方式决定了情绪的产生方式。
心理学家主要采用两种情绪表征模型来测量情绪:类别情绪状态(CES)和维度情绪空间(DES),如表1所示。CES模型将情绪分为几个基本类别。最简单的CES模型是二元正负(极性)[55],[70]。在这种情况下,“emotion”通常被称为“sentiment”,有时也包括“neutral”。由于情绪过于粗粒度,所以设计了一些相对细粒度的情绪模型,如Ekman的六种情绪(愤怒、厌恶、恐惧、快乐、悲伤、惊讶)[62]和Mikels的八种情绪(娱乐、愤怒、敬畏、满足、厌恶、兴奋、恐惧和悲伤)[29]。随着心理学理论的发展,分类情绪正变得越来越多样化和细粒度化,例如也考虑了社会情绪[71]。除了八种基本的情绪类别(愤怒、期待、厌恶、恐惧、喜悦、悲伤、惊讶)
Plutchik[63]将它们分成3个强度,从而提供了一个更丰富的集合。例如,喜悦和恐惧的三个强度是狂喜!喜悦!宁静和恐惧,恐惧!分别忧虑。另一个代表性的CES模型是Parrott的树状分层分组[64],它用一级、二级和三级类别来表示情感。例如,一个三级情绪层次被设计为两个基本类别(积极和消极)在第一级,六个类别(愤怒,恐惧,喜悦,爱,悲伤和惊讶)在第二级,和25个细粒度的情绪类别在第三级。
虽然CES模型易于用户理解,但有限的情感类别并不能很好地反映情感的复杂性和微妙性。此外,心理学家还没有就应该包括多少离散的情绪类别达成共识。不同的是,DES模型采用连续的2D、3D或高维笛卡尔空间来表示情绪,如价-唤醒-优势(VAD)[65],以及潜在的增加强度、新颖性或其他因素,以及活动-温度-重量[66]。VAD是应用最广泛的DES模型[72],效价表示从积极到消极的愉悦程度,唤醒表示从兴奋到平静的情绪强度,支配表示从被控制到被控制的控制程度。在实践中,支配度难以测量,往往被忽略,导致了常用的二维VA空间[5]。理论上,每一种情绪都可以用笛卡尔空间中的坐标点来表示。但是,用户很难区分绝对连续值,这限制了DES模型的使用。
CES和DES的比较如表2所示。与CES相比,DES能够表达更细粒度和更全面的情绪,这分别反映了它们在粒度和可描述性上的差异。此外,它们不是相互独立的,而是相互关联的。[73]、[74]研究了CES和DES之间的关系以及二者之间的转换。例如,积极效价与快乐状态有关,而消极效价与悲伤或愤怒状态有关;放松的状态与低唤醒有关,而愤怒的状态与高唤醒有关。例如,为了进一步区分愤怒和恐惧(都是负效价,但高唤醒),人们需要支配(愤怒高,恐惧低)。CES和DES分别主要用于分类和回归任务,具有离散和连续的情绪标签。因此,所采用的学习模式是不同的。对于情感图像检索任务,这两种模型都可以使用不同的情感距离测量(例如,CES使用Mikels’emotion wheel [15], DES使用euclidean distance)。如果我们将DES离散成几个常数值,我们也可以使用它进行分类[66]。我们可以考虑通过基于排名的标注来缓解评分者对DEC的理解困难。

另一个值得一提的相关概念是,对图像的反应可以是预期的、诱导的或感知的情绪。预期情感是图像创作者想要让人们感受到的情感,感知情感是人们感知到的被表达的情感,而诱导/感受情感是观众实际感受到的情感。我们不打算讨论各种情绪模型的差异或相关性,并认为心理学和认知科学的成果对AICA任务是有益的。
3 DATASETS
在早期,情感数据集只包含从心理学或艺术社区建立的小规模图像。随着数码摄影和在线社交网络的发展,通过抓取互联网上发布的图像创建了越来越多的大规模数据集。我们在表3中总结了AICA的所有数据集。
3.1 Brief Introduction to Different Datasets
国际情感图片系统(International Affective Picture System, IAPS)[28]是一个视觉情绪刺激的图像数据集,用于心理学中情绪和注意力的实验研究[28]。该数据集包含1182张纪录片风格的自然彩色图像,具有各种内容或场景,如肖像、婴儿、动物、风景等。大约100名大学生参加了VAD评分,评分标准为9分。每个图像的得分的均值和标准差(STD)可以很容易地推导出来。
从IAPS中收集IAPS的子集A (IAPSa)[29],通过描述性离散情感类别对图像进行表征。具体而言,选取203幅负面图像和187幅正面图像,由20名本科生参与者标记。据我们所知,这是第一个使用离散情感类别标记的情感图像数据集。
abstract数据集[8]由280幅绘画组成,这些绘画仅是颜色和纹理的组合。它们由大约230人注释,每张图片都经过14次投票。对于每张图像,获得最多票数的类别被视为基本事实。在对投票结果不确定的图片进行筛选后,保留了228张图片。
Artphoto数据集[8]包含从艺术共享网站收集的806张艺术照片。以情感类别为关键字,通过搜索网站获得照片。每张图片的真实程度是由上传它的用户决定的。
日内瓦情感图片数据库(gape)[75]包含730张图片,收集这些图片是为了充分利用视觉情感刺激。在这些图像中呈现了几种特定类型的消极或积极内容。520幅阴性图像,121幅阳性图像,89幅中性图像由60名年龄在19 ~ 43岁(平均24岁,STD=5.9)的人标记。此外,连续VA量表的评分从0到100分。
MART数据集[76]包含500幅抽象画,这些抽象画收集自一位艺术史学家指导的专业艺术家的2万多件艺术品。25名参与者(11名女性和14名男性)对这些图像进行了负面或正面评价。每个人平均注释145幅画。
devArt[76]是来自deviantArt (dA)网站的业余绘画数据集。由406名作家创作的500幅作品由27名女性和33名男性等60人进行标注。
Twitter I数据集[77]由1269张图像组成。总共雇佣了5名亚马逊土耳其机械(AMT)工人来标记这些图像。该数据集包含三个子集,包括“五个同意”(Twitter I-5),“至少四个同意”(Twitter I-4)和“至少三个同意”(Twitter I-3)。“五同意”表示5名AMT员工对某一形象的情感标签达成一致。Twitter I-5包含882张图片,而所有图片在情感上至少获得三张相同的投票。
Twitter II数据集[10]包括使用20多个Twitter标签收集的470张正面图像和133张负面图像。随机选择3名AMT工作人员(每组工作人员一人)分别进行基于图像、基于文本和基于图像-文本三种不同的标记运行。最终选出的图片都获得了一致的情感投票。
使用Flickr API检索和下载VSO中标记为1,553个anp的图像[10]。相应的ANP应包含在图像的标题、标签或标题中。作为构建数据集的心理学原则,Plutchik的情绪之轮涵盖了基于8种基本情绪的3种强度。MVSO[78]是VSO的扩展。该数据集由超过736万张带有12种不同语言anp注释的图像组成,包括阿拉伯语、汉语、荷兰语、英语、法语、德语、意大利语、波斯语、波兰语、俄语、西班牙语和土耳其语。共编制了4342份英文anp。
提出Flickr I[79]来研究情绪与朋友对图片的讨论之间的相关性。它包含了4807个用户发布的354192张图片,其中所有的包括注释和标签。为了更好地模拟朋友之间的互动,数据集中还记录了用户的详细信息,包括ID、别名和联系人列表。
