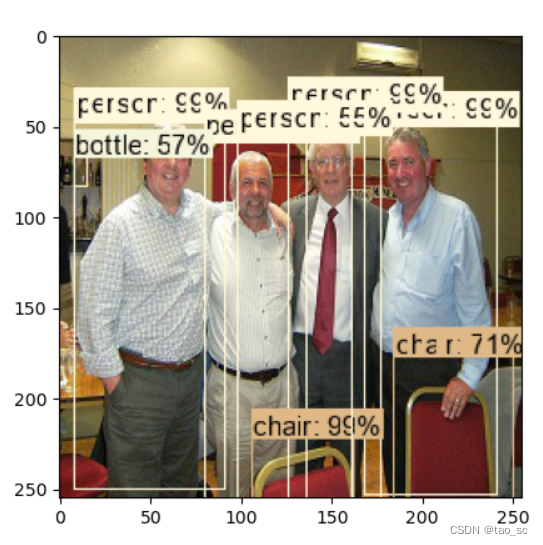
FasterRCNN目标检测
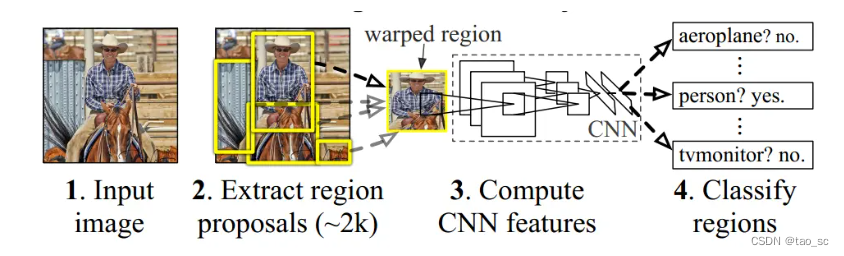
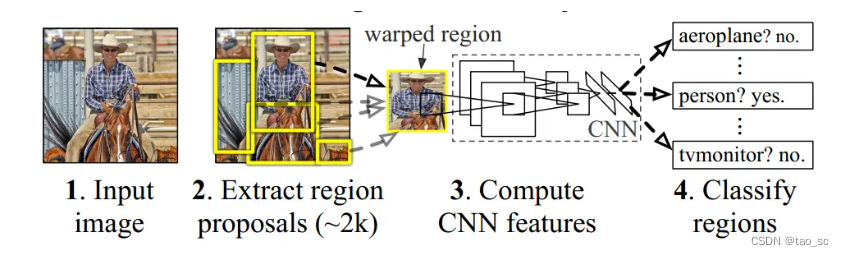
R-CNN
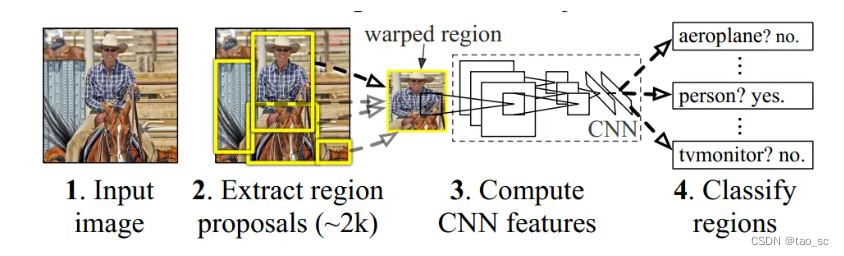
四个步骤:
- 对输入图片提取候选区(region proposal),每张大约2000个。论文中采用selective search的方法。
- 对每个候选区采用CNN网络提取特征。此处需要将proposal的尺寸缩放成统一的227x227,以匹配CNN网络。最终提取到的特征展平处理,长度为4096。
- 类别判断。将所提特征送入每一类的SVM分类器,判断是否属于该类。
- 候选框位置回归。
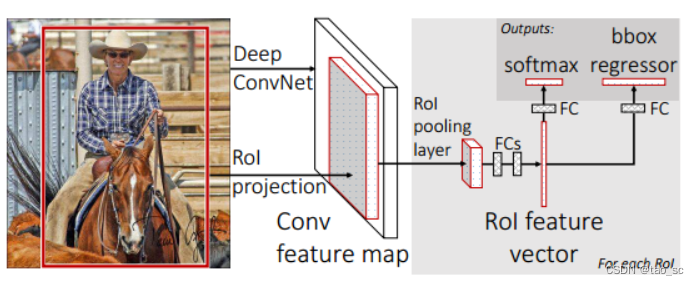
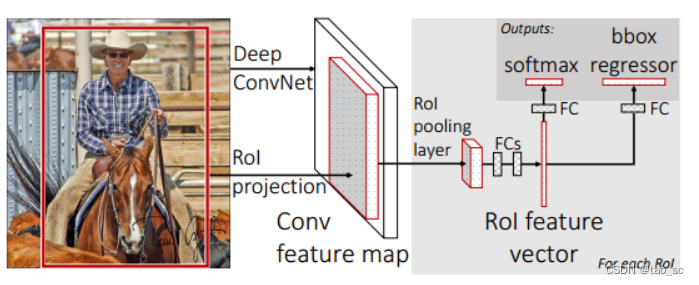
Fast RCNN
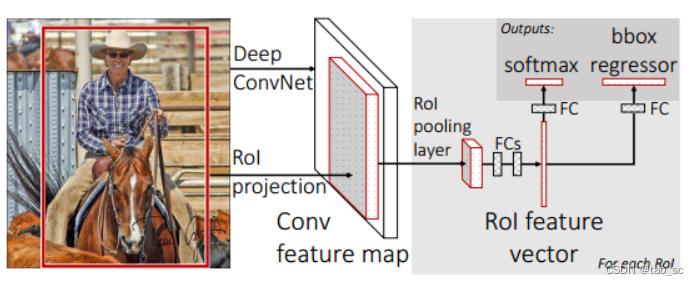
Fast RCNN相比于RCNN改进了3点:
- 共享卷积:将整幅图输出卷积神经网络,得到特征图,而不是像RCNN那样一个一个的候选区域输入卷积神经网络。
- ROI Pooling:将最后一个卷积层的SSP Layer改为RoI Pooling Layer,利用特征池化的方法,进行特征尺度变换,这样可以有任意大小的图片输入。
