YOLO模型
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本周的学习内容主要是以阅读文献为基础,在文献中了解前沿知识。这次共阅读使用卷积神经网络和区域卷积神经网络(R-CNN)的肺部异常的检测与分类方法,了解了它们在图像识别的优势,以及对医疗诊断贡献。此外还学习了解了YOLO模型,了解其大致的工作原理,与先前学习的卷积神经网络模型进行对比。
Abstract
This week’s learning content is mainly based on reading literature to understand cutting-edge knowledge. This time, we read about the detection and classification methods of lung abnormalities using convolutional neural networks and region-based convolutional neural networks (R-CNN), and learned about their advantages in image recognition and their contributions to medical diagnosis. In addition, we also learned about the YOLO model and its general working principle, and compared it with the previously learned convolutional neural network model.
文献阅读:使用卷积神经网络和区域卷积神经网络(R-CNN)的肺部异常的检测与分类方法
Title:Detection and Classification of Lung Abnormalities by Use of Convolutional Neural Network (CNN) and Regions with CNN Features (R-CNN)
Author:Shoji Kido 、Yasusi Hirano 、Noriaki Hashimoto
From:2018 International Workshop on Advanced Image Technology (IWAIT)
1、研究背景
在放射学图像的诊断、检测和分类过程很重要。肺部疾病,如肺结节和弥漫性肺部疾病有很大的差异,其中肺结节包括恶性结节和良性结节,而弥漫性肺部疾病包括许多原因,如感染和肿瘤。此前用于协助放射科医生诊断的计算机辅助诊断系统包括两种类型的CAD算法,计算机辅助检测异常病变的检测和计算机辅助将异常病变区分为良性的或恶性。我们通过这些算法可以检测和分类肺部异常的图像特征例如肺结节或弥漫性肺病模式,这些图像特征可用于计算机分类肺部疾病。然而难以定义这样的图像特征是由于肺部图像模式复杂,任务难度大。
2、研究目的
随着深度学习技术显著提高,深度学习技术在语音识别、图像识别领域有了不小的推进作用。在以往的计算机辅助算法中图像特征提取器是重要的,卷积神经网络(CNN)实现了图像模式识别的突破,使用CNN的CAD算法不一定需要图像特征提取器,在医学图像识别领域加入卷积神经网络(CNN)就能显著提高机器鉴别诊断水平。此外区域CNN(R-CNN)具有在自然图像上检测人、动物等物体等能力,因此可以为检测肺部异常提供一个全新思路。
3、研究思路