Flickr II[80]和Instagram[80]分别根据查询关键字从Flickr和Instagram中收集。情感极性标签是通过在线众包提供的。具体来说,每张图片被随机展示给三名工作人员,他们应该从五个量表中选择一个评级,包括高度积极、积极、中性、消极和高度消极。每个图像的最终真实值由极性的主要评级决定。在丢弃被标记为“中立”或收到相反情绪注释的图像后,Flickr II数据集中留下了48,139张正面和12,606张负面图像,而Instagram则包含33,076张正面和9,780张负面图像。
Emotion6[14]包含1980张图片,这些图片是通过6个分类关键词和对应的同义词从Flickr中获得的。每张图像都由15名参与者用价值唤醒分数和离散情绪分布来注释。这些类别包括Ekman的六种基本情绪[62]和中性情绪。
FI[4]是基于Mikel的情绪构建的大规模情感图像数据集。所有图片都是从Flickr和Instagram上收集的,以八种情绪作为搜索关键词。总共抓取了数百万张带有弱标签的图像。在删除噪声数据后,共雇用225名AMT工作人员评估图像的情绪。最后,23308张图片从指定的注释者那里获得至少三份协议。
IESN数据集[15]由11,347名用户上传的从Flickr上抓取的100多万张图片组成,它的构建是为了研究个性化的情绪感知。因此,还会收集相应图像的各种元数据,包括标签、描述、评论以及上传者的社交背景。对于每张图片,都会生成来自上传者的预期情绪标签和来自观看者的实际情绪标签。此外,利用13915个英语引理的VAD范数[87],计算VAD的平均值作为DES的标签.根据图像的描述和评论,情感分布也很容易得到。
T4SA数据集[81]由大约100万条tweet和相应的图像组成。根据文本情感分类,将图像分为积极、消极和中性。然而,数据集包含501,037张正面图像,214,462张负面图像和757,895张中性图像,这是不平衡的。BT4SA作为一个平衡子集,从T4SA中提取BT4SA[81],其中每个类相当于156,862张图像。
漫画数据集[82]由从70部漫画中选择的11,821幅图像组成,包括海贼王,蜘蛛侠,海绵宝宝,复仇者联盟等。共有10名参与者(平均年龄为20.3岁)被雇来用米克尔的八种情绪类别给这些图像贴上标签。数据集进一步分为两个子集:Comics子集和Manga子集。漫画子集包括来自欧洲和美国的现实主义风格的漫画样本,而漫画子集包含抽象风格的亚洲漫画。
?Event数据集[83]有8,748张图像,这些图像是通过使用来自24个事件类别的搜索关键词从微软必应获得的。活动的类型多种多样,包括个人活动和实际的公共活动。在标注过程中,如果至少有2 / 3的众包工作者对图片的标签达成一致,就可以保留图片。这些事件图像的情绪标签包含积极、消极和中性。
EMOTIC数据集[84]包含18,316张图像,这些图像是从MSCOCO[88]和Ade20k[89]数据集中选择的,并基于26个情感关键词通过Google搜索引擎下载。数据集有两种类型的注释信息。一个是包含26种情绪的DES,另一个是连续的VAD维度。总共有23,788人(66%的男性,34%的女性)被标注在图像中。
EMOd数据集[85]由1019张情绪图片组成,其中321张图片来自IAPS[28], 698张图片来自在线图片搜索引擎。每张图像都有来自16名参与者的眼动追踪数据,并标有详细信息,包括物体轮廓,物体情感,语义类别以及图像美学和情感等高级感知属性。采用三名大学生对图像中物体的特征进行标记。当协议不同时,对象的情绪被标记为“中立”。
WEBEmo数据集[22]是基于Parrott的分层情感模型构建的大规模网络情感数据集。首先,通过对25种情绪中的每一种进行关键词搜索,收集了大约30万张弱标记图像。然后,删除重复图像和带有非英语标签的图像,得到26.8万张高质量图像。
LUCFER数据集[86]包含超过360万张图像,这些图像被标记为来自Plutchik模型的24个情感类别,3个连续的情感维度和图像上下文。通过结合情境和情绪,共生成275对情绪-情境对。首先,从野外采集图像80649张,其中35239张通过了AMT工作人员的验证。使用Bing的图像搜索API中提供的功能,获得了超过3万张图像的大规模数据集。
构建Flickr_LDL[16]和Twitter_LDL[16]来研究情感歧义。每个图像都被不止一个观看者根据他们自己的情绪反应贴上标签。Flickr_LDL包含从VSO数据集提取的10,700张图像。总共有11名参与者被雇来观看每张图片,并用米克尔的八种情绪中的一种给图片贴上标签。Twitter_LDL从Twitter上收集各种情绪关键词,并雇用8名观众将这些图像标记为相同的8种情绪。最后,重复数据删除后将保留10045个映像。
3.2不同数据集之间的比较
在这里,我们从标签噪声和数据集偏差的角度比较了几个发布的数据集,以便读者更好地了解如何在实际应用中选择所需的数据集。

3.2.1 Label Noise
为了在标签噪声方面进行定量比较,我们通过预训练带有softmax损失的CNN来估计噪声率[101]。假设正(+1)图像的概率被赋值为负
3.2.2数据集偏差
为了探索情绪识别的数据集偏差,我们在不同的数据集之间进行了广泛的迁移学习实验,在一个数据集上训练分类器,在另一个数据集上进行测试。这些数据集的图像数量范围很大,从几百张到几十万张不等。同时,这些数据集包括自然图像和抽象图像等多种类型。我们将每个数据集分成80%的训练图像和20%的测试图像。为了公平的实验,我们在每个数据集上微调一个ResNet-50[18],并在所有数据集上测试模型。
混淆矩阵如图8b所示,其中每一行代表一个模型在不同数据集上的结果。我们有以下几点观察。
首先,属于不同类型的数据集之间存在较大的偏差,例如抽象、漫画和自然图像。例如,Abstract、Comics和gape的类型分别是Abstract、comic和natural。在Comics上训练的模型在Abstract和gape数据集上的准确率分别为0.522和0.546。
其次,两个数据集之间的偏差不是相互的。这意味着当两个数据集中更干净的一个被视为目标时,评估的偏差更小。例如,正如所示的Event(最干净的数据集,rm = 0.074)与其他数据集之间的实验结果,当Event为目标数据集时,结果会更好。
第三,类分布的相似性会影响数据集的偏差。例如,Twitter II和Flickr_LDL (Twitter_LDL)具有相似的类分布,其中积极图像明显多于消极图像。但是,Flickr和Instagram有一个平衡的类分布,这与Twitter II不同。因此,可以观察到,在Twitter II上训练的模型在Flickr_LDL和Twitter_LDL上的性能优于在Flickr和Instagram上的性能。
最后,FI作为应用最广泛的数据集,在这些数据集中具有最好的泛化能力。如图8b第一行所示,在FI数据集上训练的模型在所有数据集上的分类准确率都在60%以上。

4 EMOTION FEATURE EXTRACTION?
为了用信息表征来描述图像情感,许多研究都在探索提取各种类型的特征。在手工功能方面,我们在不同的层次上介绍设计的功能。此外,我们还回顾了近年来随着cnn的发展而出现的深度特征。
