urllib爬虫 应用实例(三)
2023-12-13 03:06:14
目录
一、?ajax的get请求豆瓣电影第一页
目标:获取豆瓣电影第一页的数据,并保存为json文件
设置url,检查 -->? 网络?--> ?全部? -->?top_list?--> 标头? -->?请求URL
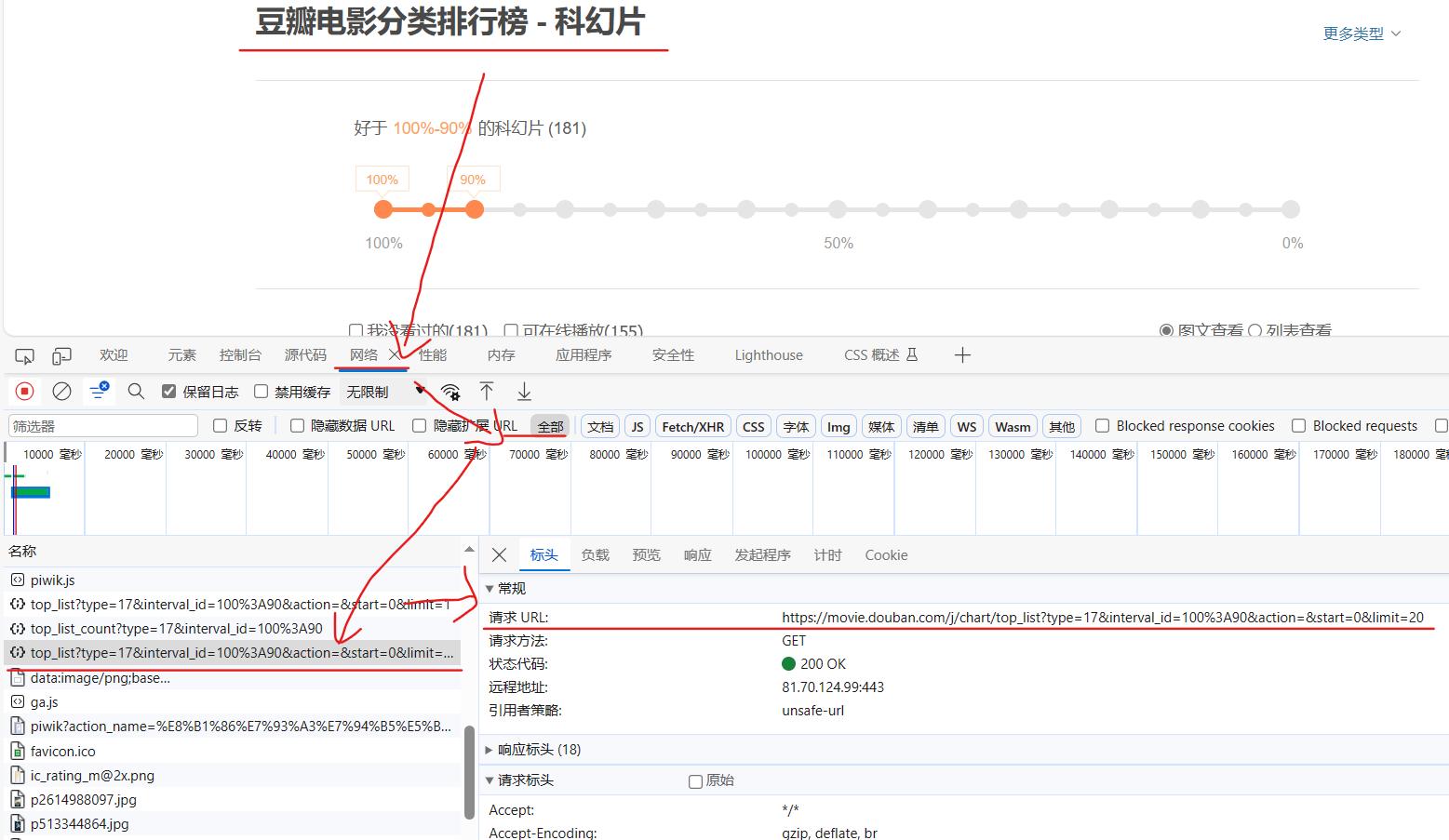
完整代码:
import urllib.request
"""
# get请求
# 获取豆瓣电影第一页的数据,并保存为json文件
"""
url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 请求对象的定制
request = urllib.request.Request(url, headers=headers)
# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# 数据下载到本地
with open('douban.json','w', encoding='utf-8') as file:
file.write(content)
# import json
# with open('douban.json','w', encoding='utf-8') as file:
# json.dump(content, file, ensure_ascii=False)
"""
通常是因为默认情况下,json.dump() 使用的编码是 ASCII,不支持包含非ASCII字符(如中文)的文本。为了在 JSON 文件中包含中文字符,你可以指定 ensure_ascii=False 参数,以确保不将中文字符转换为 Unicode 转义序列。
"""
二、ajax的get请求豆瓣电影前十页
?目标:下载豆瓣电影前十页的数据
知识点:问题的关键在于观察url的规律,然后迭代获取数据
1.设置url
找规律
点击top_list获取第一页的request url,复制url,点击清空,下拉滚动条,再次出现top_list时复制第二页的request url,重复操作,我们可以找到规律。

?观察链接,可以看到page和start之间的关系
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'
# page 1 2 3 4
# start 0 20 40 602.定义请求对象定制的函数
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = base_url+data
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 请求对象的定制
request = urllib.request.Request(url, headers=headers)
return request3.定义获取响应的数据的函数
def get_content(request):
# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content4.定义下载函数
def down_load(content,page):
with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:
file.write(content)5.调用这些函数,完成数据抓取
start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(content,page)
print(f"done_{page}")完整代码
import urllib.request
import urllib.parse
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'
# page 1 2 3 4
# start 0 20 40 60
# 全部工作:下载豆瓣电影前十页的数据
# 请求对象的定制
# 获取响应的数据
# 下载数据
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = base_url+data
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 请求对象的定制
request = urllib.request.Request(url, headers=headers)
