Python 学习
2023-12-18 17:31:07
一、基础
1.1 数据类型

1.2 注释
# 单行注释
print('Hello World!')
"""
多行注释内容
支持换行
"""
1.3 变量
money = 10
1.4 检测数据类型
type() 语句
print(type('Hello World!')) # <class 'str'>
print(type(123)) # <class 'int'>
print(type(1.23)) # <class 'float'>
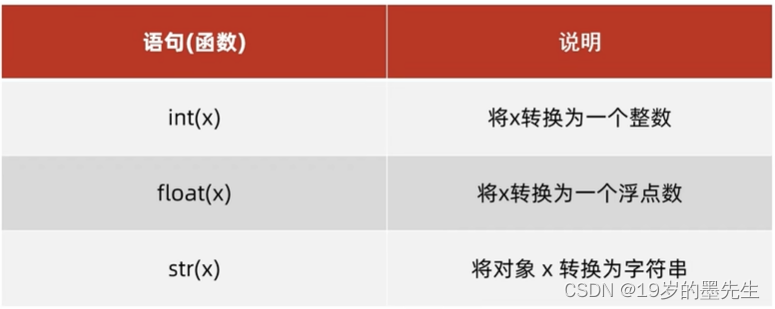
1.5 数据类型转换
1.6 数据输入(input语句)
print('你是谁?')
name = input()
print('Get !!! 你是: %s' % name)
1.7 if 语句
level = 10
if level >= 10:
print('初级')
elif level >= 40:
print('中级')
else:
print('高级')
1.8 while 语句
i = 1
while i < 100:
i += 1
1.9 九九乘法表
i = 1
while i <= 9:
j = 1
# 内层循环的 print 语句, 不要换行, 通过 \t 制表符进行对齐
while j <= i:
print(f'{j} * {i} = {j * i}\t', end='')
j += 1
i += 1
# print 空内容, 就是输出一个换行
print()
1.10 range 语句
获得一个数字序列
语法格式:
- 语法1: range(num)
- 语法2: range(num1, num2)
- 语法3: range(num1, num2, step)
注意事项:
- 语法1 从 0 开始,到 num 结束(不含 num 本身)
- 语法2 从 num1 开始,到 num2 结束(不含 num2 本身)
- 语法3 从 num1 开始,到 num2 结束(不含 num2 本身),步长以 step 值为准
1.11 函数
定义
- def 关键字,定义带有名称的函数(可重复使用)
- lambda 关键字,定义匿名函数(临时使用一次)
返回值
# 多个返回值
def test():
return 1, 2
x, y = test()
print(x) # 1
print(y) # 2
传参
def userInfo(name, age, gender):
print(f'名字:{name}, 年龄:{age}, 性别:{gender}')
# 默认传参
userInfo('Tom', 18, '男')
# 关键字传参
userInfo(name='Tom', age=18, gender='男')
# 参数默认值(必须写在最后)
def user_info(name, age, gender='男'):
print(f'名字:{name}, 年龄:{age}, 性别:{gender}')
user_info('Bob', 20)
# 不定长位置传递
def user_info(*args):
print(args) # 元组类型
user_info('Tom') # ('Tom')
user_info('Tom', 18) # ('Tom', 18)
# 不定长关键字传递
def user_info(**kwargs):
print(kwargs) # 字典类型
user_info(name='Tom', age=19) # {name: 'Tom', age: 19}
user_info(name='Bob') # {name: 'Bob'}
1.12 None 类型
一个特殊的字面量,用于表示:空、无意义。
- 用在函数无返回值上
- 在 if 判断中,None 等同于 False
- 用于声明无内容的变量上
name = None暂不赋予具体值
1.13 捕获异常
try:
print('Hello')
except Exception as e:
print(e)
else:
print('没有异常')
finally:
print('有无异常都会执行')
1.14 模块
内置模块
# 导入time模块
import time
# 使用time模块的方法
time.sleep(5)
# 导入time模块的所有方法
from time import *
# 使用sleep方法
sleep(5)
# 导入time模块的sleep方法
from time import sleep
# 使用sleep方法
sleep(5)
# 别名
import time as t
# 使用sleep方法
t.sleep(5)
# 别名
from time import sleep as sl
# 使用
sl(5)
自定义模块
# moudle.py
# 暴露出去的方法,不写则是暴露全部方法
__all__ = ['testA']
def testA(a, b):
print(a + b)
def testB(a, b):
print(a - b)
# 在当前文件运行时才会执行
if __name__ == '__main__':
testA(1, 2)
# index.py
# 跟模块文件同级目录
import moudle as *
testA(1, 2)
# testB 不能使用,因为没有暴露出来
自定义包

