Knowledge Graph知识图谱—4. Linked Open Data & Semantic Web Programming
4. LOD & Semantic Web Programming
4.1 Linked Open Data
uses techniques like URIs, RDF, RDF schema for publishing knowledge on the Web
HTML has a concept for interlinking scattered information, known as hyperlink. LOD uses that principle, too.
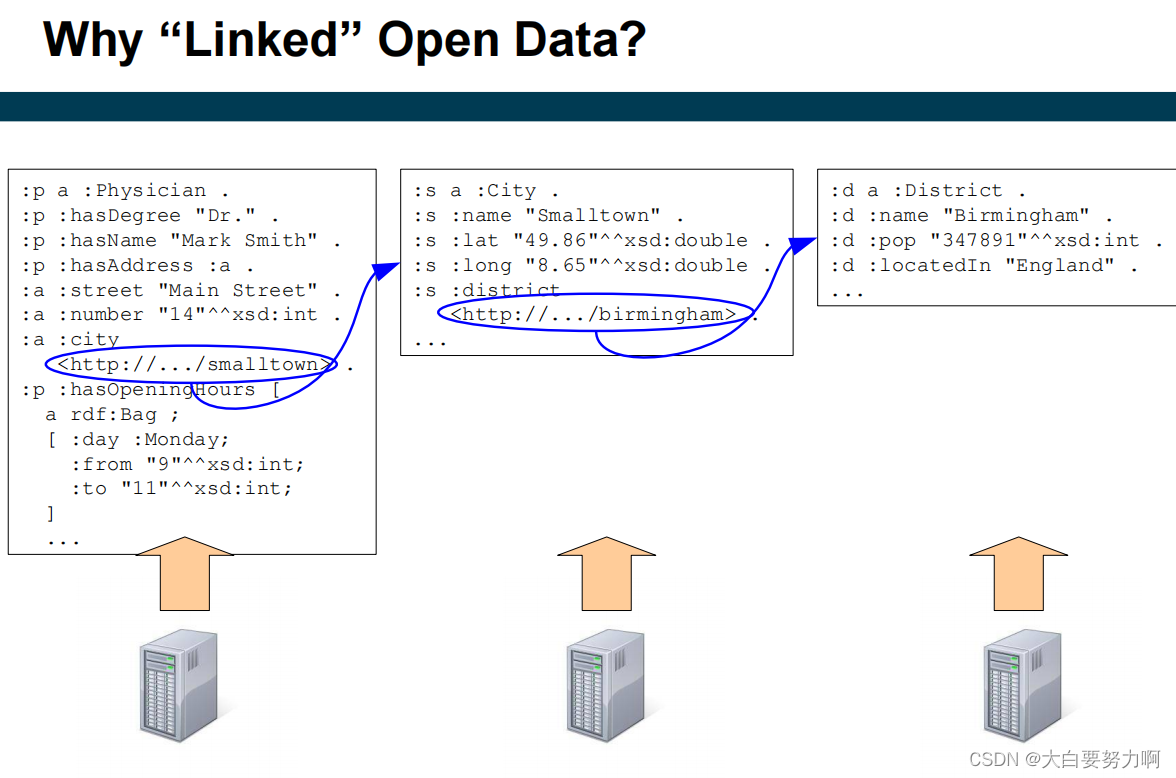
Linked Open Data is RDF data that is provided in a distributed manner.
URIs are used as simple identifiers and linked to data in LOD.
4.1.1 Links in Linked Open Data
HTML Links vs. Links in Linked Open Data
Links in Linked Open Data are always explicitly typed. The semantics of the link is thus interpretable, given that the predicate is defined in a schema.
owl:sameAs* : Links two identical resources. This is required due to the non-unique naming assumption
rdfs:seeAlso: General link to other resources
foaf:homepage: Link to (HTML) homepage
4.1.2 Linking to a Schema
Luckily, everything is identified by a URI (also properties and classes), btw: this also works for “built in” schemas (rdf:type)
4.1.3 Four Principles of Linked Open Data
- Use URIs to identify things
- Use derefencable URIs(URI可引用性:URI应该是可引用的,这意味着当你使用一个URI时,应该可以通过HTTP协议访问到相关资源。这就要求URI是有效的URL,可以在Web上获取有关资源的信息。)
- Provide useful information upon derefencable URIs, use standards
- Add links to other datasets
4.1.4 RDF Molecules
What Data to Serve at a URI?
