YOLOv5改进 | 2023注意力篇 | BiFormer双层路由注意力机制(Bi-level Routing Attention)
一、本文介绍
BiFormer是一种结合了Bi-level Routing Attention的视觉Transformer模型,BiFormer模型的核心思想是引入了双层路由注意力机制。在BiFormer中,每个图像块都与一个位置路由器相关联。这些位置路由器根据特定的规则将图像块分配给上层和下层路由器。上层路由器负责捕捉全局上下文信息,而下层路由器则负责捕捉局部区域的细节。
具体来说,上层路由器通过全局自注意力机制对所有图像块进行交互,并生成全局图像表示。下层路由器则使用局部自注意力机制对每个图像块与其邻近的图像块进行交互,并生成局部图像表示。通过这种双层路由注意力机制,BiFormer能够同时捕捉全局和局部的特征信息,从而提高了模型在视觉任务中的性能。
本文主要通过对YOLOv5模型添加Biformer机制为例,让大家对于YOLOv5模型添加注意力机制有一个深入的理解,通过本文你不只能够学会添加Biformer注意力机制,同时可以举一反三学会其它的注意力机制的添加。
Biformer适用检测目标->适合处理大尺度目标、小尺度目标、密集目标和遮挡目标的检测?
目录
二、Biformer的作用机制

论文地址:?Biformer论文地址CSDN??
代码地址:?https://github.com/rayleizhu/BiFormer

在开始介绍作用机制之前,我们先来看一下不同注意力机制的效果。

从a-f分别是->
(a) 原始注意力:全局操作,会产生高计算复杂度和大内存占用。
(b)-(d) 稀疏注意力:为了减少注意力的复杂度,一些方法引入了稀疏模式,如局部窗口、轴向条纹和扩张窗口。这些模式将注意力限制在特定区域,减少了考虑的键-值对数量。
(e) 可变形注意力:可变形注意力通过改变规则网格来实现图像自适应的稀疏性。这使得注意力机制可以集中关注输入图像的不同区域。
(f) 双层路由注意力:所提出的方法通过双层路由实现了动态的、查询感知的稀疏性。首先确定了前k个(本例中k=3)相关区域,然后关注它们的并集。这使得注意力机制能够根据每个查询自适应地关注最有语义相关的键-值对,从而实现高效的计算。
下面来介绍作用机制->Biformer是一种结合了Bi-level Routing Attention的视觉Transformer模型,所以它具有Transformer模型的特性,其与本质上是局部操作的卷积(Conv)不同,注意力的一个关键特性是全局感受野,使得视觉Transformer能够捕捉长距离依赖关系。然而,这种特性是有代价的:由于注意力在所有空间位置上计算令牌之间的关联性,它具有较高的计算复杂度并且需要大量的内存,所以效率并不高。
为了以高效的方式全局定位有价值的键-值对进行关注,提出了一种区域到区域的路由方法。核心思想是在粗粒度的区域级别上过滤掉最不相关的键-值对,而不是直接在细粒度的标记级别上进行过滤。首先,通过构建一个区域级别的亲和度图,然后对其进行修剪,保留每个节点的前k个连接,从而实现这一点。因此,每个区域只需要关注前k个路由的区域。确定了关注的区域后,下一步是应用标记到标记的注意力,这是一个非常重要的步骤,因为现在假设键-值对在空间上是分散的。对于这种情况,虽然稀疏矩阵乘法是适用的,但在现代GPU上效率较低,因为现代GPU依赖于连续内存操作,即一次访问几十个连续字节的块。相反,我们提出了一种简单的解决方案,通过收集键/值标记来处理,其中只涉及到对于硬件友好的稠密矩阵乘法。我们将这种方法称为双层路由注意力(Bi-level Routing Attention,简称BRA),因为它包含了一个区域级别的路由步骤和一个标记级别的注意力步骤。
总结->引入了一种新颖的双层路由机制来改进传统的注意力机制,以适应查询并实现内容感知的稀疏模式。利用双层路由注意力作为基本构建模块,提出了一个通用的视觉Transformer模型,名为BiFormer。在包括图像分类、目标检测和语义分割在内的各种计算机视觉任务上的实验结果表明,所提出的BiFormer在相似的模型大小下显著优于基准模型的性能。?