import my_package.my_module1
from my_package import my_module2
1.15 JSON数据格式转换
# ensure_ascii=False 不使用unicode编码
data = [{"name":"张大山","age":11},{"name":"王大锤","age":13},{"name":"赵小虎","age":16}]
json_str = json.dumps(data, ensure_ascii=False)
# 将JS0N字符申转换为Python数据类型[(k:V,k:v},{k:V,k:v}]
s = '[f"name":"张大山","age":11},{"name":"王大锤","age":13},{"name":"赵小虎","age":16}]'
1 = json.loads(s)
1.16 类型注解



# 使用 Union 类型,必须先导包
from typing import Union
my_list: list[Union[int, str]][1, 2, "itheima", "itcast"]
def func(data: Unilon[int,str]) -> Union[int,str]:
pass
1.17 闭包
def outer(num1):
def inner(num2):
nonlocal num1 # nonlocal 关键字修饰外部函数的变量,才可在内部函数中修改它
num1 += num2
print(num1)
return inner
fn = outer(10)
fn(10)
fn(10)
1.18 装饰器
def outer(func):
def inner():
print('我睡觉了')
func()
print('我起床了')
return inner
@outer # 相当于把 sleep 传入到 outer 中
def sleep():
import random
import time
print('睡眠中......')
time.sleep(random.randint(1, 5))
sleep()
# 我睡觉了
# 睡眠中......
# 我起床了
二、数据容器
2.1 列表
可修改,支持重复元素且有序
# 常用的操作方法
list = ['1', '2', '3']
# 1.查找某元素在列表的索引,不存在会报错
index = list.index('2')
# 1
# 2.插入元素
list.insert(1, '4')
# ['1', '4', '2', '3']
# 3.追加单个元素
list.append('5')
# ['1', '4', '2', '3', '5']
# 4.追加"一批"元素
list.extend(['6', '7', '8'])
# ['1', '4', '2', '3', '5', '6', '7', '8']
# 5.删除元素
del list[1]
# ['1', '2', '3', '5', '6', '7', '8']
list.pop(0)
# ['2', '3', '5', '6', '7', '8'] 返回被删除元素
list.remove('2')
# ['3', '5', '6', '7', '8'] 删除第一个匹配的元素
# 6.统计某元素在列表中的数量
list.count('3')
# 7.清空列表
list.clear()
# 8.统计列表中有多少个元素
len(list)
2.2 元组
定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。不可修改且有序(只读列表)
# (元素1, ..., 元素n)
tup = ('1', '2', '3')
# 1.查找某元素在元组的索引,不存在会报错
index = tup.index('2')
# 1
# 2.统计某元素在元组中的数量
tup.count('3')
# 3.统计元组中有多少个元素
len(tup)
2.3 序列的常用操作 - 切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,以此取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 1,表示一个个取元素
- 2,表示跳过一个元素取,依次类推
- 负数,反向取(起始下标和结束下标也要反向标记)
list = [0, 1, 2, 3, 4, 5, 6]
# 1.从1开始,4结束,步长1
result1 = list[1:4]
# [1, 2, 3]
# 2.从头开始到结束,步长2
result2 = list[::2]
# [0, 2, 4, 6]
# 3.从3开始,到1结束,步长-1
result3 = list[3:1:-1]
# [3, 2]
2.4 集合
无序(不支持下标访问),不可重复,允许修改
# 定义
my_set = {'hello', 'world'}
# 1.添加新元素
my_set.add('it')
# {'hello', 'world', 'it'}
# 2.移除元素
my_set.remove('hello')
# 3.随机取一个元素
my_set.pop()
# 4.清空
my_set.clear()
# 5.取两个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2)
# set3 {2, 3}
# 6.清除两个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2)
# set1 {2, 3}
# 7.合并两个集合
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
# set3 {1, 2, 3, 5, 6}
# 8.统计集合的数量
set1 = {1, 2, 3, 5, 6}
num = len(set1)
# num 5
# 9.遍历集合
set1 = {1, 2, 3, 5, 6}
for ele in set1:
print(f"{ele}")
2.5 字典
提供基于Key检索Value的场景实现
定义语法:
{ key: value, key: value, ..., key: value }
注意事项:
- 键值对的Key和Value可以是任意类型(Key不可为字典)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
三、文件
3.1 文件的读取操作
open() 打开函数
open(name, mode, encoding)
- name,要打开的目标文件名字符串(可以包含文件所在的具体路径)
- mode,设置文件打开的模式(只读、写入、追加等)
- encoding,编码格式
# 示例代码
f = open('python.txt', 'r', encoding='UTF-8')
# encoding 的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
mode 常用的三种基础访问模式
- r,只读(默认模式)
- w,写入。如果该文件存在则打开文件并从头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件
- a,打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
| 操作 | 功能 |
|---|---|
| 文件对象 = open(name, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节,不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
f = open('D:/test.txt', 'w', encoding='UTF-8')
f.write('Hello World!')
# 刷新,将内存中积攒的内容,写入到硬盘的文件中
f.flush()
# close 方法,内置了 flush 功能
f.close()
四、类
4.1 构造方法
构造方法的名称:__init__
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
stu1 = Student('张三', 18)
4.2 成员方法
写在类里面的函数,通过 self 关键字访问类的成员变量(不占用参数位置)
class Student:
name = None
def say_hi(self, msg):
print(f'{msg},我是{self.name}')
stu1 = Student()
stu1.name = '张三'
stu1.say_hi('大家好') # 大家好,我是张三
4.3 魔术方法

