【Datawhale 大模型基础】第二章 大模型的能力
第二章 大模型的能力
With LLMs having significantly more parameters than PLMs, a natural question arises: what new capabilities does the larger parameter size bring to LLMs?
In the paper “Emergent abilities of large language models”, a new concept has been proposed: emergent abilities. The emergent capabilities of LLMs are formally defined as “abilities that are absent in small models but manifest in large models,” a key feature that distinguishes LLMs from previous PLMs. Furthermore, a notable characteristic is introduced when emergent capabilities arise: performance significantly surpasses random levels when the scale reaches a certain threshold. There are three main typical emergent abilities for LLMs.
In-context learning
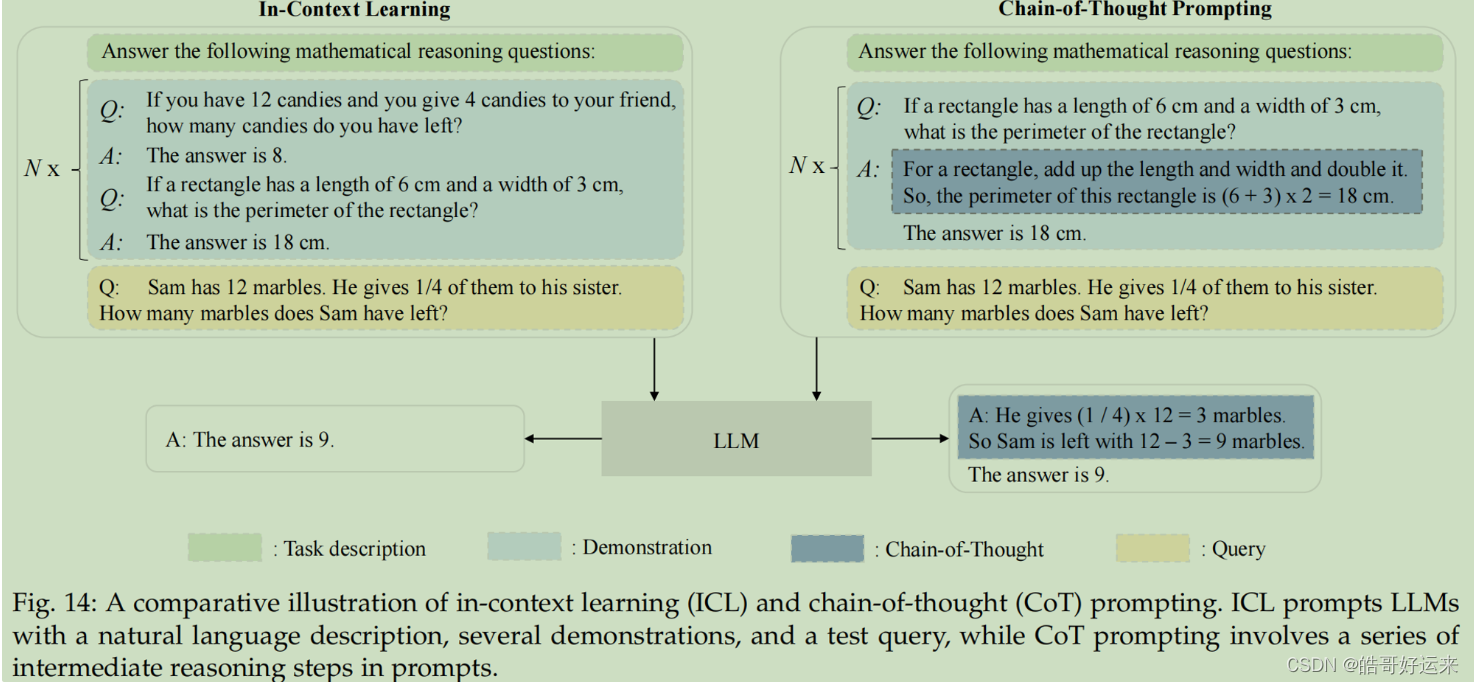
If the language model has been given a natural language instruction and/or several task demonstrations, it can produce the expected output for the test instances by filling in the word sequence of the input text, without needing additional training or gradient updates.
Take the task “predict the last word of the sentence” as an example. The task requires modeling relatively long content and having a certain dependency on it.
Alice was friends with Bob. Alice went to visit her friend ___. -> Bob
And compare GPT-3 with GPT-2 by calculating perplexity, and GPT-3 outperforms GPT-2 and got SoTA at that time.
| Model | Perplexity |
|---|---|
| GPT-3 (few-shot) | 1.92 |
| GPT-2 | 8.63 |
Instruction following
Through fine-tuning using a combination of multi-task datasets formatted with natural language descriptions (referred to as instruction tuning), LLMs have demonstrated strong performance on unfamiliar tasks that are also described in the form of instructions. Instruction tuning enables LLMs to adhere to task instructions for new tasks without relying on explicit examples, thereby enhancing their generalization ability.
Step-by-step reasoning
Small language models often struggle to tackle intricate tasks requiring multiple reasoning steps, such as mathematical word problems. However, the chain-of-thought (CoT) prompting strategy enables LLMs to address these tasks by employing a prompting mechanism that incorporates intermediate reasoning steps to arrive at the final answer. The magic power of CoT (and its variants) will be discussed in the future.
In the GPT-3 paper, it introduces many new capabilities. And I will discuss some of them following datawhale files.
Question answering
The input is a question, and the output is an answer. The language model must “know” the answer in some way, without needing to look up the information in a database or a set of documents. (I recall that Jensen Huang once said that if combining LLMs with database, LLMs would be more powerful and some papers have studied on this domain)
Q: ‘Nude Descending A Staircase’ is perhaps the most famous painting by which 20th century artist?
A: Marcel Duchamp
And GPT-3 has superior performance in many datasets.
When LLMs generate texts or choices, they may encounter hallucinations, which are characterized as generated content that is nonsensical or unfaithful to the provided source content. These hallucinations are further categorized into intrinsic and extrinsic types, depending on the contradiction with the source content.
Arithmetic
Q: What is 556 plus 497?
A: 1053
LLMs can perform well on simple calculation, but it faces some difficulty solving word problem.
Though as illustrated in the original paper, the ability of solving mathematical problems is not good enough, LLMs have the potential to be good arithmetic solvers, just needing some prompt tricks.
I pick a figure form the paper, and it tells the reason what is Chain-of-Thought Prompting. And the prompting benefits LLMs’ math.
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!