urllib 的 get 请求和 post 请求(二)
目录
一、爬取网页、图片视频?
目标:下载数据
知识点:urllib.request.urlretrieve()下载
使用urllib下载网页、图片和视频
下载网页:
# 下载一个网页
url_page= 'http://www.baidu.com'
# 参数: url 下载的路径 filename 文件名
urllib.request.urlretrieve(url_page, 'baidu.html')下载图片:?
# 下载图片
url_img = 'https://ts3.cn.mm.bing.net/th?id=OIP-C.nkWmM-lReaN8kH-ieXmZrQHaEo&w=316&h=197&c=8&rs=1&qlt=90&o=6&dpr=1.3&pid=3.1&rm=2'
urllib.request.urlretrieve(url_img, 'img.png')下载视频:
# 下载视频
# 网页--> 检查 --> (小箭头)定位视频,保存视频地址
url_video = 'https://www.youtube.com/watch?v=aT66uumZ0Zo'
urllib.request.urlretrieve(url_video, 'wind.mp4')完整代码:
import urllib.request
# # 下载一个网页
# url_page= 'http://www.baidu.com'
# # 参数: url 下载的路径 filename 文件名
# urllib.request.urlretrieve(url_page, 'baidu.html')
# 下载图片
url_img = 'https://ts3.cn.mm.bing.net/th?id=OIP-C.nkWmM-lReaN8kH-ieXmZrQHaEo&w=316&h=197&c=8&rs=1&qlt=90&o=6&dpr=1.3&pid=3.1&rm=2'
urllib.request.urlretrieve(url_img, 'img.png')
# 下载视频
# 网页--> 检查 --> (小箭头)定位视频,保存视频地址
url_video = 'https://www.youtube.com/watch?v=aT66uumZ0Zo'
urllib.request.urlretrieve(url_video, 'wind.mp4')二、请求对象的定制
目标:爬取整个网页
知识点:学习一种反爬方法,并定制请求对象
1.设置url
设置 url ,现在很多网站都是使用 https协议,安全性更高,所以爬取这类网站,要添加反爬方法。
# 这里换成了 https
url = 'https://www.baidu.com'?URL组成:
# url 的组成 # url = 'https://ts3.cn.mm.bing.net/th?id=OIP-C.nkWmM-lReaN8kH-ieXmZrQHaEo&w=316&h=197&c=8&rs=1&qlt=90&o=6&dpr=1.3&pid=3.1&rm=2' # http/https(添加了SSL协议) ts3.cn.mm.bing.net 80/443 th id=... # # 协议 主机 端口号 路径 参数 锚点 # 端口号 # http 80 # https 443 # mysql 3306 # oracle 1521 # redis 6379 # mongodb 27017
2.设置UA?
user_agent:中文名Wie用户代理,简称UA,他是一个特殊字符串头,是的服务器能够市北客户使用的操作系统及版本,CPU类型,浏览器及版本,浏览器渲染引擎,浏览器语言,浏览器插件等。
如何获取UA呢?
