【PySpark】Python 中进行大规模数据处理和分析
一、前言介绍
二、基础准备
三、数据输入
四、数据计算
五、数据输出
六、分布式集群运行
一、前言介绍
Spark概述
Apache Spark 是一个开源的大数据处理框架,提供了高效、通用、分布式的大规模数据处理能力。Spark 的主要特点包括:
-
速度快:
Spark 提供了内存计算功能,相较于传统的批处理框架(如Hadoop MapReduce),Spark 能够更高效地执行数据处理任务。Spark 将中间数据存储在内存中,减少了磁盘 I/O,从而加速了计算过程。 -
通用性:
Spark 提供了用于批处理、交互式查询、流处理和机器学习等多种计算模式的 API。这种通用性使得 Spark 在不同的数据处理场景中都能发挥作用。 -
易用性:
Spark 提供了易于使用的高级 API,其中最为知名的是 Spark SQL 和 DataFrame API。这些 API 可以让用户用 SQL 查询语言或类似于 Pandas 的操作方式对数据进行处理,降低了使用门槛。 -
弹性计算:
Spark 可以在集群中分布式执行计算任务,充分利用集群中的计算资源。它具有自动容错和任务重启的机制,保障了计算的稳定性。 -
丰富的生态系统:
Spark 生态系统包括 Spark SQL、Spark Streaming、MLlib(机器学习库)、GraphX(图计算库)等模块,提供了全面的大数据处理解决方案。
Spark 的核心概念包括:
-
RDD(Resilient Distributed Dataset): RDD 是 Spark 中的基本数据抽象,代表分布式的不可变的数据集。Spark 的所有计算都是基于 RDD 进行的。
-
DataFrame: DataFrame 是 Spark 2.0 引入的一种抽象数据结构,提供了类似于关系型数据库表的操作接口。DataFrame 可以通过 Spark SQL 进行查询和操作。
-
Spark SQL: Spark SQL 提供了用于在 Spark 上进行结构化数据处理的 API。它支持 SQL 查询、DataFrame 操作和集成 Hive 查询等。
-
Spark Streaming: Spark Streaming 允许以流式的方式处理实时数据,提供了类似于批处理的 API。
-
MLlib: MLlib 是 Spark 的机器学习库,提供了一系列常见的机器学习算法和工具,方便用户进行大规模机器学习任务。
-
GraphX: GraphX 是 Spark 的图计算库,用于处理大规模图数据。
总体而言,Spark 是一个灵活、强大且易于使用的大数据处理框架,适用于各种规模的数据处理和分析任务。
PySpark概述
PySpark 是 Apache Spark 的 Python API,用于在 Python 中进行大规模数据处理和分析。Spark 是一个用于快速、通用、分布式计算的开源集群计算系统,而 PySpark 则是 Spark 的 Python 版本。
以下是使用 PySpark 进行基本操作的简要步骤:
-
安装 PySpark:
使用以下命令安装 PySpark:pip install pyspark -
创建 SparkSession:
在 PySpark 中,SparkSession是与 Spark 进行交互的入口。可以使用以下代码创建一个SparkSession:from pyspark.sql import SparkSession # 创建 SparkSession spark = SparkSession.builder.appName("example").getOrCreate() -
读取数据:
PySpark 提供了用于读取不同数据源的 API。以下是从文本文件读取数据的示例:# 从文本文件读取数据 data = spark.read.text("path/to/textfile") -
数据转换和处理:
使用 PySpark 的 DataFrame API 进行数据转换和处理。DataFrame 是一个类似于表的数据结构,可以进行 SQL 风格的查询和操作。# 展示 DataFrame 的前几行数据 data.show() # 进行数据筛选 filtered_data = data.filter(data["column"] > 10) -
执行 SQL 查询:
使用 PySpark 提供的 SQL 接口,可以在 DataFrame 上执行 SQL 查询。# 创建临时视图 data.createOrReplaceTempView("my_table") # 执行 SQL 查询 result = spark.sql("SELECT * FROM my_table WHERE column > 10") -
保存结果:
将处理后的结果保存到文件或其他数据源。# 保存到文本文件 result.write.text("path/to/output") -
关闭 SparkSession:
在完成所有操作后,关闭 SparkSession。# 关闭 SparkSession spark.stop()
以上是一个简单的 PySpark 示例。实际应用中,可以根据具体需求使用更多功能,例如连接不同数据源、使用机器学习库(MLlib)进行机器学习任务等。 PySpark 提供了强大的工具和库,适用于大规模数据处理和分析的场景。
Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。
而Python语言,则是Spark重点支持的方向。
二、基础准备
1、PySpark库的安装
同其它的Python第三方库一样,PySpark同样可以使用pip程序进行安装。
在”CMD”命令提示符程序内,输入:
pip install pyspark
或使用国内代理镜像网站(清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
2、PySpark执行环境入口对象的构建
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境入口对象是:类 SparkContext 的类对象
"""
演示获取PySpark的执行环境入库对象:SparkContext
并通过SparkContext对象获取当前PySpark的版本
"""
# 导包
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 打印PySpark的运行版本
print(sc.version)
# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
3、PySpark的编程模型