三、Biformer的优劣势
BiFormer注意力机制的优势和劣势如下:
优势:
1. 高效的计算性能:BiFormer利用双层路由注意力机制,在查询感知的情况下,可以以内容感知的方式关注最相关的键-值对,从而实现稀疏性。这种稀疏性减少了计算和内存开销,使得BiFormer在相同计算预算下能够实现更高的计算性能,下面我通过图片来辅助大家理解这一优势!
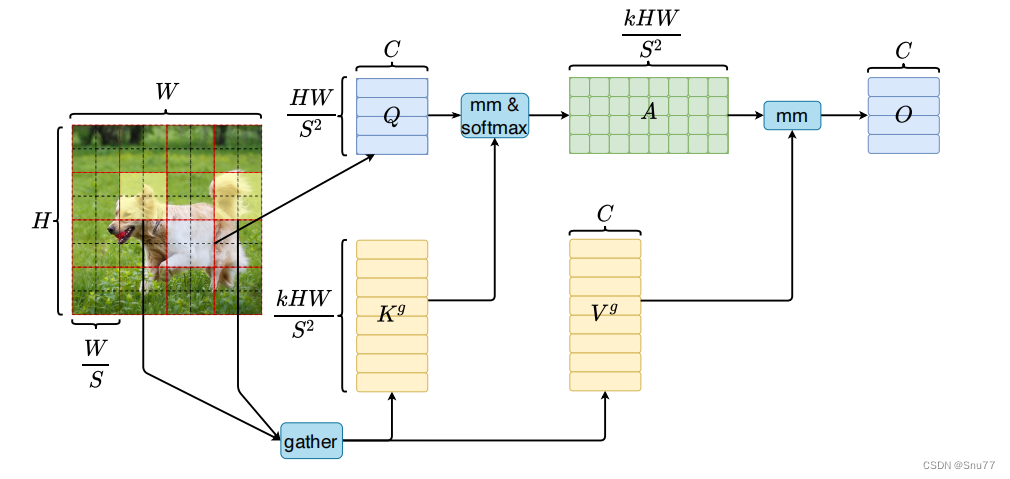
上图展示了通过收集前k个相关窗口中的键-值对,利用稀疏性跳过最不相关区域的计算过程,只进行适用于GPU的密集矩阵乘法运算。
在传统的注意力机制中,会对所有的键-值对进行全局的计算,导致计算复杂度较高。而在BiFormer中,通过双层路由注意力机制,只关注与查询相关的前k个窗口,并且仅进行适用于GPU的密集矩阵乘法运算。
这种做法利用了稀疏性,避免了在最不相关的区域进行冗余计算,从而提高了计算效率。只有与查询相关的键-值对参与到密集矩阵乘法运算中,减少了计算量和内存占用。
2. 查询感知的自适应性:BiFormer的双层路由注意力机制允许模型根据每个查询自适应地关注最相关的键-值对。这种自适应性使得模型能够更好地捕捉输入数据的语义关联,提高了模型的表达能力和性能。
劣势:
1. 可能存在信息损失:由于BiFormer采用了稀疏注意力机制,只关注最相关的键-值对,可能会导致一些次要的或较远的关联信息被忽略。这可能会在某些情况下导致模型性能的下降。
2. 参数调整的挑战:BiFormer的双层路由注意力机制引入了额外的参数和超参数,需要进行适当的调整和优化。这可能需要更多的实验和调试工作,以找到最佳的参数配置。
总体而言,BiFormer的注意力机制具有高效的计算性能和查询感知的自适应性,使其成为一个强大的视觉模型。然而,需要在具体任务和数据集上进行适当的实验和调整,以发挥其最佳性能。
四、Biformer的结构
我们通过下图来看一下Biformer的网络结构?