4.1 Hand-Crafted Features?
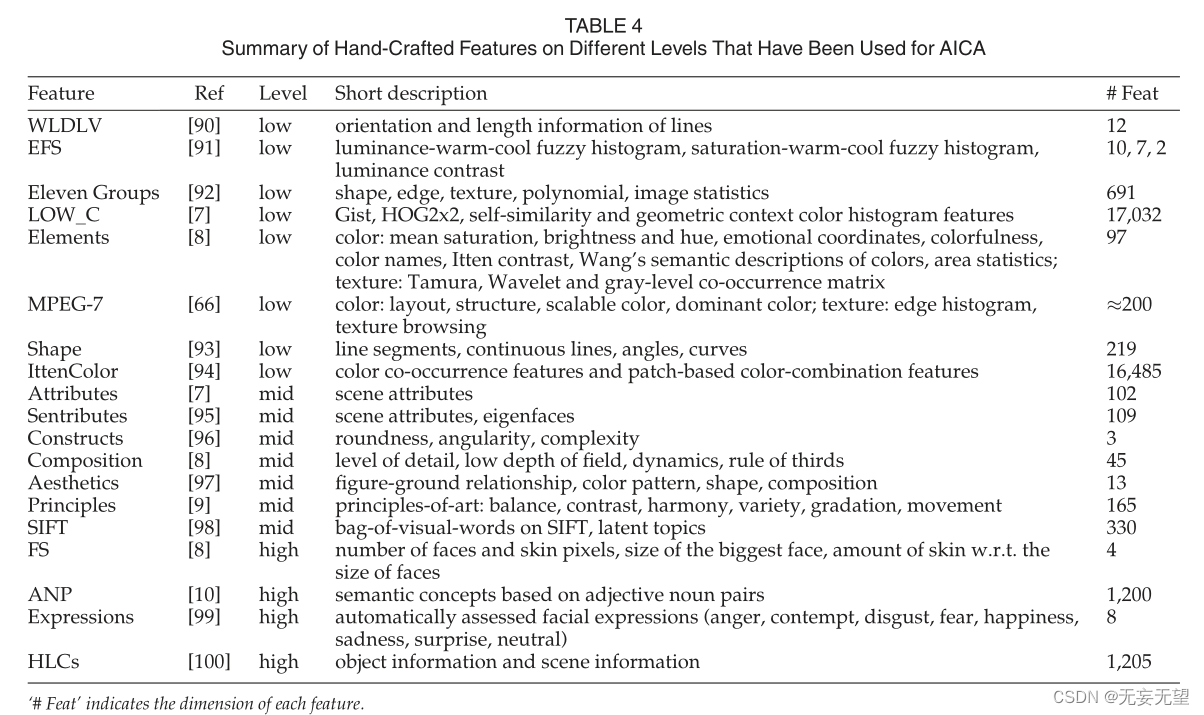
不同级别上的手工特性关注不同的方面,如表4所示。
4.1.1 Low-Level Features?
尽管缺乏合理的解释,但在早期设计了各种低级特征来表示情感内容。作为一项关于手工特征的开创性研究,[90]探讨了线条方向与图像情感之间的关系。具体来说,水平线与静态的地平线有关,总是表达放松和平静,而直接而清晰的垂直线传达永恒和尊严。不同方向的线条可以传达不同的情感。随着线条的长、粗、直的程度增加,所表达的情绪也会更强烈。而Wang等[91]为了获取更多的信息,在色彩心理学理论的指导下,在正交的三维情感因素空间中分别构建了三种图像特征。这些特征包括亮度-冷暖表示、饱和度-冷暖-对比度表示和对比度-清晰度表示。通过挖掘这些提出的情感信息,他们设计了一个基于情感的图像检索系统。
说到手工制作的功能,我们不能忽视一个里程碑[8],在这个里程碑中,不同类型的功能被组合在一起。其中,颜色和纹理是构成中具有代表性的底层特征。颜色用包含8种统计信息的70维矢量表示,纹理用包含3种图像统计信息的27维矢量编码。后来在[66]中提出了另一种由颜色和纹理组成的复杂特征组合,称为MPEG-7。此外,采用模糊相似关系计算各分量的权重。Zhang等[92]列出了从图像的多次变换中提取的11组特征,分别是纹理、形状和边缘。[93]系统探讨了视觉形状对形象情绪的影响。
实验结果证明了形状特征在情绪预测中的有效性。另外,Gist, 2?2定向梯度直方图(Histogram of Oriented Gradients, HOG)、自相似性和几何上下文颜色直方图特征由于能够表示不同的视觉场景而被广泛使用[7]。基于Itten的色轮,Sartori等人[94]研究了抽象画中不同的色彩组合,并利用这些因素来分析观者所唤起的情绪。
4.1.2 Mid-Level Features
与低级特征相比,中级特征更容易被人类理解,它们可以在很大程度上弥合低级特征和高级情感之间的差距。Patterson和Hays[7]设计了一个大型属性数据库,命名为SUN属性数据库,该数据库由102个属性组成,这些属性属于不同的类型,包括材料、表面性质等。基于这些中间属性,Yuan等[95]提出了一种名为Sentribute的图像情绪识别算法,其中还加入了基于特征脸的面部表情检测,作为确定情绪极性的关键元素。
作为艺术作品的本质特征,和谐构图[8]被引入到情感表现中。Wang等人[97]在艺术理论的指导下,设计了更具可解释性和可理解性的特征,其中包括对人物与地面对比的描述。除了用单一尺度提取整体图像特征的研究外,研究人员注重在每张图像的多尺度块中挖掘信息表示。例如,Rao等[98]使用两种不同的图像分割类型来提取每张图像中的多尺度块。他们以SIFT为基本特征,采用视觉词袋(BoVW)对每个块进行编码,然后采用概率潜在语义分析进一步估计作为中级表示的潜在主题。本研究表明,BoVW可以很好地模拟不同局部区域的情感信息,直接从整幅图像中提取特征可能导致错误的分类结果
根据不同的艺术原则,提出了一种名为“艺术原则”(principles-of-art)的组合情感表现形式[9],包括平衡、强调、和谐、变化、渐变和运动。作为中层表现的里程碑,艺术原理特征在当时获得了最先进的表现。在没有数百维特征的情况下,[96]提出了三个视觉特征,包括圆度、角度和视觉复杂性,每一个都只是一个一维标量。事实证明,这些中层表征在识别图像情绪时是有效的。
4.1.3 High-Level Features
高级特征是指图像的语义信息,这些信息易于理解,可以直接唤起观看者的情感。在[8]中,Machajdik和Hanbury提取了能够吸引观众注意力并对情绪有很大影响的内容,包括人脸和皮肤。面部表情是一种重要的高级特征,在情感的唤起过程中起着决定性的作用。人们通常按照埃克曼的“六大情绪”划分为六种基本情绪,包括愤怒、厌恶、恐惧、快乐、悲伤和惊讶。在[99]中,Yang等人基于图像斑块的组成特征检测并分析面部表情的类别。
作为里程碑,Borth等人[10]提出了一个名为SentiBank的大型视觉情感本体。它包含1200个概念,每个概念代表一个ANP,就像美丽的花朵,它提供了强大的语义表示。首先,根据普鲁契克理论中定义的24种情绪,作者检索了相关形容词,并将其与常用名词配对。在过滤掉多余的anp后,最终剩下的1200个anp包含178个形容词和313个名词。anp为弥合“情感鸿沟”提供了一种新颖的解决方案,因为它们很容易被映射到情感中。后来,作为SentiBank的扩展,[78]提出了一种大规模的多语言视觉情感本体(MVSO)。特别是,MVSO中有4342名英语anp。在[100]中,引入了包括物体和地点在内的高级概念(high-level concepts, hlc)来弥合图像内容与唤起的情感之间的情感鸿沟。HLCs明确地从预训练的cnn中导出,随后,采用线性混合模型来捕获情绪与HLCs之间的关系。
4.2 Deep Features
近年来,随着cnn的快速发展,基于学习的特征在AICA领域表现出了优越的性能。一开始,在学习过程中对图像中的每个区域一视同仁,针对不同的任务提取全局特征。后来,根据心理学理论,情绪内容总是涉及到一些重要的区域,越来越多的研究集中在如何提取信息丰富的局部特征上。
4.2.1 Global Features
基于深度CNN模型,使用Caffe训练1200个ANP概念的分类器。新训练的深度模型DeepSentiBank[103]在情感预测上的表现优于非深度SentiBank。Xu等[30]受益于迁移学习,将在大规模数据集(ImageNet)上训练的CNN的参数转移到预测情绪的任务中。他们分别从全连接(FC)层FC7和FC8中提取了4096维表示和1000维表示作为图像级特征。在Twitter II数据集上的实验结果表明,来自FC7的特征在描述情感内容方面表现出优势,因为来自FC7层的激活比FC8层的激活可以表征图像的更多方面。
渐进式CNN (PCNN)[77]是另一个里程碑,它使用来自SentiBank的50万张弱标记图像进行预训练。在学习过程中,将两极性差异较大的训练实例保留到下一轮训练中。通过迭代训练,可以逐步去除噪声数据,使训练后的模型在迁移到小尺度强标记数据集时具有更强的鲁棒性。在[11]中,Chen等人探索了两种获取图像特征的方法。
一种方法使用现成的CNN(在ImageNet上预训练)特征来训练一个单对全的线性SVM分类器。另一种方法是初始化预训练AlexNet的参数,将1000路分类层替换为8路情感类别输出。随后,网络可以从原始图像到特定的情感类别进行端到端训练。
在某些图像中,特别是在抽象画中,高级语义特征可能不足以作为情感表征。为了捕获图像中不同类型的信息,一些研究将cnn中生成的多层次深度特征整合在一起。Rao等人[104]提出了一个端到端架构,该架构由三个并行神经网络组成,包括AlexNet、美学CNN (a -CNN)和纹理CNN (T-CNN)。在输入网络之前,图像被分割成不同级别的补丁。随后,利用这三个子网络分别提取三个层次的深度表示,即图像语义、图像美学和低级视觉特征。Zhu等[105]从cnn的不同层提取多层次特征。每一层的输出被馈送到双向门控循环单元(Bi-GRU)模型中,以利用它们之间的依赖性。最后,将两端输出的特征连接起来作为情感表示。进一步认为Gram矩阵可以捕获强大的纹理特征[106];因此,Yang等人[107]提出了一种由来自不同层的Gram矩阵元素组成的情感表示。
4.2.2 Local Features
