关于目标检测任务中,XML(voc格式)标注文件的可视化
1. 前言
最近在弄关于目标检测的任务,因为检测的图片和标签是分开的,可视化效果不明显,也不知道随便下载的数据集,标注信息对不对。网上看了好多代码,代码风格和本人平时不同,看起来麻烦,也不知道怎么更改,于是按照自己的编码风格,写了个可视化脚本,这里做下记录
本章可视化的数据格式是VOC格式,即标注文件是XML文件,边界框是左上角和右下角的两个点
下面是代码的目录结构,1.jpeg 是数据图像,1.xml是对应的标签信息
result.png 是保存的绘制好边界框的图像

2. 关于代码
代码部分
2.1 自定义函数传入的路径
如下,根据上图摆放好的数据目录,将img_path 传入图片。
对应的 xml 这里是代码生成的,因为大部分数据的标签和训练图像仅仅是目录和后缀的不同,文件名是相同的

2.2 自定义可视化函数
自定义函数传入的三个参数就是原始图片、图片对应的xml标签,save 是展示后是否保存,这里默认保存
如下,parse_xml_to_dict 也是自定义函数,大概就是将xml文件按照树状图的形式解析成层层的字典。看控制台的输出部分,data 就是xml 文件的内容
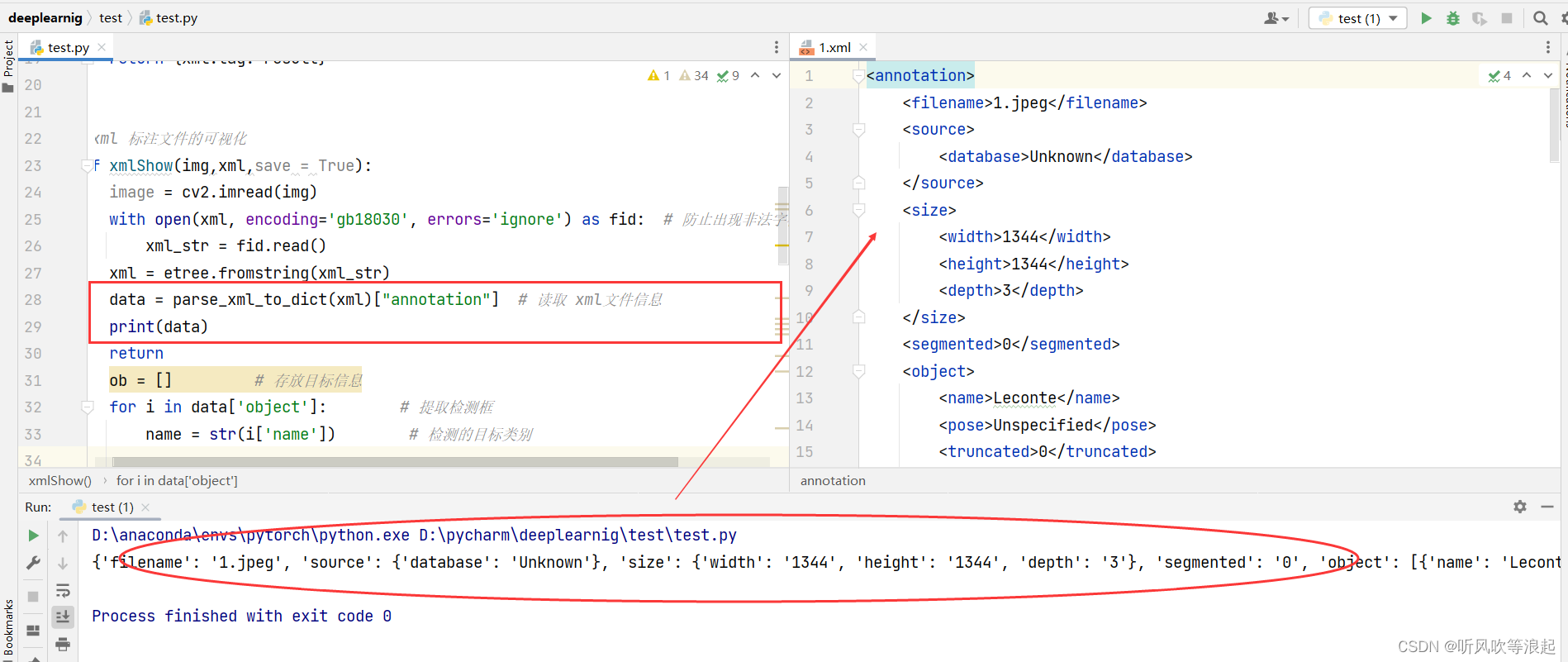
接下来就是根据解析的字典,读取里面的边界框和检测类别
XML标注格式的文件,目标在<object>下面
因为每张图片的目标不是只有一个,所有用for循环遍历,如下每个i就是一个完整的目标
通过字典的key将对应的value读取出来,然后用列表仅仅保存边界框和分类的名称
值得注意的是,XML标注的目标类别就是真实的类别,而非yolo格式的0 1 2 索引,所以这里绘制边界框是不需要json文件的
xml生成json类别字典文件,可以查看:目标检测篇:如何根据xml标注文件生成类别classes的json文件

