马尔科夫预测模型(超详细,案例代码)
概述
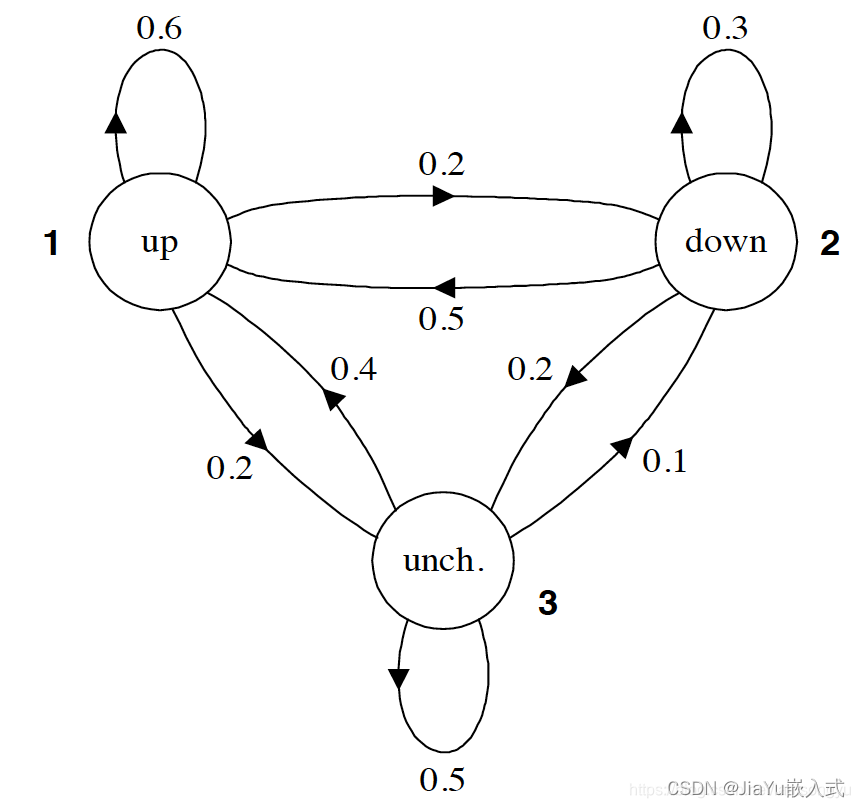
????????马尔科夫预测模型是一种基于马尔科夫过程的预测方法。马尔科夫过程是一类具有马尔科夫性质的随机过程,即未来的状态只依赖于当前状态,而与过去状态无关。这种过程通常用状态空间和状态转移概率矩阵来描述。
????????在马尔科夫预测模型中,系统被建模为处于一系列离散状态之一的马尔科夫链。每个状态表示系统可能的一个状态或情境,状态之间的转移由概率矩阵定义。这个概率矩阵描述了系统从一个状态转移到另一个状态的可能性。
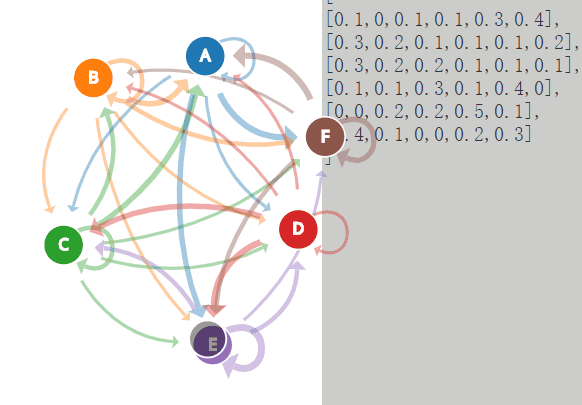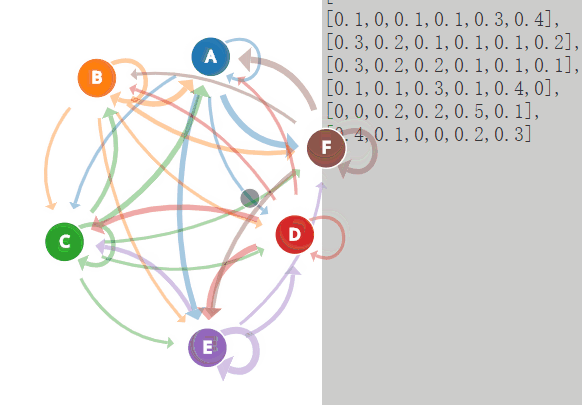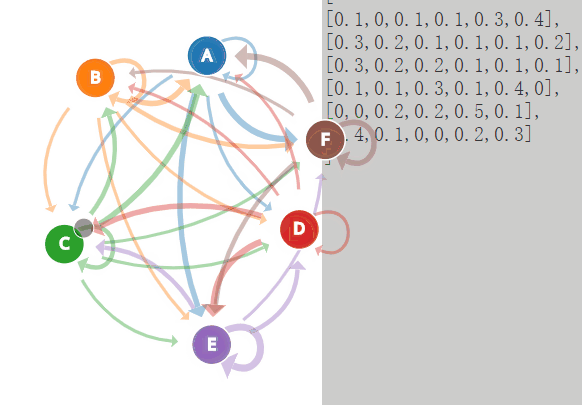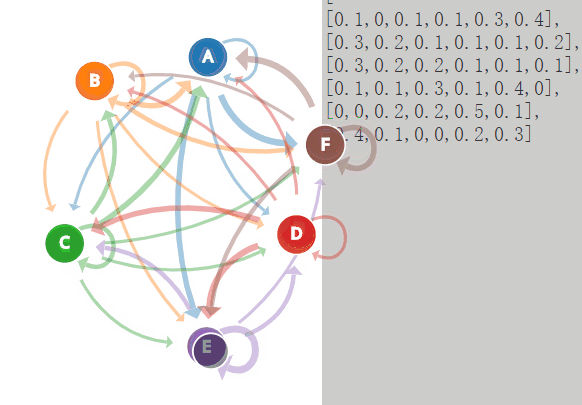
????????马尔科夫预测模型的基本思想是利用已知的状态序列来预测未来状态。通过观察现有的状态转移情况,可以估计状态转移概率,从而预测系统在未来的状态。这种方法通常用于时间序列分析、金融市场预测、天气预测等领域。
????????需要注意的是,马尔科夫预测模型有一个重要的假设,即未来状态的预测仅依赖于当前状态,而与过去的状态无关。这使得该模型在描述某些系统时可能过于简化,因为有些系统的行为可能受到更多历史信息的影响。
原理
马尔科夫链的定义
马尔科夫链是一个随机过程,具有马尔科夫性质,即未来状态的概率只取决于当前状态,与过去状态无关。马尔科夫链由状态空间、状态转移概率矩阵和初始状态分布组成。
状态空间
马尔科夫链的状态空间是指系统可能处于的所有状态的集合。状态可以是离散的或连续的,具体取决于问题的性质。
状态转移概率矩阵
状态转移概率矩阵描述了系统从一个状态转移到另一个状态的概率。对于离散状态空间,该矩阵是一个方阵,其中元素 Pij? 表示系统从状态i 转移到状态j 的概率。
初始状态分布
初始状态分布表示系统在时间初始时各个状态的概率分布。这是一个向量,其中每个元素表示系统在相应状态的初始概率。
状态转移过程
状态转移过程是指系统从一个状态到另一个状态的演变过程。通过不断迭代状态转移概率矩阵,可以模拟系统在不同时间步的状态变化。
预测过程
马尔科夫预测模型的核心思想是利用已知的状态序列来预测未来状态。通过观察现有的状态转移情况,可以估计状态转移概率,从而预测系统在未来的状态。这通常涉及到计算多步转移的概率,以确定系统在未来的可能状态。
稳态分布
????????在某些情况下,马尔科夫链可能收敛到一个稳态分布,即系统在各个状态上的概率分布趋于稳定。稳态分布对于理解系统长期行为和性质非常重要。
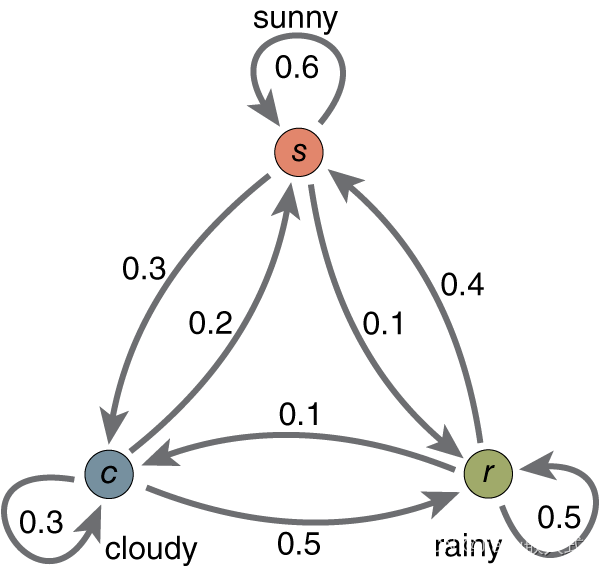
案例代码1
????????下面是一个实际的例子,演示了如何使用 Python 来建立一个简单的一阶离散状态的马尔科夫预测模型。在这个例子中,我们假设有三种天气状态:晴天、多云和雨天,然后模拟状态的转移和预测未来的天气状态。