近年来,局部特征越来越受到人们的关注,以强调包含有吸引力的情感内容的信息区域。考虑到细粒度的细节,[11]在多个尺度上提取局部斑块的特征。接下来,它们与Fisher向量聚合以获得更紧凑的表示。在[108]中,Liu等人在计算视觉显著性时,除了使用多实例学习研究一般情感内容外,还检测了面部表情和情感对象构成情感因素。
如何基于图像级标签找到关键的情感相关区域是一个值得探索的问题。You等[109]在描述性视觉属性的基础上,采用注意力模型来发现观众情绪唤起的局部区域,然后提取其特征,提高视觉情绪分析的性能。Yang等[110]利用现成的目标检测工具生成候选边界框。去除冗余的建议后,所选择的区域包含对象的概率较高,因此获得较高的情感分数。然后,将所选区域的特征与整体图像相结合进行分类。然而,在这项工作中,选择合适的图像区域的过程是耗时的。为了简化和改进选择信息区域的步骤,[12]提出了包含分类分支和检测分支的统一CNN。在检测分支中,通过组合所有分类特征响应来生成软情感图。将整体特征与情感图相结合,可以得到综合的局部信息。后来在[111]中,空间和通道参与特征都被纳入VAD空间中视觉情感回归的最终表示。为了有效利用多层的各种信息,Rao等[112]提出了一种基于多层区域的CNN框架来寻找局部区域的情绪反应。首先,利用特征金字塔网络(FPN)提取多层次深度表征。然后,基于区域建议方法检测感兴趣区域(roi),并将其在多个层次上的特征进行拼接,进行图像情感分类。该工作在多个基准数据集上取得了迄今为止最好的分类性能。为了获得情感图像检索的信息特征嵌入,Yao等人[113]分别在较低的层和较高的层上进行了极性和情感特定的关注。通过跨层双线性池化对不同层的特征进行整合,生成最终的表征
4.2.3 Comparison Between Local and Global Features
为了公平地评估局部特征和全局特征的有效性,我们基于WSCNet[12]和PDANet[111]进行了表5中的对比实验,这是最先进的方法,通过将局部特征和全局特征结合到最终表示中来考虑局部区域。对两种具有代表性的方法分别进行了局部、全局和局部-全局结合特征的对比实验。在表的最后一行,我们提供了平均排名的结果,这表明总体上全局特征优于局部特征。此外,对于大多数数据集,同时使用局部和全局特征的结果比只使用一种特征的结果要好。这主要是因为局部特征和全局特征都在一定程度上决定了情绪,并且某些局部区域可能产生情绪优先效应而不是单一效应。因此,局部特征应与全局特征有效结合,以获得更具判别性的表征[115]。

4.3 Quantitative Feature Comparison?
在表6中,我们基于不同的分类器评估了不同特征的性能。报告了六个广泛使用的数据集的结果。请注意,FI被视为同时具有两个情绪类别和八个情绪类别的数据集。手工制作的特征包括PAEF[9]、Sun attribute[7]和SentiBank[10],而现成的深度特征是从MVSO[78]和预训练的VGG-16[114]中提取的。每种类型的特征被用来训练三个分类器,包括kNN、朴素贝叶斯(NB)和支持向量机(SVM)。在Sun属性中,我们提取了四种类型的特征,包括Gist, HOG 2?2、自相似性、几何背景颜色直方图特征。在预训练的VGG-16中,我们从最后一层提取4096维特征。注意,Sun属性的特征和预训练的VGG-16都降到了256维。我们报告了不同分类器对同一特征的平均结果,以公平地研究每个特征的表示能力。从相同分类器的结果和不同分类器的平均结果可以看出,深度特征获得了最好的性能,这在传统的计算机视觉任务中也得到了证明,如图像分类和目标检测。
此外,在大多数情况下,高级功能(例如SentiBank)比中级功能(例如PAEF)表现得更好。这主要是因为高级特征与情感语义的关系更密切。例如,SentiBank是基于anp构建的,其中形容词可以更好地映射到情感。

5 LEARNING METHODS FOR DIFFERENT TASKS?
在本节中,我们回顾了近二十年来关于AICA的学习方法,其中在不同的AICA任务上取得了重大进展,包括主导情绪识别,个性化情绪预测,情绪分布学习,以及从嘈杂数据或少数标签中学习。
5.1 Dominant Emotion Recognition
5.1.1 Traditional Methods
在早期,研究人员主要使用SVM基于各种手工制作的情感特征对图像进行分类。Machajdik和Hanbury[8]将不同层次的特征组合在一起,生成最终的情感表征。实验使用支持向量机在三个小数据集上进行,使用5倍交叉验证,每个类轮流与其他类分开。结果以每个班级的真阳性率报告。通过支持向量机训练1200个anp概念检测器,产生SentiBank[10],由于与情绪有很强的共现关系,它是情绪预测的关键高级线索。作为SentiBank[10]的扩展,DeepSentiBank[103]和MVSO[78]分别使用现有的深度架构(如CaffeNet)训练2089和4342个英文anp的检测器,然后可以推断情感极性。利用文本解析技术和基于词典的情感分析工具,将形容词映射为“肯定”或“否定”;同样,得到了图像的极性。即使在cnn出现之后,支持向量机也是必不可少的分类器。例如,Ahsan等人[83]通过训练好的CNN模型检测事件概念,并基于SVM分类器将视觉属性映射到特定的情感中。此外,手工艺术特征与CNN特征相结合生成最终表征[116],然后将其输入svm进行分类。
从艺术绘画中推断所唤起的情感是近年来一个有趣的研究问题。由于艺术绘画的抽象风格,识别艺术绘画的情感成为一项具有挑战性的任务。后来,考虑到图像可以在不同的特征空间中表示,采用多核学习[117]来捕捉抽象艺术的不同情感模式。在此过程中,可以自动调整不同特征的权重,使学习到的特征组合成为最合适的特征组合。直观地说,绘画的情感与绘画技巧等各种特征有关。因此,引入非线性矩阵补全(NLMC)[76]作为一种传导分类器,对不同潜在变量之间的关系进行建模。这件作品很好地模仿了从艺术绘画中推断情感的过程。为了解决标记良好的绘画的稀缺性,Lu等[118]提出了一种自适应学习策略,使用标记的照片和未标记的绘画来识别绘画的情感。在学习过程中考虑了两种类型图像之间的差异。
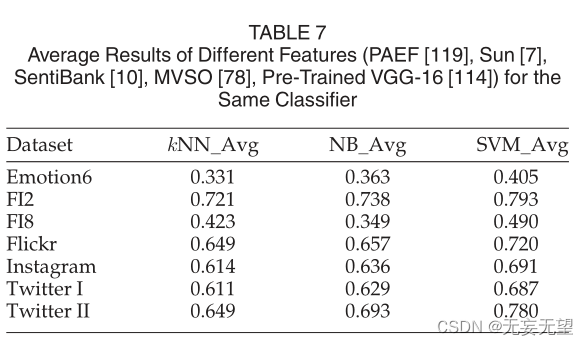
对于同一个分类器,我们计算不同特征的平均性能,如表7所示。一般来说,SVM在三种分类器中性能最好,而kNN除FI8上的结果外,其他分类器的性能较差。
5.1.2 Learning-Based Methods
利用cnn提取特征的强大能力,越来越多的研究[12]、[120]、[121]、[122]设计了各种基于学习的方法来识别图像情绪。在早期的研究中,CNN通常直接作为现成的工具使用,不做任何修改。例如,Xu等人[30]分别根据现有基础网络(AlexNet)的两个完全连接(FC)层(FC7和FC8)训练了两个分类器。实验结果表明,FC7(0.649)层后的分类器性能优于FC8(0.615)层后的分类器。结果表明,CNN的第7层比第8层的目标检测分数更能表征图像的情感信息。为了进一步深入了解CNN模式对视觉情感分析的影响,Campos等人[121],[123]对基于softmax和SVM分类器的微调CaffeNet进行了逐层分析。
Personalized Network.。
随着cnn的发展,研究人员在艺术和神经网络理论的指导下,建立了更好的情感识别性能的新网络.在[124]中,Wang等人提出了一种深度耦合的形容词和名词神经网络来识别图像中的积极和消极情绪。由两个并行子网络(A-net和N-net)组成的体系结构可以联合预测anp的形容词和名词。当ANP标签不可用时,提出了一种相互监督的方法,利用捕获名词和形容词之间关系的过渡矩阵来预测每个子网络的期望输出。
Multi-Level Features.
