【论文阅读】AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion
AADiff:基于文本到图像扩散的音频对齐视频合成。
code:没开源
paper:[2305.04001] AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion (arxiv.org)
一种新的T2V框架,额外使用音频信号来控制时间动态,使现成的T2I扩散能够生成音频对准的视频。我们提出了基于音频的区域编辑和信号平滑,平衡了时间灵活性和连贯性。
1 介绍
文本到视频模型仍处于起步阶段。例如,完全依赖文本提示来指导整个生成过程,因此建模详细的时间动态方面困难。此外,输出缺乏音频,更接近动画gif而不是视频。即使在有音频先验的情况下,也不容易将视频输出与这个附加条件同步。
作者希望地将音频模态合并到传统T2I中,实现更可控的时间扩展。具体来说,给定一个T2I扩散模型,如stable diffusion 1,使用文本和音频来指导视频合成,前者侧重于可视化场景语义,而后者更负责时间动态的细粒度控制。
总结贡献:
- 第一个使用文本和音频的组合来指导视频合成的扩散模型。
- 提出了一个简单而有效的框架,用于文本到图像模型的音频同步视频生成,无需额外的训练或配对数据。
- 制作与音频输入同步的视频,提供内容创建应用程序。
应用:媒体创作者可以使用公共声源制作短视频,同时使用不同的文本提示操作场景构图和外观。与Null inversion等图像反演技术相结合时,可以将音频对应的图像动画化。框架与其模型组件是正交的,因此可以不断地从生成模型的进步中受益。方法建立在稳定扩散的基础上,在512 × 512的尺度下进行高质量的视频合成。
2 方法

图1方法概述。给定音频信号和文本提示,首先分别由音频编码器和文本编码器嵌入。选择具有最高相似度的文本标记并用Prompt-to-prompt编辑图像,其中平滑的音频幅度控制注意力强度。?
2.1 先验知识
对比式语言-音频预训练(CLAP):通过使用两个编码器和CLIP中的对比学习,来整合文本和音频。
Latent Diffusion Model (LDM):计算效率高的扩散模型,使用Variational Auto-Encoder,首先将像素值映射到潜在码,然后在潜在空间中进行顺序去噪操作。
2.2?Audio-aligned扩散
目标是生成一个与提示相对应的视频,在此提示上,添加基于声音的精细动态效果。
采用了三种预训练基础模型:文本编码器、音频编码器和扩散主干。对于文本编码器和扩散生成器,使用Stable diffusion和CLIP。
CLAP用于生成音频嵌入,根据两两相似度,突出显示top-k文本标记。有了感兴趣的文本标记,得到如Prompt-to-prompt所示的空间注意力图。一般选择k = 1。
2.3?带有注意力图控制的局部编辑
Prompt-to-prompt是一种通过注意图控制进行文本驱动图像编辑的方法。使用图像翻译执行视频合成时,用音频查询的top-k文本token进行局部语义编辑。为了模拟音频信号的时间动态,沿时间轴取输入音频的幅值,并将其用作控制每个时间帧图像编辑强度的乘子。具体来说,音频幅度乘以目标文本标记与图像之间的注意图,当音频信号较强时,突出显示的区域会发生急剧变化。这限制了输出视频与音频信号的同步。
2.4?用滑动窗口平滑音频
使用音频幅度作为引导信号提供了时间上的灵活性。但,利用每个时间框架的原始值会导致输出不稳定。为了克服这个问题,在音频幅度上应用一个大小为5的滑动窗口。这平滑了音频信号的变化,并有助于制作更自然和连贯的动态视频。不同窗口大小的影响如图2所示。
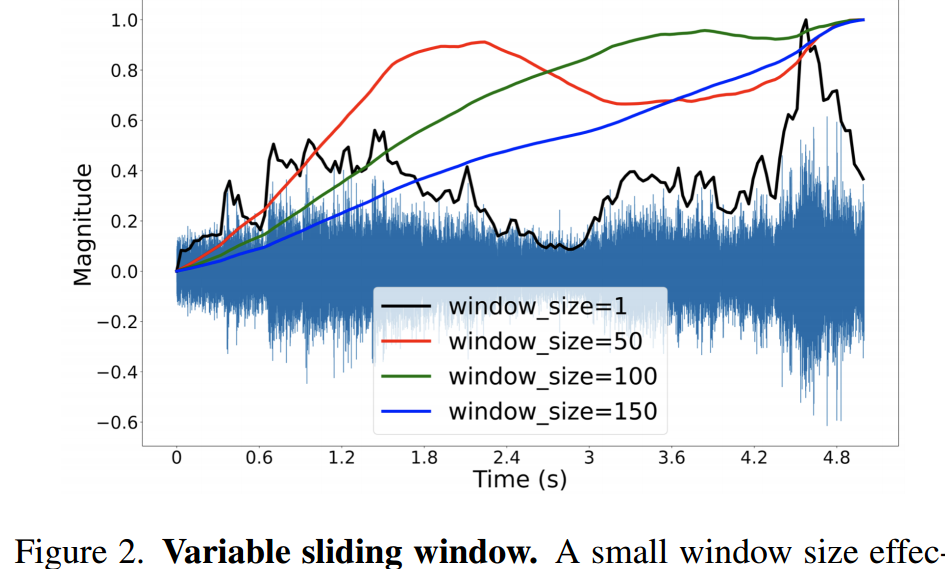
图2。可变滑动窗口。较小的窗口大小可以有效地捕捉动态变化,例如打雷。较大的窗口大小则擅长于表示渐变,例如野火蔓延。这个超参数允许内容创建者灵活地控制视频的时间动态。
?
3 实验
?
?图3。不同声源的定性结果。
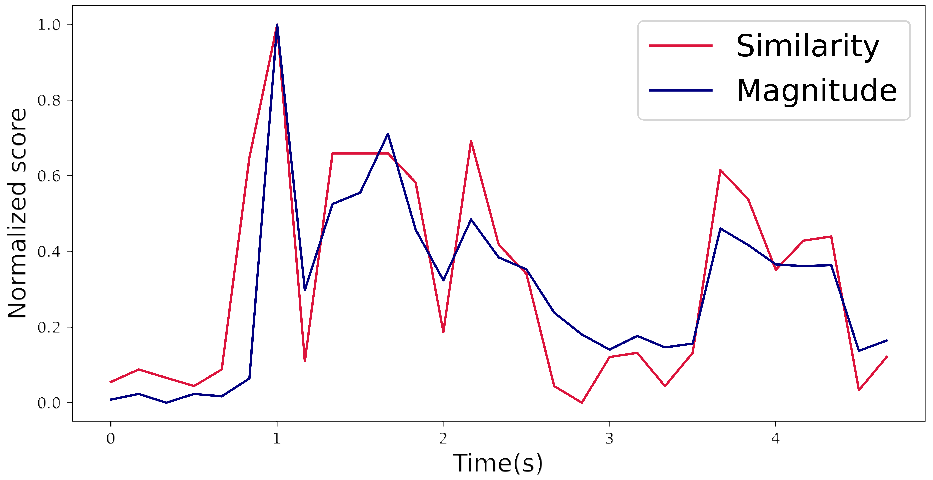
?图4。剪辑相似度和音频大小。这两个值是一致的,表明我们的模型忠实地反映了视频语义中的音频动态。