return request
def get_content(request):
# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content,page):
with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:
file.write(content)
start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(content,page)
print(f"done_{page}")
三、ajax的post请求肯德基官网
?目标:查询肯德基某地区餐厅前十页的信息
1.设置url
进入肯德基官网,点击餐厅查询,右键检查
网络 --> 名称 --> 标头 --> 请求URL
然后点击清空(左上角的 ?),点击第二页,再次获取链接信息及负载中的表单数据,找规律

可以找到如下规律
pageIndex就是页码
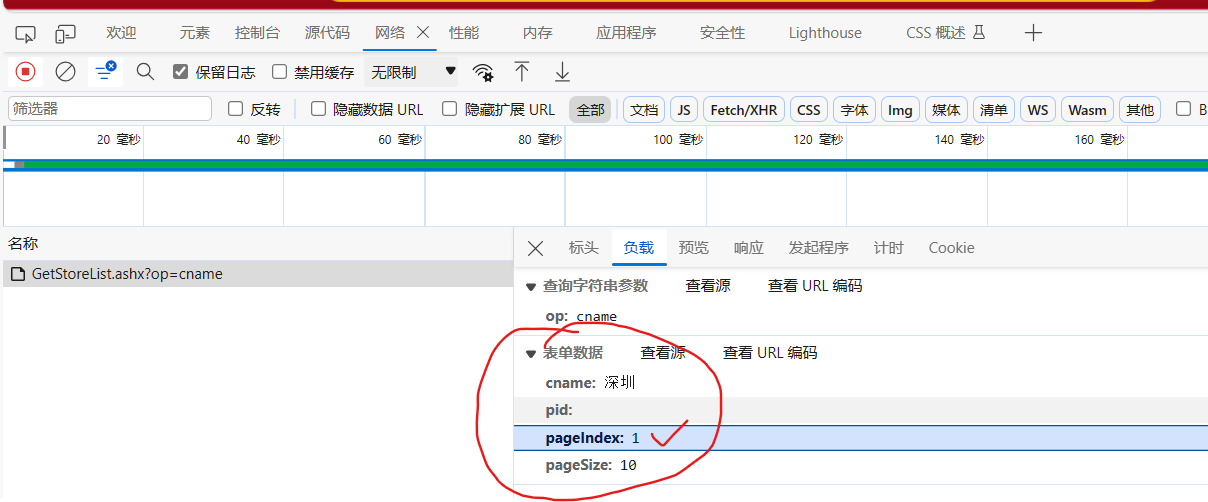
# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10
# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 102.定义请求对象地址的函数
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': '深圳',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
request = urllib.request.Request(base_url, data, headers)
return request3.获取网页源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content4.下载
def download(content, page):
with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:
file.write(content)5.调用函数
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):
# 请求对象定制
response = create_request(page)
# 获取网页源码
content = get_content(response)
# 下载1
download(content, page)完整代码:
import urllib.request
import urllib.parse
# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10
# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 10
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': '深圳',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
request = urllib.request.Request(base_url, data, headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content, page):
with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:
file.write(content)
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):
# 请求对象定制
response = create_request(page)
# 获取网页源码
content = get_content(response)
# 下载1
download(content, page)
参考
文章来源:https://blog.csdn.net/m0_45447650/article/details/134272248
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!