为了充分利用[104]中图像的多尺度特征,Zhu等[105]将CNN和RNN架构集成在一起。具体来说,使用CNN提取不同层次的特征,然后使用双向门控循环单元(Bi-GRU)捕获它们之间的依赖关系。最后,将Bi-GRU的两个输出连接起来进行情感分类。在学习过程中,使用softmax loss和contrast loss对模型进行训练。通过对比损失,从同一类别图像中提取的特征被强制彼此接近,而从不同类别图像中提取的特征被强制彼此远离。本研究首次对不同层次特征之间的关系进行了动态建模。
Emotional Polarities
在Mikels的八种基本情绪中,存在两种极性:积极的和消极的。相同极性的情绪彼此之间更接近——因此,它们是高度相关的。这一情感特征已经在几项研究中得到了关注。Yang等人[107]基于三联体损失[125],考虑极性特征,设计了一种情感度量损失,构建四联体{anchor, positive, related, negative}进行学习,其中related表示与anchor属于同一极性但不同类别的样本。通过联合优化softmax损失和情感度量损失,该体系结构可以同时用于分类和检索任务。He和Zhang[126]设计了一个统一的架构,由两部分组成:情感极性分类子网络和特定情感分类子网络。通过辅助学习策略,极性的结果可以作为重要的先验知识用于更细粒度的情绪分析。
Yao等[113]通过考虑情感的层次结构设计了情感对损失。基于度量学习策略,来自相同极性的样本的特征在嵌入空间中彼此更接近。根据与给定图像的情感相似性对图像进行排序是有益的。
Local Information.
在复杂图像中,一些信息区域可能成为决定所唤起的主导情绪的关键因素[85],[127]。因此,通过检测区域来提高识别性能的研究迅速兴起。Sun等[110]、[128]利用现成的对象工具生成提案,然后计算对象和情感得分,从众多候选中选择最优区域。选择的区域与整个图像聚集在一起,以便在情感分类中使用更具歧视性的表示。Wu等[129]在[110]的基础上,采用显著目标检测模型捕获信息区域,然后将子图像和整幅图像馈送到网络中提取局部和全局特征。使用相同的主干(VGG-16),[129]在所有常用数据集上的性能优于[110]。我们有理由推断[129]通过将裁剪后的原始图像输入到网络中,可以捕获更多的判别信息。显然,在选择候选人时,上述方法耗费时间和计算量。后来开发出WSCNet[12],根据特征图上的响应自动生成单镜头的注意图,节省了大量的时间和计算资源。注意,每个注意力图是通过计算每个类的激活的加权和来获得的。在[130]中,通过将图像的焦点对象掩模或显著性图作为输入,在神经网络中添加了新的第四通道,称为焦点通道(focal channel)。
通过对情绪表征的局部信息进行编码,表明消极情绪主要由焦点区域引起,几乎不受语境的影响,而积极情绪则由焦点区域和语境共同决定。[131]提出了一种带有视觉注意力的情感网络(sentinel -A),该网络生成空间区域的注意力分布。然后从多尺度全卷积网络(FCN)中得到显著性图,以细化注意力分布。如何捕捉不同区域之间的情感关系是近年来研究的热点。Zhang等[132]基于贝叶斯网络对不同图像区域的对象语义之间的相关性进行建模,以推断图像情感。[133]提出了一种多关注金字塔模型来提取不同尺度的局部特征,然后利用自关注机制来挖掘不同区域特征之间的关系。
Knowledge of Other Fields
研究情绪识别还可以利用其他领域的知识。Yu等[134]考虑到图像的审美与情感之间的相关性,设计了一种新的统一的审美-情感混合网络(AEN),可以同时进行图像的审美评价和情感识别。受大脑中情感生成过程的启发,Zhang等[135]开发了一种多子网神经网络来模拟特定情绪信号的产生和大脑神经元中信号抑制的过程。
Quantitative Comparison of Representative?