Basic principle: provide a complete RDF molecule at the URI.
Complete RDF molecule: All triples that have the URI as a subject or an object & Every blank node is connected by at least two predicates.
RDF Molecules avoid dead ends in browsing & avoid (potentially useless) partial information.
Consequences of RDF Molecules:
Triples are duplicated (in the subject’s and the object’s molecule), redundancy, depending on serving strategy
Molecules can become very big
In theory, all triples have to be served
Pragmatic approach: Which information is interesting for a user?
4.1.5 The Five Star Schema & Best Pratices of LOD
Best Practices
1 Provide dereferencable URIs
2 Set RDF links pointing at other data sources
3 Use terms from widely deployed vocabularies
4 Make proprietary vocabulary terms dereferencable
5 Map proprietary vocabulary terms to other vocabularies
6 Provide provenance metadata
7 Provide licensing metadata
8 Provide data-set-level metadata
9 Refer to additional access methods
4.2 The Linked Open Data Cloud
viewpoint1: a set of interconnected knowledge graphs
viewpoint2: one huge knowledge graph
4.2.1 Example
Examples: Government Data
Linguistics Example: BabelNet
Cross-Domain Example: DBpedia
DBpedia
Data from different infoboxes (extracted from multiple languages)
Redirects and disambiguations
External web links
Abstracts in multiple languages
Instance type information: DBpedia Ontology, YAGO, schema.org, DOLCE, and others
YAGO
derived from Wikipedia
Tries to capture time
Wikidata
Collaboratively edited knowledge base
Special: provenance information. i.e., evidence: where did that statement come from?
Further Example Datasets: Linked Movie Database, MusicBrainz, Open Library, DBLP, Linked Open Numbers
4.3 Vocabularies
Dublin Core
Usage: Metadata for resources and documents
Common prefix: dc
Defines properties, e.g., creator, subject, date, …
Resources: DCMI Type Vocabulary: Text, Image, Software, …
FOAF (Friend of a Friend)
Persons and their relations
Created for personal home pages
Common prefix: foaf
Important classes: Person, Group, Organization, Project, …