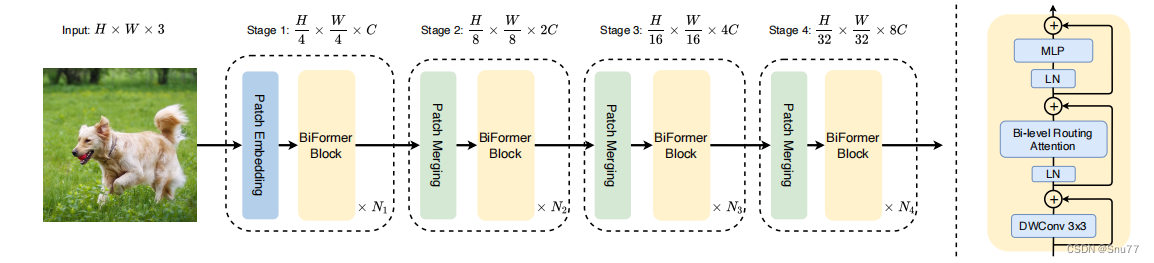
上图展示了BiFormer的整体架构和一个BiFormer块的详细信息。
左侧:BiFormer的整体架构。该架构包括多个BiFormer块的堆叠,并且根据具体任务和需求可以进行不同的配置。BiFormer通过引入双层路由注意力机制,在每个块中实现内容感知的稀疏性,从而提高了计算性能和任务表现。
右侧:BiFormer块的详细信息。BiFormer块是BiFormer的基本构建单元,由多个子层组成。其中包括自注意力子层(self-attention)和前馈神经网络子层(feed-forward neural network)。自注意力子层使用双层路由注意力机制,根据查询自适应地关注最相关的键-值对。前馈神经网络子层通过多层感知机对注意力输出进行非线性变换和特征提取。这样的组合使得BiFormer具备了适应性和表达能力,能够在不同的计算机视觉任务中发挥优异的性能。
通过整体架构和BiFormer块的设计,BiFormer能够有效地利用双层路由注意力机制,实现内容感知的稀疏性,并提供灵活性和强大的表达能力,适用于各种计算机视觉任务。
到此Biformer注意力机制的理论层面以及讲解完毕,下面我们开始来在YOLOv5中添加该机制,用实战的方式帮助大家理解。
五、添加Biformer注意力机制
5.1 Biformer的核心代码
"""
Bi-Level Routing Attention.
"""
from typing import Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from torch import Tensor, LongTensor
class TopkRouting(nn.Module):
"""
differentiable topk routing with scaling
Args:
qk_dim: int, feature dimension of query and key
topk: int, the 'topk'
qk_scale: int or None, temperature (multiply) of softmax activation
with_param: bool, wether inorporate learnable params in routing unit
diff_routing: bool, wether make routing differentiable
soft_routing: bool, wether make output value multiplied by routing weights
"""
def __init__(self, qk_dim, topk=4, qk_scale=None, param_routing=False, diff_routing=False):
super().__init__()