深度的方法。如表8所示,我们通过实验对DCNN[30]、RCA[107]、WSCNet[12]、PDANet[111]等四种具有代表性的基于学习的方法进行了比较。
我们用四个不同的主干替换原始主干来评估有效性和鲁棒性,包括AlexNet[136]、VGG-16[114]、ResNet-50[18]和Inception-v3[137]。结果表明,不同方法的鲁棒性不同。与WSCNet和PDANet相比,当使用不同的架构作为主干时,RCA的鲁棒性更强,因为RCA在每个数据集上的结果波动比其他方法要小,尤其是在Flickr和Emotion6上。在RCA中,最终的图像表示包含来自多个层的特征,从而产生更丰富的信息,并且当使用较浅的网络时,识别能力不会显着降低。相比之下,仅基于最后一层特征的方法对所用骨干的深度更为敏感。一般来说,最近的研究结果,如RCA, WSCNet和PDANet,比DCNN的结果要好,DCNN不包含专门为情感设计的组件

在相同的输入大小、初始化、骨干网等常见实验设置下,RCA、WSCNet和PDANet的总体结果没有明显差异。对于不同的数据集,获得最佳性能的方法是不同的。例如,对于一个小规模数据集Twitter II(只有603张图像),考虑局部信息特征的方法(WSCNet和PDANet)比其他方法表现得更好。
5.2 Personalized Emotion Prediction
Yang等[31]首先提出基于用户兴趣和社会影响力来预测个人对社交图像的情绪。通过同时考虑文本和图像来建模用户兴趣,通过构建个性化字典和聚类基本颜色特征来预测文本和图像的情感。社会影响力是通过不同用户对同一微博的情感相似性来衡量的。通过挖掘用户的历史行为,获得用户兴趣和社会影响力的权重。后来,Rui等人用概率图模型扩展了权重策略[138]。从用户的历史行为中隐藏,使用图模型中的一组参数来估计内容和影响力的重要性。然而,这些方法也有一定的局限性。首先,提取的视觉特征非常简单,不能很好地反映视觉内容。其次,没有考虑几个重要的因素,如时间演变。第三,用户和图像之间的高阶相关性没有很好地建模。
在[15]、[139]中,Zhao等人在预测特定用户在观看与在线社交网络相关的图像后的个性化情绪(见图4b)时,对这些问题进行了若干改进。考虑了可能影响情绪感知的不同类型的因素:图像的视觉内容、与相应用户相关的社会背景、情绪的时间演变和图像的位置信息。滚动多任务超图学习就是将这些因素结合起来。每一个超图顶点都是一个复合的三重eu;x;ST,其中u代表用户,x和S是当前图像和最近的过去图像,分别称为“目标图像”和“历史图像集”。基于这3个顶点分量,构建了以目标图像为中心、以历史图像集为中心和以用户为中心的超边缘。从目标图像和历史图像集中提取视觉特征(主旨、元素、属性、原则、ANP和表达式)来表示视觉内容。用户关系是利用用户组件来考虑社会环境的。
从历史图像集中推断出过去的情感,以揭示时间的演变。位置嵌入到目标图像和历史图像集中。然后对多任务超图进行半监督学习,同时对多个用户的个性化情绪进行分类。
5.3 Emotion Distribution Learning
标签分布学习(LDL)[140]用于为图像的每个类别的相对重要性建模。离散空间中每个标签上的概率之和为1。它通常用于解决离散标签空间中情感的模糊性。
Peng等[14]构建了带有概率分布标注的Emotion6数据集。采用SVR、CNN和CNN回归(CNNR)作为情绪回归模型。特别是,针对每个类别训练不同的SVR和CNNR模型,而通过将输出神经元的数量改变为情感类别的数量,对所有类别训练CNN。Zhao等[32],[141]将情绪分布预测建模为共享稀疏学习(SSL)问题。输入是不同类型特征的组合,通过加权最小二乘迭代优化目标。后来在文献[61]中提出了加权多模态共享稀疏学习(weighted multi-modal shared sparse learning, WMMSSL),可以自动学习不同特征的权重。在条件概率中性网络(conditional probability neutral network, CPNN)的基础上,[140]提出了BCPNN[16],用二进制编码代替一般的无符号整数表示图像标签。此外,ACPNN是在BCPNN的基础上,在地面真值标签上加入噪声而发展起来的。通过这种策略,增强了情绪分布,有利于训练更健壮的模型。Zhao等[142]提出了加权多模态条件概率神经网络(Weighted Multi-Modal Conditional Probability Neural Network, WMMCPNN)来探索不同类型特征的最优组合系数。在[143]中,Yang等人设计了一个统一的框架来同时优化Kullback-Leibler (KL)损耗和softmax损耗。此外,考虑到某些数据集缺乏人工标注的情绪分布,本文提出了一种将单个情绪转换为概率分布的方案。
考虑到某些情绪的共存和互斥,在预测概率标签时,对不同情绪标签的关系进行建模是很重要的。
He和Jin[144]使用图卷积网络(GCN)对标签关系进行建模,用于标签分布预测。将情绪的GloVe-300词嵌入作为节点输入GCN,利用两种情绪共现的概率计算不同标签之间的关系。Liu等[145]将低秩和反协方差正则化项整合到一个情绪分布学习框架中。低秩正则化项用于学习低秩结构化嵌入特征,反协方差正则化项用于保证回归系数的结构化稀疏性。为了充分利用情绪强度的极性和特征,在[146]中利用结构化和稀疏注释来学习情绪标签分布。在连续情感空间中,Zhao等[17]采用高斯混合模型对连续分布进行建模,其中参数可通过期望最大化算法进行估计。将共享稀疏回归(SSR)作为学习模型,假设测试特征和测试参数可以由训练特征和训练参数线性表示,但具有共享系数。为了探索任务相关性,进一步提出了多任务SSR,通过适当的跨任务共享信息,同时预测不同测试图像的参数。
5.4 Learning From Noisy Data or Few Labels
Few-Shot or Zero-Shot Learning
如第1.1节所述,少/零学习和无监督/弱监督学习是解决标签缺失挑战的两种可能解决方案。Few/zero shot learning是指一种特定的机器学习,即基于很少甚至没有标记的示例来学习模型[38]。虽然人类只能通过少量样本进行学习,但机器很难做到这一点。传统方法通常为可见类和不可见类构建一个共享空间。对于可见类,空间是基于可见图像及其标签之间的对应关系来学习的。
依靠侧信息(例如,属性),首先将未见类与已见类关联起来,然后基于视觉特征和类语义表示之间的跨模态相似性映射到公共空间。情感差距的存在使得这种相似性难以计算。
Wang等[147]提出了一种利用辅助噪声数据的情感导航框架,以少量的精确样本为原型中心,引导噪声数据聚类。Zhan等[38]提出了一种情感结构嵌入框架,该框架利用ANP特征构建了一个中间嵌入空间,用于零镜头情感识别。此外,引入情感对抗约束来选择既保留情感结构信息又保留辨别能力的嵌入空间。
Unsupervised/Weakly-Supervised Learning.
无监督学习的目的是在没有预先存在的标签的数据集中发现以前未知的模式。两种主要的方法是聚类分析和主成分分析。如何自动确定聚类的数量是聚类研究中的一个关键问题。不同的是,Wang等人[148]利用视觉内容和相关文本信息之间的关系,对社会图像进行无监督情感分析。这种方法依赖于社交图片的附带文本。一方面,文本可能是不完整和嘈杂的。另一方面,可能没有可用的文本。在这种情况下,如何进行无监督分析是值得研究的。
对于社会图像,更实际的情况是对它们进行弱噪声标记[19],[102],[149],[150]。考虑到VSO数据集的图像被噪声弱标记,Wang等[102]估计噪声矩阵来重新加权softmax损失,可以补偿噪声标签导致的分类性能下降。通过重新加权损失进行再训练,学习到的模型对情绪图像具有更强的辨别能力。
Wu等人提出基于anp的情感对弱标记数据集进行细化,并提供了标签[149]。如果anp和标签的情绪相互矛盾,并且积极标签和消极标签的数量相等,则删除图像。剩下的图像被重新贴上标签的主导情绪。使用改进后的数据集,可以获得更好的性能。
Chen等人采用概率图模型过滤掉标签噪声[150]。Wei等[19]提出通过基于文本的蒸馏训练文本和视觉联合嵌入来降低网络标注标签中的噪声。设计一个有效的策略,可以更好地细化数据集或过滤标签噪声,有望提高性能。
Domain Adaptation/Generalization.