3.1、对使用CNN的计算机辅助诊断算法进行性能测试
我们使用了预先在在ImageNet上的“AlexNet”数据集训练过的CNN模型,该数据集有1000个对象类别和120万个训练图像。对于肺结节病例数据,我们使用了163个结节图像,我们通过对图像数据进行旋转而增加了8倍的数量,获得了另外的1304个结节图像。对于在弥漫性肺部疾病病例的数据,我们使用了来自372名不同患者的9635块贴片(715 CON,1051HON,1886 GGO,3474 EMP和2509 NOR),通过数据增强,获得了77080个数据贴片。图像分为训练和验证集。每组30%的图像为训练数据,其余70%为验证数据。随机分组以避免偏倚结果。首先,利用CNN提取训练图像的特征。接下来将这些特征用于训练多类向量机器(SVM)。最后,对多类向量机器的验证集进行了评价。 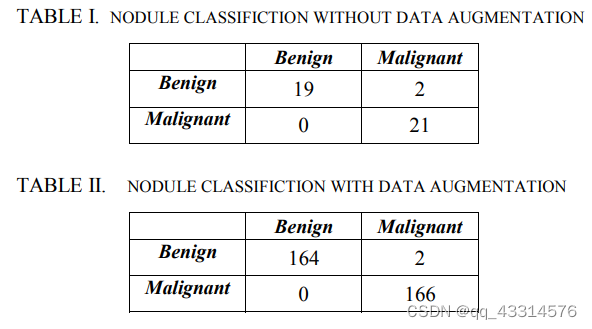
对于良性和恶性肺结节的分类,在不增加数据的情况下,平均准确率为95.2%,在增加数据扩充的情况下准确率为99.4%,如上图所示。
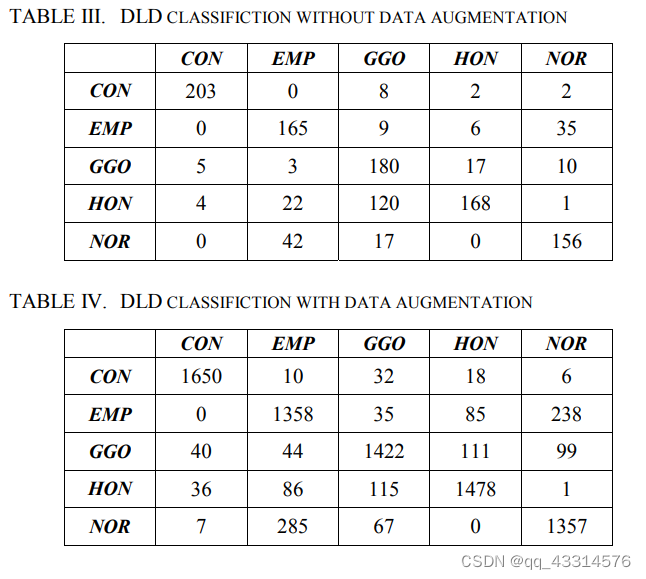
对于五种类型的弥漫性肺部疾病(CON、EMP、GGO,HON和NOR),在没有数据的情况下,平均准确率为81.1%,在增加数据扩充的情况下准确率为84.7%,如上图所示。
3.2、对使用R-CNN的计算机辅助诊断算法进行性能测试
在使用R-CNN探测器的过程中,不使用滑动窗口对整个图像进行检测,而是只处理那些可能包含病变的区域。R-CNN使用选择性搜索创建边界框,一旦确定区域附近可能有病变的存在,R-CNN就会将该区域扭曲成标准的正方形大小,并将其传递给CNN模型。在CNN模型的最后一层,会将其分类为目标物体,如肺结节或具有弥漫性肺病。我们在CT图像上标记了异常病变的边界框,用于训练数据。我们使用了一个leave-one-out的方法进行评估。因此,我们选择了一个案例进行验证,其他案例用于训练。R-CNN用标记的异常病变进行训练,并在测试图像上标记异常病变的边界框。
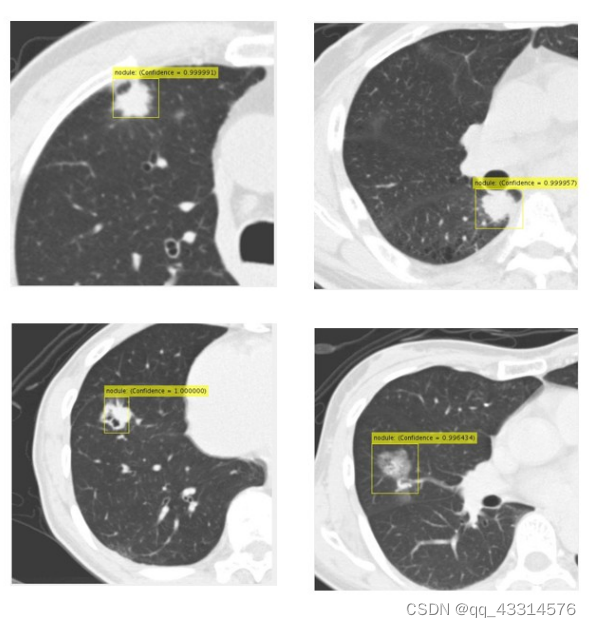
对于结节的检测,使用了R-CNN的CADe能正确地检测到了附着在胸壁和纵隔上的肺结节,它可以检测到各种带有空气支气管图的结节和毛玻璃样混浊的结节,如上图所示。需要注意的是因为某种结节类型的数据比较少,无发作出相应的检测。
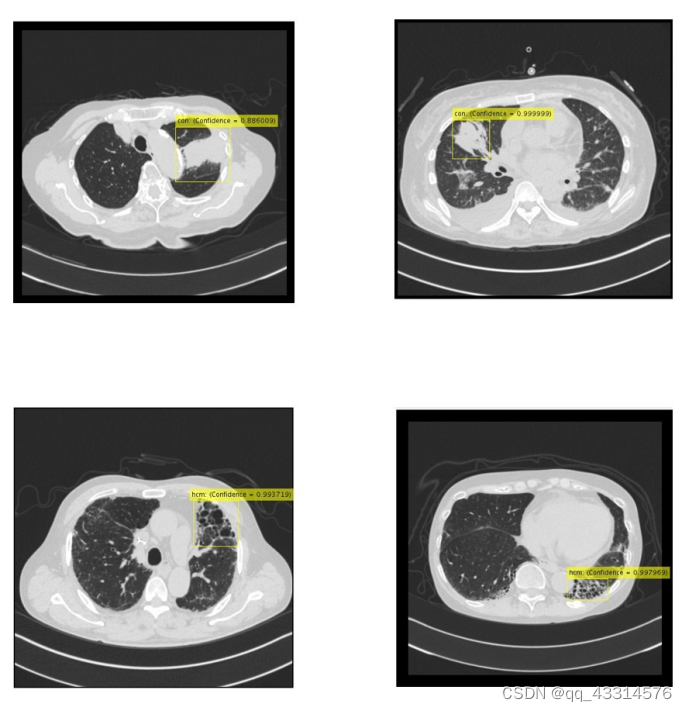
对于弥漫性肺部疾病的检测,我们评估了一些模式,如 consolidaion cases和 honeycombing cases,这两种类型均能被很好地检测出来,如上图所示,上面两幅为consolidaion cases,下面两幅为 honeycombing cases。
4、文献贡献
通过对计算机辅助诊断算法加入卷积神经网络(CNN)进行赋能,得到新的计算机辅助算法CADx和CADe,为医学诊断提供全新的思路。基于图像检测的CADx利用CNN可以区分各种肺部异常,如肺结节和弥漫性肺部疾病。此外,基于图像的CADe利用R-CNN也可以检测这种肺部异常。在以往的图像特征CAD算法中,我们必须使用多种图像处理算法来提取图像特征,然而,正确定义各种肺部异常是一项艰巨的任务。由于使用CNN或R-CNN的CAD算法不一定需要图像特征提取器。因此,使用CNN的基于图像的CADx和使用R-CNN的基于影像的CADe都可用于放射科医生对肺部异常的诊断。
YOLO模型
1、什么是YOLO?