总结
- 如何安装PySpark库
pip install pyspark - 为什么要构建SparkContext对象作为执行入口
PySpark的功能都是从SparkContext对象作为开始 - PySpark的编程模型是?
- 数据输入:通过SparkContext完成数据读取
- 数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成计算
- 数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
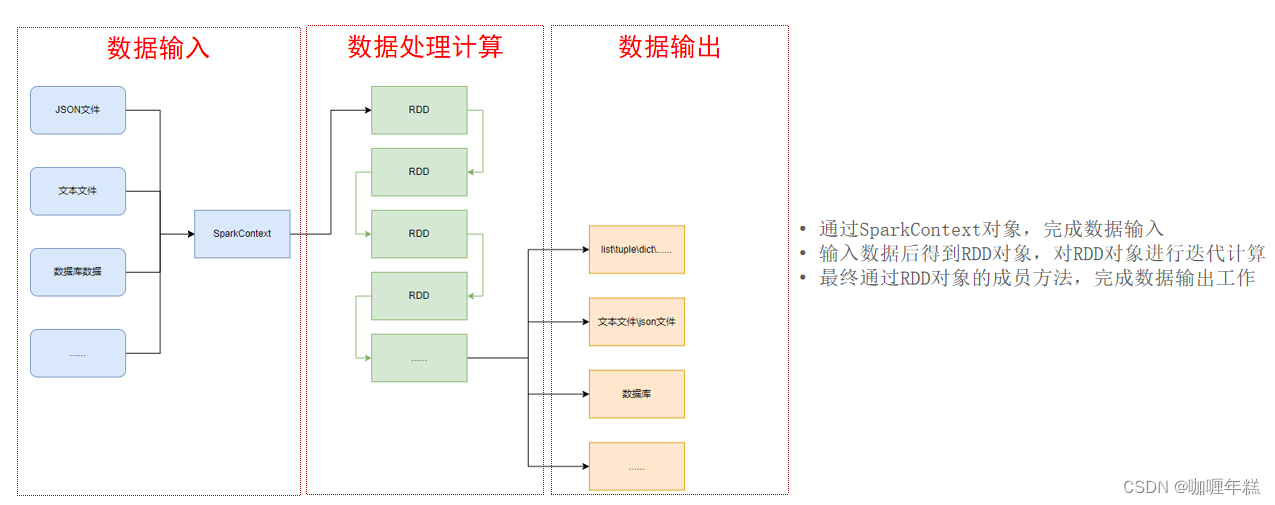