- 多任务损失函数:将边框回归直接加入到CNN网络中训练,同时包含了候选区域分类损失和位置回归损失。
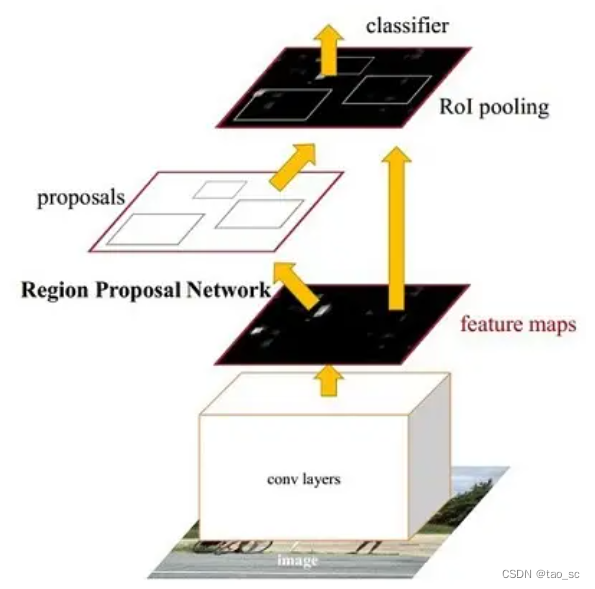
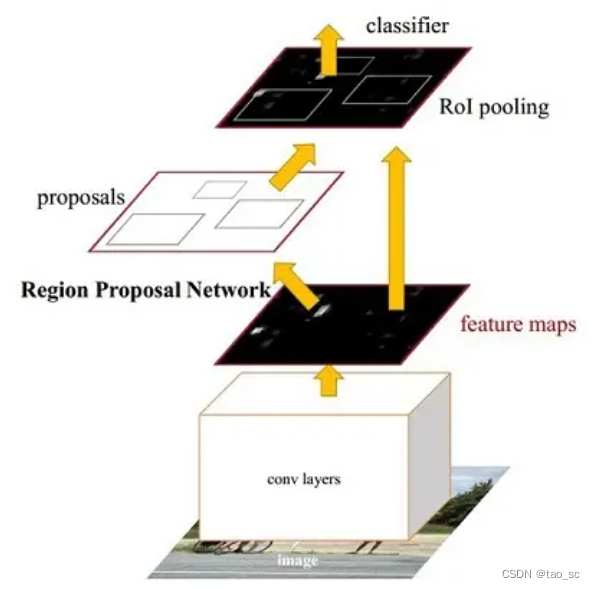
Faster RCNN
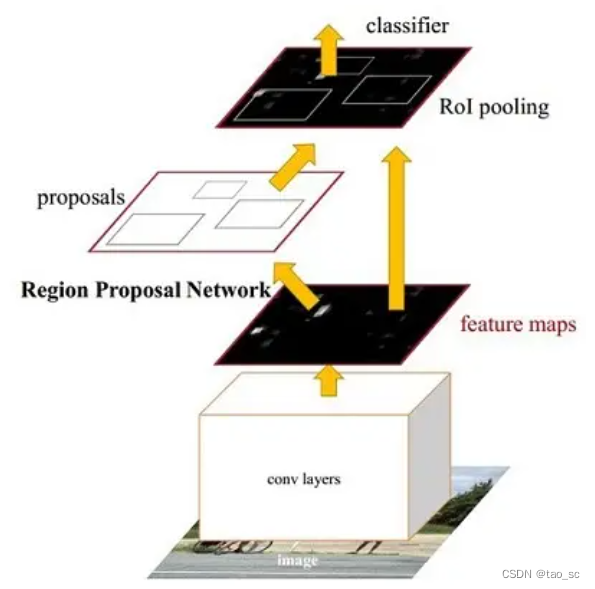
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
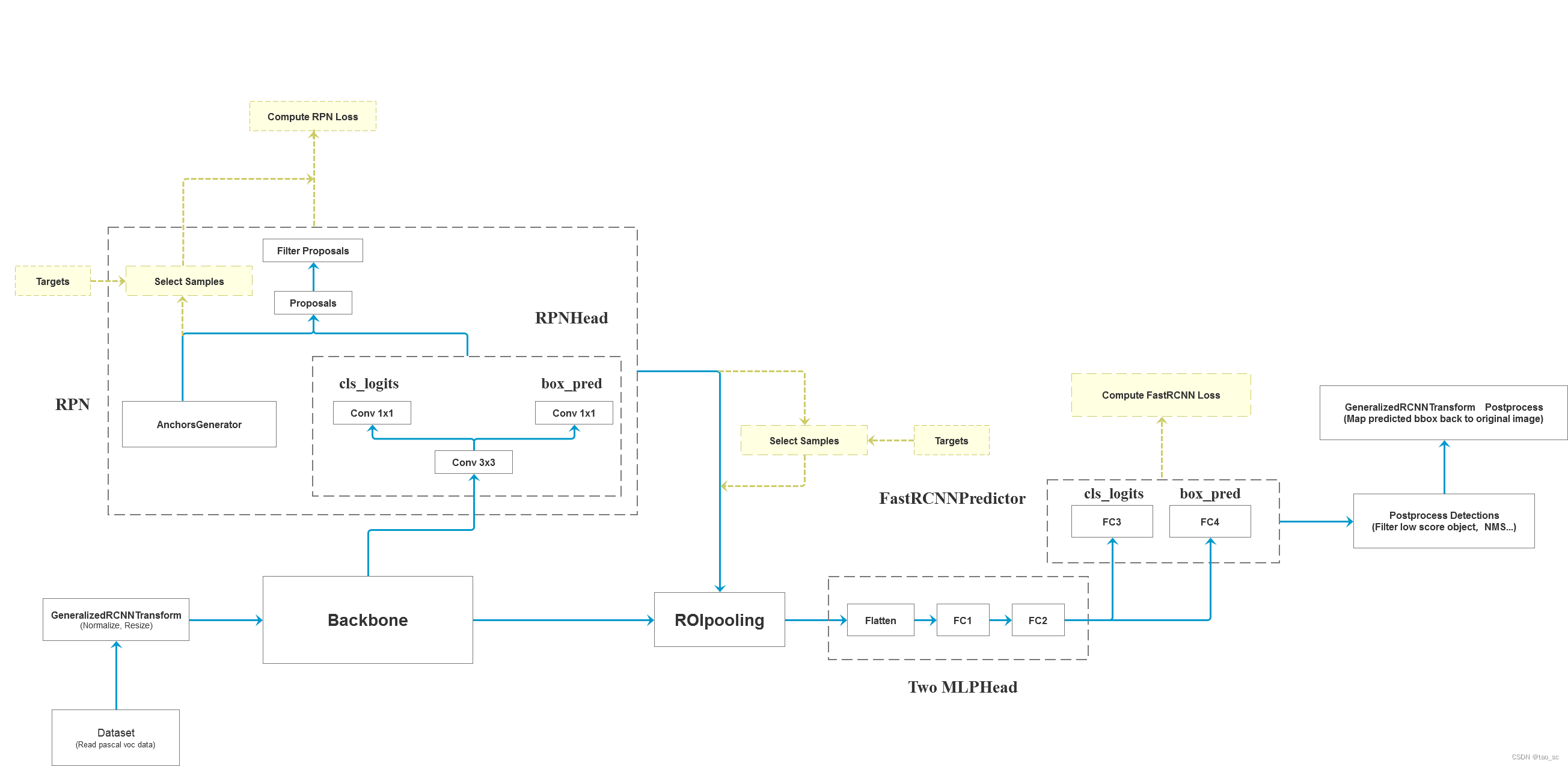
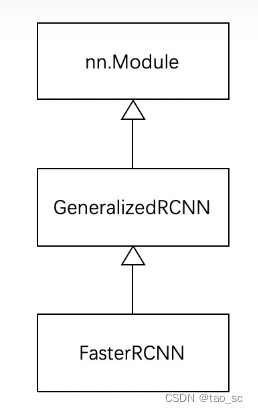
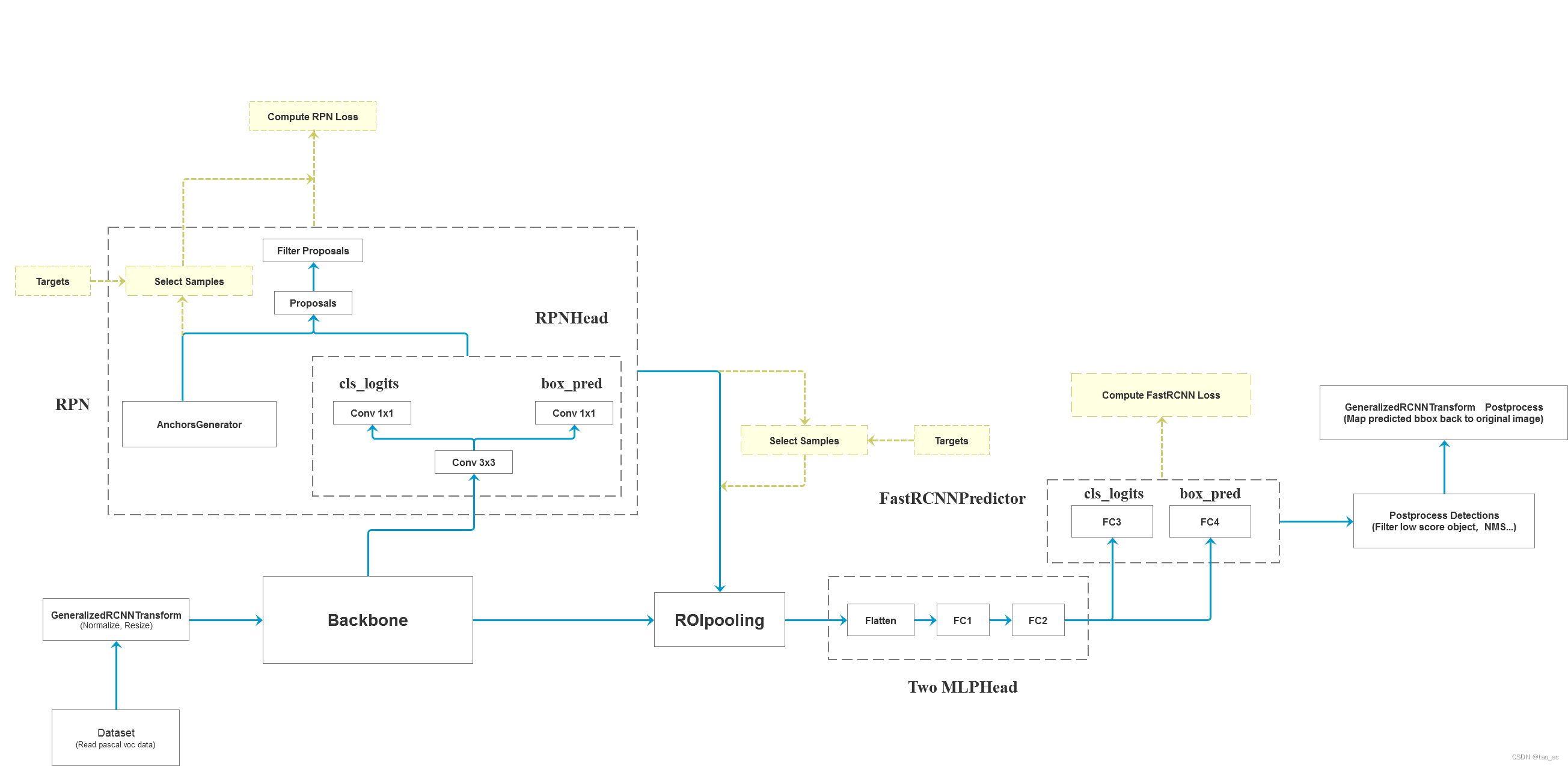
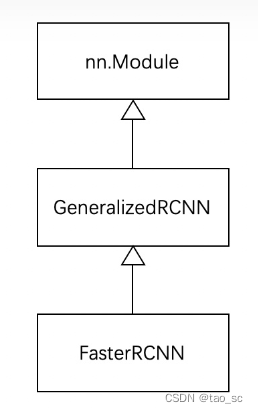
作为 torchvision 中目标检测基类,GeneralizedRCNN 继承了 torch.nn.Module,后续 FasterRCNN 、MaskRCNN 都继承 GeneralizedRCNN。
4个步骤:
-
将 transform 后的图像输入到 backbone 模块提取特征图
#GeneralizedRCNN.forward(…)
features = self.backbone(images.tensors)