self.topk = topk
self.qk_dim = qk_dim
self.scale = qk_scale or qk_dim ** -0.5
self.diff_routing = diff_routing
# TODO: norm layer before/after linear?
self.emb = nn.Linear(qk_dim, qk_dim) if param_routing else nn.Identity()
# routing activation
self.routing_act = nn.Softmax(dim=-1)
def forward(self, query: Tensor, key: Tensor) -> Tuple[Tensor]:
"""
Args:
q, k: (n, p^2, c) tensor
Return:
r_weight, topk_index: (n, p^2, topk) tensor
"""
if not self.diff_routing:
query, key = query.detach(), key.detach()
query_hat, key_hat = self.emb(query), self.emb(key) # per-window pooling -> (n, p^2, c)
attn_logit = (query_hat * self.scale) @ key_hat.transpose(-2, -1) # (n, p^2, p^2)
topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # (n, p^2, k), (n, p^2, k)
r_weight = self.routing_act(topk_attn_logit) # (n, p^2, k)
return r_weight, topk_index
class KVGather(nn.Module):
def __init__(self, mul_weight='none'):
super().__init__()
assert mul_weight in ['none', 'soft', 'hard']
self.mul_weight = mul_weight
def forward(self, r_idx: Tensor, r_weight: Tensor, kv: Tensor):
"""
r_idx: (n, p^2, topk) tensor
r_weight: (n, p^2, topk) tensor
kv: (n, p^2, w^2, c_kq+c_v)
Return:
(n, p^2, topk, w^2, c_kq+c_v) tensor
"""
# select kv according to routing index
n, p2, w2, c_kv = kv.size()
topk = r_idx.size(-1)
# print(r_idx.size(), r_weight.size())
# FIXME: gather consumes much memory (topk times redundancy), write cuda kernel?
topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1),
# (n, p^2, p^2, w^2, c_kv) without mem cpy
dim=2,
index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv)
# (n, p^2, k, w^2, c_kv)
)
if self.mul_weight == 'soft':
topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv # (n, p^2, k, w^2, c_kv)
elif self.mul_weight == 'hard':
raise NotImplementedError('differentiable hard routing TBA')
# else: #'none'
# topk_kv = topk_kv # do nothing
return topk_kv
class QKVLinear(nn.Module):
def __init__(self, dim, qk_dim, bias=True):
super().__init__()
self.dim = dim
self.qk_dim = qk_dim
self.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias)
def forward(self, x):
q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim + self.dim], dim=-1)
return q, kv
# q, k, v = self.qkv(x).split([self.qk_dim, self.qk_dim, self.dim], dim=-1)
# return q, k, v
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, n_win=7, num_heads=8, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',
topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False,
side_dwconv=3,
auto_pad=True):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads == 0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv // 2,
groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
# assert self.kv_downsample_ratio is not None
# assert self.kv_downsample_kenel is not None
# TODO: fracpool
# 1. kernel size should be input size dependent
# 2. there is a random factor, need to avoid independent sampling for k and v
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
# TODO: need to consider the case where k != v so that need two downsample modules
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
# softmax for local attention
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad = auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
x = rearrange(x, "n c h w -> n h w c")
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
assert H % self.n_win == 0 and W % self.n_win == 0 #
###################################################
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
#################qkv projection###################
# q: (n, p^2, w, w, c_qk)
# kv: (n, p^2, w, w, c_qk+c_v)
# NOTE: separte kv if there were memory leak issue caused by gather
q, kv = self.qkv(x)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean(
[2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win,
i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
############ gather q dependent k/v #################
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)
# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)
######### do attention as normal ####################
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c',
m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
# param-free multihead attention
attn_weight = (
q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H // self.n_win, w=W // self.n_win)
out = out + lepe
# output linear
out = self.wo(out)
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return rearrange(out, "n h w c -> n c h w")5.2 手把手教你添加Biformer注意力机制?
5.2.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
?
?5.2.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
?
5.2.3 修改三?
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
 ????
????
5.2.4 修改四
然后我们找到parse_model方法,按照如下修改->

到此就修改完成了,复制下面的ymal文件即可运行。
六、配置Biformer注意力机制
恭喜你,到这里我们就已经成功的导入了注意力机制,离修改模型只差最后一步,我们需要找到yaml文件进行修改即可
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, BiLevelRoutingAttention, []], # 18
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, BiLevelRoutingAttention, []], #22
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, BiLevelRoutingAttention, []], # 26
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
七、训练模型
到此我们的所有准备工作都已完成,我们可以开始进行训练了。

最后祝大家学习顺利,科研成功,多多论文!如果你觉得这篇文章有帮助到你希望你给博主来个三连谢谢!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!