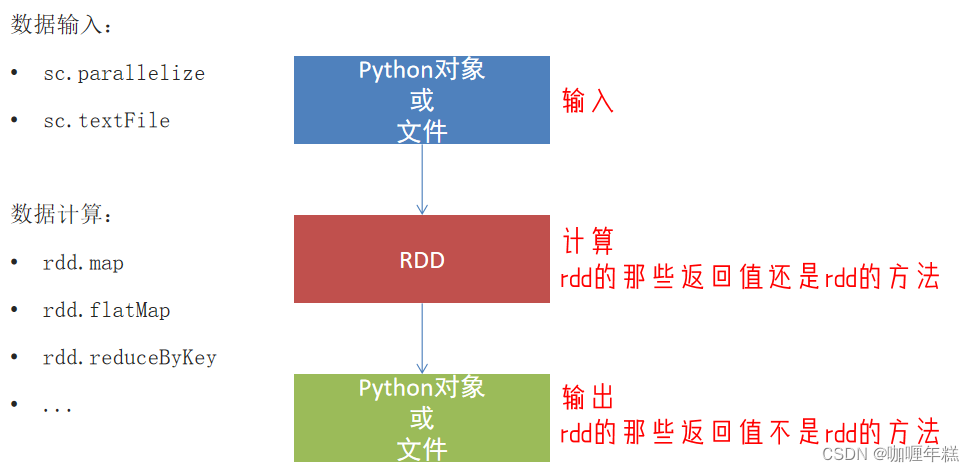
三、数据输入
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
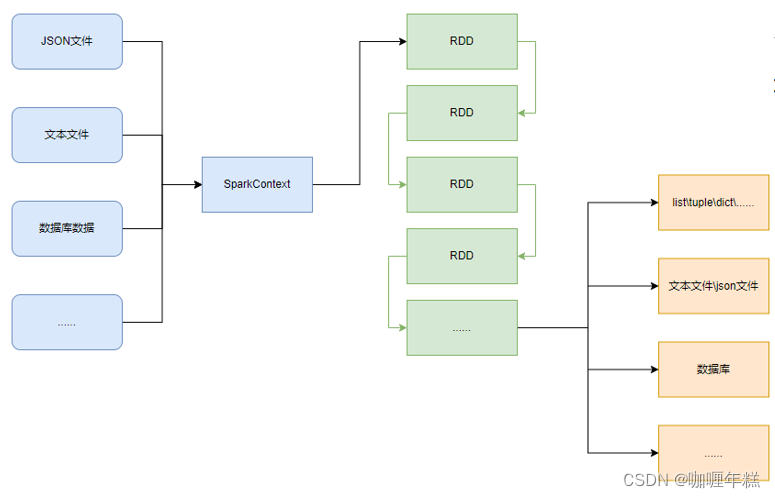
PySpark的编程模型(上图)可以归纳为: - 准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等
- 即:源数据 -> RDD -> 结果数据
PySpark数据输入的2种方法
Python数据容器转RDD对象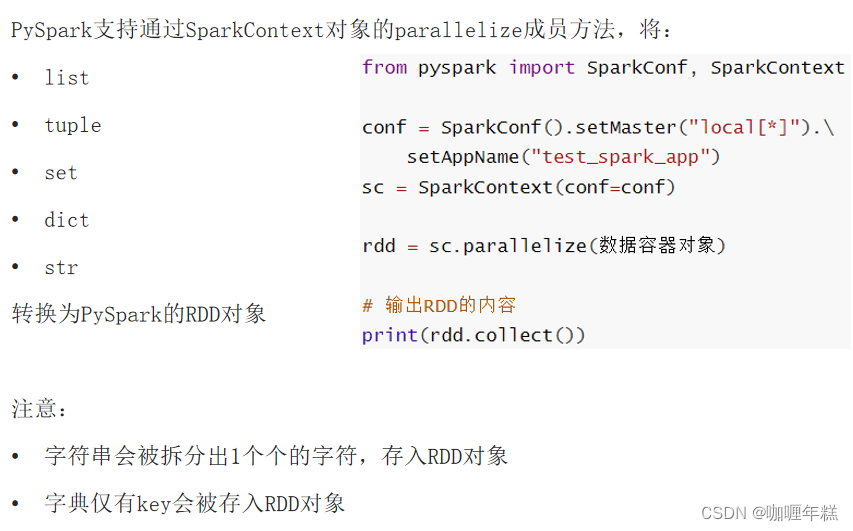
读取文件转RDD对象