class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f'Student类对象,name={self.name},age={self.age}'
def __lt__(self, other):
return self.age < other.age
def __le__(self, other):
return self.age <= other.age
def __eq__(self, other):
return self.name == other.name
stu1 = Student('张三', 18)
stu2 = Student('李四', 19)
print(stu1) # Student类对象,name=张三,age=18
print(stu1 < stu2) # True
print(stu1 > stu2) # False
print(stu1 == stu2) # False
4.4 私有成员
仅供內部使用的属性和方法,不对外开放。
定义:以__开头

4.5 类的继承
语法:
class 类(父类[, 父类2, ......, 父类n])
类内容体
class Phone:
IMEI = None
producer = 'HM'
def call_by_5g(self):
print('父类的5g通话')
# psaa 关键字,表示内容体为空
class MyPhone1(Phone):
pass
# super关键字调用父类
class MyPhone2(Phone):
producer = 'ITCAST' # 复写父类的成员属性
def call_by_5g(self): # 复写父类的成员方法
print(super().producer) # 使用父类的成员属性
super().call_by_5g(self) # 使用父类的成员方法
print('子类的5g通话')
五、操作数据库
5.1 连接数据库
- 安装:
pip install pymysql - 获取链接对象
- 导包:
from pymysql import Connection - Connection(主机,端口,账户,密码)即可得到链接对象
- 链接对象.close() 关闭和MySQL数据库的连接
- 导包:
- 执行SQL查询,通过链接对象调用cursor()方法,得到游标对象
- 游标对象.execute()执行SQL语句
- 游标对象.fecthall()获取数据
from pymysql import Connection
# 获取MySQL数据库的链接对象
conn = Connection(
host='localhost', # 主机名(或IP地址)
port=3306, # 端口,默认3306
user='root', # 账户名
password='123456', # 密码
autocommit=True # 自动提交(确认)
)
# 获取游标对象
cursor = conn.cursor()
conn.select_db('test') # 选择test数据库
# 使用游标对象,执行sql语句
cursor.execute('select * from student')
# 获取查询结果
results: tuple = cursor.fetchall()
for r in results:
print(r)
# 关闭数据库的连接
conn.close()
文章来源:https://blog.csdn.net/weixin_44257930/article/details/131867562
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!