Important properties: name, firstName, lastName, phone, mbox, homepage, knows, currentProject, pastProject, …
DBLP: Combining FOAF and DC
WGS 84
Encodes geographic data
Common prefix: geo:
Classes: SpatialThing, Point
Properties: latitude, longitude, altitude, location
Where to search for vocabulary terms?
One possibility: https://lov.linkeddata.es/dataset/lov/
Where to search for prefix definitions?
One possibility: http://prefix.cc/
4.4 Publishing Linked Open Data
Possible variant: hand coded, from triple stores, or from relational databases
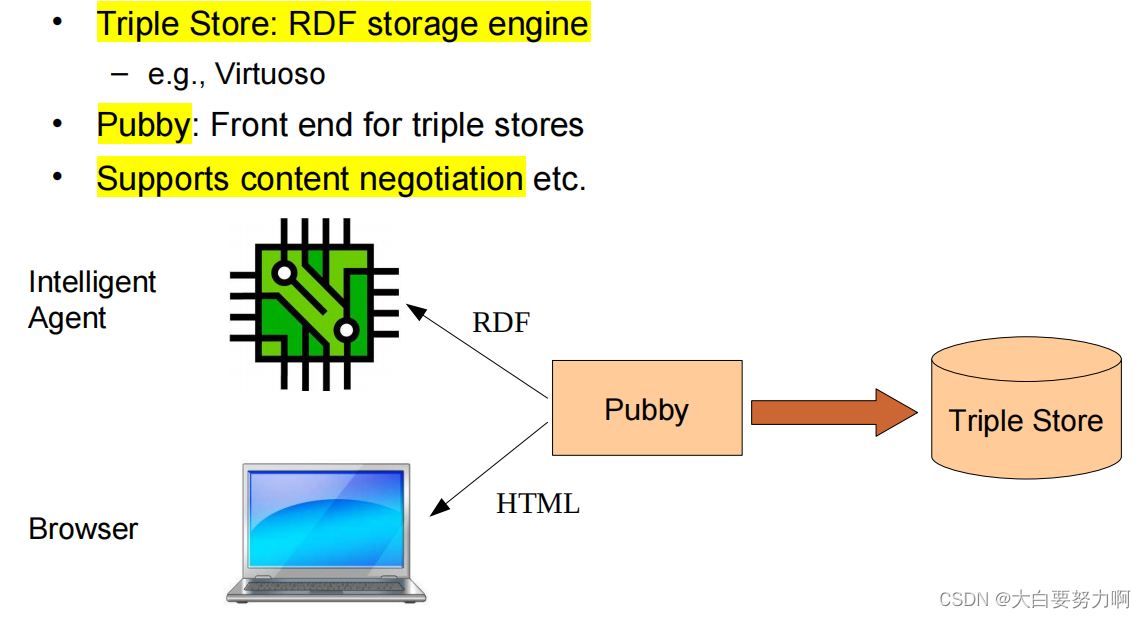
4.4.1 Linked Data from Triple Stores
4.4.2 Knowledge Graphs from Databases
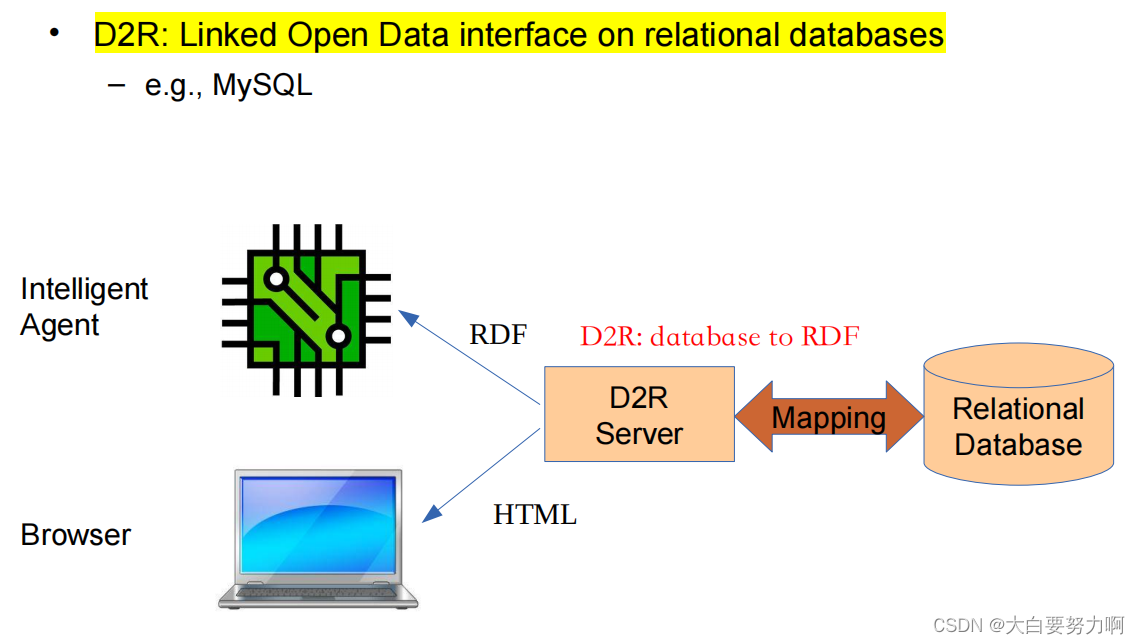
the knowledge graph does not replicate the data, only a “virtual” knowledge graph, providing a knowledge graph view on data from another system
Combining such virtual knowledge graphs can provide a unified view of data from different sources
4.5 Microdata and schema.org
schema.org defines (among others), products, product offers, businesses and local businesses (stores, cafés, …), books, movies, records, events, recipes, persons, …
Main topics of schema.org:
Meta information on web page content (web page, blog…)
Business data (products, offers, …)
Contact data (businesses, persons, …)
(Product) reviews and ratings
a massive long tail
schema.org is mainly used with Microdata and Microdata is mainly used with schema.org
4.6 Microdata/schema.org vs. Linked Open Data
Commonalities:
Both encode machine-interpretable knowledge
Schema.org uses a standard vocabulary
Both can be encoded as RDF
Differences:
Microdata is embedded in the DOM tree(not a general directed graph, no cycles, no reification)
Microdata uses only blank nodes and literals

4.7 Programming with Knowledge Graphs
Using only Plain Java -> Jena
Jena is a well-known Semantic Web programming framework
Programming with RDFLib (Python)
RDFLib is a Python library for working with RDF
Both can performing reasoning.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!