“You Only Look Once”是一种使用卷积神经网络进行目标检测的算法。YOLO是其中速度较快的物体检测算法之一。虽然它不是最准确的物体检测算法,但是在需要实时检测并且准确度不需要过高的情况下,它是一个很好的选择。与识别算法相比,检测算法不仅预测类别标签,还检测对象的位置。因此,它不仅将图像分类到一个类别中,还可以在图像中检测多个对象。该算法将单个神经网络应用于整个图像。这意味着该网络将图像分成区域,并为每个区域预测边界框和概率。这些边界框是由预测的概率加权的。
2、一个全卷积神经网络
YOLO仅利用卷积层,使其成为一个全卷积网络(FCN)。在YOLO v3论文中,作者提出了一个名为Darknet-53的更深的特征提取器架构。它包含53个卷积层,每个卷积层后面跟随批量归一化层和Leaky ReLU激活函数。没有使用任何形式的池化,而使用带有步长2的卷积层来降采样特征图。这有助于防止池化经常归因于低级特征的丢失。
YOLO对输入图像的大小不变。然而,在实践中,由于我们在实现算法时可能遇到各种问题,因此我们可能希望坚持使用恒定的输入大小。
其中一个重要问题是,如果我们想以批量方式处理图像(GPU可以并行处理批量图像,从而提高速度),则需要所有图像具有固定的高度和宽度。这是将多个图像连接成大批量所需的。网络通过称为网络步长的因素对图像进行下采样。例如,如果网络的步长为32,则大小为416 x 416的输入图像将产生大小为13 x 13的输出。通常,网络中任何一层的步长都等于该层的输出比输入图像小的因子。
3、YOLO输出
在YOLO中,使用了一个使用1 x 1卷积的卷积层进行预测。因此,首先要注意的是我们的输出是一个特征图。由于我们使用了1 x 1卷积,因此预测图的大小与其前面的特征图的大小完全相同。在YOLO v3中,您解释此预测图的方法是,每个单元格可以预测一定数量的边界框。
例如,如果在特征图中有(B x (5 + C))个条目,则B表示每个单元格可以预测的边界框数。根据论文,这B个边界框中的每个边界框可以专门用于检测某种类型的对象。每个边界框都有5 + C个属性,用于描述边界框的中心坐标、尺寸、目标分数和C类置信度。YOLO v3为每个单元格预测3个边界框。
如果对象的中心落在单元格的感受野中,我们期望特征图的每个单元格通过其边界框之一预测出一个对象。这与YOLO的训练方式有关,其中仅一个边界框负责检测任何给定的对象。首先,我们必须确定该边界框属于哪些单元格。为此,我们将输入图像划分为一个网格,其尺寸等于最终特征图的尺寸。请看下面的示例,其中输入图像为416 x 416,网络步长为32。如前所述,特征图的尺寸将为13 x 13。然后,我们将输入图像分成13 x 13个单元格。
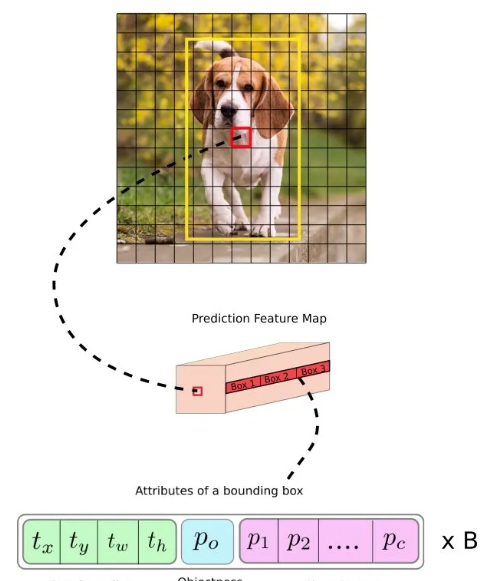
然后,包含物体实际中心点的单元格(在输入图像中)被选为负责预测该物体的单元格。在上面的图像中,是标为红色的单元格,它包含物体实际中心点(标为黄色)。现在,红色单元格是网格中第7行第7个单元格。我们现在将第7行第7个单元格在预测特征图上对应的单元格(对应的特征图上的单元格)指定为负责检测狗的单元格。现在,这个单元格可以预测三个边界框。哪一个会被分配到狗的实际标签?为了理解这一点,我们必须理解“anchors”的概念。(请注意,这里讨论的单元格是预测特征图上的单元格。我们将输入图像分成网格,只是为了确定负责预测的特征图单元格是哪个。)
–
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!