backbone 一般为 VGG、ResNet、MobileNet 等网络。 -
然后经过 rpn 模块生成 proposals 和 proposal_losses
#GeneralizedRCNN.forward(…)
proposals, proposal_losses = self.rpn(images, features, targets) -
接着进入 roi_heads 模块(即 roi_pooling + 分类)
#GeneralizedRCNN.forward(…)
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets) -
最后经 postprocess 模块(进行 NMS,同时将 box 通过 original_images_size映射回原图)
#GeneralizedRCNN.forward(…)
detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
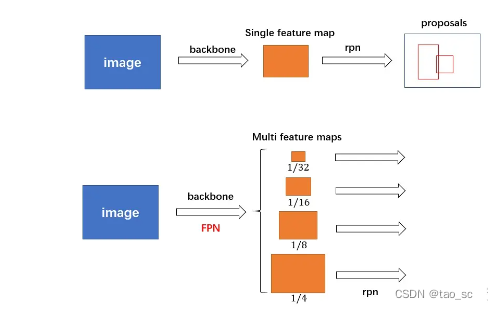
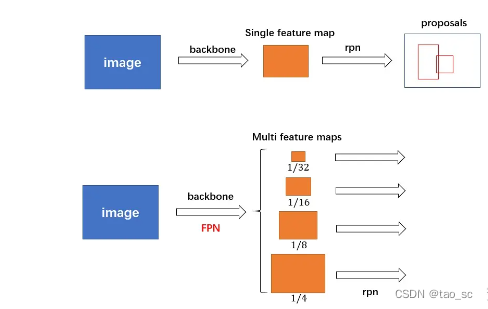
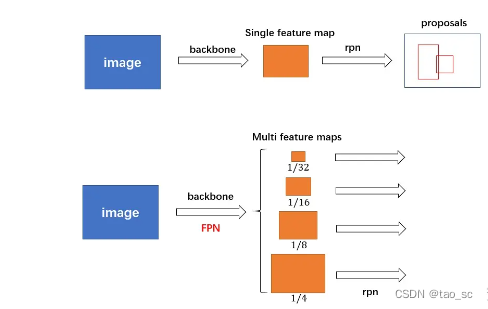
对于普通的 FasterRCNN 只需要将 feature_map 输入到 rpn 网络生成 proposals 即可。但是由于加入 FPN,需要将多个 feature_map 逐个输入到 rpn 网络。