随便打开一个网页,右键选择检查 --> 网络(network) --> 全部(all)--> 左边随便点一个 --> 标头(header)--> 请求标头(request header)--> User-Agent 复制“User-Agent”及其后面的内容。

?将上面获取的信息写成一个字典
# 网页检查 --> 网络 --> request --> User-Agent
# UA是反爬的一种手段
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}3.定制请求对象
注意:request.urlopen()只接受字符串格式和request格式
所以我们要将 url和header的组合封装成一个 request格式的元素
使用urllib.request.Request()?定制请求对象,其中方法中传入的第一个参数为url,第二个为data,第三个为header,所以在传入header时使用关键字传参。
# 不能直接将 headers 放入 urlopen 中,它不能存储字典,只接受字符串和request格式
# 所以我们要进行请求对象的定制
# 注意,由于参数顺序的问题,需要关键字传参
request = urllib.request.Request(url, headers=headers)3.模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)4.打印结果
content = response.read().decode('utf-8')
print(content)此外,如果不加UA的话,获取的信息就会非常少
完整代码:
import urllib.request
# 这里换成了 https
url = 'https://www.baidu.com'
# 网页检查 --> 网络 --> request --> User-Agent
# UA是反爬的一种手段
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# url 的组成
# url = 'https://ts3.cn.mm.bing.net/th?id=OIP-C.nkWmM-lReaN8kH-ieXmZrQHaEo&w=316&h=197&c=8&rs=1&qlt=90&o=6&dpr=1.3&pid=3.1&rm=2'
# http/https(添加了SSL协议) ts3.cn.mm.bing.net 80/443 th id=... #
# 协议 主机 端口号 路径 参数 锚点
# 端口号
# http 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017
# 不能直接将 headers 放入 urlopen 中,它不能存储字典,只接受字符串和request格式
# 所以我们要进行请求对象的定制
# 注意,由于参数顺序的问题,需要关键字传参
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# 打印出的结果比较少,原因是遇到了反爬,给的数据不完整,所以要加user-Agent
三、get请求的urlencode方法
?目标:爬取网页,url中存在中文的情况
知识点:urllib.parse.quote()方法
1.设置url
导入包
import urllib.request
import urllib.parseurl = 'https://www.baidu.com/s?wd='
# 将‘周杰伦’三个字变成Unicode格式编码
# 我们需要依赖urllib.parse。
# 缺点:quote只能操作一个词,不能批量处理
name = urllib.parse.quote('周杰伦') # %E5%91%A8%E6%9D%B0%E4%BC%A6
url = url + name
# 或者直接这么操作
# url = 'https://www.baidu.com/s?wd=' + urllib.parse.quote('周杰伦')2.设置UA
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}3.定制请求对象
request = urllib.request.Request(url, headers=headers)4.模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)5.打印结果
content = response.read().decode('utf-8')
print(content)完整代码:
import urllib.request
import urllib.parse
# url = 'https://www.baidu.com/s?wd =%E5%91%A8%E6%9D%B0%E4%BC%A6'
# url = 'https://www.baidu.com/s?wd = 周杰伦
# 需求:获取这个地址下的网页源码(无法解析‘周杰伦’这三个字,换成上面Unicode编码格式就可以成功print )
# url = 'https://www.baidu.com/s?wd = 周杰伦'
url = 'https://www.baidu.com/s?wd='
# 将‘周杰伦’三个字变成Unicode格式编码
# 我们需要依赖urllib.parse。
# 缺点:quote只能操作一个词,不能批量处理
name = urllib.parse.quote('周杰伦')
url = url + name
# 或者直接这么操作
# url = 'https://www.baidu.com/s?wd=' + urllib.parse.quote('周杰伦')
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
request = urllib.request.Request(url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)四、post 请求英文翻译
?目标:获取百度翻译的翻译参数信息
