【专题】哈希函数的构造方法、处理冲突的方法
目录
一、哈希表
1. 相关术语
- 冲突:不同关键字得到同一哈希地址,key1≠key2,f(key1)=f(key2);
- 构造哈希表:考虑选择一个“好”的哈希函数+ 选择一种处理冲突的方法;
- 哈希表:根据设定的哈希函数H(key)和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集(区间)上,并以关键字在地址集中的“象”作为相应记录在表中。
- 哈希函数:在记录的关键字和其在表中位置之间建立一种函数关系,即以f(key)作为关键字为key的记录在表中的位置。哈希函数是一个映象,将关键字的集合映射到某地址集合。
二、哈希函数的构造方法
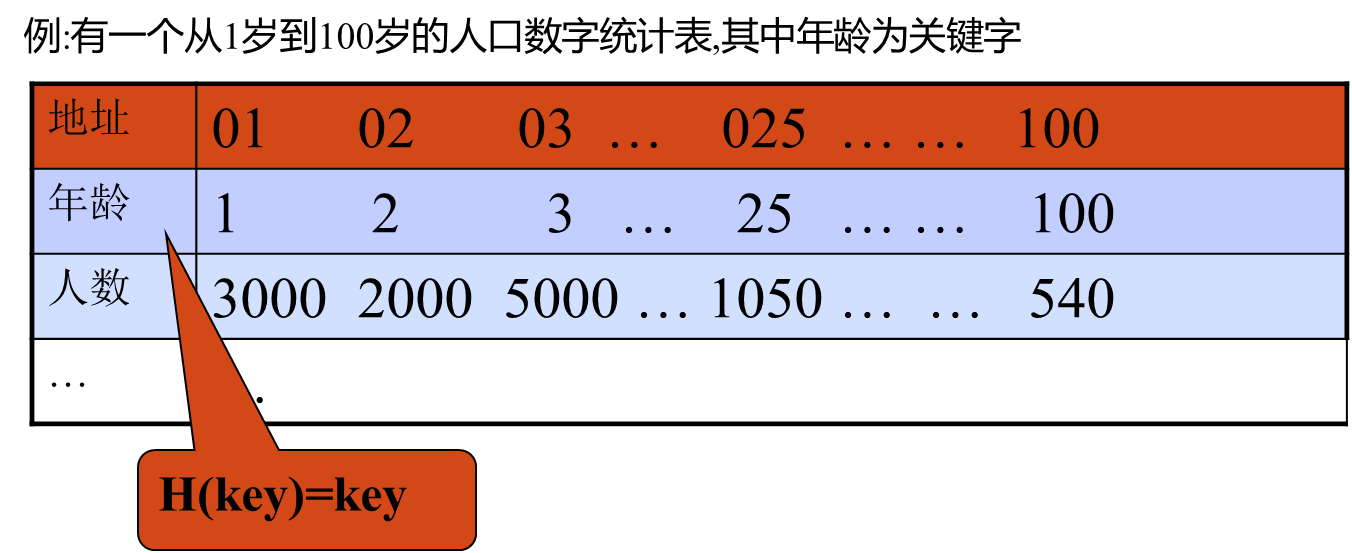
1. 直接定址法
- 方法:取关键字或关键字的某个线性函数值为哈希地址。即H(key)=key或H(key)=a×key+b;
- 特点:直接定址所得地址集合和关键字集合的大小相同,不同关键字不会发生冲突;
2. 数字分析法
- 数字分析法:分析关键字,取其若干位或组合作哈希地址;
- 特点:适于关键字位数比哈希地址位数大,且关键字已知的情况;

3. 平方取中法
- 取关键字平方后的中间几位为哈希地址;
- 特点:适于不知道全部关键字情况;
4. 折叠法及位移法
- 将关键字分割成维数相同的几部分,取这几部分的叠加和为哈希地址。有:移位叠加和间界叠加两种;
- 适于关键字位数很多,且每一位数字分布大致均匀情况;

5. 除留余数法
- 取关键字被某个不大于哈希表长m的数p除后的余数为哈希地址。H(key) = key MOD p (p≤m);
- 简单常用,可与上述方法结合使用,p选不好易产生同义词;
6. 随机数法
- 取关键字的随机函数值为哈希地址。H(key)=Random(key);
- 当关键字长度不等时采用此法比较恰当;
采用哈希函数考虑的因素:计算哈希函数所需时间、关键字长度、哈希表大小、关键字分布、记录的查找频率。
三、处理冲突的方法
1. 开放定址法
Hi=(H(key)+di) MOD m 其中i=1,2,…,k (k≤m-1),
H(key)为哈希函数;m:哈希表长,di是增量序列, 有三种取法:
di=1,2,…m-1,称为线性探测再散列
di=
1
2
1^2
12,
?
1
2
-1^2
?12,
2
2
2^2
22,
?
2
2
-2^2
?22,…,
±
k
2
±k^2
±k2 (k≤m/2)称为二次探测再散列
di=伪随机数列,称为随机探测再散列

2. 再哈希法
Hi=RHi(key)i=1,2,…,k,RHi和Hi都是不同的哈希函数,在同义词产生地址冲突时计算另一个哈希函数地址。直到冲突不再发生,这种方法不易产生聚集,但增加了计算时间
3. 公共溢出区法
HashTable[0…m-1]:基本表,每个分量存放一个记录;
OverTable[0…v]:溢出表,所有关键字和基本表中关键字为同义词的记录,填入溢出表;
4. 链地址法
将所有关键字为同义词的记录存储在同一线性链表中;
四、例题



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!