class AnchorGenerator(nn.Module):
def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device="cpu"):
def set_cell_anchors(self, dtype, device):
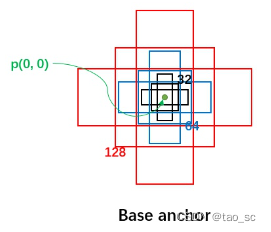
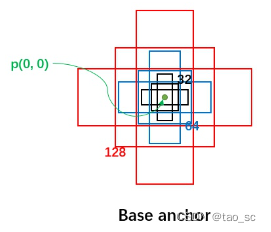
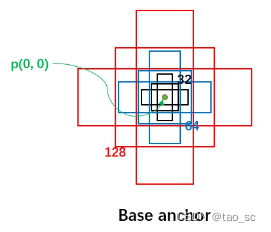
首先,每个位置有 5 种 anchor_size 和 3 种 aspect_ratios,所以每个位置生成 15 个 base_anchors:
[ -23., -11., 23., 11.] # w = h = 32, ratio = 2
[ -16., -16., 16., 16.] # w = h = 32, ratio = 1
[ -11., -23., 11., 23.] # w = h = 32, ratio = 0.5
[ -45., -23., 45., 23.] # w = h = 64, ratio = 2
[ -32., -32., 32., 32.] # w = h = 64, ratio = 1
[ -23., -45., 23., 45.] # w = h = 64, ratio = 0.5
[ -91., -45., 91., 45.] # w = h = 128, ratio = 2