领域自适应研究如何将在标记的源域上训练的模型转移到另一个稀疏标记或未标记的目标域。一种直接的解决方案是使用gan将源图像转换到与目标图像无法区分的中间域[151],[152],[153]。
同时,应保留源标签。现有的一些无监督域自适应方法都是基于这种直觉。Zhao等[35]研究了情绪分布学习中的领域适应问题。他们开发了一个对抗模型,称为EmotionGAN,通过交替优化GAN损失、语义一致性损失和回归损失。语义一致性损失保证了翻译后的中间图像保留了源标签。由于传统GAN不稳定且容易失效[152],设计了周期一致GAN (CycleGAN)。Zhao等人基于CycleGAN,在不需要对齐图像对的情况下,在适应主导情绪时强制语义一致性[36],[37]。He和Ding提出了一种基于差异的领域自适应方法[154]。通过最小化联合最大平均差异来减小全连通层的边际和联合域分布差异。在不生成中间域的情况下,该方法旨在提取更多可转移的特征。
上述所有方法都侧重于单一源场景。
然而,在实践中,标记的数据可能从具有不同分布的多个来源收集。简单地将多个源合并为一个源并执行单源域适应可能会导致次优解决方案。在[155]中,Lin等人研究了用于图像二值情感分类的多源域自适应。具体来说,设计了一个多源情感生成对抗网络(MSGAN)来寻找一个统一的情感潜在空间,其中源图像和目标图像具有相似的分布。MSGAN包括三个流程:图像重建、图像平移和周期重建。结果表明,与最佳的单源自适应方法相比,探索多源的互补性可以大幅度提高自适应性能。
不同的是,Panda等[22]研究了AICA的领域泛化问题,以克服数据集偏差。通过收集股票网站上的图像,构建了一个弱标记的大规模情感数据集,以涵盖广泛的情感概念。提出了一种简单而有效的课程引导训练策略来学习判别情绪特征,该策略比现有数据集具有更好的泛化能力。
6 AICA BASED APPLICATIONS
随着AICA的蓬勃发展,相关的应用已经或将在不同的方向上被提上日程,包括意见挖掘、商业智能、心理健康、娱乐助理等等。
6.1 Opinion Mining
如今,越来越多的人使用图像来表达他们对某些事件的观点或态度。通过对这些共享图片的分析,我们可以推断出不同用户的情绪,包括上传者和评论者。此外,我们可以推测他们对特定事件或产品的态度。文献[15]利用超图模型对视觉内容、社会情境、时间演化和位置影响等不同类型的因素进行建模,迭代优化个人社会形象情绪预测。此外,根据用户的兴趣或背景,还会形成各种虚拟小组。分析群体情绪有助于预测社会趋势。
基于上述技术,我们可以想象,对社会形象情感的理解可以用于舆情分析及相关应用。
在产品评论等特殊领域,用户的体验已经根据上传图片的情绪进行了调查和评估。在[156]中,Truong和Lauw进行了视觉情感分析,以便更好地理解关于不同产品、服务和场所的评论图像。在这个过程中,用户因素和物品因素都被考虑在内。Ye等[157]联合使用视觉和文本分类来分析产品评论的情感。构建了一个名为Product reviews - 150k (PR-150K)的数据集。在[158]中,Hassan等人通过考虑人们的观点、态度、感受和情绪来分析灾害相关图像所引发的情绪。该研究为未来灾害相关图像情感分析的研究奠定了基础。因此,通过分析相关图像的情绪来挖掘用户意见的积极或消极方面具有重要意义。
6.2 Psychological Health
随着社交媒体的普及,人们在互联网上分享他们的情绪,而不是与他们真正的朋友。对于持续分享负面信息的用户,有必要进一步跟踪其心理状态,防止心理疾病甚至自杀的发生。
Guntuku等人[159]揭示了twitter个人资料和帖子图像如何反映抑郁和焦虑。文献[160]通过分析多模态微博数据的情感内容,提出了一种针对社交网络用户的自动应力检测模型。基于这个模型,我们可以进一步为用户设计后续的解压服务,包括播放一些平滑的音乐,播放一些有趣的视频,提供一些形式的练习等。
在心理学领域,情感意象被用来进行一些研究。例如,IAPS[28]是一个图像数据库,它的构建是为了提供一个标准化的集合,以唤起人们的目标情绪,用于研究心理状态。每张图片都列出了引发情绪的平均评分,这些评分可以用于心理学理论的各个研究方向。[161]在著名的临床心理健康人格诊断工具明尼苏达多相人格量表(MMPI)[162]的基础上,构建了一套新的图像系统清华心理图像系统(Tsinghua psychological image system, ThuPIS)。该系统可用于支持监测人类心理健康的新心理测试。
6.3 Business Intelligence
形象在传达商业信息中起着至关重要的作用,因此选择具有适当情感的形象有利于企业的发展。例如,大多数广告都使用视觉内容来唤起观众强烈的情感刺激。消费者研究[163]已经证明情绪可以影响决策过程。一个设计良好的广告可以吸引人们的注意力,唤起观众的积极情绪,从而在观看相应定制的广告时产生购买欲望。Holbrook和O’shaughnessy[164]研究了情感在广告中的作用。具体来说,他们将情感与其他类型的消费者反应区分开来,并从广告中的情感内容中研究情感的产生过程。并对今后考虑情感因素的广告设计提出了建议。Poels和Dewitte[165]回顾和更新了广告中情绪的测量方法,并进一步讨论了其适用性。最后,研究了情绪对广告效果的影响。
在旅游领域,情感是评价旅游整体体验的一个不可忽视的重要因素[166]。文献[167]通过分析社交网络上上传的旅游照片,探讨了地点动机、图像维度和情感品质之间的关系。文章揭示了自然资源,包括“动植物”、“乡村”、“海滩”等,总是与特定目的地的“唤起”和“愉快”的感觉联系在一起。此外,长镜头拍摄的旅行照片,在眼睛的水平,具有鲜明的密度水平,可以引起幸福的感觉。
这些发现可以指导在一些特定的平台上展示更具吸引力的旅行照片,从而发起成功的营销努力,促进旅游业的蓬勃发展。文献[168]通过发放自填问卷的方式对游客的情感体验进行了调查。每个目的地的情绪反馈(兴奋和愉悦)被绘制在相应的二维网格上。Hosany和Prayag[169]对游客的情绪反应模式进行了实证研究,并探讨了这些情绪反应模式与消费满意度的关系。通过聚类分析,得出了五种不同的情绪反应模式(高兴、不激动、消极、混合、激情),这些模式是基于爱、惊喜、快乐和不愉快所定义的四维情感空间。据报道,这五种模式在满意度和推荐意图上是不同的。未来,基于更细粒度的情感分析,我们可以为有不同旅行体验的用户自动构建个性化的目的地推荐系统。
6.4 Entertainment Assistant
如今,娱乐标准已经将情感作为决定娱乐体验的关键因素[170]。同时,情感也可以用来评价娱乐体验。
例如,情感可以被视为连接不同形式的数据(如图像和音乐)的媒介。在[171]中,基于差分和进化支持向量机(DE-SVM)设计了一个情感驱动的跨媒体检索系统。该系统可以实现中国民间音乐与中国民间形象之间基于情感的检索。Chen等人[172]和Zhao等人[173]设计了一个计算音乐和图像之间情感相似性的系统。有了这个系统,用户可以从他们的个人相册照片中生成情绪感知音乐幻灯片。
漫画中的情感在吸引人们方面起着至关重要的作用。
印尼读者广泛接受日本漫画的原因有研究[174]。该报告指出,漫画对他们来说不仅是一种娱乐,也是一种重要的生活体验,情感是其中的重要元素。因此,我们在衡量漫画时应该考虑到所唤起的情感。在[82]中,构建了一个大规模的漫画数据集,其中图像被标记为Mikel 's wheel中定义的情感。随着娱乐领域对AICA的关注越来越多,我们可以基于各种类型的图像与聊天机器人建立对话,而不仅仅是基于文本。
7 FUTURE DIRECTIONS
尽管情感图像内容分析(affective image content analysis, AICA)已经取得了显著的进展,但在心理学、认知科学、多媒体和机器学习等不同学科的共同努力下,仍然存在一些值得研究的开放性问题和方向。
7.1 Image Content and Context Understanding
由于观众的情绪可能会被图像内容直接唤起,因此准确分析图像所包含的内容可以显著提高AICA的性能。如第4节所述,存在不同类型的情绪特征。虽然深度的通常比手工制作的要好,但手工制作的和深度的结合是否能提高性能还不清楚。如果是,如何有效地融合它们?此外,深层特征与特定情绪之间的关系尚不清楚,而手工制作的特征——尤其是中级和高级特征——则更容易理解。使用手工制作的特征来指导生成可解释的深度特征是一个有趣的话题。有时候,我们甚至需要对图像内容进行细致的分析。例如,我们可能会对美丽的花朵感到“快乐”;但是,如果鲜花放在葬礼上,我们可能会感到“悲伤”。如果一张图片是关于一个可爱的孩子的笑声,我们更有可能感到“好笑”;但如果是关于一个已知的邪恶统治者或罪犯的笑声,我们可能会感到“愤怒”。构建一个大规模的存储库并收集足够的相应映像可以帮助解决这个问题。如图3所示,图像的上下文也非常重要。多模态情感识别将更有意义,如文本-视觉数据[150],[175]和视听数据[176]。一个关键的挑战是如何融合不同模式的数据。
7.2 Viewer Contextual and Prior Knowledge Modeling
观众观看图像时的情境信息对情绪感知有显著影响。同一位观众对同一幅图像的感受会因气候、时间、社会背景等不同而不同[15]。结合这些重要的上下文因素可以提高性能。利用概率图或超图模型来表示不同因素之间的复杂相关性被证明是可行的[15],[79],[177]。我们可以通过最近的图卷积网络[178]和超图神经网络[179]进一步尝试对这些因素进行建模。
观众的性别、性格等先验知识也会影响情感感知。例如,一个乐观的观众和一个悲观的观众可能对同一图像有完全不同的情绪。
Wu等人研究了用户人口统计数据(包括性别、婚姻状况和职业)对社交图像情感感知的影响[180],[181]。
除了视觉内容、时间相关性和社会相关性外,用户人口统计数据也被作为因子函数纳入因子图模型。结果表明,用户人口统计数据确实可以提高整体情绪分类性能。然而,在社交网络上收集到的先验知识可能是不准确的。如何自动过滤噪声信号还没有研究。
7.3 Learning From Noisy Data or Few Labels
Few-Shot or Zero-Shot Learning
目前针对AICA的few-shot/zero-shot学习方法存在一定的局限性[38],[147]。首先,并非所有看到的图像都有助于生成嵌入空间。如何自动选择代表性图像以产生更好的嵌入空间尚不清楚。第二,嵌入过程可能导致信息丢失,跨模态相似性不能充分利用数据分布。我们可以考虑根据估计的分布为未见类合成可靠的样本。随着生成对抗网络(GANs)[151]的成功,这样的想法将具有真正的潜力。
Domain Adaptation/Generalization.