import numpy as np
# 定义状态空间
states = ['晴天', '多云', '雨天']
# 定义状态转移概率矩阵
transition_matrix = np.array([[0.7, 0.2, 0.1], # 从晴天到晴天的概率为0.7,从晴天到多云的概率为0.2,从晴天到雨天的概率为0.1
[0.3, 0.4, 0.3], # 从多云到晴天的概率为0.3,从多云到多云的概率为0.4,从多云到雨天的概率为0.3
[0.1, 0.4, 0.5]]) # 从雨天到晴天的概率为0.1,从雨天到多云的概率为0.4,从雨天到雨天的概率为0.5
# 初始状态分布
initial_distribution = np.array([0.4, 0.4, 0.2]) # 初始时,系统处于晴天、多云和雨天的概率分别为0.4、0.4和0.2
# 模拟状态转移过程
num_steps = 7
current_state = np.random.choice(states, p=initial_distribution)
predicted_states = [current_state]
for _ in range(num_steps):
next_state = np.random.choice(states, p=transition_matrix[states.index(current_state)])
predicted_states.append(next_state)
current_state = next_state
# 打印预测结果
print("模拟的天气状态序列:", predicted_states)
????????这个例子中,使用了一个包含三个状态的马尔科夫链,每个状态之间的转移概率由 transition_matrix 定义。通过模拟状态转移过程,生成了一个模拟的天气状态序列。
????????注意,实际问题中,你可能需要基于真实数据来估计状态转移概率矩阵,而不是随机指定。
案例代码2
from hmmlearn.hmm import GaussianHMM
from hmmlearn.hmm import MultinomialHMM
#GaussianHMM是针对观测为连续,所以观测矩阵B由各个隐藏状态对应观测状态的高斯分布概率密度函数参数来给出
#对应GMMHMM同样,而multinomialHMM是针对离散观测,B可以直接给出
############################################博客实例#######################
#观测状态是二维,而隐藏状态有4个。
#因此我们的“means”参数是4×24×2的矩阵,而“covars”参数是4×2×24×2×2的张量
import numpy as np
startprob=np.array([0.6, 0.3, 0.1, 0.0])
#这里1,3之间无转移可能,对应矩阵为0?
transmat=np.array([[0.7, 0.2, 0.0, 0.1],