[ -64., -64., 64., 64.] # w = h = 128, ratio = 1
[ -45., -91., 45., 91.] # w = h = 128, ratio = 0.5
[-181., -91., 181., 91.] # w = h = 256, ratio = 2
[-128., -128., 128., 128.] # w = h = 256, ratio = 1
[ -91., -181., 91., 181.] # w = h = 256, ratio = 0.5
[-362., -181., 362., 181.] # w = h = 512, ratio = 2
[-256., -256., 256., 256.] # w = h = 512, ratio = 1
[-181., -362., 181., 362.] # w = h = 512, ratio = 0.5
由于有 FPN 网络,所以输入 rpn 的是多个特征。为了方便介绍,以下都是以某一个特征进行描述,其他特征类似。
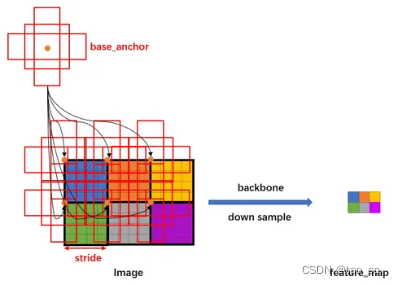
假设有h * w的特征,首先会计算这个特征相对于输入图像的下采样倍数 stride:
比如原图800*800大小的图片,输出特征图50*50,stride则为800/50=16


#AnchorGenerator.grid_anchors(...)
shifts_x = torch.arange(0, grid_width, dtype=torch.float32, device=device) * stride_width
shifts_y = torch.arange(0, grid_height, dtype=torch.float32, device=device) * stride_height
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
然后将 base_anchors 的中心从(0,0)移动到网格的点,且在网格的每个点都放置一组 base_anchors。这样就在当前 feature_map 上有了很多的 anchors。
stride 代表网络的感受野,网络不可能检测到比 feature_map 更密集的框了!所以才只会在网格中每个点设置 anchors(反过来说,如果在网格的两个点之间设置 anchors,那么就对应 feature_map 中半个点,显然不合理)。
#AnchorGenerator.grid_anchors(...)
anchors.append((shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4))
#RPN
-
如果输入3*600*800的图像,经过Backbone网络,降采样率为16,输出512*37*50(600/16=37.5,800/16=50)的特征图feature map.