在这种情况下,域自适应任务成为半监督场景。一个有趣的问题是,至少需要多少标记的目标图像才在实践中,我们可能有一些标记的目标图像。能达到甚至超过在目标域上完全训练的结果。除了半监督域自适应之外,还有一些具有挑战性的问题,包括异构域自适应(源域和目标域之间的标签空间不同)、开放集域自适应(源域和目标域都包含不属于感兴趣类别的图像)和类别转移域自适应(来自不同来源的类别可能不同)。
虽然目标图像(尽管没有标签)在领域适应中是可用的,即在训练过程中目标图像是可访问的,但领域泛化在不访问任何目标图像的情况下学习模型[182]。
为了丰富泛化能力,一种可能的解决方案是在训练阶段使用域随机化方法将标记好的源图像随机化到足够数量的域[183],然后目标域在很大程度上属于随机化域,这样在随机化域上训练的模型就能很好地适应目标域。
7.4 Group Emotion Clustering
简单地识别一张图片的主要情绪过于笼统,而预测每个用户的个性化情绪又过于具体。由于一些用户群体或小团体,他们有着相似的品味或兴趣和相似的背景,更有可能对相同的图像做出相似的反应,因此预测这些群体或小团体的情绪将更有意义。分析每个人提供的用户配置文件,根据性别、背景、品味、兴趣等将用户划分为不同类型的组,这可能是一种可行的解决方案。
目前对群体情绪的研究主要集中在识别参加各种社会活动的图像中包含的人群的情绪[184],[185]。对人群的情感形象分析,即识别群体的诱导情绪,尚未得到探索。群体情感识别在推荐中起着重要的作用。例如,对于同一群体中的人来说,如果一个人对某种特定的产品感兴趣,其他人就更有可能接受它。
7.5 Viewer-Image Interaction
除了对图像内容的直接分析外,我们还可以记录和分析观看者在观看图像时的视听或生理反应(如面部表情或脑电图信号),这通常被称为内隐情感标记。目前的方法主要集中在视频上[186]、[187]、[188]、[189],因为视频在时间上具有相对的情感一致性。探索观众对图像内隐情绪分析的反应仍然是一个很大程度上开放的研究课题。将图像内容和观众的反应联合建模可以更好地弥合情感差距,从而获得更好的性能。在实践中,一些数据可能会丢失或损坏。例如,一些生理信号不能被成功捕获。在这种情况下,应该考虑如何处理丢失的数据。
如第1节所述,生理反应要么难以捕捉,要么很容易被抑制。在现实应用中,即使没有生理反应,在训练过程中共同探索特权模态也可能比只使用图像模态带来更好的表现。
7.6 Novel and Real-World AICA-Based Applications
随着大规模数据集的可用性和机器学习的改进,特别是在深度学习方面,AICA的性能将得到显著提升。因此,我们预见到一个基于ai的真实世界应用的情商时代的到来。例如,在在线时尚推荐中,智能客户服务,如客户形象互动,可以为客户提供更好的体验。在广告中,生成或策划能够强烈唤起预期情绪的图像可以吸引更多的注意力。一种初步的图像调整系统在[190]中实现。给定一个输入图像和一个情感词,系统可以调整图像颜色以满足所需的情感。仅更改颜色信息,在应用中可能不足。Peng等人则提出通过改变颜色和纹理相关特征,将给定源图像的诱发情绪分布修改为目标图像的诱发情绪分布[14]。
我们认为基于gan的对抗模型可能更适合于生成情感图像。在艺术理论中,我们可以理解艺术家是如何通过他们的作品来表达情感的。这些原则可以指导情感意象的生成。生成的合成图像可以通过域自适应来改善AICA的结果。在教育中,情感丰富的图像可以帮助孩子更好地学习和理解。当然,更多令人兴奋的应用程序将很快出现。
7.7 Efficient AICA Learning’
深度学习的成功有三个因素:增加的计算能力、深度复杂模型和足够的标记数据。然而,这些因素可能无法用于边缘设备,如手机,在我们的日常生活中广泛使用,但有限的功率,内存和计算能力。因此,需要设计专业化、高效的“绿色”深度学习模型。有效的模型设计一直是计算机视觉研究的热点。一些有效的表示方法包括自动通道修剪、师生网络方法、神经网络与硬件加速器协同设计、自动混合精度量化、最优神经结构搜索等。
据我们所知,效率问题在非洲还没有得到很好的研究。将计算机视觉中的现有方法扩展到AICA任务,通过结合其特殊性(例如,情绪层次)是一个简单但有效的解决方案。如果设备上的训练模型能够使用增量数据在线学习,这将更有意义。
7.8 Benchmark Dataset Construction
现有的AICA研究采用的数据集主要是标记良好的小规模数据集(如IAPSa[29])或通过关键词搜索策略获得标签的大规模数据集(如IESN[15])。由于前一种方法没有足够的训练样本,因此后一种方法无法保证自动标注的标签质量。创建一个大规模、高质量的数据集,如计算机视觉中的ImageNet,可以极大地推动人工神经网络的发展。一种可能的解决方案是利用在线系统和众包平台,邀请/吸引大量具有代表性背景的观众,以注释他们对图像的个性化情感感知以及他们情绪反应的上下文信息。个性化的情绪注释更符合情绪的主观性。
进一步,从个性化的情绪中,我们可以得到主导情绪和情绪分布。收集社交媒体用户与图像的互动,如点赞、评论,以及他们的自发反应,如面部表情,在可能的情况下,可以提供更多的信息来丰富情感数据集。为了促进AICA在不同情绪需求的实践中的适用性,采用带有情绪强度的分层模型(如Parrott[64])是一个不错的选择。
8 CONCLUSION
这篇文章试图提供一个全面的调查,最近发展的情感图像内容分析(AICA)在过去的二十年。显然,它不能涵盖所有关于AICA的文献,我们关注的是最新方法的一个代表性子集。我们总结和比较了目前广泛使用的情感表征模型、可用的数据集以及情感特征提取、学习方法和基于ai的应用等方面的代表性研究成果。最后,讨论了该领域有待解决的问题和未来的研究方向。尽管基于深度学习的AICA方法近年来取得了显著的进展,但尚未设计出一种有效、高效、鲁棒的AICA算法,并能在无约束条件下取得令人满意的性能。随着脑科学对情绪唤起的深入理解、心理学对情绪的精确测量以及机器学习中新颖的深度学习网络架构的快速发展,我们相信AICA将在很长一段时间内继续是一个活跃和有前景的研究课题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!