[0.3, 0.5, 0.2, 0.0],
[0.0, 0.3, 0.5, 0.2],
[0.2, 0.0, 0.2, 0.6]])
#隐藏状态(component)高斯分布均值?The means of each component
means=np.array([[0.0, 0.0],
[0.0, 11.0],
[9.0, 10.0],
[11.0, -1.0]])
#隐藏状态协方差The covariance of each component
covars=.5*np.tile(np.identity(2),(4,1,1))
#np.tile(x,(n,m)),将x延第一个轴复制n个出来,再延第二个轴复制m个出来。上面,为1*2*2,复制完了就是4*2*2
#np.identity(n)获取n维单位方阵,np.eye(n.m.k)获取n行m列对角元素偏移k的单位阵
# hmm=GaussianHMM(n_components=4,
# 参数covariance_type,为"full":所有的μ,Σ都需要指定。取值为“spherical”则Σ的非对角线元素为0,对角线元素相同。取值为“diag”则Σ的非对角线元素为0,对角线元素可以不同,"tied"指所有的隐藏状态对应的观测状态分布使用相同的协方差矩阵Σ
# covariance_type='full',
# startprob_prior=1.0,#PI
# transmat_prior=1.0,#状态转移A
# means_prior=,#“means”用来表示各个隐藏状态对应的高斯分布期望向量μ形成的矩阵
# means_weight=,
# covars_prior=,#“covars”用来表示各个隐藏状态对应的高斯分布协方差矩阵Σ形成的三维张量
# covars_weight=,
# algorithm=,
# )
hmm=GaussianHMM(n_components=4,covariance_type='full')
#Instead of fitting it from the data, we directly set the estimated parameters, the means and covariance of the components
hmm.startprob_=startprob
hmm.transmat_=transmat
hmm.means_=means
hmm.covars_=covars
########以上,构建(训练)好了HMM模型(这里没有训练直接给定参数,需要训练则fit)
#观测状态二维,使用三维观测序列,输入3*2*2张量
seen = np.array([[1.1,2.0],[-1,2.0],[3,7]])
logprob, state = hmm.decode(seen, algorithm="viterbi")
print(state)
#HMM问题1对数概率计算
print(hmm.score(seen))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!