总结
- RDD对象是什么?为什么要使用它?
-
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD迭代计算)
-
后续对数据进行各类计算,都是基于RDD对象进行
- 如何输入数据到Spark(即得到RDD对象)
- 通过SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象
- 通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
四、数据计算
1、map方法
PySpark的数据计算,都是基于RDD对象来进行的,那么如何进行呢?
自然是依赖,RDD对象内置丰富的:成员方法(算子)

"""
演示RDD的map成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map方法将全部数据都乘以10
# def func(data):
# return data * 10
rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5)
print(rdd2.collect())
# (T) -> U
# (T) -> T
# 链式调用

总结
- map算子(成员方法)
接受一个处理函数,可用lambda表达式快速编写
对RDD内的元素逐个处理,并返回一个新的RDD - 链式调用
对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子。
2、flatMap方法

"""
演示RDD的flatMap成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize(["itheima itcast 666", "itheima itheima itcast", "python itheima"])
# 需求,将RDD数据里面的一个个单词提取出来
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect())
总结
flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能
3、reduceByKey方法

"""
演示RDD的reduceByKey成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([('男', 99), ('男', 88), ('女', 99), ('女', 66)])
# 求男生和女生两个组的成绩之和
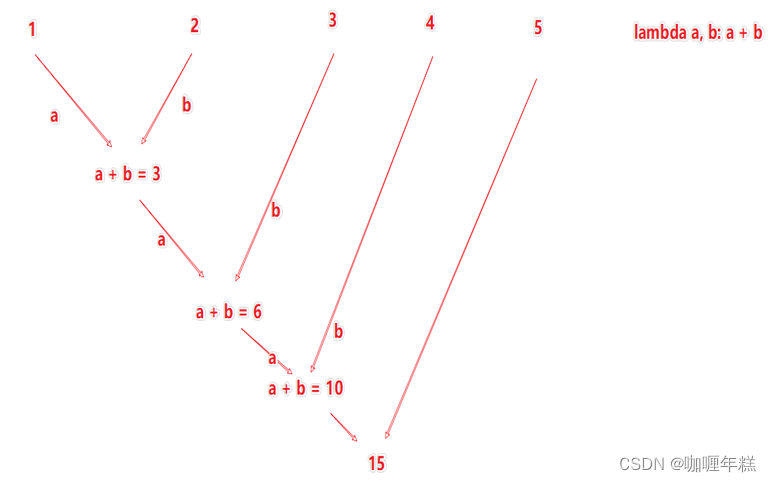
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect())
总结
reduceByKey算子
接受一个处理函数,对数据进行两两计算
WordCount案例
"""
完成练习案例:单词计数统计
"""
# 1. 构建执行环境入口对象
from pyspark import SparkContext, SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 2. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 3. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 4. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 5. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 6. 打印输出结果
print(result_rdd.collect())
4、filter方法
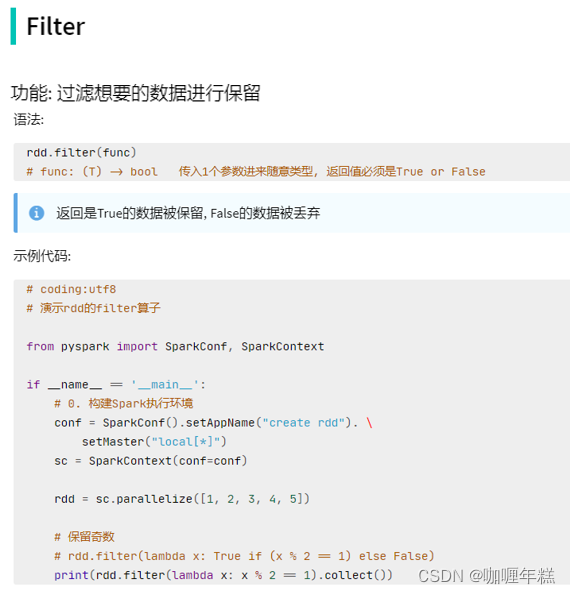
"""
演示RDD的filter成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 对RDD的数据进行过滤
rdd2 = rdd.filter(lambda num: num % 2 == 0)
print(rdd2.collect())
总结
filter算子
- 接受一个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
5、distinct方法

"""
演示RDD的distinct成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 1, 3, 3, 5, 5, 7, 8, 8, 9, 10])
# 对RDD的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())
总结
distinct算子
完成对RDD内数据的去重操作
6、sortBy方法
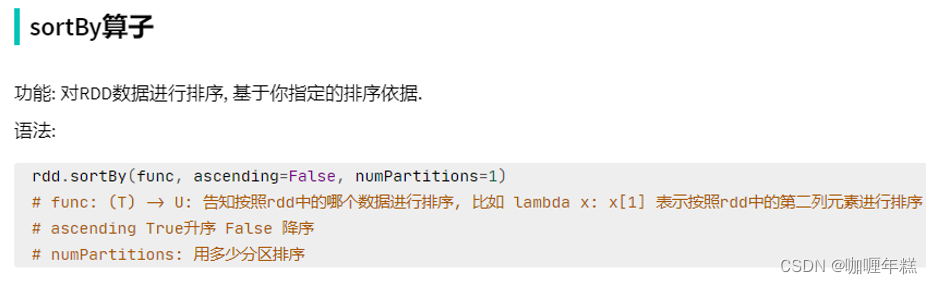
"""
演示RDD的sortBy成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 1. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 2. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 3. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 4. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 5. 对结果进行排序
final_rdd = result_rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=1)
print(final_rdd.collect())
总结
sortBy算子
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1
五、数据输出
1、输出为Python对象
将RDD的结果输出为Python对象的各类方法
collect方法