图5。零反演的定性结果。我们的方法可以将真实图像和音频源结合起来,创造出更加身临其境的视听内容。

?图6。窗口大小分析。无窗口(s = 1)导致过度波动,而无限窗口(s = 150)过度限制了时间动态。我们在中档找到最佳点。
没有窗口,时间动态太不稳定,导致时间不一致的输出。应用无限窗口时,视频被过度的动量拖动,产生类似于静止图像的样本。我们在中间找到一个最佳点,在不过度损害动态灵活性的情况下保证一定程度的时间一致性。
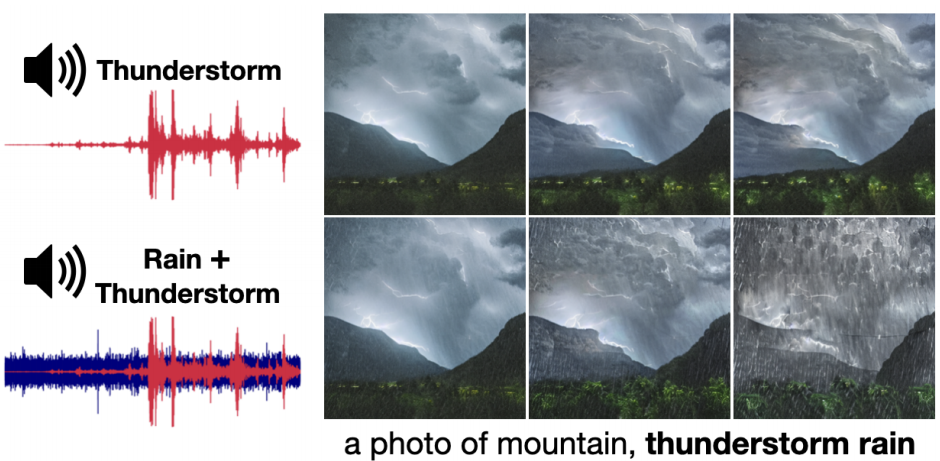
图7。视频合成从多个音频信号。AADiff可以利用混合在音频输入中的不同语义,并生成自然结合这些概念的视频。?

图8。通过不同的音频幅度,可以进一步控制变形的程度。?
 ?
?
图9。与传统的文本到视频模型不同,AADiff结合了音频输入的时间动态,当给出同一类的不同声音时产生不同的视频。?
框架是如何整合音频信号的:尽管被赋予相同的声音类别(如雷雨),但由于音频内容的不同,输出的视频也具有不同的视觉动态。这将我们的方法与纯文本驱动的视频合成方法区别开来,后者通常缺乏以细粒度方式控制时间动态的手段。
4 结论
提出了一个新的框架,将文本和音频作为输入并生成音频同步视频。由于不需要额外的训练或任何形式的配对数据,它可以以简单的方式充分利用最先进的多模态基础模型。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!