-
经过RPNhead的3*3卷积神经网络维度还是512*37*50,对于分类网络分支,1x1卷积输出18*37*50的特征,对于回归网络分支,1x1卷积输出36*37*50的数据。
18是因为在RPN中的分类网络部分只是判断有无物体,即正负样本,不进行物体类别分类,所以分类结果只有两种(0和1),若每个特征点生成9个锚框Anchor,2*9=18.
回归网络中每个anchor对应四个数据,tx、ty、tw、th,因此9x4=36。 -
RPN中的AnchorGenerator 生成37*50*9=16650个锚框Anchors,有一些锚框超出了边界,因此保留边框内部部分。
-
RPN中分类网络部分:通过计算Anchor与标签的IOU来判断是正样本还是负样本,具体实现时,需要计算每一个Anchor与每一个标签的IOU,因此会得到一个IOU矩阵。判断标准如下:
(1) 对于任何一个Anchor,与所有标签的最大IOU小于0.3,则视为负样本。 (2) 对于任何一个标签,与其有最大IOU的Anchor视为正样本。 (3) 对于任何一个Anchor,与所有标签的最大IOU大于0.7,则视为正样本。由于Anchor的数量接近2万,并且大部分时背景,因此需要筛选一部分,默认选择256个Anchor。
-
RPN的回归偏移真值:得到anchor相对于target框的偏移量后,保存在bbox_tarets中,损失函数通常使用smooth函数,smooth函数结合了1阶与2阶损失函数,原因在于,当预测偏移量与真值差距较大时,使用2阶函数时导数太大,模型容易发散而不容易收敛,因此大于1时采用导数较小的1阶段损失函数。
-
RPN的非极大值抑制(NMS)将重叠的框去掉,最后再次根据RPN的预测得分选择前2000个,作为最终的Proposal,输出到下一阶段。这里得到2000个候选框还是太多,继续Select Sample,筛选出的正负样本总数为256,筛选标准如下:
(1)对于任何一个proposal,其与所有标签的最大IOU如果大于等于0.5,则视为正样本。 (2)对于任何一个proposal,其与所有标签的最大IOU如果大于等于0且小于0.5,则视为负样本。为了控制正负样本比例基本满足1:3,在此正样本数量不超过64,超过了则随机选取64个。
ROI Pooling
- 从RPN得到了256个ROI,以及每一个ROI对应的类别与偏移量真值,为了计算损失,还需要计算每一个ROI的预测量。由于ROI是由各种大小高宽不同的Anchor经过偏移修正、筛选得到的,但后续的RCNN全连接网络部分要求输入特征大小维度固定。Pooling的过程就是获得7*7大小区域的特征。
- 如输入原图像600*800,ROI为332*332,对应原图的一块子区域,经过下采样率为16的Backbone,特征图上ROI对应区域为20*20大小(332/16=20.75),然后为了获得7x7的特征,20/7=2.857,对ROI对应的20*20区域进行步长为2的最大池化。
全连接RCNN模块
- 在经过ROIPooling层之后,特征被池化到了固定的维度,因此接下来可以利用全连接网络进行分类与回归预测量的计算。经过池化后的256个ROI维度为256*512*7*7,作展平处理为256*25088,两个全连接网络输出256*4096,再分别进入分类网络分支和回归网络分支,得到256*21的分类输出和256*84的回归网络输出
- RCNn部分的损失函数计算方法与RPN相似,只不过分类类别有2变为21,回归则是至多有64个正样本参与回归计算,负样本不参与回归计算。
代码

网络输出
2. RCNn部分的损失函数计算方法与RPN相似,只不过分类类别有2变为21,回归则是至多有64个正样本参与回归计算,负样本不参与回归计算。
代码
[外链图片转存中…(img-ujOc2x2C-1699491243408)]





本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!