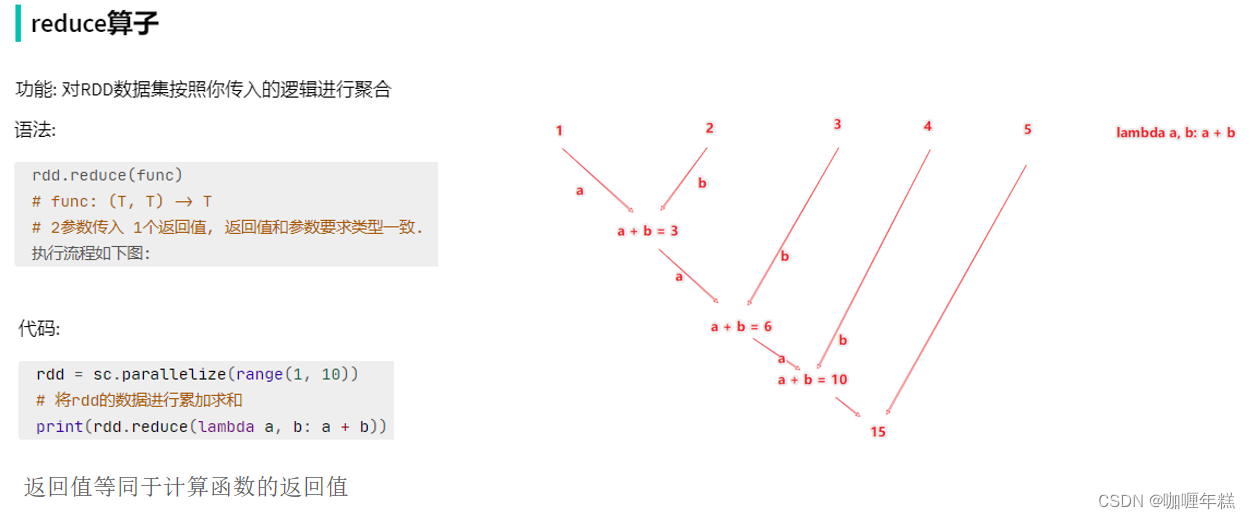
reduce方法
take方法

count方法

总结
- Spark的编程流程就是:
- 将数据加载为RDD(数据输入)
- 对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
- 数据输出的方法
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
数据输出可用的方法是很多的。
2、输出到文件中
将RDD的内容输出到文件中
saveAsTextFile方法

注意事项
调用保存文件的算子,需要配置Hadoop依赖
- 下载
Hadoop安装包
http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz - 解压到电脑任意位置
- 在Python代码中使用os模块配置:
os.environ[‘HADOOP_HOME’] = ‘HADOOP解压文件夹路径’ - 下载
winutils.exe,并放入Hadoop解压文件夹的bin目录内
https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe - 下载
hadoop.dll,并放入:C:/Windows/System32文件夹内
https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
更改RDD的分区数为1