知识点:post请求和get请求定制请求参数的方式不同urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url, data, headers)
1.设置url
# 百度翻译 spider --> 蜘蛛 # 网页检查 --> network --> all -->选择sug元素 看标头和负载 # url是sug元素的标头的request url (如果没有sug可能是因为输入’spider‘时是用中文输入的,改成英文输入就显示了)
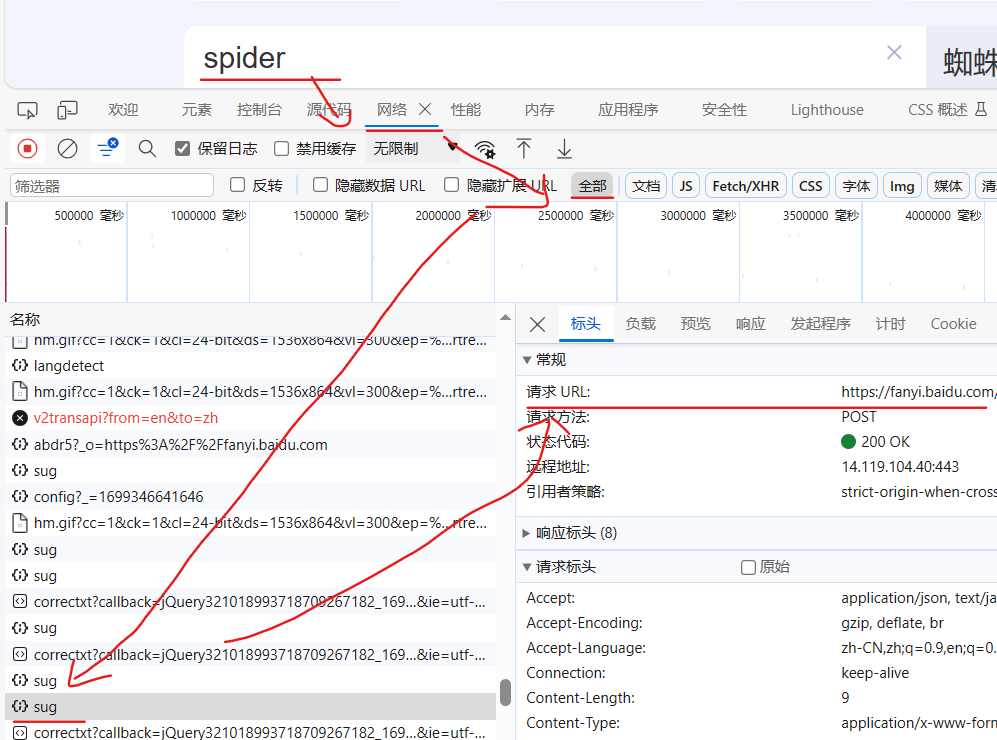
# post 请求
url = 'https://fanyi.baidu.com/sug'2.设置UA
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}3.设置参数
data中“kw”就是?网页检查 --> network --> all -->选择sug元素 的负载(payload)
data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码,不编码的data是字符串类型,但是发送到服务器时需要使字节形式
data = urllib.parse.urlencode(data).encode('utf-8')4.定制请求参数
# post的请求参数是不会拼接在url的后面的,而是需要放在请求对象定制的参数中
# post 请求的参数 必须要进行编码
request = urllib.request.Request(url, data, headers)5.模拟浏览器向服务器发送请求
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)6. 获取数据
直接输出的数据格式是字符串,无法显示中文?
# 获取相应的数据
content = response.read().decode('utf-8')
print(content) #{"errno":0,"data":[{"k":"spider","v":"n. \u8718\u86db; \u661f\u5f62\u8f6e\uff0c\u5341\u5b...
print(type(content)) # <class 'str'>7.将结果转为json格式
# 字符串 --> json对象
import json
obj = json.loads(content)
print(obj) # {'errno': 0, 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'}, {'k': 'Spider', 'v': '[电影]蜘蛛'}, {'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {'k': 'spiders', 'v': 'n. 蜘蛛( spider的名词复数 )'}, {'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般细长的; 象蜘蛛网的,十分精致的'}], 'logid': 2230303859}
# 总结
# post请求方式的参数,必须编码 data = urllib.parse.urlencode(data).encode('utf-8')
# 编码之后必须调用 encode 方法
# 参数放在请求对象定制的方法中,不能拼接
完整代码:
import urllib.request
import urllib.parse
# 百度翻译 spider --> 蜘蛛
# 网页检查 --> network --> all -->选择sug元素 看标头和负载
# url是sug元素的标头的request url (如果没有sug可能是因为输入’spider‘时是用中文输入的,改成英文输入就显示了)
# post 请求
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码,不编码的data是字符串类型,但是发送到服务器时需要使字节形式
data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求参数是不会拼接在url的后面的,而是需要放在请求对象定制的参数中
# post 请求的参数 必须要进行编码
request = urllib.request.Request(url, data, headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 获取相应的数据
print(content) #{"errno":0,"data":[{"k":"spider","v":"n. \u8718\u86db; \u661f\u5f62\u8f6e\uff0c\u5341\u5b...
print(type(content)) # <class 'str'>
# 字符串 --> json对象
import json
obj = json.loads(content)
print(obj) # {'errno': 0, 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'}, {'k': 'Spider', 'v': '[电影]蜘蛛'}, {'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {'k': 'spiders', 'v': 'n. 蜘蛛( spider的名词复数 )'}, {'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般细长的; 象蜘蛛网的,十分精致的'}], 'logid': 2230303859}
# 总结
# post请求方式的参数,必须编码 data = urllib.parse.urlencode(data).encode('utf-8')
# 编码之后必须调用 encode 方法
# 参数放在请求对象定制的方法中,不能拼接
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!