关键的信息提取好了,就可以绘制边界框了,通过打印,可以发现ob里面存放的就是我们需要的部分(name、xmin、ymin、xmax、ymax)
绘制的部分很简单,利用cv就行了
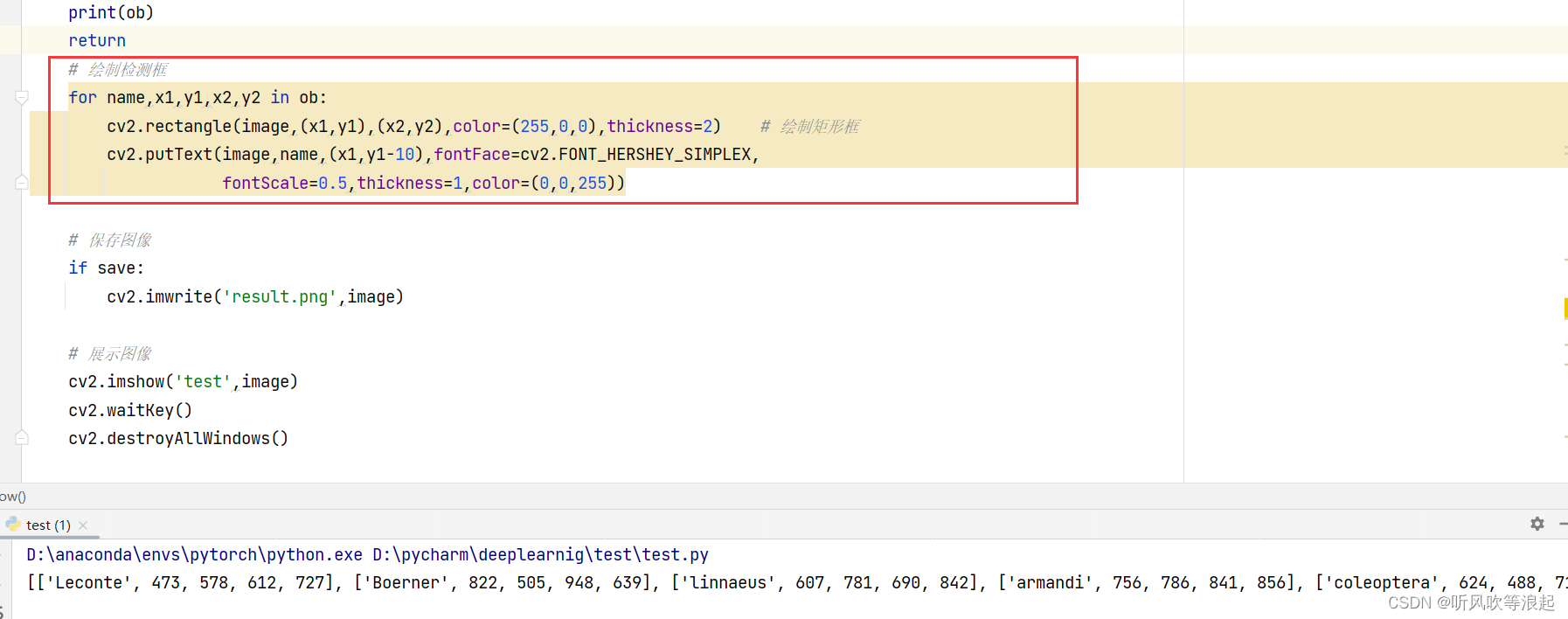
2.3 绘制结果
因为大部分训练图像size很大,cv窗口展示不出来,所以这里查看生成的result.png文件
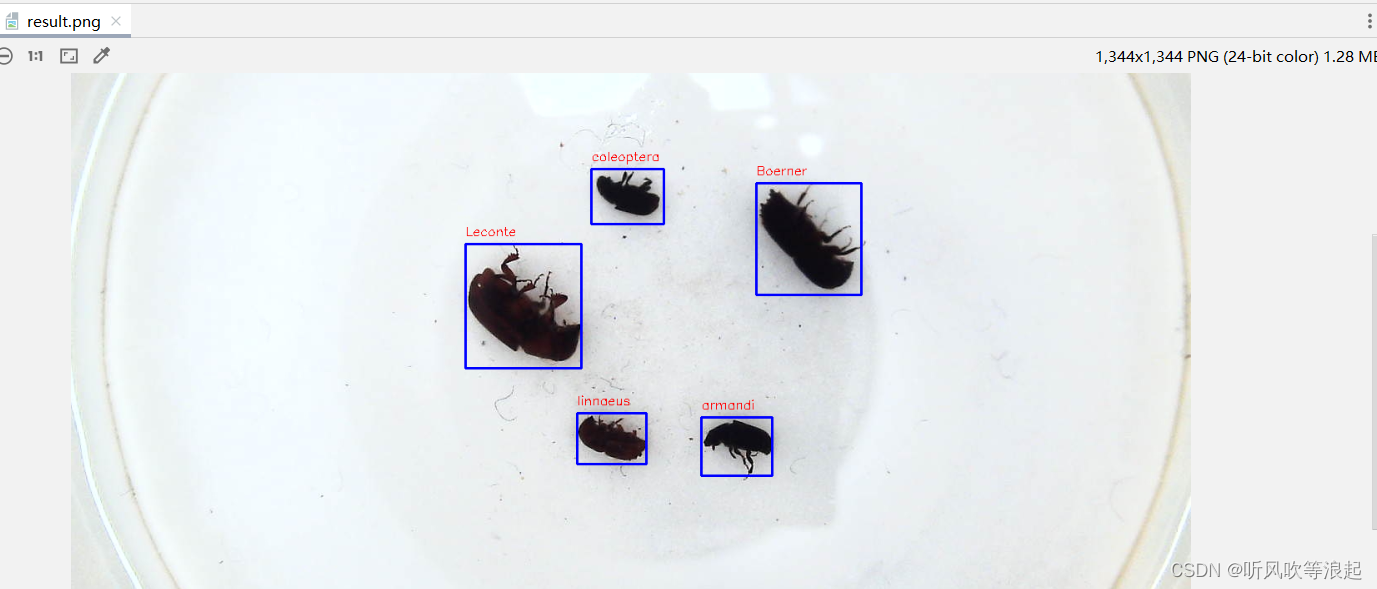
- 想要同时展示多张绘制好的图片,可以利用for循环嵌套,或者用dataloader和plt结合等等
- 待会看看能不能把YOLO格式txt的可视化数据写出来,因为yolo标注的相对信息和类别索引,可能会相对复杂一些
?
3. 完整代码
如下:
from lxml import etree
import cv2
# 读取 xml 文件信息,并返回字典形式
def parse_xml_to_dict(xml):
if len(xml) == 0: # 遍历到底层,直接返回 tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
# xml 标注文件的可视化
def xmlShow(img,xml,save = True):
image = cv2.imread(img)
with open(xml, encoding='gb18030', errors='ignore') as fid: # 防止出现非法字符报错
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = parse_xml_to_dict(xml)["annotation"] # 读取 xml文件信息
ob = [] # 存放目标信息
for i in data['object']: # 提取检测框
name = str(i['name']) # 检测的目标类别
bbox = i['bndbox']
xmin = int(bbox['xmin'])
ymin = int(bbox['ymin'])
xmax = int(bbox['xmax'])
ymax = int(bbox['ymax'])
tmp = [name,xmin,ymin,xmax,ymax] # 单个检测框
ob.append(tmp)
# 绘制检测框
for name,x1,y1,x2,y2 in ob:
cv2.rectangle(image,(x1,y1),(x2,y2),color=(255,0,0),thickness=2) # 绘制矩形框
cv2.putText(image,name,(x1,y1-10),fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.5,thickness=1,color=(0,0,255))
# 保存图像
if save:
cv2.imwrite('result.png',image)
# 展示图像
cv2.imshow('test',image)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == "__main__":
img_path = './my_xml_dataset/train/images/1.jpeg' # 传入图片
labels_path = img_path.replace('images', 'labels') # 自动获取对应的 xml 标注文件
labels_path = labels_path.replace('.jpeg', '.xml')
xmlShow(img=img_path, xml=labels_path,save=True)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!