总结
- RDD输出到文件的方法
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
- 如何修改RDD分区
- SparkConf对象设置conf.set(“spark.default.parallelism”, “1”)
- 创建RDD的时候,sc.parallelize方法传入numSlices参数为1
六、分布式集群运行
在 Spark 中,分布式集群运行是其强大性能的体现。下面是使用 Spark 进行分布式集群运行的基本步骤:
-
准备 Spark 安装:
在集群中的每台机器上安装 Spark。确保每台机器都能访问相同的 Spark 安装路径。 -
配置 Spark:
在 Spark 安装路径下,编辑conf/spark-env.sh文件,设置一些必要的环境变量,例如 Java 路径、Spark 主节点地址等。确保所有节点的配置文件保持一致。 -
启动 Spark 主节点(Master):
在集群中选择一台机器作为 Spark 主节点,执行以下命令启动主节点:sbin/start-master.sh默认情况下,主节点的 Web UI 地址是
http://localhost:8080。 -
启动 Spark 工作节点(Worker):
在其余机器上执行以下命令启动工作节点,将它们连接到主节点:sbin/start-worker.sh spark://<master-node-ip>:<port><master-node-ip>是主节点的 IP 地址,<port>是主节点的端口号(默认为 7077)。 -
提交 Spark 应用程序:
编写 Spark 应用程序,并使用以下命令提交到 Spark 集群:bin/spark-submit --class com.example.MyApp --master spark://<master-node-ip>:<port> myapp.jarcom.example.MyApp是你的应用程序主类,myapp.jar是打包好的应用程序 JAR 文件。 -
监控和调优:
可以通过 Spark 的 Web UI(默认地址为http://localhost:4040)监控集群运行状态,查看任务的执行情况、资源使用情况等。根据实际情况进行性能调优。 -
停止 Spark 集群:
当任务执行完成后,可以停止 Spark 集群。首先停止工作节点:sbin/stop-worker.sh然后停止主节点:
sbin/stop-master.sh
这些步骤涵盖了在分布式集群上运行 Spark 应用程序的基本流程。确保配置正确、节点正常连接,以及应用程序能够充分利用集群中的计算资源。 Spark 提供了灵活的配置选项,可以根据具体的集群规模和需求进行调整。
将案例提交到YARN集群中运行
提交命令:
bin/spark-submit --master yarn --num-executors 3 --queue root.teach --executor-cores 4 --executor-memory 4g /home/hadoop/demo.py
上面的 Spark 提交命令已经包括了提交到 YARN 集群的必要参数。
以下是命令的解释:
bin/spark-submit
--master yarn # 指定 Spark 的主节点为 YARN
--num-executors 3 # 指定执行器的数量
--queue root.teach # 指定 YARN 队列
--executor-cores 4 # 指定每个执行器的核心数
--executor-memory 4g # 指定每个执行器的内存大小
/home/hadoop/demo.py # 提交的 Spark 应用程序的路径
解释一下每个参数的作用:
-
--master yarn: 指定 Spark 的主节点为 YARN。这告诉 Spark 将任务提交到 YARN 集群管理器。 -
--num-executors 3: 指定执行器的数量。这是 YARN 上的计算资源,即分配给 Spark 应用程序的节点数量。 -
--queue root.teach: 指定 YARN 队列。这是一个可选的参数,用于将 Spark 应用程序提交到指定的 YARN 队列。 -
--executor-cores 4: 指定每个执行器的核心数。这告诉 YARN 每个执行器可以使用的 CPU 核心数量。 -
--executor-memory 4g: 指定每个执行器的内存大小。这告诉 YARN 每个执行器可以使用的内存量。 -
/home/hadoop/demo.py: 提交的 Spark 应用程序的路径。这应该是您的 Spark 应用程序的入口点。
请确保在提交之前,Spark 相关的配置正确,并且 YARN 集群正常运行。如果有额外的依赖项,确保它们在集群中的每个节点上都可用。
代码
"""
演示PySpark综合案例
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python'
os.environ['HADOOP_HOME'] = "/export/server/hadoop-3.3.1"
conf = SparkConf().setAppName("spark_cluster")
conf.set("spark.default.parallelism", "24")
sc = SparkContext(conf=conf)
# 读取文件转换成RDD
file_rdd = sc.textFile("hdfs://m1:8020/data/search_log.txt")
# TODO 需求1: 热门搜索时间段Top3(小时精度)
# 1.1 取出全部的时间并转换为小时
# 1.2 转换为(小时, 1) 的二元元组
# 1.3 Key分组聚合Value
# 1.4 排序(降序)
# 1.5 取前3
result1 = file_rdd.map(lambda x: (x.split("\t")[0][:2], 1)).\
reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(3)
print("需求1的结果:", result1)
# TODO 需求2: 热门搜索词Top3
# 2.1 取出全部的搜索词
# 2.2 (词, 1) 二元元组
# 2.3 分组聚合
# 2.4 排序
# 2.5 Top3
result2 = file_rdd.map(lambda x: (x.split("\t")[2], 1)).\
reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(3)
print("需求2的结果:", result2)
# TODO 需求3: 统计黑马程序员关键字在什么时段被搜索的最多
# 3.1 过滤内容,只保留黑马程序员关键词
# 3.2 转换为(小时, 1) 的二元元组
# 3.3 Key分组聚合Value
# 3.4 排序(降序)
# 3.5 取前1
result3 = file_rdd.map(lambda x: x.split("\t")).\
filter(lambda x: x[2] == '黑马程序员').\
map(lambda x: (x[0][:2], 1)).\
reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(1)
print("需求3的结果:", result3)
# TODO 需求4: 将数据转换为JSON格式,写出到文件中
# 4.1 转换为JSON格式的RDD
# 4.2 写出为文件
file_rdd.map(lambda x: x.split("\t")).\
map(lambda x: {"time": x[0], "user_id": x[1], "key_word": x[2], "rank1": x[3], "rank2": x[4], "url": x[5]}).\
saveAsTextFile("hdfs://m1:8020/output/output_json")
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!